Amazon SageMaker 기반 컨테이너를 활용한 Scikit-Learn 모델 훈련 및 호스팅 방법
지난 re:Invent 2017에서 처음 소개된 Amazon SageMaker는 원하는 규모의 머신 러닝 모델의 빌드, 훈련, 배포를 할 수 있는 서버리스(serverless) 데이터 사이언스용 환경을 제공하고 있습니다. 이를 통해 scikit-learn 처럼 폭넓게 사용되고 있는 프레임워크를 이용한 작업도 가능해졌습니다.
이 블로그에서는 2가지를 주제로 소개하려고 합니다: 첫번째는, 모델을 훈련(Training)시키고 호스팅하기 위해 Amazon SageMaker에서 컨테이너를 어떻게 사용하는지에 대해 알아봅니다. 그리고 두 번째는 Amazon SageMaker에서 Scikit 모델을 훈련시키고 호스팅하기 위한 도커(Docker) 컨데이너를 빌드하는 방법에 대해 설명합니다.
우선 모델의 훈련과 호스팅을 위해 Amazon ECS (Elastic Container Service)에서 Amazon SageMaker로 불러온 도커 이미지를 실행하는 방법부터 알아보겠습니다. 아울러 훈련코드와 추론(inference) 코드를 포함한 SageMaker 도커 이미지 등 관련 용어에 대해 간략히 설명합니다.
Amazon SageMaker에서 Scikit 모델의 빌드, 훈련, 배포에 대해서만 관심이 있으신 분들은 앞부분에 설명할 개요는 건너뛰어도 됩니다. 그리고 최소한의 노력으로 SageMaker에서 Scikit 모델을 컨테이너로 만드는 방법에 대해 실습을 통해 확인해보시기 바랍니다.
Amazon SageMaker 컨테이너 활용 방법
SageMaker는 알고리즘의 훈련과 배포에 있어 도커 컨테이너를 폭넓게 사용할 수 있도록 지원하고 있습니다. 컨테이너는 개발자, 데이터 과학자들이 소프트웨어를 표준화된 형태로 패키징할 수 있게 해줍니다. 이렇게 해서 만들어진 패키지는 도커를 지원하는 모든 플랫폼 상에서 일관되게 동작합니다. 컨테이너 생성 작업은 코드, 런타입, 시스템 툴, 시스템 라이브러리 등 필요한 모든 것을 한 곳에 모아서 패키징 하는 것을 의미합니다. 이렇게 하면 컨테이너가 실행되었을 때 주변의 다른 환경에 영향을 받지 않고 일관된 런타임을 보장할 수 있습니다.
Amazon SageMaker에서 모델을 개발할 때, 훈련 코드와 추론 코드를 위한 도커 이미지를 별개로 만들 수도 있고, 두 가지 코드를 하나의 도커 이미지에 합치는 것 모두 가능합니다. 이 블로그에서는 훈련과 호스팅을 모두 지원하는 단일 도커 이미지를 빌드해보겠습니다.
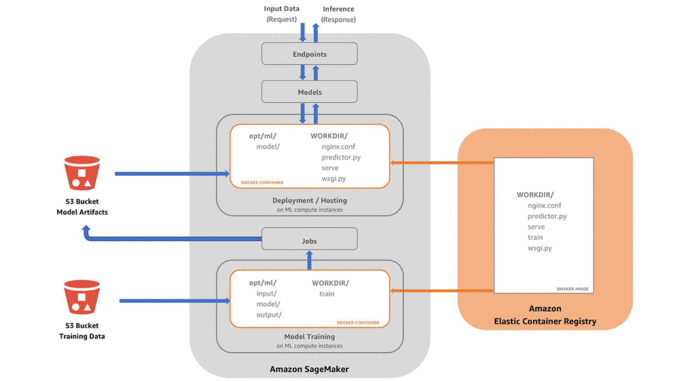
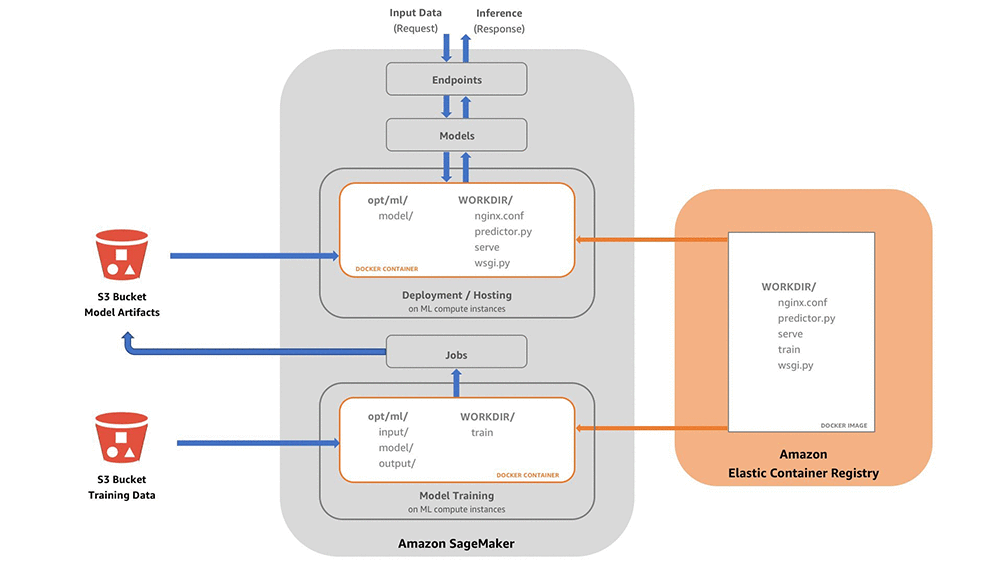
Amazon SageMaker 컨테이너 개념도

이렇게 강력한 컨테이너 환경을 이용하여, 개발자는 Amazon SageMaker 에코시스템 내에서 다양한 종류의 코드를 배포할 수 있습니다. 뿐만 아니라 DevOps 같은 배포 팀, 보안 팀, (컨테이너를 유지 관리하는) 인프라 팀, (컨테이너에 추가할 모델을 만드는 데 집중하는) 데이터 과학 팀 등 업무 성격에 따라 개별적으로 생성도 가능합니다.
컨테이너 폴더 사례
여러분이 직접 활용할 알고리즘에 대한 훈련과 호스팅을 위해 Amazon SageMaker에서 도커를 실행시키는 방법에 대해 설명하겠습니다. 이를 위해 여기서는 다음과 같은 임의의 컨테이너 폴더(github 참조)를 예로 들겠습니다. 컨테이너 폴더에 있는 주요 파일들은 다음과 같습니다 (아래 파일 목록 참조):
container/
decision_trees/
nginx.conf
predictor.py
serve
train
wsgi.py
DockerfileDockerfile은 컨테이너를 빌드하는데 사용됩니다. Dockerfile내에, (Python, NGINX, Scikit 등) 컨테이너 내에 설치될 필요 항목 또는 의존성(dependency)을 지닌 솔루션, 패키지, 라이브러리 등을 지정할 수 있습니다. 다음 단계로 설치된 컨테이너가 프로그램 폴더 내에 포함되어 있는 프로그램들을 실행시킵니다. 이를 위해, 여러분의 컨테이너 폴더 내에 프로그램 폴더의 이름을 지정해주어야 합니다. 여기서는 프로그램 폴더를 Scikit 모델 뒤에 있는 이름인 decision_tress 로 붙여봤습니다. 다음으로, Dockerfile에 정의되어 있는 컨테이너의 WORKDIR로 프로그램 폴더를 복사하도록 Dockerfile 내에 스크립트를 한 줄 추가해야 합니다. 이를 통해서 설치된 프로그램이 어디 있는지 컨테이너가 알 수 있게 됩니다.
컨테이너 시작 프로그램
여러분이 도커 이미지를 실행시킬 때, 컨테이너는 ENTRYPOINT에서 정의된 프로그램을 실행하는 경우,입력 매개변수를 통해서 전달받은 프로그램의 이름을 찾아서 실행시키는 경우 중 한 가지 형태로 프로그램을 시작하게 합니다. 만약 ENTRYPOINT가 정의되어 있으면, 다음 명령어를 통해서 기본값으로 설정되어 있는 시작 프로그램을 실행하게 될 것입니다.
docker run <image>또는, 다음 명령어를 이용해서 특정 프로그램을 실행시킬 수도 있습니다:
docker run <image> <startup program>훈련 또는 호스팅 용으로만 이미지를 빌드하려면, 프로그램 폴더에서 사용하지 않는 기능들을 빌드할 필요가 없겠죠. 만약 훈련용으로만 이미지를 빌드할 경우, 프로그램 폴더 내에 있는 train 파일만 있으면 될 겁니다. 또, ENTRYPOINT로 train폴더를 설정할 수도 있는데, 이렇게 하면 이미지는 train 프로그램을 훈련 서비스를 위한 기본 설정값으로 이용하여 동작하게 됩니다.
마찬가지로, 만약 호스팅용으로만 이미지를 빌드할 경우, 프로그램 폴더 내에 있는 파일들은 nginx.conf, predictor.py, serve, wsgi.py 등이 있습니다. 여기서 serve를 ENTRYPOINT로 설정할 수 있는데, 이를 통해서 serve 프로그램이 기본값으로 설정된 상태로 이미지를 실행시킬 수 있습니다.
이 블로그에서는 앞에서도 설명 드렸듯이, 훈련과 호스팅을 둘 다 할 수 있는 단일 이미지를 빌드합니다. 따라서 ENTRYPOINT로 시작 프로그램을 정의하는 작업은 하지 않습니다. 대신, Amazon SageMaker가 다음 2개의 명령어 중 하나를 이용하여 이미지를 실행시킬 것입니다. 그러고 나면 컨테이너는 자연스럽게 훈련과 호스팅용 서비스를 위한 프로그램을 시작하게 됩니다.
docker run <image> train
docker run <image> serve
이들 프로그램의 기능을 로컬 상에서 테스트하고 디버깅하는 방법에 대해서는 뒤에서 설명하겠습니다.
Amazon SageMaker를 이용한 도커 컨테이너 실행 방법
이번 섹션에서는 훈련용 컨테이너와 호스팅용 컨테이너 간의 차이점에 대해 알아보겠습니다. 이를 통해서 Amazon SageMaker 내에서 여러분의 알고리즘을 포함하고 있는 컨테이너의 빌드를 위해 어떤 파일이 재사용될 수 있는지, 또는 변경될 수 있는지를 알 수 있을 것입니다.
Amazon SageMaker 훈련을 위한 컨테이너 실행
Amazon SageMaker는 다음 명령어를 실행시켜서 훈련 코드가 실행되도록 합니다.
docker run <image> train이 명령어는 도커 이미지에 train이라는 실행 파일이 있다는 것을 의미합니다. 여러분의 훈련 알고리즘을 구현하기 위해 이 프로그램을 수정할 것입니다. 도커 환경 내에서 실행가능한 언어라면 무엇이든 가능합니다. 하지만 데이터 과학자들에게 있어서 대부분의 경우 Python, R, Scala, Java 등이 많이 사용되고 있습니다. 이 글에서는 Scikit 예제를 위해 Python을 사용하겠습니다.
런타임 시에, Amazon SageMaker는 Amazon S3 에서 컨테이너로 훈련 데이터를 불러들입니다. 문제없이 이상적으로 잘 실행되었다면 훈련 프로그램은 모델 결과물(아티팩트, artifact)을 만들어낼 것입니다. 이 아티팩트는 컨테이너에 반영되며, tar 아카이브 형태로 압축됩니다. 그리고 이 작업이 Amazon SageMaker에서 완료되면 Amazon S3로 옮겨집니다.
Amazon SageMaker 호스팅을 위한 컨테이너 실행
Amazon SageMaker는 다음 명령어를 이용해서 호스팅 서비스가 실행되도록 합니다.
docker run <image> serve이 명령어의 실행을 통해서 추론(inference)을 위한 HTTP 요청을 받아들일 수 있는 RESTful API가 열립니다. 다시 한 번 말씀드리면, 도커 환경에서 사용 가능한 프로그래밍 언어 또는 프레임워크는 여기서도 모두 사용 할 수 있습니다. 이 글에서는 Python 마이크로프레임워크인 Flask를 사용합니다.
대부분의 Amazon SageMaker 컨테이너에서 serve는 추론 서버를 시작하기 위한 래퍼(wrapper)로 생각하시면 됩니다. 하지만 단순한 래퍼라기 보다는 Amazon SageMaker 에서는 훈련을 위해 생성된 모델 아티팩트를 컨테이너로 불러들이고 이 아티팩트의 아카이브 압축을 푸는 작업까지 자동으로 해준다는 점을 기억해주시기 바랍니다.
RESTful 마이크로서비스를 위해 Flask를 실행시킬 경우, Amazon SageMaker의 sample notebook 에서 다음과 같은 파일을 사용할 수 있게 됩니다:
이들 중 호스팅 서비스를 위해서 수정이 필요한 파일은 predictor.py 입니다. 이 파일 안에 추론(inference) 관련 코드가 들어있고, 이 코드를 통해 예측(prediction)을 위한 Flask 앱(app)이 만들어집니다. 여기에 대한 자세한 내용은 이 글에서 다루고 있는 Scikit 예제를 이용해서 뒤에서 조금 더 자세히 설명하겠습니다.
Amazon SageMaker컨테이너 저장 위치
Amazon SageMaker가 훈련과 호스팅을 위한 컨테이너를 실행시키기 위해서는, 이미지 저장소(repository)인 Amazon ECR (Elastic Container Registry)에서 호스팅용 이미지를 찾을 수 있어야 합니다. 이와 관련하여 다음과 같은 3가지 주요 작업이 있습니다: (1) 로컬 환경에서 빌드, (2) 저장소 위치 태깅(tagging), (3) 저장소로 이미지 푸시(pushing). 여기서는 이 작업들이 어떻게 이뤄지는지 상위 개념 수준으로 알아보고, 뒤에서 소개할 “컨테이너 빌드” 섹션에서 실제 코드를 통해 실습해보실 수 있도록 설명 드리겠습니다.
로컬 이미지를 빌드하려면, 다음 명령어를 실행하면 됩니다.
docker build <image name>이 명령어를 실행하면 여러분의 로컬 인스턴스에서 이미지를 생성하기 위해 (앞에서 설명한) Dockerfile 에서 필요한 명령어들을 가져옵니다. 이미지 빌드가 완료되면, 도커의 로컬 인스턴스에게 이미지를 저장할 위치를 알려주어야 합니다. 그래야만 SageMaker가 이 이미지를 찾을 수 있겠죠. 다음 명령어를 이용해서 이미지에 태깅 작업을 합니다.
docker tag <image name> <repository name>저장소 이름은 다음과 같은 형식을 따릅니다.
<account number>.dkr.ecr.<region>.amazonaws.com/<image name>:<tag>저장소 이름을 지닌 이미지에 태깅을 하지 않을 경우, 도커는 기본 설정에 맞춰서 Amazon ECR이 아니라 Docker hub에 업로드하게 됩니다. Amazon SageMaker는 현재 도커 이미지를 Amazon ECR에 올리도록 되어 있습니다. 이미지를 Doker hub가 아니라 ECR에 푸시하려면, 저장소의 호스트 이름을 가지고 태깅 작업을 해야 합니다.
Docker hub와는 달리, Amazon ECR은 기본적으로 Amazon SageMaker에 잘 맞춰진 사설 저장소입니다. 만약 Amazon SageMaker의 이미지를 외부로 공유하고 싶으면, Amazon ECR 사용자 가이드 정보를 참고하시면 됩니다.
끝으로, 저장소 이름의 태그에 있는 리전 목록을 가지고 이미지를 Amazon ECR에 업로드 하려면, 다음 명령어를 실행하면 됩니다.
docker push <repository name>이어서 Scikit의 실습 가이드에 대해 조금 더 자세한 내용을 소개하겠습니다. 우선 Amazon SageMaker에서 도커를 어떻게 이용하면 되는지 알아보겠습니다.
Amazon SageMaker 도커 컨테이너에 대해 끝으로 하나만 더 말씀드리겠습니다. 우리는 앞에서 모델 훈련과 호스팅(hosting) 두 가지를 모두 할 수 있는 도커 컨테이너를 빌드할 수도 있고, 각각을 따로따로 빌드할 수 있는 옵션도 있음을 확인했습니다. 2개의 도커 이미지를 빌드하는 작업은 중복이 있을 수 있는 공통 라이브러리 때문에 저장 공간의 증가와 비용 낭비가 일어날 수 있지만, 추론(inference)용 컨테이너를 훨씬 작게 빌드할 수 있는 장점도 있습니다. 이렇게 하면 트래픽이 증가하는데 따른 호스팅 서비스의 확장도 매우 빠르게 할 수 있습니다. 특히, 훈련을 위해 GPU를 사용한 반면, 추론 코드는 CPU에 최적화시킨 경우가 대표적입니다. 따라서 하나 이상의 컨테이너를 빌드할 경우 앞으로 나타날 트레이드오프에 대해 충분히 신중하게 생각할 필요가 있겠습니다.
훈련 이미지에 대한 ECR 내 경로
이미지를 빌드하고 Amazon ECR에 푸시하고 나면, 앞에서 설명한 도커 명령어가 실행되었을 때 Amazon SageMaker는 여러분의 알고리즘을 위한 훈련 서비스를 실행시키게 됩니다. Amazon ECR에 저장되어 있는 훈련용 이미지의 저장소 경로를 Amazon Sagemaker가 알 수 있도록 Amazon SageMaker콘솔 상에서 설정하는 방법을 알아보겠습니다. 그런 다음, AWS CLI를 이용하여 훈련 작업과 엔드포인트를 효율적으로 론칭(launching)하는 방법도 설명합니다. 아마도 꽤 유용할 것입니다.

추론 이미지에 대한 ECR 내 경로
앞에서와 마찬가지로, Amazon ECR 내에 저장된 추론 코드 이미지의 위치와 Amazon S3에 있는 훈련 모델 아티팩트의 위치를 지정해놓으면, Amazon SageMaker가 여러분의 알고리즘을 위한 호스팅 서비스를 실행할 수 있게 됩니다.
아래 스크린샷에 나와 있는 것처럼, 모델을 통해 예측한 결과를 추론 요청에 전달할 수 있도록 SageMaker의 런타임 HTTPS 엔드포인트를 통해서 말이죠.

뒤에서 한 단계씩 차근차근 알아보도록 하겠습니다. 우선 이러한 것들을 통해서 어떻게 연동할 수 있는지만 알아두기로 합니다.
/opt/ml/
런타임 시에, Amazon SageMaker는 도커 컨테이너에서 사용 가능한 외부의 모델 아티팩트, 훈련용 데이터, 그리고 기타 환경 설정 정보 등을 /opt/ml 로 불러들입니다. 이렇게 하면 Amazon SageMaker가 모델 아티팩트를 실행시킬 위치이자, 도커 컨테이너의 밖에서 접근 가능한 프로그램 결과물의 위치를 의미합니다. 이러한 내용을 알고 있으면 훈련용 코드와 추론용 코드를 작성할 때 도움이 될 것입니다.
/opt/ml/
input/
config/
data/
model/
output/
failure/
특히, 로컬 상에서 테스트와 디버깅을 위해서 훈련용 입력 자료가 저장될 경로(/opt/ml/input/data/)와 모델의 경로(/opt/ml/model/)를 정확하게 알아두는 것이 매우 중요합니다. 경로 매핑에 대해 마운팅하는 방법은 Amazon SageMaker의 Using Your Own Training Algorithms와 Using Your Own Inference Code 문서를 참고하시기 바랍니다.
Scikit-Learn을 이용한 실제 모델 빌드
“빌드”는 Amazon SageMaker 워크플로우의 첫 번째 단계입니다. 특히 Scikit과 관련해서는1) 모델, 2) 훈련 코드, 그리고 3) 추론 코드라는 3가지가 빌드됩니다. 이렇게 만들어진 결과물은 도커 이미지에 컨테이너로 만들어집니다.
도커를 위한 훈련 코드 빌드
Scikit 모델처럼 여러분이 직접 만든 모델을 이용할 경우, Jupyter notebook 이 아니라 파이썬 파일 내에서 모델을 빌드해야 합니다. 노트북 인스턴스 내에 모델 파이프라인을 이용하여 실험을 수행할 수 있습니다. 하지만, 훈련용 클러스터로 옮길 준비가 일단 되었다면, 파일 내에 관련 코드가 있어야 합니다. 이렇게 해야만 도커를 이용하여 컨테이너를 만들 수 있습니다.
예제 노트북 중 하나인 train을 가져와서 샘플 훈련 파일을 살펴보기로 합시다. 이 코드는 Amazon SageMaker가 컨테이너에 훈련 작업(training job)을 띄울 때 실행됩니다. 이 파일이 약간 복잡할 수도 있겠지만, 대단히 중요한 섹션이니 꼼꼼하게 읽어보시기 바랍니다.
우선, 21-31 라인 사이의 코드는 SageMaker가 컨테이너의 /opt/ml/안에 아래의 사항들을 마운트하기 위한 모든 경로를 정의하고 있습니다.
- 훈련 데이터 (채널 포함)
- 환경 설정 정보
- 모델
- 결과
다음으로, 훈련을 실시할 함수를 정의합니다. 만약 여러분이 Amazon SageMaker 상에서 Scikit 모델을 빌드하는 작업을 주로 한다면, 52-53 라인의 코드가 가장 중요합니다:
train_y = train_data.ix[:,0]
train_X = train_data.ix[:,1:]이 2줄의 코드는 데이터에 있는 컬럼 중 어떤 것이 레이블 컬럼인지를 정해줍니다. 이번 예에서는 붓꽃(Iris) 데이터셋을 사용합니다. CSV 파일의 첫 번째 컬럼은 대상 레이블로, train_y 변수에 할당합니다. 나머지 컬럼은 train_X에 할당합니다. 붓꽃 데이터에 헤더 컬럼이 없다는 점 역시 매우 중요합니다. 여러분의 데이터를 다룰 때에는 train 코드 내에서 이 부분을 잘 편집해서 사용해야 합니다. 또는 붓꽃 데이터와 비슷한 포맷으로 보이도록 데이터 파일을 수정해야 합니다.
아래 코드 블록(57-59 라인)에서는 훈련 작업에 전달할 모든 하이퍼파라미터들을 가져오는 역할을 합니다.
max_leaf_nodes = trainingParams.get('max_leaf_nodes', None)
if max_leaf_nodes is not None:
max_leaf_nodes = int(max_leaf_nodes)
train 파일에서 전달되는 파라미터는 하나밖에 없습니다. 하지만 전달되는 문자열을 어떻게 받아들이는지 함께 살펴봅시다. 그리고, 적절한 포맷으로 문자열을 변환하는 방법도 알아봅시다. 이 예에서는 max_leaf_nodes 파라미터를 정수로 변환합니다. 이를 통해서 모델에서 세팅하려고 하는 하이퍼파라미터의 개수를 확장시킬 수 있습니다.
다음으로, 아마도 가장 중요할 수 있는, Scikit 모델을 정의하고 훈련을 진행합니다. 이 부분은 62-63 라인에 있습니다:
clf = tree.DecisionTreeClassifier(max_leaf_nodes=max_leaf_nodes)
clf = clf.fit(train_X, train_y)이 코드는 Scikit을 다루어 보신 경험이 있는 분들에겐 익숙할 겁니다. 하이퍼파라미터를 세팅하는 방법 외에, 모델 정의와 모델 훈련은 노트북에서 했던 방법과 동일합니다. 하이퍼파라이터를 위해서는, 앞에서 이미 구해놓은max_leaf_nodes 변수를 사용한다는 점에 주목하시기 바랍니다. 이렇게 해서 Scikit 모델이 여러분에게 가장 적합한 형태로 만들어지도록 모델을 정의할 수 있습니다.
끝으로, 모델이 train 파일에 어떻게 저장되는지 알아봅시다. 이 코드는 라인 66-67에 있습니다:
with open(os.path.join(model_path, 'decision-tree-model.pkl'), 'w') as out:
pickle.dump(clf, out)
객체 직렬화(object serialization)와 모델 저장을 위해 여기서는 pickle을 사용합니다. 도커 컨테이너의 output 폴더에 있을 것입니다. 그리고 나중에는 Amazon S3로 옮겨질 것입니다. 이 코드는 train파일에서 몇 줄 밖에 되지 않습니다. 하지만 여러분이 Amazon SageMaker에서 Scikit 모델을 빌드해야 할 경우 대단히 중요합니다.
도커를 위한 추론 코드 빌드
훈련 작업(training job)을 수행하는 동안 실행되는 train 코드 외에, 컨테이너에 추론 코드(inference code)를 추가해봅시다. 이 코드는 predictor.py에 담겨 있습니다. 이 코드는 SageMaker의 엔드포인트와 연결하려고 할 때 사용됩니다.
우선 라인 30-31을 보시기 바랍니다. 이 코드는 모델을 불러온 결과를 확인하는 역할을 합니다.
with open(os.path.join(model_path, 'decision-tree-model.pkl'), 'r') as inp:
cls.model = pickle.load(inp)여기서 중요한 점은 pickle 파일의 이름이 올바르게 되어있는지 확인하는 것입니다. 위의 예에서는 train 파일의 코드 내에 decision-tree-model.pkl로 되어 있습니다. 따라서 이 이름과 동일한 지 확인합니다.
다음으로 라인 42-43에 중요한 코드가 있습니다. 이 코드는 실제로 예측을 수행하는 역할을 합니다.
clf = cls.get_model()
return clf.predict(input)이 코드에서 따로 변경할 사항은 없습니다. 하지만, 실제 예측 함수에서Scikit 모델을 어떻게 불러와서 사용하는지는 대단히 중요합니다.
끝으로, 입력 데이터를 모델이 어떻게 불러오는지 알아봅시다. 이 부분은 라인 67-69에 있습니다.
data = flask.request.data.decode('utf-8')
s = StringIO.StringIO(data)
data = pd.read_csv(s, header=None)
이 부분도 어쩌면 가장 중요한 부분 중 하나일 수 있겠네요. 왜냐하면, 데이터를 로딩하는 방식이 대부분의 데이터 과학자가 통상적인 워크플로우에서 사용하는 것과는 다르기 때문입니다. 여기서 데이터는 Flask 프레임워크를 통해서 얻게 되어 있습니다. 이는 메모리상에서 객체를 파일처럼 처리하고 (StringIO), read_csv 함수를 이용하는 Pandas 라이브러리로 데이터를 읽어들일 수 있다는 것을 의미합니다. 데이터 자체는 CSV 포맷으로 Flask에 HTTP POST 방식으로 전달됩니다.
이제, 76 라인의 코드에서 예측 결과를 얻을 수 있습니다:
predictions = ScoringService.predict(data)끝으로, 라인 79-83 의 코드를 이용하여 예측 결과를 CSV 파일로 리턴합니다:
out = StringIO.StringIO()
pd.DataFrame({'results':predictions}).to_csv(out, header=False, index=False)
result = out.getvalue()
return flask.Response(response=result, status=200, mimetype='text/csv')보시다시피, 효과적으로 모델을 배포하기 위해 prediction.py에서 많은 것을 바꿀 필요는 없습니다. 입력 데이터만 적절하게 포맷을 맞췄는지, 훈련 단계에서 저장해놓은 pickle 파일을 그대로 다시 쓰고 있는지만 확인하면 됩니다.
컨테이너 빌드하기
앞에서 train 과 prediction.py 의 코드에 대해 자세히 알아봤으니, 이제 도커 컨테이너를 빌드하고 이 결과를 Amazon ECR로 올릴 수 있을 것입니다. 우선 다음 파일들을 포함한 디렉토리를 만듭니다.
decision_trees/
nginx.conf
predictor.py
serve
train
wsgi.py
이 디렉토리는 앞에서 설명한 프로그램 폴더입니다. 다시 한 번 강조하지만 prediction.py와 train 파일에 대해 특히 주목하시기 바랍니다. 나머지는 Amazon SageMaker의 sample notebook에 있는 것과 동일하므로 따로 편집을 할 필요는 없습니다. 자세한 것은 소스 코드를 참고하세요.
container/
decision_trees/
Dockerfile아울러, Dockerfile이라는 이미지를 어떻게 빌드하는지 Docker에게 알려줄 파일이 필요합니다. 이는 앞에서 만든 프로그램 폴더의 상위 컨테이너 폴더에 만듭니다. 이 파일에 대해 특별히 변경할 사항은 없습니다. 다만, 프로그램 폴더(이 글에서는 decision_trees 로 되어 있습니다)의 이름만 주의하시면 됩니다. 이 파일은 Amazon SageMaker의 sample notebooks에서 다운받을 수 있습니다.
이 외에도, build_and_push.sh 라는 이름의 도커 이미지를 빌드하기 위한 스크립트도 준비합니다. 이제 모든 것을 마련했으니 스크립트를 실행해봅시다.
빌드와 푸시 프로세스를 진행하기 위해, Amazon SageMaker 노트북 인스턴스에 있는 sample-notebooks 폴더에 있는 스크립트를 재활용 해보겠습니다. 일단 빌드 프로세스의 핵심부분을 확실히 이해하고 계신다면, 이 프로세스를 복제해서 이미 설치되어 있는 AWS CLI를 이용해서 여러분이 사용하고 있는 터미널 어디서든 해당 스크립트를 이용하여 빌드를 수행하실 수 있습니다. Jupyter Notebook에서 터미널 사용 방법은 아래 스크린샷을 참고하셔서 메뉴를 찾아서 클릭하시면 됩니다.

터미널을 실행시키고 나서, 다음과 같이 예제 컨테이너 폴더로 이동합니다.
cd ~/SageMaker/sample-notebooks/advanced_functionality/
scikit_bring_your_own/container
ls
ls decision_trees/여기서 build_and_push.sh 스크립트는 AWS CLI 환경 설정 정보로부터 리전(Region) 정보를 얻어냅니다. 리전 정보가 없을 경우, 기본값으로 us-west-2로 설정됩니다. 다음 명령어를 통해서 리전 정보를 변경할 수도 있습니다.
aws configure set region us-east-1
모델 훈련에 대해서는, Amazon SageMaker의 훈련 작업과 훈련용 컨테이너가 있는 리전과 동일한 리전에 훈련 데이터를 저장할 Amazon S3 버킷이 필요합니다. 추론(inference)에 대해서는, 여러분의 모델과 추론 컨테이너를 Amazon SageMaker를 사용할 수 있는 리전 중 원하는 리전 각각에 푸시해야 합니다. 예를 들어 지연시간을 줄이기 위해 SageMaker 엔드포인트를 여러 리전에 배포할 계획을 갖고 있다면, 그에 맞게 컨테이너를 여러 리전에 배포하는 것이 당연히 좋은 판단이라 하겠습니다.
프로그램 폴더 내에 있는 파일들이 실행 가능하도록, 빌드를 실행하기에 앞서 다음 명령어를 실행합니다.
chmod +x decision_trees/train
chmod +x decision_trees/servebuild_and_push.sh 스크립트도 실행 가능한 상태가 되어야 합니다. 아울러, 스크립트를 실행했을 때 이미지의 이름을 입력 인자로 받을 수 있어야 합니다. 이 글의 예제에서 이미지 이름은 decision_trees 입니다. 그리고 도커 이미지를 생성하고 이 결과를 Aamzon ECR로 푸시합니다.
chmod +x build_and_push.sh
./build_and_push.sh decision_trees

빌드와 푸시가 성공적으로 진행되었다면 위의 스크린샷과 같은 결과를 볼 수 있을 것입니다. 푸시는 다음과 같은 구조로 이뤄진 저장소 이름을 참조합니다.
<account number>.dkr.ecr.<region>.amazonaws.com/<image name>뿐만 아니라, Amazon ECR 안에 있는 decision-trees 이미지도 볼 수 있습니다. AWS Management Console로 로그인한 상태에서, Services 메뉴의 Compute 카테고리에 있는 Elastic Container Service(ECS)를 선택합니다. 그리고 화면 왼쪽에서 Repositories 메뉴를 클릭하면 decision-trees라는 Repository name을 볼 수 있을 것입니다. 이 이름을 선택하면 Repository URI 를 볼 수 있습니다. 아마도 build_and_push.sh 를 실행한 결과와 일치할 것입니다. 나중에 쓸 곳이 있으니 이 결과를 저장 해둡니다.
테스팅과 디버깅
빌드와 푸시는 build_and_push.sh 를 실행해서 한 번에 진행할 수 있습니다. 하지만 논리적으로는 Amazon ECR에 이미지를 푸시하기 전에, 도커 이미지 함수가 예상한대로 동작할지 확인하기 위한 테스트를 수행합니다. 예를 들어 테스트를 목적으로 빌드된 도커 이미지가 있다고 가정해봅시다. 다음과 같은 명령어를 실행하면 로컬 상에서 빌드된 도커 이미지 목록이 나옵니다. 아마도 이 글의 예제에서는 decision_trees 가 나타날 것입니다.
docker image ls
AWS는 Amazon SageMaker 상에서 모든 잡(job)과 엔드포인트를 생성하기 전에 컨테이너에 대해 로컬 테스트를 수행하는 샘플 스크립트를 제공하고 있습니다. 바로 다음과 같은 3개의 파일을 통해서 말이죠. (train_local.sh, serve_local.sh, predict.sh) 이 파일들은 local_test folder 폴더에서 확인할 수 있습니다(링크 참조). 이 글에서 소개하는 예제 관련 local_test 폴더와 동일한 구조를 지닌 local_test 폴더를 어디에든 다운받을 수 있습니다. 도커 컨테이너 내에 있는 /opt/ml에 여러분의 운영체제로부터 test_dir을 마운트하게 됩니다.
local_test/
test_dir/
input/
config/
hyperparameters.json
resourceConfig.json
data/
training/
iris.csv
model/
output/
payload.csv
predict.sh
serve_local.sh
train_local.shSageMaker 노트북 인스턴스 상에서 테스팅과 디버깅을 하기 위한 샘플 스크립트를 실행시키기 위해, local_test 폴더로 돌아가 봅시다.
cd ~/SageMaker/sample-notebooks/advanced_functionality/scikit_bring_your_own/container/local_test여기서 파일이 실행가능한 상태인지 확인하고, 필요하면 다음 명령어를 이용하여 변경 작업을 수행합니다.
chmod +x *.sh훈련을 위한 컨테이너 테스트
자, 이제 로컬 환경에서 빌드된 도커 이미지 상에서 훈련 작업(training job)을 시작합니다. ./test_dir/input/data/training/ 디렉토리 안에 있는 iris.csv 파일을 대상으로 train_local.sh 파일을 실행시킵니다. 아마 다음과 같은 명령어가 필요할 것 같습니다.
./train_local.sh decision_treeshyperparameters.json 과 resourceConfig.json에 대해 아무것도 없는 JSON 파일을 이용하여 훈련을 위한 로컬 테스트를 수행할 수 있습니다. 한편, 훈련 데이터가 있는 data/ 폴더 내에 training 용 채널을 확보해야 합니다. 훈련용 코드에서 이 모든 것들은 논리적으로 순서에 맞춰 수행됩니다. test_dir/input/ 폴더의 구조와 각종 파일들은 여러분의 모델 훈련용 코드에 맞게 조정되어 있을 것입니다.
로컬 테스트를 위해서는 데이터에서 아주 작은 일부만 샘플로 떼어내어 사용하시기 바랍니다. 전체 데이터는 실제 훈련 작업 (training job)에서 사용하시기 바랍니다. 스크립트가 성공적으로 실행되면, ./test_dir/model/ 디렉토리 내에 모델이 생성된 것을 확인할 수 있을 것입니다.

이제 스크립트 실행이 실패했을 경우 디버깅하는 방법도 알아보겠습니다. 우선 ./test_dir/input/config/ 폴더에 있는 hyperparameter.json 파일을 삭제합니다. 그러면 스크립트 실행이 실패할텐데, 이와 관련해서 디버깅과 문제 해결을 위한 상세 정보를 기록해놓은 결과가 ./test_dir/output/ 폴더에 파일 형태로 만들어질 것입니다.

추론을 위한 컨테이너 테스트
훈련이 문제없이 진행되었다면, 추론 코드를 이용하여 테스트도 수행해보도록 합시다. 우선 ./test_dir/model/ 폴더 안에 모델 파일이 있는지 확인합니다. 그런 다음, 로컬 환경에서 RESTful 서비스를 시작합니다. 이를 위해 다음과 같은 명령어를 이용합니다.
./serve_local.sh <image name> > output.log
Flask 애플리케이션의 모든 결과는 ./output.log 파일에 저장됩니다.
끝으로, 다른 터미널 창을 하나 더 연 다음, 다음 명령어를 이용하여 엔드포인트 코드를 테스트합니다.
./predict <payload file> [content-type]
content-type은 옵션이며, 기본 설정값은 text/csv입니다. 이제 ./output.log 파일을 열어서 작업이 제대로 완료되었는지 확인합니다.

모든 스크립트가 정상적으로 실행되면, Amazon SageMaker 상에서 훈련 작업을 배포할 준비가 된 것입니다. 그리고 나중에 컨테이너를 엔드포인트로 배포할 준비도 된 것입니다. 마지막 단계로 배포 환경을 깨끗하게 정리합니다. 우선 RESTful 서비스를 중단합니다. 만약 실행중인 도커 컨테이너가 있으면 다음 명령어를 이용하여 중단시킬 수 있습니다.
docker ps -a
docker kill <CONTAINER ID>
만약 여러분의 인스턴스 상에서 다른 도커 컨테이너가 동작 중이면, 특정 프로세스만 찾아서 해당 프로세스를 종료시키기 바랍니다.
Amazon SageMaker 콘솔을 이용한 훈련과 배포
훈련 작업 생성
도커 이미지를 만들었으니, 이제 훈련 코드와 추론 코드를 만들어봅시다. AWS Management Console로 가서, Services 메뉴의 Machine Learning 카테고리에 있는 Amazon SageMaker를 선택합니다. 그리고 화면 왼쪽에서 Jobs 메뉴를 클릭한 다음 Create training job버튼을 클릭합니다.
다음 스크린샷처럼 Create training job 창이 나타날 것입니다. 스크린샷을 참고해서 Job name을 decision-trees-<datetime> 형태로 입력합니다. 참고로 여기서 한 것처럼 잡 이름에 datetime을 추가하면 ResourceInUse라는 문제를 효과적으로 피할 수 있습니다. IAM role 항목에서는 Create a new role 또는 Enter a custom IAM role ARN 을 적절한 것을 선택합니다. 두 가지 경우 모두 AmazonSageMakerFullAccess와 AmazonS3FullAccess 정책이 포함되어 있어야 합니다. Algorithm 항목에서는 Custom을 선택합니다. 여기서는 Input Mode 항목에 대해 File로 설정합니다. 그리고 Training image 항목에 대해서는 여러분이 만든 도커의 Repository URI와 Image Tag 정보를 입력합니다(참고로 build_and_push.sh 파일을 통해 도커 이미지는 latest로 태깅됩니다).

스크롤을 아래로 내리면 Resource Configuration 항목이 나옵니다. 이 환경설정 항목은 다음 그림과 같이 공백으로 둡니다. 하지만 여러분의 모델을 만드는 데에는 아무 문제가 없으니 걱정하지 않으셔도 됩니다. 주요 환경설정 항목은 Instance Type으로, 인스턴스의 갯수를 지정하는 Instance count도 함께 체크하시기 바랍니다. Scikit 같은 몇몇 알고리즘들은 단일 인스턴스를 사용하는 것이 더 좋을 수 있습니다. 인스턴스 갯수를 더 크게 설정하더라도 여러대의 인스턴스에 알고리즘을 자동으로 확장시키지는 못합니다.
인스턴스 타입은 보통 m-계열, c-계열, p-계열 중 하나를 선택합니다. m-계열은 범용형 인스턴스로, 여러분의 모델을 훈련시키는 데 얼마나 많은 리소스가 필요한지 예상하기 어려울 경우 좋은 옵션입니다. c-계열은 많은 양의 계산이 필요한 작업에 적합합니다. 반면, p-계열 인스턴스는 GPU 리소스를 지원하며, 따라서 딥 러닝 관련 작업에 많이 사용됩니다. 여러분의 모델이 많은 리소스를 필요로 하는지에 대해서는 CloudWatch for SageMaker를 통해서 더 자세히 아실 수 있습니다.

이 작업에 대한 하이퍼파러미터는 Hyperparameters 박스에서 설정합니다. 이 예에서는 max_leaf_nodes만 설정하면 됩니다. 다음 스크린샷과 같이 설정하셔도 됩니다. 여러분의 알고리즘에 대해 더 많은 하이퍼파라미터를 설정하실 경우, 해당 사항들은 도커 이미지 내에 있는 train 파일로 모두 전달됩니다.

다음으로, Input data configuration 항목을 설정합니다. Channel name은 train 스크립트에서 작성한 것과 동일하게 맞춥니다. 보통 채널 이름과 입력 데이터가 잘 맞도록 S3 location값으로 입력하는 것이 좋습니다. 특히 여러 채널을 이용할 경우는 이 방법이 더 효과적입니다. train 프로그램이 데이터를 찾으려고 할 때 Amazon SageMaker는 사용하려는 컨테이너의 경로로 채널 데이터를 입력시킬 수 있습니다(예: /opt/ml/input/data/<channel_name>). 이 예제에서는 training 이라는 단일 채널을 사용합니다. 우리 모델이 사용할 입력 데이터는 CSV 포맷의 파일이고, 헤더 정보는 없으며, 첫번째 컬럼은 타겟 레이블로 되어 있어야 합니다. 이 예제에서 사용된 것처럼 여러분의 S3 location에 붓꽃 데이터셋(Iris dataset)을 자유롭게 업로드합니다. Done 버튼을 클릭하기 전에 전체적으로 한 번 더 확인하시기 바랍니다.

이 예제에서는, 다음과 같이 훈련 데이터 폴더가 만들어져 있을 것입니다.
![]()
끝으로, 훈련 작업이 완료된 다음 모델 아티팩트를 Amazon S3상에서 어디에 저장할 것인지 지정해야 합니다. 여기서 기억할 점이 있습니다. 모델 아티팩트 저장은 컨테이너내에 있는, 즉 /opt/ml/model/에 있는 모든 것을 다 가져와서 tar로 아카이빙 한 다음 gzip으로 압축하는 과정을 거칩니다. S3 output path 항목에 Amazon S3 버킷의 경로를 지정해줍니다.

다음으로, Create training job 버튼을 클릭합니다.
훈련 작업 생성이 완료되었으면, 여러분이 입력한 S3 output path에서 생성된 모델을 확인할 수 있습니다. 모델의 전체 경로는 다음과 같습니다.
s3://<bucket name>/models/<job name>/output/model.tar.gz
엔드포인트 배포
훈련 작업(training job)이 완료되고 나면, 프로덕션 환경에서 모델을 사용할 수 있도록 엔드포인트를 배포할 수 있습니다. 이 작업을 SageMaker의 콘솔에서 할 수 있는데, 다음과 같은 3가지 단계를 수행하면 됩니다: (1) 모델 리소스 생성, (2) 엔드포인트 환경 설정(endpoint configuration) 생성, 그리고 (3) 실제 엔드포인트 배포.
첫 단계로 모델 리소스 생성을 해보겠습니다. 여기에는 Amazon SageMaker가 도커 이미지에 대해 필요한 정보와 Amazon S3 내에서 모델 아티팩트의 위치 정보가 담겨 있습니다.
Amazon SageMaker 콘솔 화면에서 왼쪽 메뉴 중, Resources 항목의 Models를 선택합니다. 그런 다음Create model 버튼을 클릭합니다.
우선 Model name 항목에 대해 decision-trees같은 이름을 입력합니다. 그런 다음 IAM Role을 선택합니다 (필요하면 새로 생성하셔도 됩니다). 훈련 작업에서 사용한 것과 동일한 역할(role)을 사용해도 됩니다. AmazonSageMakerFullAccess 라는 IAM policy가 첨부되어 있으면 됩니다.

다음으로, 컨테이너에 대한 정보를 입력해야 합니다. 훈련 잡(training job)에서 사용했던 것과 동일한 컨테이너를 사용해도 됩니다. Location of inference code image 항목에 대해, 컨테이너를 위해 앞에서 저장해 두었던 ECR URI를 입력합니다. 특히, 맨 뒤에 latest 태그 처럼 이미지 태그를 꼭 붙이시기 바랍니다. 그런 다음, Location of model artifacts 항목에 대해 훈련 작업에서 생성했던 모델 아티팩트의 S3 URI를 입력합니다. 이 항목은 훈련 단계에서 설정했던 S3 output path 입니다.

자, 이제 Create model 버튼을 클릭합니다.
다음으로 엔드포인트 환경설정(endpoint configuration)을 생성합니다. 어떤 종류의 인스턴스를 프로비저닝할 지 결정하기 위해 모델의 리소스와 이 환경설정 정보를 함께 활용합니다. 물론 A/B 테스팅을 위해 하나 이상의 모델을 지정할 때 이 환경설정 정보를 이용할 수도 있습니다. 이 예제에서는 하나의 모델만 사용하겠습니다.
왼쪽 메뉴 중 Resources 항목의 Endpoint configuration메뉴를 클릭합니다. 그리고 Create endpoint configuration 버튼을 클릭합니다.
Endpoint configuration name 항목에 엔드포인트 환경설정 이름을 입력합니다. 똑같은 모델로 다양한 버전을 만들지 않을 계획이라면, 모델에 대해 동일한 이름을 입력합니다(이 예에서 decision-trees 를 사용한 것처럼 말이죠). 다음으로 왼쪽 메뉴에서 Add model 링크를 클릭합니다. 방금 생성한 모델을 선택하고, Save를 클릭합니다. 이 예제에서 기본값으로 설정된 기타 항목들은 그대로 둡니다.

Create endpoint configuration 버튼을 선택합니다.
이제 모델과 엔드포인트 환경설정 정보를 확보했으니, 실제 엔드포인트를 배포할 준비가 되었습니다. 엔드포인트를 활성화하면 인스턴스의 프로비저닝이 이루어집니다. 엔드포인트가 활성화되어 있으면 비용이 계속 과금될 수 있습니다. 따라서 직접적인 트래픽이 필요한 경우에만 엔드포인트를 활성화 해놓는 것이 중요합니다.
왼쪽 메뉴에서, Resources 항목의 Endpoints를 선택합니다. 그런 다음 Create endpoint 버튼을 클릭합니다.
Endpoint name 항목에 엔드포인트 이름을 입력합니다. 다양한 버전없이 단일 모델로 배포할 경우 모델 이름을 그대로 사용합니다. 이 예제에서는 decision-trees를 사용합니다. Use an existing endpoint configuration은 선택된 상태 그대로 둡니다.
Endpont configuration 항목에 대해서는 앞에서 생성한 엔드포인트 환경설정 결과를 선택합니다. 그런 다음 Select endpoint configuration 버튼을 클릭합니다. 끝으로, Create endpoint 버튼을 클릭합니다.

결과는 다음과 같습니다.

AWS CLI를 이용한 훈련과 배포
훈련 작업 생성
다음 명령어를 이용하여 AWS CLI 상에서 작업이 생성 가능합니다.
aws sagemaker create-training-job
--training-job-name <job name>
--algorithm-specification
TrainingImage=<Repository URI>:<Image Tag>,TrainingInputMode=File
--role-arn <Role ARN>
--input-data-config
'{"ChannelName":"training",
"DataSource":{"S3DataSource":{"S3DataType":"S3Prefix",
"S3Uri":"s3://<bucket name>/data/training/",
"S3DataDistributionType":"FullyReplicated"
}
}
}'
--output-data-config
S3OutputPath=s3://<bucket name>/models/
--resource-config
InstanceType=ml.m4.xlarge,InstanceCount=1,VolumeSizeInGB=1
--stopping-condition
MaxRuntimeInSeconds=86400
--hyper-parameters
max_leaf_nodes=5 이 명령어는 Amazon SageMaker 콘솔에서 생성했던 것과 동일한 환경 설정 정보를 이용해서 동일한 작업을 생성합니다. 여기서 작업의 이름만 다릅니다 (이건 고유값이므로). 결과값 중 TrainingJobArn은 작업이 성공적으로 만들어졌다는 것을 나타냅니다. Amazon SageMaker 콘솔의 Jobs 페이지에 가면 훈련 잡(training job)의 상태를 확인할 수 있습니다.

input-data-config 에 대해 채널 객체의 배열을 사용할 수 있습니다. 예를 들어, 훈련 채널이 정의되어 있으면 이것을 첨부 하기만 하면 다른 채널로 제공할 수 있습니다. 다른 2개의 객체를 따로따로 분리해서 말이죠. hyper-parameters는 KeyName1=string, KeyName2=string 형태로 최대 100개의 하이퍼파라미터를 사용할 수 있습니다. 예를 들면, max_depth를 정의했으면, max_leaf_nodes=5 바로 뒤에 max_depth=10 을 첨부할 수 있습니다. AWS CLI를 이용한 훈련 잡 생성에 관한 더 자세한 사항은 aws.sagemaker.create-training-job 과 Using Shorthand Syntax with the AWS Command Line Interface 자료를 참고하시기 바랍니다.
이 외에도, S3OutputPath 에는 Amazon SageMaker 콘솔과 AWS CLI를 통해서 생성된 훈련 잡(training job)이 모두 포함되어 있음을 알 수 있을 것입니다.

엔드포인트 배포
SageMaker 엔드포인트 배포는 3가지 AWS CLI 명령어를 가지고 수행할 수 있습니다. 각각의 명령어에 대한 실행 예상 결과도 제공됩니다.
aws sagemaker create-model
--model-name <model name>
--primary-container
Image=<Repository URL>:<Image Tag>,ModelDataUrl=s3://<bucket name>/models/<job name>/output/model.tar.gz
--execution-role-arn <Role ARN>

aws sagemaker create-endpoint-config
--endpoint-config-name <endpoint config name>
--production-variants
VariantName=dev,ModelName=<model name>,InitialInstanceCount=1,InstanceType=ml.m4.xlarge,InitialVariantWeight=1.0

aws sagemaker create-endpoint
--endpoint-name <endpoint name>
--endpoint-config-name <endpoint config name>성공적으로 생성되면 엔드포인트의 Status가 InService로 나타날 것입니다.

추론 테스트
엔드포인트를 테스트는 SageMaker 노트북 인스턴스에서 수행하면 가장 쉽게 할 수 있습니다. 노트북 셀(cell)에서 다음 코드를 실행합니다.
import boto3
import io
import pandas as pd
import itertools
# Set below parameters
bucket = '<bucket name>'
key = 'data/training/iris.csv'
endpointName = 'decision-trees'
# Pull our data from S3
s3 = boto3.client('s3')
f = s3.get_object(Bucket=bucket, Key=key)
# Make a dataframe
shape = pd.read_csv(io.BytesIO(f['Body'].read()), header=None)
# Take a random sample
a = [50*i for i in range(3)]
b = [40+i for i in range(10)]
indices = [i+j for i,j in itertools.product(a,b)]
test_data=shape.iloc[indices[:-1]]
test_X=test_data.iloc[:,1:]
test_y=test_data.iloc[:,0]
# Convert the dataframe to csv data
test_file = io.StringIO()
test_X.to_csv(test_file, header=None, index=None)
# Talk to SageMaker
client = boto3.client('sagemaker-runtime')
response = client.invoke_endpoint(
EndpointName=endpointName,
Body=test_file.getvalue(),
ContentType='text/csv',
Accept='Accept'
)
print(response['Body'].read().decode('ascii'))이 코드는 데이터 파일에서 샘플 데이터를 랜덤으로 추출해서 엔드포인트에 전달합니다. 그리고 결과도 화면에 출력해줍니다.
결론
이렇게 해서 여러분은 Amazon SageMaker에서 Scikit 모델을 빌드하고, 훈련시키고, 테스트하는 과정을 모두 배우고 익혔습니다. 여러분만의 모델에 더 적합하도록 워크플로우와 코드를 자유롭게 수정해서 활용해보시기 바랍니다.
이 글은 AWS Machine Learning 블로그의 Train and host Scikit-Learn models in Amazon SageMaker by building a Scikit Docker container의 한국어 번역으로, 남궁영환 AWS 솔루션즈 아키텍트께서 수고해 주셨습니다.
Source: Amazon SageMaker 기반 컨테이너를 활용한 Scikit-Learn 모델 훈련 및 호스팅 방법

Leave a Reply