Amazon SageMaker BlazingText: 다중 CPU/GPU상에서 Word2Vec 알고리즘의 병렬 처리
이 글에서는 Amazon SageMaker에서 제공하는 알고리즘 중 2018년 1월에 출시된 BlazingText를 소개하고자 합니다. BlazingText는 Word2Vec임베딩을 생성하기 위한 비지도 학습 알고리즘입니다. 여기서 말하는 임베딩이란 대규모 코퍼스(말뭉치)에 있는 단어들이 밀집되어 있는 벡터를 의미합니다. 다음과 같은 환경에서 Amazon SageMaker를 사용하실 경우, BlazingText를 이용해서 Word2Vec을 빠르게 구현할 수 있습니다:
- (Mikolov의 Word2Vec C버전, fastText 같은 알고리즘을 위한) 단일 CPU 인스턴스
- P2, P3 처럼 다중 GPU로 구성된 단일 인스턴스
- (분산 CPU 트레이닝을 위한) 다중 CPU 인스턴스
p3.2xlarge (1 Volta V100 GPU) 인스턴스 1대 상에서BlazingText와 c4.2xlarge 인스턴스 1대 상에서 fastText 와 비교하면 BlazingText가 약 21배 빠르고 비용면에서도 20% 가량 저렴합니다. 여러개의 CPU 노드로 구성된 분산 트레이닝의 경우 BlazingText는 c4.8xlarge 인스턴스 8대에서 최대 초당 5천만 단어까지 학습 속도를 낼 수 있는데, 이는 c4.8xlarge 인스턴스 1대에서 fastText의 CPU 버전과 비교하면 임베딩의 퀄리티에 영향을 거의 주지 않으면서도 속도면에서 약 11배나 빠른 결과입니다.
Word2Vec
만약 여러분이 리오넬 메시(Lionel Messi)를 검색할 경우 ‘축구’, ‘바르셀로나’같은 검색어에 대해 검색엔진은 어떤 결과를 내주나요? 단어들 간의 관계를 명확하게 정의하지 않은 상태에서 머신이 텍스트 데이터를 이해하게 하고 , 이를 통해 분류, 클러스터링을 효율적으로 할 수 있도록 하려면 어떻게 해야할까요? 이에 대한 답은 단어의 뜻, 의미론적 관계, 그리고 해당 단어가 어떤 유형의 맥락으로 사용되었는지 등이 담긴 단어의 표현을 만드는 데 있습니다.
Word2Vec은 비지도 학습을 이용하여 대규모 코퍼스에서 단어의 고밀도 벡터 표현을 생성하는 데 널리 사용되는 알고리즘입니다. 단어들 간의 의미론적 관계를 잡아낸 결과는 벡터로 표현됩니다. 이 벡터는 감성 분석, NER (Named Entity Recognition), 기계 번역 같은 여러가지 자연어 처리 (NLP) 애플리케이션 영역에서 광범위하게 사용됩니다.
어떻게 구현했는지 자세히 알아보겠습니다. 3가지 서로 다른 아키텍처를 위해 알고리즘을 어떻게 사용했는지에 대해서는 이 블로그의‘시작하기’섹션을 참고하시기 바랍니다.
모델링
Word2Vec은 단어에 대해 고밀도 벡터 표현을 학습하는 뉴럴 네트워크 알고리즘입니다. 단어 표현을 학습하는 딥 뉴럴 아키텍처, RNN 아키텍처가 많이 있지만, 이들은 Word2Vec과 비교했을 때 학습에 상당히 많은 시간을 필요로 합니다. Word2Vec은 비지도 학습 방식으로 (모델의 파라미터인) 학습된 고밀도 임베딩 벡터 관점에서 단어를 (neighbor라고 부르는) 주변의 단어로부터 해당 단어를 직접적으로 예측합니다.
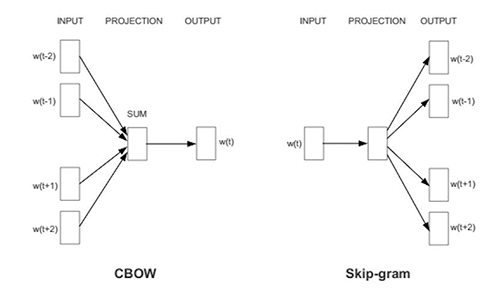
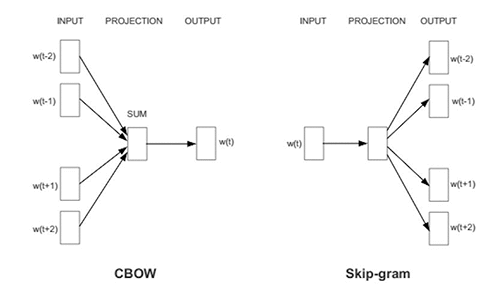
Word2Vec은 CBOW (Contextual Bag-Of-Words)와 SGNS (Skip-Gram with Negative Sampling)의 두 가지 모델 아키텍처로 제공됩니다. CBOW는 어떤 컨텍스트가 주어진 조건 하에서 단어를 예측하는 반면, skip-gram은 어떤 단어가 주어졌을 때 해당 단어의 컨텍스트를 예측합니다. skip-gram은 성능이 좋긴 하지만 속도가 느린 단점이 있습니다.
Word2Vec의 최적화는 문제를 반복적으로 해결하는 SGD (Stochastic Gradient Descent)를 사용해서 이뤄집니다. 매 수행 단계에서, 윈도우 또는 임의의 네거티브 샘플로부터 입력 단어와 타겟 단어 한 쌍(pair)을 선택합니다. 다음으로 선택된 두 단어에 대한 목적 함수(objective function)의 그래디언트 값을 계산합니다. 계산된 그래디언트 값을 기반으로 두 단어의 단어 표현을 업데이트합니다. 그런 다음 알고리즘은 다른 단어 쌍을 선택하여 다음 번 반복 수행을진행합니다.
Multi-core 아키텍처와 Many-core 아키텍처 상에서 분산 트레이닝
SGD의 주요 문제점 중 하나는 순차적이라는 것입니다. 임의의 반복 수행 단계에서 얻은 업데이트 결과와 그 다음 반복 수행 단계에서 이뤄지는 계산 간에 종속성이 존재합니다(동일한 단어 표현을 다루는 경우가 발생할 수 있죠). 이러한 이유에서 각 반복 수행은 이전 반복 수행의 업데이트가 완료될 때까지 대기하고 있어야 합니다. 결국 하드웨어의 병렬 리소스 사용이 불가능할 수 밖에 없습니다.
HogWild 병렬 SGD
HogWild는 서로 다른 쓰레드가 서로 다른 워드 페어를 병렬로 처리하는 기법으로, 모델 업데이트 단계에서 발생할 수 있는 충돌 상황(conflicts)은 무시해버립니다. 이론적으로는, 순차적으로 실행되는 경우와 비교했을 때 이렇게 하면 알고리즘의 수렴 비율을 줄일 수 있습니다. 아울러, HogWild 기법은 쓰레드를 통한 업데이트가 동일한 단어가 아닐 경우 잘 동작하는 것으로 알려져 있습니다. 즉, 대규모의 어휘집에 대해 충돌 상황이 상대적으로 매우 적게 나타나며 따라서 알고리즘의 수렴에도 영향이 별로 없습니다.
HogBatch 병렬 SGD
Word2Vec을 구현한 결과 대부분은 단일 노드, 멀티-코어 CPU 아키텍처에 최적화되어 있습니다. 하지만, 이들은 HogWild 업데이트를 이용한 벡터-벡터 연산을 기반으로 하고 있습니다. 즉, 메모리도 많이 필요로 하고 계산 리소스도 비효율적으로 사용합니다.
Shihao Ji 연구팀은 알고리즘에서 다양한 데이터 구조를 재사용하는 부분을 향상시킨 HogBatch 기법을 소개했습니다. 이 기법은 미니배치와 네거티브 샘플 공유 등으로 구성되어 있습니다. 이를 통해 매트릭스 곱셈 연산 (level3 BLAS)을 이용해서 문제를 표현할 수 있게 해줍니다. CPU 상에서 Word2Vec 알고리즘의 확장성을 지원하기 위해, BlazingText에서는 HogBatch를 이용합니다. 이를 통해 컴퓨트 클러스터 내의 여러 노드를 이용하는 분산형 계산 작업이 가능해집니다.
GPU 상에서 Word2Vec 스케일 확장
멀티 코어(multi-core) 및 단일 코어 여러 개로 구성된(many-core) 아키텍처에서 Word2Vec에 대한 HogWild/HogBatch 방식이 잘 동작함을 알 수 있었습니다. 이를 통해 이 알고리즘을 GPU에서 활용할 수 있다고 생각해볼 수 있겠습니다. GPU는 CPU보다 훨씬 더 큰 규모로 병렬 처리를 제공합니다. Amazon SageMaker BlazingText에서는 GPU를 사용하여 Word2Vec를 더 빠르게 처리하는 효율적인 병렬화 기술을 제공합니다. 이 버전에서는GPU 병렬성을 최대한 활용하여 출력 정확도에 영향을 미치지 않으면서도 CUDA 멀티 스레딩 기능을 최적으로 활용하도록 설계 되었습니다. 병렬 처리 수준과 동기화 수준 사이의 트레이드오프를 잘 관리할 수 있도록 해야 합니다. 이를 통해서여러 스레드가 동일한 단어 벡터에 대해 동시에 읽기 및 쓰기를 수행 하지 않도록 말입니다. 이는 트레이닝 과정의 속도를 높이는 동시에 정확도도 잘 유지할 수 있게 합니다.
BlazingText는 데이터 병렬 처리 방식을 사용하여 Word2Vec이 여러 개의 GPU를 활용할 수 있게 해줍니다. 뿐만 아니라 GPU에서 모델 가중치를 효율적으로 동기화 시켜줍니다. GPU 버전에 대한 자세한 내용은 BlazingText 문서를 참조하시기 바랍니다.
BlazingText의 단일 인스턴스 모드에서는 HogWild (CBOW 및 skip-gram) 및 HogBatch (batch_skipgram)를 모두 지원합니다. 하지만 분산 CPU 모드에서는 HogBatch skip-gram (batch_skipgram)을 지원합니다.
다음 표를 통해 Amazon SageMaker BlazingText의 다른 아키텍처에서 지원되는 모드를 요약 한 결과를 확인해보십시오.
| Hardware type / Mode | CBOW | skip-gram | batch_skipgram |
| Single Instance (CPU) | ✔ | ✔ | ✔ |
| Distributed (CPU) | ✔ | ||
| Single Instance (1 or more GPUs) | ✔ | ✔ |
Amazon SageMaker 상에서 BlazingText의 성능
Amazon SageMaker BlazingText를 (서브워드 임베딩 없는) fastText CPU 버전과 비교하여 벤치마크 테스트를 수행 했습니다. 표준 단어 유사도 테스트셋인 WS-353에서 처리량 (단위: 백만 단어/초)과 학습된 임베딩 결과의 정확도를 결과로 정리했습니다.
하드웨어: 모든 실험은 Amazon SageMaker에서 수행 했습니다. BlazingText에 대해서는 단일 GPU 인스턴스 (p3.2xlarge, p2.xlarge, p2.8xlarge, p2.16xlarge) 및 단일 CPU 인스턴스/다중 CPU 인스턴스 (c4.2xlarge 및 c4.8xlarge) 상에서의 성능 측정 결과를 정리했습니다. BlazingText는 GPU 인스턴스에서는 CBOW 및 skip-gram 모드를 사용해서 실행되었고, CPU 인스턴스에서는 batch_skipgram을 사용하여 실행 되었습니다. 단일 CPU 인스턴스에서는 CBOW 및 skip-gram을 사용하여 fastText를 실행 시켰습니다.
BlazingText 성능은 CBOW 와 skip-gram을 사용하는 단일 CPU 인스턴스의 fastText와 유사합니다. 따라서, 이와 관련된 결과는 생략했습니다.
학습용 코퍼스: One Billion Word Benchmark dataset 에서 모델을 훈련시켰습니다.
하이퍼 파라미터(모든 실험에 대해 적용): CBOW, skip-gram 및 batch_skipgram 모드 (네거티브 샘플링 포함) 및 fastText의 기본 파라미터 설정 (벡터 크기 = 100, 윈도우 크기 = 5, 샘플링 임계치 = 1e-4, 학습율 초기값 = 0.05).

One Billion Word Benchmark 데이터셋 기준 성능(Throughput) 비교(Million Words/Sec)
위의 결과서 알 수 있듯이, 하드웨어 타입이 동일한 경우 CBOW, batch_skipgram, skip-gram 순서대로 빠른 속도를 보여주고 있습니다. 하지만 정확도 면에서는 CBOW가 가장 좋은 결과를 내지는 못했습니다. 아래의 버블 차트를 보면 조금 더 명확하게 알 수 있을 것입니다.

BlazingText 벤치마크테스트 – 학습 단계에서는 One Billion Words Benchmark 데이터셋을 사용. 평가 단계에서는WS-353 데이터셋을 사용
버블 차트의 각 원(circle)은 여러가지 알고리즘과 하드웨어 설정을 바탕으로 한 BlazingText, fastText 학습 작업의 성능을 나타냅니다. 원의 크기는 쓰루풋 값에 비례합니다. 차트에 나와 있는 잡 번호에 관련된 다른 작업의 결과들을 다음과 같이 표로 정리했습니다. BlazingText는 다중 GPU를 사용할 수 있고 다중 CPU 상에서 분산형 계산 작업이 가능하기 때문에, fastText보다 속도가 몇 배 빠를 수 있습니다. 하지만, 가장 좋은 인스턴스 환경을 선택하기 위해, 임베딩(정확도)의 퀄리티, 쓰루풋, 비용 간의 균형을 잘 맞추는 것이 무엇보다 중요합니다. 이는 버블 차트를 통해서도 파악할 수 있습니다.
| Job No. | Implementation | Instance | Instance Count | Mode | Throughput in Million words/s | Accuracy | Cost ($) |
| 1 | fastText | ml.c4.2xlarge | 1 | skip-gram | 1.05 | 0.658 | 1.24 |
| 2 | fastText | ml.c4.8xlarge | 1 | skip-gram | 3.49 | 0.658 | 1.67 |
| 3 | fasttext | ml.c4.2xlarge | 1 | CBOW | 3.62 | 0.6 | 0.41 |
| 4 | fasttext | ml.c4.8xlarge | 1 | CBOW | 12.36 | 0.599 | 0.63 |
| 5 | blazingtext | ml.p2.xlarge | 1 | skip-gram | 2.58 | 0.655 | 1.25 |
| 6 | blazingtext | ml.p2.8xlarge | 1 | skip-gram | 11.82 | 0.635 | 3.1 |
| 7 | blazingtext | ml.p2.16xlarge | 1 | skip-gram | 23.52 | 0.613 | 4.49 |
| 8 | blazingtext | ml.p3.2xlarge | 1 | skip-gram | 22.16 | 0.658 | 0.97 |
| 9 | blazingtext | ml.p2.xlarge | 1 | CBOW | 9.92 | 0.602 | 0.44 |
| 10 | blazingtext | ml.p2.8xlarge | 1 | CBOW | 44.93 | 0.576 | 1.69 |
| 11 | blazingtext | ml.p2.16xlarge | 1 | CBOW | 79.16 | 0.562 | 2.89 |
| 12 | blazingtext | ml.p3.2xlarge | 1 | CBOW | 32.65 | 0.601 | 0.82 |
| 13 | blazingtext | ml.c4.2xlarge | 1 | batch_skipgram | 2.65 | 0.647 | 0.53 |
| 14 | blazingtext | ml.c4.2xlarge | 2 | batch_skipgram | 4.1 | 0.637 | 0.74 |
| 15 | blazingtext | ml.c4.2xlarge | 4 | batch_skipgram | 7.15 | 0.632 | 0.95 |
| 16 | blazingtext | ml.c4.2xlarge | 8 | batch_skipgram | 12.54 | 0.621 | 1.36 |
| 17 | blazingtext | ml.c4.8xlarge | 1 | batch_skipgram | 9.96 | 0.641 | 0.77 |
| 18 | blazingtext | ml.c4.8xlarge | 2 | batch_skipgram | 15.6 | 0.637 | 1.15 |
| 19 | blazingtext | ml.c4.8xlarge | 4 | batch_skipgram | 28.26 | 0.63 | 1.75 |
| 20 | blazingtext | ml.c4.8xlarge | 8 | batch_skipgram | 52.41 | 0.628 | 2.9 |
성능 테스트 결과에서 주목할 점
위의 표를 통해서 알고리즘과 하드웨어 구성 조합에 따른 장단점을 전체적으로 확인할 수 있지만, 몇 가지 눈여겨 볼만한 것들을 다음과 같이 정리 해보았습니다.
- Job 1 과 Job 8: p3.2xlarge (Volta GPU) 인스턴스 상에서 BlazingText는 정확도와 비용 면에서 가장 좋은 성능을 보였습니다. (c4.2xlarge 인스턴스 상에서) fastText 보다 약 21배 빠르면서도 비용은 20% 저렴하고, 정확도는 거의 비슷한 성능을 보였습니다.
- Job 2 와 Job 17: CPU 상에서 batch_skipgram기반의 BlazingText의 경우, skip-gram기반의 fastText와 비교했을 때 정확도 면에서 근소한 차이를 보였지만 속도면에서는 약 5배 빠르고 비용은 50% 저렴한 성능을 나타냈습니다.
- Job 17-20 (4개): 데이터셋이 아주 큰 경우 (50GB 이상) 다중 CPU 인스턴스 상에서 batch_skipgram을 이용하는 BlazingText를 쓰시기 바랍니다. 인스턴스의 개수증가 대비 처리 속도가 선형적으로 증가하는 결과를 내줍니다. 정확도 면에서도 거의 차이가 없습니다. NLP 애플리케이션에 따라 차이는 있겠지만 이 정도는 허용 가능한 수준으로 볼 수 있습니다.
실행해 보기
BlazingText는 텍스트 문서를 기반으로 모델을 학습시키고 Word-to-Vector 맵핑 결과가 포함된 파일을 리턴합니다. 기타 다른 Amazon SageMaker 알고리즘처럼, 학습 데이터와 모델 결과물을 저장하기 위해 Amazon Simple Storage Service (Amazon S3)를 이용합니다. Amazon SageMaker는 학습이 진행되는 동안 여러분의 Amazon Elastic Compute Cloud (Amazon EC2) 인스턴스를 자동으로 시작하고 중단시킵니다.
모델 학습이 이뤄지고 나면, Amazon S3로부터 워드 임베딩 딕셔너리 결과를 다운로드 받을 수 있습니다. 기타 다른 Amazon SageMaker 알고리즘과는 달리, 이 모델은 엔드포인트로 배포를 할 수 없는데 이는 추론 작업이 단지 벡터 룩업(vector lookup) 정도 밖에 안 되기 때문입니다. Amazon SagkeMaker 워크플로우에 대한 전체적인 내용에 대해서는 Amazon SageMaker 문서를 참고하시기 바랍니다.
데이터 포맷팅
BlazingText에는 전처리 텍스트 파일이 필요합니다. 이 파일은 각 라인이 단일 문장으로 이뤄져 있고, 각 라인은 공백문자로 구분되어 있는 여러 개의 토큰으로 구성됩니다. 만약 여러개의 텍스트 파일을 사용하고자 할 경우 이들을 하나의 파일로 합쳐야 합니다. BlazingText에서는 텍스트 전처리를 수행하지 않습니다. 따라서 코퍼스에 “apple”과 “Apple”이 있을 경우 2개의 서로 다른 벡터가 생성됩니다.
훈련 작업 세팅
훈련 작업을 시작하려면, AWS SDK for Python (Boto3) 또는 AWS Management Console을 사용해야 합니다. 하드웨어 환경 변수와 하이퍼파리미터를 설정한 다음, Amazon S3상에 학습 데이터를 올릴 주소를 지정해야 합니다. BlazingText에서 사용하기 위해서는 학습 데이터에 “train” 채널이 반드시 포함되어 있어야 합니다.
관련 자료
더 필요한 정보는, BlazingText 관련문서를 참고하시기 바랍니다. 아울러 Amazon SageMaker 노트북 인스턴스 상에서 이 블로그에서 소개한 새로운 알고리즘을 직접 테스트해보고자 하실 경우에는 BlazingText 예제 노트북 을 참고하시기 바랍니다. 노트북에서는 여러분이 알고리즘을 사용할 수있는 다양한 모드와 더불어 사용자가 직접 제어할 수 있는 하이퍼파라미터를 제공합니다.
– Saurabh Gupta (AWS Deep Learning 응용 과학자), Vineet Khare (AWS Deep Learning 사이언스 매니저)
이 글은 AWS Machine Learning 블로그의 Amazon SageMaker BlazingText: Parallelizing Word2Vec on Multiple CPUs or GPUs를 남궁영환 AWS AI 전문 솔루션즈아키텍트가 한국어로 번역하였습니다.
Source: Amazon SageMaker BlazingText: 다중 CPU/GPU상에서 Word2Vec 알고리즘의 병렬 처리

Leave a Reply