AWS IoT Analytics 기반 시계열 데이터 QuickSight 시각화 방법
짧은 시간 안에 (예시: 수 초 이내) 크게 달라질 수 있는 사물인터넷(IoT) 데이터를 시각화하는 것은 패턴 탐색, 추세 및 주기성 분석, 잠재적 상관 관계 및 이상 징후 관찰 등을 위해 중요합니다. 시계열 시각화 기능은 이상 징후를 식별하고, 이를 기반으로 알림을 발생시키고, 여러 이해 당사자 간의(특히 데이터 소비자와 엔지니어링) 커뮤니케이션을 개선하는 데 유용합니다.
이 글에서는 시계열 분석에서 일반적으로 수행하는 아래 세 가지 작업을 소개합니다.
- 기본 AWS IoT Analytics 기능을 사용하여 원시 IoT 데이터를 처리하는 방법
- 시계열 데이터 세트를 쉽게 시각화할 수 있도록 타임스탬프 필드를 변환하는 방법 예시
- Amazon QuickSight를 사용한 IoT 시계열 데이터의 시각화 방법
이를 위해 실생활의 사용 사례를 사용하고 오픈 소스 데이터 세트를 활용합니다.
여기에서는 여러분이 QuickSight 비즈니스 분석 서비스뿐만 아니라 AWS IoT Core 및 AWS IoT Analytics 플랫폼에 대한 실무 경험이 있다고 가정합니다. 이 포스팅에서 소개하는 예제 전반에 걸쳐 AWS CLI(명령줄 인터페이스)를 사용하기 때문에 CLI를 처음 설정해야 한다면 이 지침을 따르십시오. 또한, 여러분이 IAM 자격 증명을 설정하고, Python 프로그램을 실행하여 IoT Core까지 메시지를 게시하는 방법을 알고 있다는 가정하겠습니다.
IoT 데이터 세트
IoT Analytics는 IoT 디바이스와 센서에서 생성된 데이터를 직접 모드와 배치 모드로 수집할 수 있습니다. 직접 수집 모드를 사용하는 경우, IoT Core 규칙 엔진은 페이로드를 IoT Analytics 채널에 즉시 라우팅합니다. 배치 수집 모드를 사용하는 경우에는 Amazon S3 버킷과 같은 JSON 리포지토리에서 데이터를 수집할 수 있습니다.
이 글에서는 오스트레일리아 멜버른 시가 AWS IoT Core를 거쳐 AWS IoT Analytics 채널에 제공하는 오픈 소스에서 데이터 세트를 일괄 수집합니다.
멜버른 시는 2014년에 Fitzroy Gardens와 Docklands Library 두 곳에서 조도와 습도, 온도를 측정하는 환경 센서를 설치했습니다. 수집된 데이터는 캐노피 커버가 도시 냉각에 미치는 영향을 더 잘 이해하고 그 결과를 전파하기 위해 사용되었습니다. 데이터는 시험 기간(2014년~2015년) 동안 8개 장소에서 5분마다 측정된 온도, 빛, 습도를 포함하는 센서 판독 값에서 수집되었습니다.
센서에서 수집된 원시 JSON 데이터를 활용하겠습니다. 다음은 Docklands Library에 설치된 센서에서 수집된 단일 JSON 페이로드 샘플입니다.
{
"boardid": "509",
"boardtype": "1",
"humidity_avg": "47.7",
"humidity_max": "47.7",
"humidity_min": "47.7",
"latitude": "-37.8199043",
"light_avg": "93.7",
"light_max": "93.7",
"light_min": "93.7",
"location": "Docklands Library",
"longitude": "144.9404851",
"mac": "0013a20040b31583",
"model": "ENV",
"rowid": "509-20141216210500",
"temp_avg": "13.9",
"temp_max": "13.9",
"temp_min": "13.9",
"timestamp": "2014-12-16T21:05:00.000"
}페이로드 검사 결과, 이 특정 센서에서 생성된 타임스탬프가 ISO 8601 형식(날짜 및 시간)이며 오스트레일리아/퍼스 표준 시간대임을 확인할 수 있습니다.
이 데모에서는 두 곳(Fitzroy Gardens와 Docklands Library)에 있는 센서에서 생성 데이터에서 처음 1,000개의 샘플 JSON 메시지를 사용합니다. 블로그에서 사용되는 모든 샘플 JSON 메시지는 여기에서 찾을 수 있습니다. 데이터 세트를 다운로드 하려면 마우스 오른쪽 버튼을 클릭한 다음 [다른 이름으로 저장]을 클릭하세요.
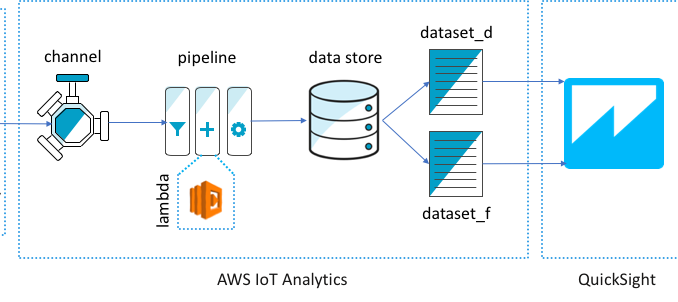
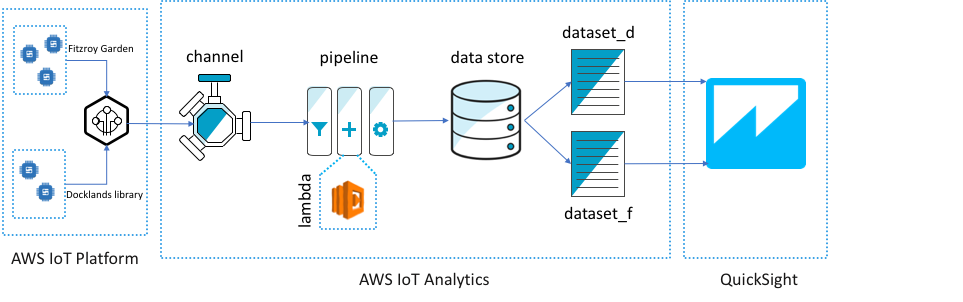
AWS IoT Analytics 아키텍처 개요

JSON 데이터는 MQTT 토픽 형태로 AWS IoT Core에 전송되고 여기에서 IoT 규칙 엔진을 통해 AWS IoT 채널로 전달됩니다. 날짜-시간을 다른 형식으로 변환하기 위한 Lambda 함수를 호출하는 파이프라인과 데이터를 저장하는 데이터 스토어를 만듭니다. 각 원본 위치에 하나씩 두 개의 데이터 세트가 생성되고, 시계열 데이터를 나타내는 QuickSight 시각화를 구성합니다. 전반적인 작업 흐름은 아래와 같습니다.
- 오픈 소스 파일의 원시 JSON 데이터를 AWS IoT Core에 게시
- 기존 오스트레일리아 ISO 8601 타임스탬프(예: 2014-12-16 21:05:00.000)에 따라 각 JSON 메시지 페이로드에 다음 사항 추가
- UTC 형식의 UNIX epoch 타임스탬프(1418677200)
- 미국 태평양 표준 시간대 ISO 8601 타임스탬프(12/15/2014 13:00:00.000)
- JSON 메시지를 단일 AWS IoT Analytics 데이터 스토어에 저장
- 데이터 스토어를 쿼리하고 두 센서 위치(Fitzroy Gardens와 Docklands Library)를 기준으로 데이터를 필터링하여 두 개의 AWS IoT Analytics 데이터 세트를 생성
프로덕션 워크로드는 AWS IoT Core를 무시하고 BatchPutMessage API를 사용하여 JSON 페이로드 데이터를 AWS IoT Analytics 채널에 직접 게시해야 할 수도 있는 점을 숙지하시기 바랍니다.
AWS IoT 데이터 수집, AWS IoT Analytics 및 QuickSight 시각화 단계
- 원본 페이로드를 보강하는 Lambda 함수를 생성하고 위에서 지정한 두 개의 시간 형식(UNIX epoch와 US PT)을 추가합니다.
- IoT Analytics 채널, 파이프라인 및 데이터 스토어를 생성합니다.
- 두 개의 IoT Analytics 데이터 세트를 생성합니다.
- Python 스크립트를 사용하여 JSON 파일의 원본 데이터를 IoT Core로 가져옵니다. 그러면 1단계에서 생성된 IoT Analytics 채널로 데이터를 전송하는 규칙이 트리거됩니다.
- 데이터 세트를 가져와 QuickSight에서 시계열 시각화를 생성합니다.
1단계
아래 코드를 사용하여 transform_pipeline이라는 Lambda 함수(Python 2.7)를 생성합니다.
import time
import sys
import pytz
import datetime as DT
from datetime import datetime
from pytz import timezone
def lambda_handler(event, context):
for e in event:
if 'timestamp' in e:
# Converting timestamp string to datetime object
d_aus_unaware = datetime.strptime(e['timestamp'],'%Y-%m-%dT%H:%M:%S.%f')
# Adding Australia/Perth timezone to datetime object
timezone_aus = pytz.timezone("Australia/Perth")
d_aus_aware = timezone_aus.localize(d_aus_unaware)
# Determining UTC epoch timestamp from input Australian timestamp
d_utc = d_aus_aware.astimezone(timezone('UTC'))
epoch = time.mktime(d_utc.timetuple())
# Determining PST timestamp from input Australian timestamp
d_uspst = d_aus_aware.astimezone(timezone('US/Pacific'))
# Adding Epoch and PST timestamp to message payload
e['timestamp_aus'] = d_aus_aware.strftime('%m/%d/%Y %T')
e['timestamp_us'] = d_uspst.strftime('%m/%d/%Y %T')
e['epoch'] = epoch
return event
위의 함수(transform_pipeline)는 패키지로 불러와야 하는 pytz 라이브러리를 사용합니다. 이 작업을 수행하는 방법에 대한 자세한 내용은 AWS Lambda 배포 패키지(Python) 페이지를 참조하십시오.
IoT Analytics에 위의 Lambda 함수를 호출할 수 있는 권한을 부여하기 위해 CLI를 사용합니다. statement-id는 여기에 설명된 대로 고유한 식별자입니다.
aws lambda add-permission --function-name transform_pipeline --statement-id stat_id_100 --principal iotanalytics.amazonaws.com --action lambda:InvokeFunction
2단계
IoT Analytics 채널, 파이프라인 및 데이터 스토어를 생성하려면 AWS 콘솔에 로그온하고 여기에 나와 있는 지침을 따르시면 됩니다. 또는 CloudFormation 템플릿을 사용하여 IoT Analytics 리소스를 생성할 수도 있습니다.
채널은 IoT Core 또는 S3 버킷에서 데이터를 수집하여 파이프라인에 제공하기 위해 사용합니다. 이때 원시 메시지의 복사본은 선택한 기간 동안 (또는 무기한) 유지됩니다.
여기에서는 가공되지 않은 원시 JSON 메시지와 수신 메시지를 저장하기 위해 mychannel_aus_weather라는 단일 채널을 생성하겠습니다. IoT Analytics 콘솔을 사용하여 mychannel_aus_weather 채널을 생성합니다. IoT Core 토픽에 대한 메시지가 표시될 때 iot/aus_weather를 사용하면 IoT Core에서 이 채널에 메시지를 전달하는 규칙이 생성됩니다. 콘솔을 통해 여기에 필요한 IAM 역할을 생성할 수 있습니다.
파이프라인은 수신되는 JSON 페이로드를 보강하거나 변환 혹은 필터링하는 데 사용합니다. 이 글에서는 데이터 원본을 mychannel_aus_weather 채널로 지정한 mypipeline_aus_weather라는 파이프라인을 생성합니다. 바로 전, 1단계에서 transform_pipeline이라는 Lambda 함수를 생성했습니다. 파이프라인에 Lambda 활동 하나를 추가하고 목록에서 이 함수를 선택하십시오.
파이프라인 생성 마무리 단계에서 파이프라인 출력용으로 사용할 데이터 스토어를 생성할 수 있습니다. 데이터 스토어는 파이프라인을 통해 처리된 데이터를 저장하는 데 사용됩니다. 이 글에서는 mydatastore_aus_weather라는 데이터 스토어를 생성하겠습니다.
3단계
CLI를 사용하여 데이터 스토어에서 데이터 세트를 생성해 보겠습니다. 콘솔을 사용하여 대화형으로 데이터 세트를 생성할 수도 있습니다.
Docklands Library 데이터 세트
aws iotanalytics create-dataset --dataset-name="aus_weather_docklands_library" --cli-input-json file://dataset_docklands.json해당 JSON 파일 내, 입력은 아래와 같습니다.
{
"actions" :[{
"actionName":"myaction1",
"queryAction":{
"sqlQuery":"select * from mydatastore_aus_weather where location = 'Docklands Library' order by timestamp_aus"
}
}]
}Fitzroy Gardens 데이터 세트
aws iotanalytics create-dataset --dataset-name="aus_weather_fitzroy_gardens" --cli-input-json file://dataset_fitzroy.json
해당 JSON 파일 내용은 아래와 같습니다.
{
"actions" :[{
"actionName":"myaction2",
"queryAction":{
"sqlQuery":"select * from mydatastore_aus_weather where location = 'Fitzroy Gardens' order by timestamp_aus"
}
}]
}timestamp_aus는 원본 데이터 세트에 없는 속성입니다. 이 속성은 Lambda 함수에 의해 각 JSON 페이로드에 추가되었습니다. 또한 QuickSight에서 이 속성에 대해 데이터를 순차적으로 표시할 수 있도록 order by 문이 추가되었습니다.
4단계
이전 단계에서 데이터 수집, 변환 및 시각화를 위한 구조를 설정했지만 아직 데이터가 없습니다. 이 단계에서는 오픈 소스 데이터 세트의 데이터를 IoT Core로 가져옵니다.
아래 코드를 사용하여 오픈 소스 데이터 세트에서 1,000개의 데이터 레코드를 다운로드합니다.
curl -XPORT 'https://data.melbourne.vic.gov.au/resource/277b-wacc.json' > input_aus.json오픈 소스 데이터 세트의 데이터를 IoT Core로 보내려면 먼저 CLI를 설정해야 합니다. Windows 또는 OS용 CLI를 설치하고 구성하는 방법은 여기에서 확인하세요.
구성 중에 AWS 사용자 ID와 연결된 AWS 액세스 키 및 AWS 보안 액세스 키를 입력하라는 메시지가 표시됩니다. 액세스 키를 가져오려면 AWS 콘솔로 이동하여 검색 표시줄에서 IAM(Identity Access Management)을 검색한 후 [users]를 선택하고 사용자 이름을 클릭합니다. 그런 다음 [security credentials]에서 [Create Access Key]를 선택하고 보안 액세스 키를 복사 및 저장해야 합니다.
IoT Core로 데이터를 가져오는 Python 함수를 작성하고 이름을 upload_raw_aus.py로 지정합니다.
import json
import boto3
import fileinput
import multiprocessing as mp
import os
processes = 4
# An array of boto3 IoT clients
IotBoto3Client = [boto3.client('iot-data') for i in range(processes)]
def publish_wrapper(lineID, line):
# Select the appropriate boto3 client based on lineID
client = IotBoto3Client[lineID % 4]
line_read = line.strip()
print "Publish: ", os.getpid(), lineID, line_read[:70], "..."
payload = json.loads(line_read)
# Publish JSON data to AWS IoT
client.publish(
topic='iot/aus_weather',
qos=1,
payload=json.dumps(payload))
if __name__ == '__main__':
pool = mp.Pool(processes)
jobs = []
print "Begin Data Ingestion"
for ID, line in enumerate(fileinput.input()):
# Create job for each JSON object
res = jobs.append(pool.apply_async(publish_wrapper, (ID, line)))
for job in jobs:
job.get()
print "Data Ingested Successfully"위의 Python 스크립트를 실행하기 전에 jq를 설치해야 합니다. Windows 머신을 사용하는 경우 여기에서 다운로드 지침을 확인하십시오.
sudo yum install jq이제 CLI를 사용하여 위의 함수를 호출하고, curl 명령을 사용하여 다운로드된 파일을 전달할 수 있습니다.
cat input_aus.json | jq -c '.[]' | python upload_raw_aus.py이 Python 스크립트는 네 개의 프로세스를 사용하여 데이터를 병렬로 수집합니다. 네 개의 IoT boto3 클라이언트가 생성되고 각 원시 JSON 메시지를 게시하는 작업이 라운드 로빈 형식으로 배포됩니다. MQTT 토픽 iot/aus_weather는 2단계에서 채널 구독에 대한 토픽 규칙을 생성할 때 사용한 토픽과 동일합니다.
위의 cat 스크립트를 실행한 후에는 QuickSight 시각화를 위해 두 개의 데이터 세트를 사용할 수 있게 됩니다.
5단계
AWS IoT Analytics가 시각화에 사용되는 다음 데이터 세트를 변환했습니다.
- aus_weather_docklands_library: Docklands Library에 대한 IoT 데이터를 포함합니다.
- aus_weather_fitzroy_gardens: Fitzroy Gardens에 대한 IoT 데이터를 포함합니다.
이제 QuickSight를 열고 시계열 시각화를 위한 작업을 구성하겠습니다.
QuickSight에서 [New analysis]를 클릭한 다음 [New data set]를 클릭합니다.
그런 다음 [AWS IoT Analytics]를 클릭합니다. QuickSight 분석에서는 두 데이터 세트(aus_weather_docklands_library, aus_weather_fitzroy_gardens)를 모두 추가해야 합니다. 일단 이 중에서 하나를 선택하고 [Create data source]를 선택합니다. aus_weather_fitzroy_gardens에 대해 위의 단계를 반복합니다. 이제 각 데이터 세트를 개별적으로 또는 함께 시각화할 수 있습니다.
이 포스팅에서는 두 개의 데이터 세트를 함께 시각화해 보겠습니다. 먼저 데이터 세트 하나를 클릭합니다. 여기에서는 ‘aus_weather_docklands_library‘를 사용합니다. [Create analysis]를 클릭합니다.

QuickSight 시각화 화면이 나타납니다. 이제 다른 데이터 세트(aus_weather_fitzroy_gardens)를 분석에 추가하겠습니다. aus_weather_docklands_library 데이터 세트를 클릭합니다. [Edit analysis data sets]를 클릭하면 다른 데이터 세트를 추가할 수 있는 팝업 블록이 나타납니다. 아래 다이어그램과 같이 aus_weather_fitzroy_gardens 데이터 세트를 추가합니다.

이제 두 데이터 세트 모두 분석으로 가져왔습니다.

필요한 모든 데이터가 분석에 포함되어 있으며 시각화 개발을 시작할 수 있습니다. 먼저 Docklands Library에 대해 epoch 대 humidity_avg, light_avg 및 temp_avg를 그려 보겠습니다. aus_weather_docklands_library 세트를 클릭합니다. 왼쪽 아래의 그래프 옵션에서 선 그림을 선택합니다. 그래프 위에서 epoch 필드를 X 축으로 끌고 humidity_avg, light_avg, temp_avg 필드를 Value 열로 끕니다.

각 값 필드에 대해 집계 유형을 [Average]로 선택합니다(기본값은 [Sum]).

이제 시간에 따른 습도, 온도 및 빛의 변화에 대한 시각화 구성을 완성했습니다. 그래프 아래의 파란색 창을 스크롤하거나 확장하여 서로 다른 시간 간격에 대한 시각 자료를 분석할 수 있습니다. 또한 그래프 제목을 클릭하면 제목을 변경할 수 있습니다.

동일한 방법으로 Fitzroy Gardens 데이터도 시각화할 수 있습니다. 왼쪽 위에서 + 버튼을 클릭하고 [Add visual]을 선택합니다. 기존 그래프 아래에 새 그래프가 비어 있는 상태로 추가됩니다. aus_weather_fitzroy_gardens 데이터 세트를 선택하면 aus_weather_docklands_library의 시각화를 구성한 것과 같은 방식으로 그래프를 생성할 수 있습니다. 아래 다이어그램은 최종 결과를 보여줍니다.

최종 결과는 다음과 같이 나타납니다.

두 시각화 모두 시간(가로) 축에 Epoch 시간 형식을 사용하므로 ISO 8601 형식을 사용하도록 변경해야 합니다. mm/dd/yyyy HH:MM:SS 형식으로 시간을 표시하는 timestamp_aus 열이 이미 추가되어 있습니다. 기본적으로 QuickSight는 이를 날짜 형식으로 처리합니다. 날짜 형식의 이 열에 대해 데이터(습도, 빛, 온도)를 표시하면 다음과 같은 시각화가 생성됩니다.

여기서 X 축의 측정 단위는 하루입니다. 샘플 데이터 포인트가 분 단위로 세분화되어 있으므로 여기서는 IoT 데이터를 정확하게 표현하지 못합니다. 데이터 레이블과 같은 수준의 정밀도를 얻으려면 날짜가 일반 날짜 형식이 아닌 문자열 형식이어야 합니다.
다음 단계를 수행하여 이 문제를 해결할 수 있습니다.
- timestamp_aus 필드의 형식을 날짜(date)에서 문자열(string)로 변경합니다.
- timestamp_aus 열을 기준으로 데이터를 사전식으로 정렬합니다. 데이터 세트 쿼리를 생성할 때 이 단계를 처리했습니다. 데이터 스토어에서 데이터 세트가 생성될 때 해당 데이터를 정렬하기 위해 아래와 같이 order by timestamp_aus가 쿼리에 포함되어 있습니다.
select * from mydatastore_aus_weather where location = 'Fitzroy Gardens' order by timestamp_aus
1단계를 수행하기 위해 데이터 세트 이름(aus_weather_docklands_library)을 클릭하고 [Edit analysis data sets]를 클릭합니다. aus_weather_docklands_library 옆에 있는 [Edit]를 클릭합니다. 이제 필요에 따라 모든 열을 편집할 수 있습니다. timestamp_aus 열을 클릭하여 데이터 형식을 문자열(string)로 변경합니다.

aus_weather_fitzroy_gardens 데이터 세트에 대해 이 프로세스를 반복합니다. 이제 UNIX epoch 타임스탬프로 그린 것과 같은 방식으로 그래프를 그릴 수 있습니다. X 축에 epoch 대신 timestamp_aus를 사용할 수 있습니다. 생성되는 그래프는 epoch 타임스탬프와 동일하지만 X 축에 ISO 8601 형식의 타임스탬프가 표시됩니다.

QuickSight에는 기존 데이터 필드에서 새 데이터 필드(열)를 생성하는 기능이 있습니다. 예를 들어 일별 데이터 및 월별 데이터를 나타내도록 위의 그림을 변경할 수 있습니다. 위의 그림을 보면 샘플 포인트가 2일(12/14/2014, 12/15/2014)에 걸쳐 확장됩니다.
새 계산 필드를 생성하여 각 그림을 2개(일별)로 나눌 수 있습니다. timestamp_aus 필드의 값이 ‘MM/DD/YYYY HH:MM:SS’ 문자열 형식인 경우, 12번째 문자에서 시작하여 5자까지 범위를 지정하면 시간과 분을 나타내는 하위 문자열(HH:MM)이 생성됩니다. 마찬가지로 첫 번째 문자에서 시작하여 10자까지 범위를 지정하면 날짜를 나타내는 하위 문자열(MM/DD/YYYY)이 생성됩니다. 이를 추출하여 HH:MM과 MM/DD/YYYY라는 두 개의 새 필드를 생성할 수 있습니다.
데이터 세트 이름(aus_weather_docklands_library)을 클릭하고 [Edit analysis data sets]를 클릭합니다. aus_weather_docklands_library 옆에 있는 [Edit]를 클릭합니다. 왼쪽에 있는 [Fields] 탭을 클릭한 다음 [New Field]를 클릭합니다.

먼저 timestamp_aus 필드에서 시간과 분을 가져오는 새 필드를 생성하겠습니다. 이를 위해 QuickSight에서 제공하는 substring()을 사용합니다. QuickSight 함수에 대한 자세한 내용은 지원되는 QuickSight 함수 페이지를 참조하십시오. substring을 클릭하고 새 필드의 이름을 HH:MM으로 입력합니다. 아래 다이어그램을 참조해서 같은 프로세스를 반복하고 일과 월을 MM/DD/YYYY라는 새 계산 필드로 가져옵니다.

맨 위에 있는 [Save and Visualize]를 클릭합니다. 이제 그래프를 생성할 준비가 되었습니다. 간단히 humidity_avg만 그려 보겠습니다. 선 그래프를 선택한 후 HH:MM을 X 축으로 끌고 humidity_avg와 MM/DD/YYYY를 각각 Value 열과 Color 열로 끕니다. 아래와 같은 시각화가 생성되어 각 날짜마다 하나씩 두 개의 humidity_avg 선 그림을 보여줍니다. aus_weather_fitzroy_gardens 데이터 세트에 대해 위의 단계를 반복합니다.
Docklands Library의 최종 결과

Fitzroy Gardens의 최종 결과

QuickSight는 위치 좌표(위도, 경도)가 제공될 경우 위치 맵에서 센서 위치를 표시할 때도 유용합니다. 위에서 구성한 데이터 세트에 이러한 속성이 포함되어 있습니다. 왼쪽 아래의 지구본 아이콘을 클릭하고 latitude 및 longitude 열을 클릭합니다.

이제 건물 층 별로 구성된 QuickSight 분석을 수행합니다. 시계열 데이터와 지역별 센서 위치를 표시하는 2개의 층을 구성하는 방법을 보여드렸습니다. 분석의 이름을 바꿔 보겠습니다. 맨 위의 분석 이름은 기본적으로 aus_weather_docklands_library로 지정되지만 이를 ‘Melbourne Weather Analysis’같은 다른 이름으로 변경할 수 있습니다. 새 분석 페이지에서 언제든지 분석에 액세스할 수 있습니다.

데이터를 시각화하면 이해 당사자 간의 커뮤니케이션을 개선하고 협업을 강화할 수 있습니다. QuickSight는 이해 당사자와 시각 자료를 공유할 수 있도록 대시보드라는 유용한 스냅샷 도구를 제공합니다. 대시보드 도구를 사용하여 시각 자료를 캡처하고 상태를 저장하는 중요 메커니즘을 지원할 수 있습니다. 이 도구를 통해 다른 활성 사용자와 시각 자료를 공유할 수 있습니다. 분석을 위한 대시보드를 생성하여 다른 QuickSight 사용자와 공유해 보겠습니다. 오른쪽에 있는 [share]를 클릭한 다음 [Create dashboard]를 클릭합니다.

[Create a dashboard] 페이지에서 대시보드에 지정할 이름(Melbourne IoT Weather Analysis)을 입력한 다음 [Create dashboard]를 클릭합니다.

다음 페이지에서 대시보드를 공유할 사용자의 이름 또는 이메일 주소를 입력합니다. 해당 사용자의 QuickSight 계정이 이미 등록되어 있어야 합니다. 아래 그림은 Pat라는 가상의 사용자를 입력하는 것을 보여줍니다. 사용자 이름/이메일이 유효하면 [Share]를 클릭할 수 있습니다. 공유할 필요가 없으면 [Cancel]을 클릭할 수 있습니다. 다음 페이지에서 사용자 옆에 있는 [Can create analyses]를 클릭하여 해당 사용자가 직접 분석을 생성하도록 허용할 수 있습니다. [Close]를 클릭합니다. 그리고 다음 페이지에서 [Confirm]을 선택하여 해당 사용자에게 데이터에 대한 액세스 권한을 부여합니다.

사용자에게 공유 대시보드 접속 링크가 포함된 이메일이 전송됩니다.

결론
이 글에서는 QuickSight를 사용하여 시계열 데이터와 위치 데이터를 시각화하는 방법을 단계별로 안내했습니다. 또한 AWS IoT Analytics를 사용하여 시각화를 위한 데이터 처리 방법도 소개했습니다.
여기에는 설명하지 않았지만 데이터와의 상호 작용과 시각화를 개선하기 위해 QuickSight에서 제공하는 시각 요소 관련 기능이 있습니다. 예를 들어 왼쪽에 있는 [Filter] 탭을 사용하면 데이터를 선택적으로 표시하고 노이즈를 제거할 수 있습니다. QuickSight는 선 그래프 외에도 다양한 종류의 그래프(막대 그래프, 원형 차트 등)를 지원합니다. 사용자가 기본 데이터 특성에 대해 잘 알고 있으면 더 유용하고 의미 있는 분석 모델과 시각화를 생성할 수 있습니다.
이 글에서는 특정 사용 사례에 대해 AWS IoT Analytics를 사용하여 데이터 흐름을 생성하는 방법을 보여주었습니다. 그러나 비슷한 사용 사례에 대해 플랫폼에서 생성할 수 있는 다양한 데이터 흐름을 이해하고, 이 중 하나를 선택할 때의 영향을 제대로 평가하는 것이 중요합니다. 다른 시각화 도구/서비스 사용 방법에 대한 자세한 내용은 이 블로그를 참고하시기 바랍니다.
궁금한 점이 있거나 QuickSight 시각화를 통해 생성한 대시보드를 공유하려면 당사 포럼을 방문하십시오.
이 글은 The Internet of Things on AWS – Official Blog의 Use AWS CodeDeploy to Implement Blue/Green Deployments for AWS Fargate and Amazon ECS의 번역본입니다.

Leave a Reply