


MySQL InnoDB의 Adaptive Hash Index 활용

개요
MySQL의 InnoDB에는 Adaptive Hash Index 기능이 있는데, 어떤 상황에서 효과가 있고 사용 시 반드시 주의를 해야할 점에 대해서 정리하도록 하겠습니다.
InnoDB B-Tree 인덱스
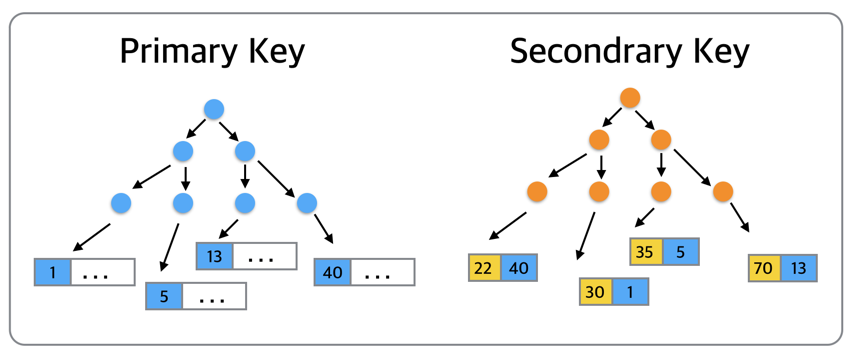
MySQL의 InnoDB의 대표적인 인덱스는 B-Tree입니다. 데이터는 Primary Key 순으로 정렬되어 관리되고, Secondrary Key는 인덱스키+PK를 조합으로 정렬이 되어 있습니다.
즉, 특정 데이터를 찾기 위해서는 Secondrary Key에서 PK를 찾고, 그 PK를 통해 다시 원하는 데이터로 찾아가는 형태로 데이터가 처리 됩니다.
트리의 가장 큰 강점은 데이터 접근 퍼포먼스가 데이터 증가량에 따라서도 결코 선형적으로 증가하지 않다는 점에 있습니다.
참고로, PK 접근 시 데이터 접근에 소요되는 비용은 O(logN)이고,두번 트리에 접근하는 Secondrary Key에 소요되는 비용은 2 * O(logN)입니다.

데이터가 아무리 많아져도, 데이터 접근에 소요되는 비용이 크게 증가되지 않음에도, 상황에 따라 효율이 좋지 않습니다. 자주 사용되는 데이터 탐색에도 매번 트리의 경로를 쫓아가야 한다는 것이죠. 게다가 Mutex Lock이 과도하게 잡히게 되면, 적은 데이터 셋에도 불구하고 DB 자원 사용 효율이 떨어지게 됩니다.
InnoDB Adaptive Hash Index
InnoDB에서는 앞서 언급한 상황을 해결하기 위해, InnoDB Adative Hash Index 기능이 있습니다. 자주 사용되는 칼럼을 해시로 정의하여, B-Tree 를 타지 않고 바로 데이터에 접근할 수 있는 기능이죠. “Adaptive”라는 단어에서 예상할 수 있겠지만, 모든 값들이 해시로 생성이 되는 것이 아니라, 자주 사용되는 데이터 값만 내부적으로 판단하여 상황에 맞게 해시 값을 생성합니다.


즉, 전체 데이터를 대상으로 해시값을 생성하지는 않는다는 말인데요,
Adative Hash Index에 할당되는 메모리는 전체 Innodb_Buffer_Pool_Size의 1/64만큼으로 초기화됩니다.
최소 메모리 할당은 저렇게 할당되나, 최대 사용되는 메모리 양은 알 수는 없습니다. 서버의 특성마다 다르겠지만, Apdaptive Hash Index를 활성화한 경우 반드시 현재 사용하고 있는 관련 메모리를 모니터링을 해야합니다. (서버마다 사용량이 다를 수 있습니다.)
이 기능은 innodb_adaptive_hash_index라는 파라메터로 기능을 켜고 끌 수 있는데, MySQL 5.5 버전(엄밀하게 말하면 InnoDB Plugin 1.0.3 버전)부터는 동적으로 Global 변수를 변경할 수 있습니다.
- 켜고
mariadb> set global innodb_adaptive_hash_index = 1;
- 끄고
console
mariadb> set global innodb_adaptive_hash_index = 0;
관련 통계 정보는 아래와 같이 확인하면 됩니다.
mariadb> show global status like 'Innodb_adaptive_hash%';
+----------------------------------------+------------+
| Variable_name | Value |
+----------------------------------------+------------+
| Innodb_adaptive_hash_cells | 42499631 |
| Innodb_adaptive_hash_heap_buffers | 0 |
| Innodb_adaptive_hash_hash_searches | 21583 |
| Innodb_adaptive_hash_non_hash_searches | 3768761684 |
+----------------------------------------+------------+
MariaDB에서는 Global Status에서 현황을 파악해볼 수 있지만, Oracle MySQL에서는 관련 통계정보를 status로 관리하지 않습니다. 대신, 다음과 같이 엔진 상태 정보에서 관련 정보를 추출할 수 있습니다.
mysql> SHOW ENGINE INNODB STATUS
.. 중략 ..
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 365, seg size 367, 5414843 merges
merged operations:
insert 4902179, delete mark 1620426, delete 70789
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 17700827, node heap has 41801 buffer(s)
8217.61 hash searches/s, 957.12 non-hash searches/s
.. 중략 ..
자주 사용되는 자원을 해시를 통해서 직접 접근하기 때문에, 내부적인 락(이를테면 Mutex)으로 인한 지연이 줄어듭니다. 게다가 B-Tree의 데이터 접근 비용(O(LogN))에 비해, 해시 데이터 접근 비용인 O(1)으로 굉장히 빠른 속도로 데이터 처리가 가능한 것이죠. 단 자주 사용되는 자원 만을 해시로 생성하기 때문에, 단 건 SELECT로 인하여 반드시 해당 자원을 향한 직접적인 해시 값이 만들어지지 않습니다.
Adaptive Hash Index의 효과
아래와 같이 테스트 테이블을 생성 후 1300만 건 데이터를 만들고, PK로 접근하는 IN 쿼리를 발생시켜 효과를 확인해봅니다.
IN 절에는 약 30개 정도의 파라메터를 넣고, 300개의 쓰레드에서 5ms 슬립을 줘가며 트래픽을 줍니다.
- 테이블 스키마
create table ahi_test(
i int unsigned not null primary key auto_increment,
j int unsigned not null,
v text,
key ix_j(j)
);
- SELECT 쿼리
select left(v, 1) from ahi_test
where i in (x,x,x,x,x,...x,x,x,,);
하단 결과에서 Adaptive Hash Index를 사용하지 않는 경우 CPU가 100% 였으나, Adaptive Hash Index를 사용한 이후에는 60% 정도로 사용률이 내려갔습니다.
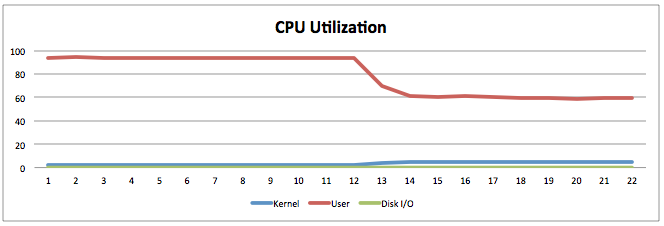

CPU는 줄었으나, 쿼리 응답 시간이 줄었기에 처리량 또한 20,000에서 37,000으로 늘어났습니다.


모든 데이터를 해시로 만들지 않기에, 해시가 켜진 상태에서도 여전히 B-Tree를 통해서 데이터 접근을 합니다. 이 수치는 장기간 테스트 쿼리를 날려보아도 변함이 없습니다.


Semaphore도 크게 줄어들었습니다.


주의사항
빈번한 데이터 접근이 많은 환경에서는 대단히 효율이 좋은 결과를 나타내었으며, 실제 MySQL을 활용하여 앞선 테스트 환경과 비슷한 서비스에서 효율적으로 잘 활용하고 있습니다. 그러나, 주의를 해야할 점은 오래된 테이블인 경우에도 해시가 여전히 메모리에 남아있을 수 있으며, 이에 대한 제어는 불가합니다.


얼마전, 수개월 전 pt-online-schema-change 유틸리티를 사용을 하여 스키마를 변경한 이후, 오래된 테이블을 정리하다가 대형 장애가 발생하였습니다.
데이터 사이즈는 크지 않은 상태(1~2G)였으며, 파일시스템 또한 xfs였던 지라 디스크 I/O적인 이슈 없이 쉽게 테이블 정리가 가능할 것으로 판단하였으나, 해시 메모리 정리하는 과정에서 쿼리 응답 속도가 떨어지게 되어서 결과적으로 장애가 발생하게 되었습니다.
하단은 해시 인덱스를 사용하던 환경에서 오래된 테이블을 정리하는 시점의 쿼리 처리량에 대한 결과입니다.
| Com_select | 39041 |
| Com_select | 39189 |
| Com_select | 38774 |
| Com_select | 38953 |
| Com_select | 39527 |
| Com_select | 37906 |
| Com_select | 39316 |
| Com_select | 37541 |
| Com_select | 37972 |
| Com_select | 32484 | <=== DROP OLD TABLE START
| Com_select | 27514 |
| Com_select | 27602 |
| Com_select | 27692 |
| Com_select | 27918 |
| Com_select | 27818 |
| Com_select | 28266 |
| Com_select | 28383 |
| Com_select | 28350 |
| Com_select | 37047 | <=== DROP OLD TABLE END
| Com_select | 39572 |
| Com_select | 38868 |
| Com_select | 39315 |
| Com_select | 38738 |
| Com_select | 39548 |
| Com_select | 39413 |
| Com_select | 38978 |
수 개월동안 사용되지 않은 테이블일지라도, Adaptive Hash Index를 사용하고 있다면 테이블 정리 시 최대한 트래픽이 없는 시점에 진행을 해야 합니다.
결론
InnoDB Adaptive Hash Index는 B-Tree의 한계를 보완할 수 있는 좋은 기능입니다.
특히 단일 랜덤 키 접근이 빈도있게 발생하는 경우라면, B-Tree 를 통하지 않고 데이터에 접근/처리가 가능하기에 좋은 퍼포먼스를 보입니다.
그러나, 자주 사용되는 데이터를 옵티마이저가 판단하여 해시 키로 만들기 때문에 제어가 어려우며, 수 개월 동안 사용되지 않던 테이블일지라도 기존 해시 자료 구조에 데이터가 남아 있게 되면, 테이블 Drop 시 영향을 줄 수 있습니다. 해시 인덱스에 의존하여 트래픽이 주로 처리되는 서비스인 경우 이런 점을 염두해 두고 사용을 해야겠습니다.
이 글은 카카오의 데이터베이스팀에서 운영하는 기술 블로그 small-dbtalk의 글 InnoDB Adaptive Hash Index을 옮긴 것입니다.
데이터베이스에 관심이 있으신 분들이라면 small-dbtalk에서 카카오의 데이터베이스팀이 공유하는 다양한 사례들과 기술들을 만나보세요. 절대 후회하지 않으실 거예요~~ ;)
- 커버 이미지 출처: Index © Simon Cunningham