


Parallel Programming and Applicative in Scala

Monolithic 아키텍쳐로 개발하기
Monolithic 아키택쳐로 개발시에는 일반적으로 하나의 저장소만 고려해야 하는 경우가 많았습니다.
Monolithic 아키텍쳐를 사용하면 편리한점이 많습니다.
코드가 한곳에 모여 있고 데이터가 한곳에 집중이 되어 있다는 것입니다.
일반적인 정규화 된 테이블에서 상품과 관련된 정보를 가져온다고 가정해보겠습니다.
데이터는 여러개의 테이블로 쪼개져 있기 때문에 필요한 데이터를 조합이 필요하다면 아래와 같이 SQL을 이용해서 여러개의 테이블을 join해서 데이터를 조합하여 가져올수 있습니다.
SELECT *
FROM
items, catalogs, wishes, categories, details, certificiations
WHERE
items.id = ?
AND items.id = catalogs.itemId
AND items.id = wishes.itemId
...
단순함을 가지고 있는 Monolithic은 장점도 많이 있지만 단점이 많은 개발 방법론입니다.
하나의 코드 베이스안에서 모든것이 관리 되기 때문에 경계선이 애매하고 많은 컴포넌트가 서로 의존을 가지고 강결함을 이루고 있게 됩니다.
코드가 늘어남에 따라 시스템은 무거워지고 조금만 고쳐도 여러곳에서 side effect가 생기며 외부 변화에 빠르게 대처하지 못하게 됩니다.
이런 단점을 극복하기 위해서 마이크로 서비스란 개념이 2011년도에 나오고 그 이후 패러다임이 바뀌게 되었습니다.
특히 Netflix와 같은 실리콘 밸리의 유명한 IT기업에 이를 전폭적으로 사용하고 이에 대한 성공 사례를 보여주며
많은 기업과 소프트웨어 개발자들이 이 아키텍쳐를 채택 해야하는 근거를 제시해주었습니다.
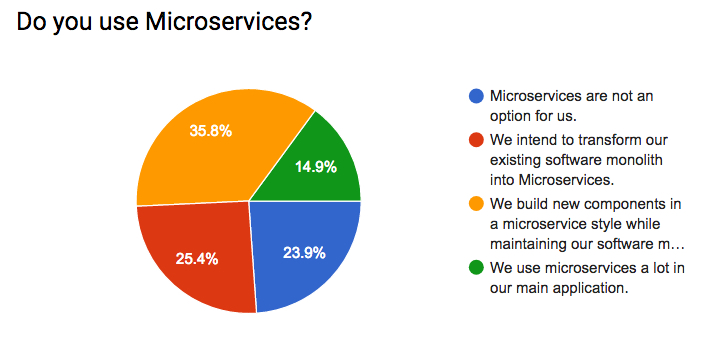
이제 마이크로 서비스는 많은 관심을 가지고 엔터프라이즈 시장에서 인기를 가지고 있는 아키텍쳐 입니다.
아래 통계자료를 보면 75% 이상이 마이크로 서비스를 일부 혹은 전면적으로 사용하며 개발할고 있습니다.

마이크로 서비스로 개발하기 – 데이터의 분리
마이크로 서비스로 개발하는 것은 무조건 좋고 장점만 있는 것은 아닙니다.
마이크로 서비스로 개발 방법론 을 한다는 것은 과거의 Monolithic 아키택쳐로 하나의 저장소만 관리하는것과 완전 다른 개발 방식을 가져오게 되었습니다.
각각의 마이크로 서비스는 각각의 서비스가 독립적으로 동작하기 때문에 자신만의 고유한 데이터를 가지고 있습니다.
많은 데이터가 각각의 마이크로 서비스로 분산 됩니다.


Monolithic으로 개발시에는 메인의 DB에 ER Diagram만 잘알면 되었지만
다른 마이크로 서비스의 데이터는 어디에 어떤 테이블로 저장되어었는지 알 필요가 없습니다.
도메인이 분리 되었기 때문에 다른 마이크로 서비스의 API의 스펙 관리 하고 이를 쉽게 호출 할수 있어야 해야 합니다.
이를 위해 Rest API는 documentation을 잘 보여주는 Swagger, RPC의 Thrfit 그리고 GRPC와 같은 도구로 API Spec을 표현합니다.
그리고 분리된 데이터를 합치고 구성하기 위해서 API Gateway에서 여러곳에 마이크로 서비스의 정의된 API를 호출하여 분산되어 있는 다양한 정보를 가져와서 조합을 해야합니다.
순차 연동 방식
예를 들어 마이크로 서비스에서 정보를 얻기 위해서 10개의 API에서 정보를 가져와야 할 경우가 있다고 해보겠습니다.
이를 동기화 방식으로 처리를 한다면 각각의 API가 100 ms의 응답을 준다면 1초의 딜레이가 생기게 됩니다.
마이크로 서비스가 좋다고 했는데 SQL한번호출하고 200ms이면 되던 API가 5배나 느려졌습니다.


- 이미지 출처 : Reactive Microservices Architecture By Jonas Bonér, Co-Founder & CTO Lightbend, Inc.
혹자는 과거(Monolithic)가 더 좋다며 이런걸 왜 쓰냐고 하는 경우도 있습니다.
하지만 마이크로 서비스의 느슨한 결합의 장점은 쉽게 뿌리 칠수가 없습니다.
코드에 한번 들어간 SQL 조인 쿼리는 시스템과 강결합 되어서 쉽게 고칠수 없고 리팩토링및 시스템을 유지보수 하기 여간 어려운것이 아닙니다.
문제를 해결하기 위해 블로킹 연산 말고 Future의 비동기 연산을 사용하면 상황이 달라지지 않을까요?
Future Monad를 이용한 비동기 연동 방식
이전 글(Asynchronous Programming and Monad Transformers in Scala)은 Monad를 이용한 비동기 연동방식
Future Monad의 flatMap을 이용하여서 비동기 프로그래밍을 실행할수 있는 방법을 알려드렸습니다.
이것을 간단하게 코드로 표현하면 아래와 같습니다.
val product: Future[ProductDto] = for {
item <- itemReposotory.findByid(itemId)
catalog <- catalogRepository.findById(item.catalogId)
brand <- brandRepository.findById(item.brandId)
wishCount <- itemWishCountRepository.findByItemId(item.id)
category <- categoryRepository.findOneByBrandId(item.brandId)
detail <- itemDetailRepository.findByItemId(item.id)
certifications <- itemCertificationRepository.findByItemId(item.id)
} yield ProductFactory.of(item, brand, catalog, wishCount, category, detail, certifications)
위의 for comprehension 코드는 flatMap과 map으로 변경이 됩니다.
예를 들어 아래와 같이 변환 하게 됩니다.
for(x <- c1; y <- c2; z <- c3) yield {...}
위의 코드는 아래 코드로
c1.flatMap(x => c2.flatMap(y => c3.map(z => {...})))
Future의 flatMap은 앞의 행위가 완료 되었을때 즉 API를 호출 했다면 그 전 API가 완료 되어야만 그 다음 API가 callback으로 수행하기 됩니다.


그렇기 때문에 이 코드는 아레 순서대로 데이터를 가져오게 됩니다.
item => catalog => brand => wishCount => category => detail => certification
flatMap 의 아용한 비동기 프로그램은 되지만 병렬 프로그램은 아닙니다.
async != parallel 입니다. 비동기가 된다고 병렬 프로그래밍은 아닙니다.
병렬 프로그래밍


- 이미지 출처 : Reactive Microservices Architecture By Jonas Bonér, Co-Founder & CTO Lightbend, Inc.
서로 의존성이 없은 데이터라면 순차적으로 가져올 필요가 없습니다.
동시에, 병렬로 가져오면 됩니다.
병렬 프로그래밍은 간단한 수식을 통해 성능을 예측할수 있습니다.
특정 테스크를 실행하기 위해서 순차적으로 실행되야 하는 부분과 병렬로 실행 될수 있는 부분은 구분함으로서 가능합니다.
Speed up in latency – Amdahl’s law
전체 테스크 중에 병렬로 처리 가능한 부분의 비율이 성능의 향상을 결정짓습니다.
병렬 프로그래밍, map-reduce와 같은 내용에 자주 나오는 Amdahl의 법칙에 맞추어 보면
여기서 S(latency) 는 전체 테스크 실행의 이론적인 속도 향상이다.
s 는 병렬로 처리가능했을때 성능이 일어날수 있는 부분이다.
p 는 전체 테스크중에 성능 개선(병령처리)이 가능한 부분의 원래 시간이다.


각각의 데이터를 가져오는걸을 1초라 하면 각각의 연산의 단순합으 1초 * 7 = 7초가 걸리게 됩니다.
이중 병렬로 가져올수 있는것이 6초입니다.
먼저 동시에 2개씩 병렬로 처리하는 경우에는 그 성능이
def slatency(p: Float, s: Int): Float = 1 / (1 - p) + p / s
val p = 6 / 7.0
val s = 2
slatency(p, s)
// 1.75
1.75배가 증가합니다.
7초가 걸리던 응답 속도는 약 4초로 줄어들게 됩니다.
6개를 동시에 병렬로 처리가 가능하다면
val p = 6 / 7.0
val s = 6 // 6 개를 동시에 실행하면
slatency(p, s)
// 3.49999
이번엔 기존 속도에 약 3.5배 정도 증가하게 됩니다.
예상 되는 응답시간은 7초에서 2초로 줄어들게 됩니다.
이는 기존에 monolithic 아키텍처와 같은 수준을 유지 할수가 있습니다.
물론 방금 말한 수치는 단순한 가정입니다.
복잡한 엔터프라이즈 환경에서 성능의 변수는 다양하고 많기 때문에 꼭 이렇다 말할수는 없습니다.
하지만 동시에 실행할수 있다면 순차 프로그래밍보다 병렬 프로그래밍을 통해서 응답속도를 획기적으로 줄일수 있습니다.
Scala Future의 Eager evaluation 활용하기
scala.concurrent.Future의 특성을 고려해서 구현해보겠습니다.
scala에서 기본으로 제공해주는 Future는 eager evaluation 방식으로 동작합니다.
lazy(사용하는 시점) evaluation이 아니라 선언되는 시점에 바로 동작하기 때문에
간단하게 테스트 해보면 변수 future를 따로 실행을 하지 않아도 1초 후에 ‘hello world’가 화면에 출력됩니다.
import scala.concurrent.Future
import scala.concurrent.ExecutionContext.Implicits.global
val future = Future {
Thread.sleep(1000)
println("hello world")
}
// 선언만 했는데 1초후 출력됨
hello world
Eager evaluation 특성을 이용해서 먼저 future를 실행하고 나중에 for comprehension으로 조합하는 코드를 만들수 있습니다.
private def getProduct(itemId: Int): Future[ProductDto] = {
val itemFuture = itemRepository.findById(itemId)
itemFuture.flatMap { item =>
val catalogFuture = catalogRepository.findById(item.catalogId)
val brandFuture = brandRepository.findById(item.brandId)
val wishFuture = itemWishCountRepository.findByItemId(item.id)
val categoryFuture = categoryRepository.findOneByBrandId(item.brandId)
val itemDetailFuture = itemDetailRepository.findByItemId(item.id)
val itemCertificationFuture = itemCertificationRepository.findByItemId(item.id)
for {
catalog <- catalogFuture
brand <- brandFuture
wishCount <- wishFuture
category <- categoryFuture
detail <- itemDetailFuture
certifications <- itemCertificationFuture
} yield
ProductFactory.of(item, brand, catalog, wishCount, category, detail, certifications)
}
}
이제 위의 코드는 병렬도 동작합니다.


하지만 코드가 2배로 늘어났다 한번만 쓰고 필요없는 local variable이 왕창 늘어 났습니다.
그리고 중대한 문제점이 하나 더 들어있습니다.
자바에도 Future에 대한 다양한 구현체, thrird party 라이브러리가 존재를 하듯이
이와 마찬가지로 스칼라에도 monix – Task, scalaz – Task, twitter future등 다양한 비동기 구현제가 존재한다.
이 구현체들은 scala.concurrent.Future 처럼 eager evaluation을 한다는 보장은 없습니다.
Twitter가 만든 Future 구현체의 경우 eager evaluation을 하지만
monix와 scalaz의 Task는 lazy evaluation을 합니다.
Lazy evaluation의 함정
같은 로직을 monix.task를 활용해서 구현할수 있습니다.
// scala future를 활용한 비동기 프로그램
object itemRepositoryScalaFuture extends ItemRepository {
def findById(id: Int): Future[Item] = Future {
// slow computation
}
}
// monix task를 활용한 비동기 프로그램
object itemRepositoryMonixTask extends ItemRepository {
def findById(id: Int): Task[Item] = Task {
// slow computation
}
}
아래 수치는 같은 로직을 scala future와 monix task를 활용하여 수치를 비교한것입니다.
테스트에 대한 전체 소스코드는 github에 올려 놓았습니다.
scala future with eager evaluation
00:39:12 - item-10
00:39:13 - catalog-1000
00:39:13 - brand-100000
00:39:13 - wish-10
00:39:13 - category-100000
00:39:13 - detail-10
00:39:13 - certification-10
elapsed : 2.786119929 sec
monix task with lazy evaluation
00:39:14 - item-10
00:39:15 - catalog-1000
00:39:16 - brand-100000
00:39:17 - wish-10
00:39:18 - category-100000
00:39:19 - detail-10
00:39:20 - certificatTaskn-10
elapsed : 7.074971322 sec
우리의 코드는 더이상 병렬로 동작하지 않습니다. monix task는 7초 걸리고 scala future는 2.7초 걸렸습니다.
Eager evaluation의 효과를 이용해보려 했지만 여러개의 scala future를 합친결과는 monix의 task를 합친 결과는 다릅니다.
비동기 연산의 구현체가 바뀌었다고 병렬로 진행되것이 순차로 진행되는것을 누구도 원하지 않을 것입니다.
이를 해결하고 명확하게 프로그램에게 나는 이걸 병렬도 돌리고 싶다고 말할수 있는 방법이 있습니다.
병렬 프로그래밍을 하기 위해서 Monad와 eager evaluation 활용해서 만드는것 보다
Monad의 친구 또다른 typeclass인 Applicative를 활용하는 방법이 있습니다.
Applicative 이건 뭔소리인가?
Applicative 단어를 듣는 순간 이건 무엇인가 당황할수 있습니다.
Monad도 잘 모르는데 뭔 Applicative인가?


하지만 포기하지 마세요! 어렵지 않습니다. 다만 용어가 아직 익숙하지 않을 뿐입니다!
Applicative는 겨우, 단지, 고작 함수 2개로 정의 됩니다.
먼저 Applicative의 인터페이스 정의를 살며보면
trait Applicative[F[_]] {
def pure[A](a: A): F[A]
def ap[A, B](fa: F[A])(ff: F[A => B]): F[B]
}
생각보다 복잡하진 않습니다. 단순히 pure와 ap함수로 구성되어 있습니다.
Applicative의 ap함수는 형태는 Functor의 map 모양과 유사합니다.
trait Functor[F[_]] {
def map[A, B](fa: F[A])(f: A => B): F[B]
}
ap함수의 map에서 받는 함수의 모양 A => B의 형태가 F로 감싼 F[A => B]로 감싸졌습니다. 이게 끝입니다.
그리고 주된 특징은 아래 그림에서 처럼 두개의 container를 열어서 함수를 적용하고 닫는것입니다.
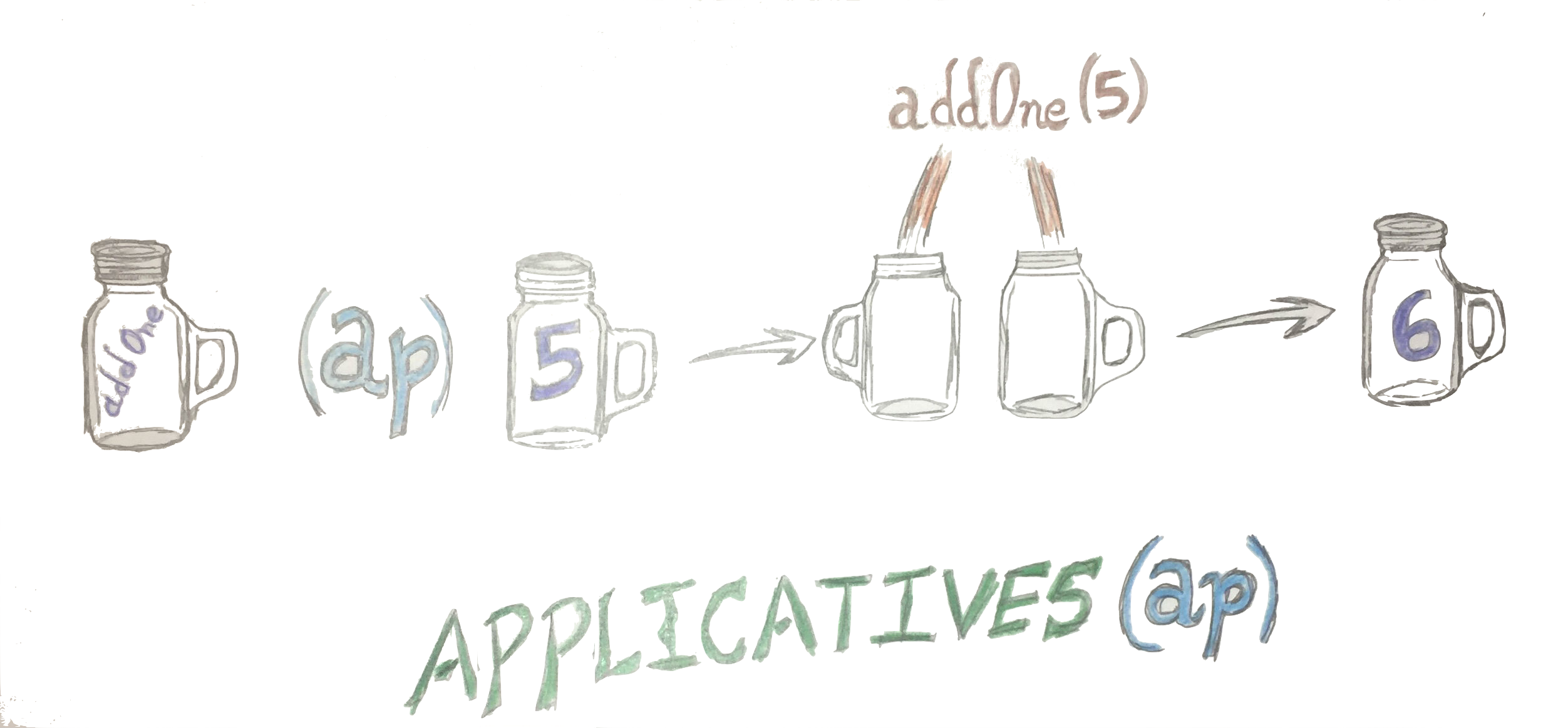

- 이미지 출처 : Functional programming in javascript
두개를 연다는것은 두개를 동시에 열수(parallel)도 있다는 뜻입니다.
오픈소스 함수형 프로그래밍 라이브러리인 cats의 Applicative trait와 Apply trait를 통해서 ap함수와 pure함수를 확인할수 있습니다.
다양한 함수를 이용한 상태 변경
함수형 언어에서 에서 F[A]를 F[B]로 바꾸는 여러가지 방법이 있습니다.
잠깐 정리하고 넘어가보겠습니다.
- Functor :
A => B함수를 받아F[A]를F[B]로 변형시키는map함수를 가지고 있습니다.map : (A => B) => F[A] => F[B] - Monad :
A => F[B]함수를 받아F[A]를F[B]로 변형시키는flatMap함수를 가지고 있습니다.flatMap: (A => F[B]) => F[A] => F[B] - Applicative :
F[A => B]함수를 받아F[A]를F[B]로 변형시키는ap함수를 가지고 있습니다.ap: F[A => B] => F[A] => F[B] - Comonad :
F[A] => B함수를 받아F[A]를F[B]로 변형시키는coflatMap함수를 가지고 있습니다.coflatMap: (F[A] => B) => F[A] => F[B]그외에도 F[A]를 F[B]를 변화 시키는 여러 typeclass가 존재합니다. 또만
F[A] ~> G[A]로 변환 시키는 것도 존재합니다.
이 글에서는 Applicative에만 집중하겠습니다.
언제나 그렇듯 의문이 들고 많은 질문을 받는습니다.
Applicative란 함수는 도대체 언제 사용해야하는가?
Applicative란 개념이 외 필요한가?
Applicative 안에 있는 ap 함수는 future를 활용한 병렬 프로그래밍을 할때 효과적으로 사용될수 있습니다.
ap함수는 바로 사용하는 경우는 많이 없지만 활용한 보조함수 product, mapN 같은 함수를 많이 사용하게 됩니다.
Future 병렬 처리 예를 통한 Applicative 이해하기
Future의 기준으로 ap 함수를 생각해보겠습니다.
두개의 future fa, fb가 있고 두개의 future안에 들어 있는 값을 동시에 완료되는 연산하고 싶다고 하고 싶다면
def fa: Future[A] = Future { a }
def fb: Future[B] = Future { b }
// 동시에 실행
val fab: Future[(A, B)] = // fa와 fb가 동시에 실행되고 그값이 fab에 저장된다.
이제 ap함수를 활용해서 fab를 도출해보겠습니다. 즉 fa와 fb의 값을 합쳐 보겠습니다.
ap함수는 두번째 인자가 함수를 감싼 F[A => B]입니다.
def ap[A, B](fa: F[A])(ff: F[A => B]): F[B]
입력이 F[A => B]인데 우리가 가지고 있는 값은 F[B]입니다. 입력값의 타입을 맞추어 주기 위해 우리는 fb를 변환해야 합니다.
아래와 같이 바꿀수 있습니다.
val fa2b: F[A => B] = map(fb)(b => (a: A) => b)
우리가 최종적으로 원하는건 A와 B값의 쌍이기 때문에
Future[B]의 B값에 A의 값이 들어오면 A와 B의 값의 쌍으로 변환 시키는 faab: Future[A => (A, B)]의 형태로 바꾸어 보겠습니다.
val faab: F[A => (A, B)] = map(fb)(b => (a: A) => (a, b))
이제 하나가 함수가 되었기 때문에 ap함수에 적용시킬수 있습니다.. 타입도 정확합니다.
(F[A])(F[A => (A, B)]) => F[(A, B)] 그다음에 ap(fa)(faab)를 적용시키면 F[(A, B)]의 형태가 됩니다.
val fab: F[(A, B)] = ap(fa)(faab)
어떻게 사용할지 몰랐던 ap 함수는 두개의 Future를 합치는데 탁월한 역할을 합니다.
간단하게 두개의 future를 합치는 함수를 만들었습니다. 이를 일반화 하고 이 함수 이름을 product라 하겠습니다.
def product[A, B](fa: F[A], fb: F[B]): F[(A, B)] = {
val faab: F[A => (A, B)] = map(fb)(b => (a: A) => (a, b))
val fab: F[(A, B)] = ap(fa)(faab)
fab
}
이 product를 활용하면 간단하게 두개의 future를 병렬 연산하고 그 완료된 값을 합쳐 보겠습니다.
def fa: Future[A] = Future { a }
def fb: Future[B] = Future { b }
// 동시에 실행
val fab: Future[(A, B)] = product(fa, fb)
아직 우리는 ap 구현하지 않았습니다. ap 인터페이스를 정의만 하고 이를 이용해서 product함수를 만드는것만 구현했습니다.
ap를 두개의 future를 동시에 완료되게 구현하면 동시에 fa, fb가 실행되고 Future[(A, B)]를 만들수 있습니다 .
즉 병렬로 A와 B를 가져오는 연산을 ap함수에 구현하면 product함수도 병렬로 실행되게 됩니다.
def ap[A, B](fa: => Future[A])(fab: => Future[A => B]) =
fab zip fa map { case (fa, a) => fa(a) }
실제 많이 사용되는 오픈소스 라이브러리도 이와 같은 방식을 이용해서 구현하였습니다.
스칼라의 함수형 프로그래밍을 도와주는 scalaz의 future instance, free monad를 쉽게 사용할수 있게 도와주는 freestyle에 구현되어 있는 future instance는 future의 zip 연산을 활용해서 동시성을 구현하였습니다.
하지만 cats의 future instance는 별도의 구현없이 flatMap을 이용하여 구현하였습니다.
// cats/FlatMap.scala
// https://github.com/typelevel/cats/blob/f4aa32d803d99d981ba46b637832c79a97665148/core/src/main/scala/cats/FlatMap.scala#L96-L97
override def ap[A, B](ff: F[A => B])(fa: F[A]): F[B] =
flatMap(ff)(f => map(fa)(f))
flatMap을 이용해서 ap를 구현할수는 있습니다.
하지만 이 ap함수는 flatMap의 순차 연산 특성을 가지게 되기 때문에
병렬연산의 특성을 가지 있지 않다는것에 주의해야합니다.
앞에서 말했듯이 cats의 future instance가 실제 병렬로 잘 동작하는 이유는 scala의 future가 eager evaluation이기 때문이다.
product 함수를 호출하는 시점에 이미 두개의 future가 이미 실행되었기 때문이다.
cats에서 기본 제공해주는 future instance를 사용하지않고 별도로 future.zip을 이용해서 구현해서 사용하는 사례 1, 2가 있습니다.
그리고 scalaz와 monix에서는 nondeterminism이라는 기능을 제공해서 Applicative를 병렬로 연산하거나 순차연산 할것인지를 명시적으로 선택할수 있습니다.
Nondeteminism을 이용한 병렬 프로그래밍
scalaz의 task는 아래 예를 참고하면 된다.
parallel로 동작하기 위해서는 Nondeterminism를 활용하면 됩니다.
import scalaz._, Scalaz._
// sequence
def runAp(): Unit = {
val ap2 = Applicative[Task].apply2(ta, tb)(_ + _)
ap2.unsafePerformSync
}
// parallel
def runNondeterminism(): Unit = {
val both = Nondeterminism[Task].mapBoth(ta, tb)(_ + _)
both.unsafePerformSync
}
monix의 task 경우에도 아래 코드처럼 nondeterminism을 이용하면 applicative에서 병렬 프로그래밍이 가능합니다.
import monix.eval.Task
import monix.execution.Scheduler.Implicits.global
import cats.implicits._
// parallel
def runWithZip() = {
val tc : Task[Int] = ta.zipMap(tb)(_ + _)
}
// sequence
def runWithAp() = {
val tc : Task[Int] = Applicative[Task].map2(ta, tb)(_ + _)
}
// parallel
def runWithNondeterminismAp() = {
import monix.eval.Task.nondeterminism
val tc : Task[Int] = Applicative[Task].map2(ta, tb)(_ + _)
}
위의 코드의 전체 코드는 github에 올려놓았습니다.
이제 이를 활용하여 원래 처음 만들었던 프로그램에 적용을 하면 Applicative의 mapN 연산자를 활용하여서 병렬 연산을 하고 빠른 응답을 얻을수 있습니다.
itemRepository.findById(itemId).flatMap { item =>
(
catalogRepository.findById(item.catalogId),
brandRepository.findById(item.brandId),
itemWishCountRepository.findByItemId(item.id),
categoryRepository.findOneByBrandId(item.brandId),
itemDetailRepository.findByItemId(item.id),
itemCertificationRepository.findByItemId(item.id)
).mapN { case (catalog, brand, wish, category, detail, cert) =>
List(brand, catalog, wish, category, detail, cert)
}
}
함수형 언어에는 다양한 특징이 있는데 이 특징들은 마이크로 서비스를 하기에 좋은 언어라고 생각합니다.
특히 비동기 프로그래밍(Monad), 병렬프로그래밍(Applicative)에는 장점이 부각이 됩니다.
꼭 함수형 언어가 아니더라도 마이크로 서비스를 적용하고 있거나 적용하려고 한다면 코드의 많은 부분을 병렬 프로그래밍으로 바꿀수 있는지 보고 적극적으로 병렬로 처리하면
더욱더 빠른 응답을 주고 마이크로 서비스의 장점을 최대화 할수 있을것이라 생각합니다. :-)
Source: Parallel Programming and Applicative in Scala