


새로운 기능 – Amazon SageMaker 기반 수십억 개의 파라미터로 딥 러닝 모델 훈련 간소화

오늘 Amazon SageMaker에서 이전에 하드웨어 한계로 인해 훈련이 어려웠던 매우 큰 딥 러닝 모델의 훈련을 단순화 할 수 있는 기능을 발표하게 되어 매우 기쁩니다.
지난 10년 동안 딥 러닝(DL)이라는 기계 학습 관련 기술은 세계에 큰 반향을 일으켰습니다. 신경망을 기반으로 DL 알고리즘은 이미지, 비디오, 음성 또는 텍스트와 같은 방대한 양의 비정형 데이터에 숨겨진 정보 패턴을 추출하는 탁월한 능력을 가지고 있습니다. 실제로 DL은 특히 컴퓨터 비전 및 자연어 처리에서 인간이 하는 것 같은 다양하고 복잡한 작업에서 인상적인 결과를 신속하게 달성했습니다. 사실, 딥 러닝은 ImageNet 대규모 시각 인식 과제(ILSVRC), 일반 언어 이해 평가(GLUE)나 스탠포드 질문 응답 데이터 세트(SQUAD)와 같은 참조 작업에 대한 결과를 지속적으로 개선하면서 혁신은 그 어느 때보다 빨라졌습니다.
보다 복잡한 작업을 처리하기 위해 딥 러닝 연구원들은 점점 더 복잡한 모델을 설계하고, 더 많은 뉴런 레이어와 더 많은 연결을 추가하여 패턴 추출 및 예측 정확도를 개선하고, 모델 크기에 직접적인 영향을 미치고 있습니다. 예를 들어 100MB의 ResNet-50 모델을 사용함으로써 이미지 분류에 대한 매우 좋은 결과를 얻을 수 있습니다. 물체 감지 또는 인스턴스 세분화와 같은 더 어려운 작업을 수행하려면 Mask R-CNN 또는 YOLO v4와 같은 더 큰 모델을 사용해야 합니다. 용량은 약 250MB입니다.
추측할 수 있듯이 모델 성장은 모델 훈련에 필요한 시간과 하드웨어 리소스에도 영향을 미치기 때문에 GPU(그래픽 처리 장치)는 오랫동안 대형 DL 모델을 훈련하고 미세 조정하는 데 선호되는 옵션입니다. 대규모 병렬 아키텍처와 대형 온보드 메모리 덕분에 미니 배치 훈련이라는 기술을 사용할 수 있습니다. 여러 데이터 샘플을 한 번에 GPU로 전송하면 하나씩 보내는 대신 통신 오버헤드가 줄어들고 훈련 작업이 매우 빨라집니다. 예를 들어, Amazon Elastic Compute Cloud(EC2) p4 제품군에서 사용할 수 있는 NVIDIA A100에는 7,000개가 넘는 컴퓨팅 코어와 40GB의 빠른 온보드 메모리가 있습니다. 당연히 매우 큰 모델에서 많은 배치의 데이터를 훈련하기에 충분할 것 같습니다. 그렇겠죠?
글쎄요, 그렇지 않습니다. OpenAI GPT-2(150억 개의 파라미터), T5-3B(30억 개의 파라미터) 및 GPT-3(1,750억 개의 파라미터)과 같은 대용량 자연 언어 처리는 수십 또는 수백 기가바이트의 GPU 메모리를 소비합니다. 마찬가지로, 고해상도 3D 이미지로 작업하는 최첨단 모델은 너무 커서 GPU 메모리에 맞지 않을 수 있습니다. 심지어 배치 크기가 1인 경우에도 마찬가지입니다.
원을 사각형으로 만들기 위해 DL 연구원은 다음과 같은 방법들을 조합하여 사용합니다.
- 비록 일부 모델에서는 선택사항이 아니지만 더 강력한 GPU를 구매합니다.
- 덜 강력한 모델로 작업하고 정확도를 포기합니다.
- 기울기 체크포인팅(Gradient checkpoint)을 구현합니다. 이 기법은 중간 훈련 결과를 메모리에 보관하는 대신 훈련 속도를 20~30% 정도 낮추어 중간 훈련 결과를 디스크에 저장합니다.
- 모델 병렬 처리를 구현합니다. 즉, 모델을 수동으로 분할하고 다른 GPU 들에서 더 작은 조각들을 훈련합니다. 말할 필요도 없이 이 작업은 전문가인 실무자에게도 매우 어렵고 시간이 많이 걸리며 불확실한 작업입니다.
고객분들은 위의 어느 것도 아주 큰 모델을 작업할 때 만족스러운 해결책이 아니라고 말했습니다. 고객은 더 간단하고 비용 효율적인 솔루션을 요청했고, 우리는 방법을 찾아야 했습니다.
Amazon SageMaker에서 모델 병렬 처리 소개
SageMaker의 모델 병렬 처리는 여러 GPU에 걸쳐 모델을 효율적으로 자동 분할하므로 정확성이 떨어지거나 복잡한 수동 작업이 필요하지 않습니다. 또한 모델 훈련에 대한 이러한 확장형 접근 방식 덕분에 메모리 병목 현상 없이 매우 큰 모델로 작업할 수 있을 뿐 아니라 많은 수의 작고 비용 효율적인 GPU를 활용할 수도 있습니다.
시작시 TensorFlow 및 PyTorch에서 이를 지원하며, 코드 수정은 최소한만 필요로 합니다. 훈련 작업을 시작할 때 모델을 속도 또는 메모리 사용량에 맞게 최적화할지 지정할 수 있습니다. 그런 다음 Amazon SageMaker는 모델의 컴퓨팅 및 메모리 요구 사항을 분석하기 위해 사용자를 대신하여 초기 프로파일링 작업을 실행합니다. 그런 다음 이 정보는 통신을 최소화하면서 모델을 분할하는 방법과 모델 파티션을 GPU에 매핑하는 방법을 결정하는 파티셔닝 알고리즘에 전송됩니다. 파티셔닝 결정의 결과는 파일에 저장되며, 이 파일은 실제 훈련 작업에 대한 입력으로 전달됩니다.
보시다시피, SageMaker는 모든 작업을 처리합니다. 원하는 경우 모델을 수동으로 프로파일링하고 분할한 다음 SageMaker에서 훈련할 수도 있습니다.
코드를 살펴보기 전에 내부 동작방식에 대한 간단히 알려 드립니다.
모델 파티션 및 마이크로배치를 사용한 훈련
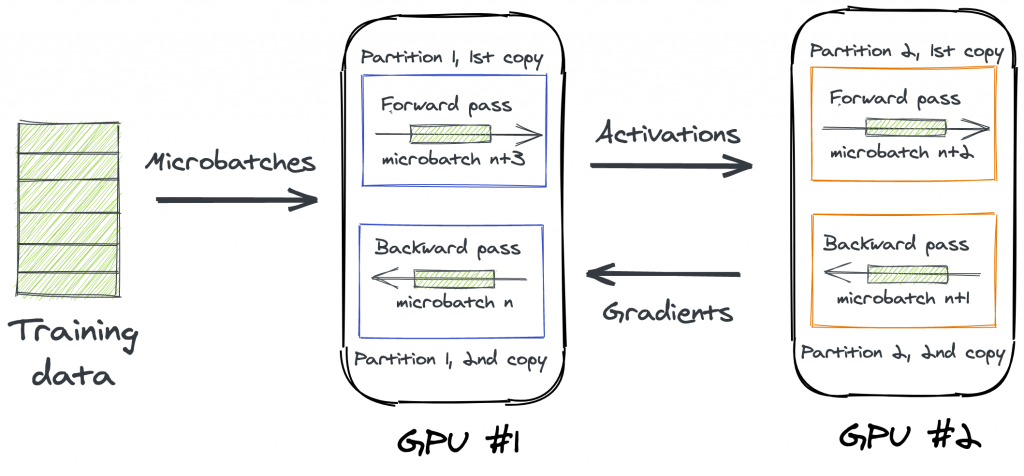
서로 다른 GPU에서 실행되는 모델 파티션은 서로 순방향 패스 입력(활성화 값)을 예상하기 때문에 파티션 시퀀스에서 미니 배치를 훈련하면 항상 하나의 파티션만 사용하게 되고 다른 파티션은 정체됩니다.
이러한 비효율적인 동작을 피하기 위해 미니 배치는 여러 GPU에서 병렬로 처리되는 마이크로배치로 분할됩니다. 예를 들어, GPU#1는 마이크로배치 n을 순방향으로 전파할 수 있지만 GPU#2는 마이크로배치 n+1에서 동일한 작업을 수행할 수 있습니다. 활성화 값을 저장할 수 있으며 수락할 준비가 될 때마다 다음 파티션으로 전달할 수 있습니다.
역전파의 경우 파티션은 서로의 입력 값(기울기)도 예상합니다. 파티션이 순전파 및 역전파를 동시에 실행할 수 없으므로 모든 GPU가 자체 마이크로배치에서 순방향 패스를 완료할 때까지 기다렸다가 해당하는 역방향 패스를 실행하도록 할 수 있습니다. 이 단순한 모드는 Amazon SageMaker에서 사용할 수 있습니다.
인터리브 모드라고 하는 훨씬 더 효율적인 옵션이 있습니다. 여기서 SageMaker는 마이크로배치의 수에 따라 파티션을 복제합니다. 예를 들어, 2개의 마이크로배치로 작업하면 각 GPU는 수신한 파티션의 두 복사본을 실행합니다. 각 복사본은 순전파 또는 역전파를 위해 다른 GPU에서 실행되는 파티션과 공동 작업을 수행합니다.
4개의 다른 마이크로배치가 2개의 중복된 파티션에 의해 처리되는 것처럼 보일 수 있습니다.

요약하면, 서로 다른 마이크로배치의 순방향 패스와 역방향 패스를 인터리빙하는 것은 SageMaker가 GPU 사용률을 극대화하는 방법입니다.
이제 TensorFlow와 함께 작동하는 방법을 살펴 보겠습니다.
Amazon SageMaker에서 모델 병렬 처리 구현
SageMaker SMP(모델 병렬 처리) 라이브러리 덕분에 자체 TensorFlow 코드에서 모델 병렬 처리를 쉽게 구현할 수 있습니다. 이 프로세스는 PyTorch와 유사합니다. 다음은 이 기능과 관련하여 수행해야 할 것들입니다.
- 파티션 구성을 정의하고 초기화합니다.
- 표준 Keras 서브클래싱을 사용하여 모델을
DistributedModel클래스의 하위 클래스로 만듭니다. @smp.step을 사용하여 모델에 대한 순방향 및 역방향 단계를 나타내는 훈련 함수를 작성합니다. 이 함수는 이전 섹션에서 설명한 아키텍처에 따라 파이프라인 됩니다.- 선택적으로 파이프라인 될 평가 함수에 대해서도 동일한 작업을 수행합니다.
4개의 NVIDIA V100 GPU가 장착된 ml.p3.8xlarge 인스턴스를 사용하여 MNIST 데이터 세트에 대한 간단한 합성곱 신경망 훈련에 이 기능을 적용하겠습니다.
먼저 SMP API를 초기화합니다.
import smdistributed.modelparallel.tensorflow as smp
smp.init()그런 다음 DistributedModel을 서브클래싱하고 모델을 빌드합니다.
class MyModel(smp.DistributedModel):
def __init__(self):
super(MyModel, self).__init__()
self.conv = Conv2D(32, 3, activation="relu")
self.flatten = Flatten()
self.dense1 = Dense(128)
self.dense2 = Dense(10)
. . .다음은 훈련 함수입니다.
@smp.step
def forward_backward(images, labels):
predictions = model(images, training=True)
loss = loss_obj(labels, predictions)
grads = optimizer.get_gradients(loss, model.trainable_variables)
return grads, loss그런 다음 SageMaker SDK에서 사용할 수 있는 TensorFlow 추정기를 사용하여 평소와 같이 훈련할 수 있습니다. 모델 병렬 처리 구성을 추가하면 됩니다. 2개의 파티션(따라서 2개의 GPU에 대한 훈련)과 인터리빙이 있는 2개의 마이크로배치(각 파티션의 2개의 사본)입니다.
smd_mp_estimator = TensorFlow(
entry_point="tf2.py",
role=role,
framework_version='2.3.1',
pv_version='py3',
instance_count=1,
instance_type='ml.p3.16xlarge',
distribution={
"smdistributed": {
"modelparallel": {
"enabled":True,
"parameters": {
"microbatches": 2,
"partitions": 2,
"pipeline": "interleaved",
"optimize": "memory",
"horovod": True,
}
}
},
"mpi": {
"enabled": True,
"processes_per_host": 2, # Pick your processes_per_host
"custom_mpi_options": mpioptions
},
}
)시작하기
앞서 살펴본 것처럼, 모델 병렬화를 사용하면 매우 큰 최첨단 딥 러닝 모델을 쉽게 훈련할 수 있습니다. 현재 Amazon SageMaker를 이용할 수 있는 모든 리전에서 추가 비용 없이 사용할 수 있습니다.
즉시 시작할 수 있도록 예제가 제공됩니다. 사용해보시고 의견을 알려주세요. 언제든지 AWS 지원 담당자나 SageMaker에 대한 AWS 포럼을 통해 피드백을 보내 주시기 바랍니다.
Source: 새로운 기능 – Amazon SageMaker 기반 수십억 개의 파라미터로 딥 러닝 모델 훈련 간소화