


서비스 규모 확장에 따른 게임 서비스 아키텍처 개선

AWS 기반 게임 개발자를 위한 안내서 – 2부. 게임 출시 전 반드시 챙겨야 할 것들에서 살펴본 것처럼 많은 것들을 고려하고 준비하여 성공적으로 게임을 출시했습니다. 이제, 모두 한시름 덜고 게임의 동시접속자 수가 성공적으로 늘어나기만을 기도하면 될까요? 게임이 인기를 얻고, 서비스 대상 지역이 확장될수록 처음에는 잘 동작하던 게임 백엔드가 점점 삐걱거리기 시작합니다. 모바일 게임을 포함한 온라인 게임은 게임의 재미만큼이나 게임의 서비스 안정성이 플레이어들이 떠나지 않도록 하는데 중요한 요소입니다. 늘어나는 트래픽에 따라서 어떤 것들을 고려해야 게임의 서비스 안정성을 확보할 수 있을까요?
1. 서비스 모니터링
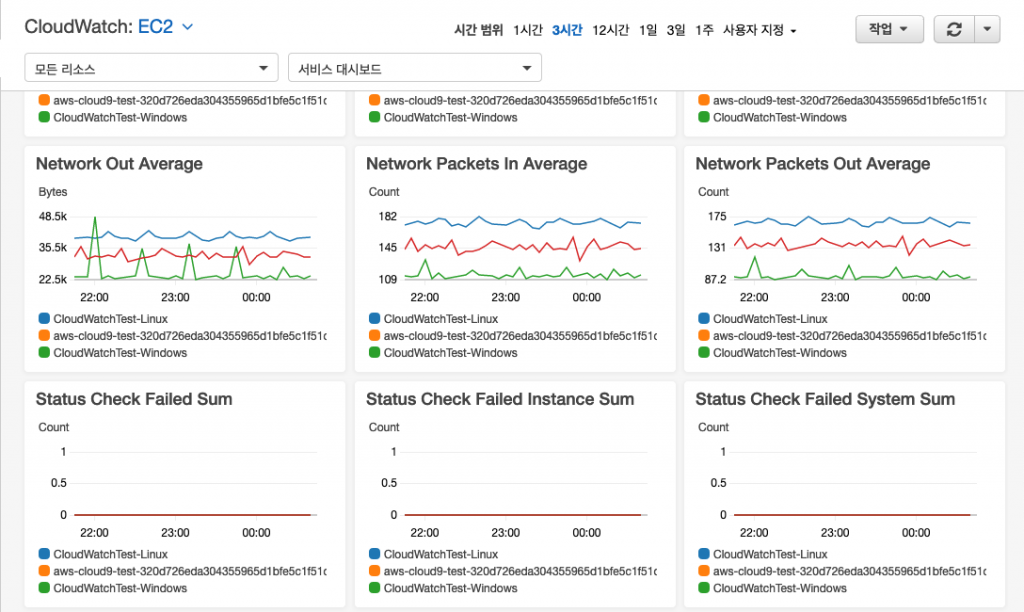
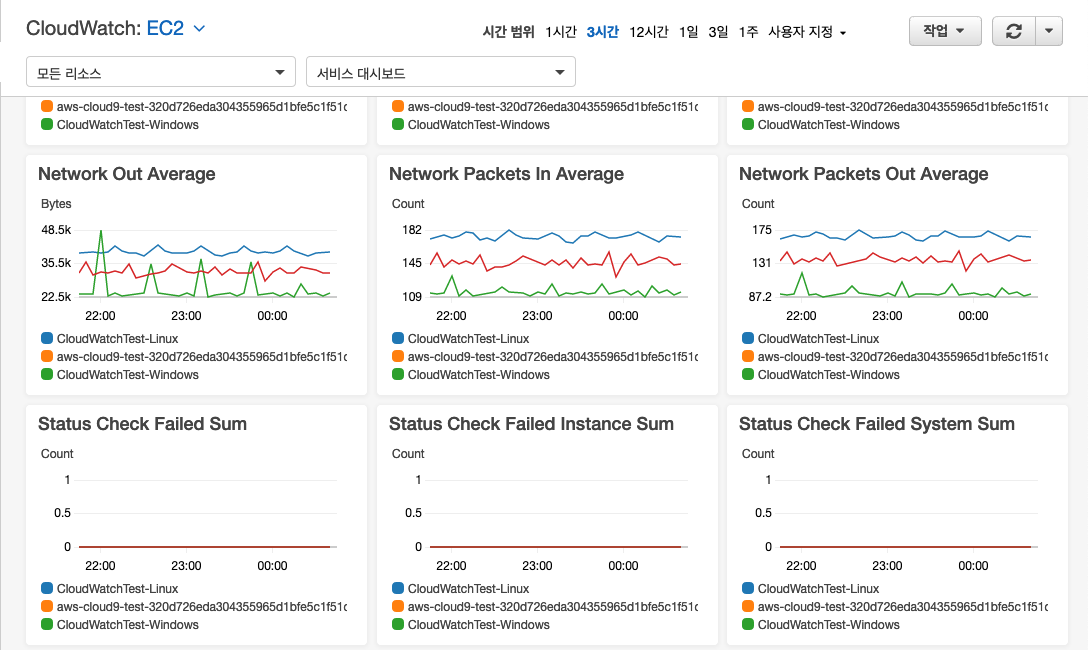
트래픽 증가에 따라 아키텍처를 지속적으로 개선하고 진화시키기 위해서는 적절한 모니터링을 통한 현 서비스 상태를 파악하는 것이 선결과제입니다. AWS의 서비스 모니터링을 위한 서비스인 Amazon CloudWatch를 활용하면, AWS 서비스들의 주요 지표를 확인하고 문제지점을 확인할 수 있으며, Alarm, Amazon SNS, AWS Lambda를 통해 이상징후에 대한 통지 및 조치를 자동화할 수 있습니다. 또한, AWS 내장 지표뿐 아니라 애플리케이션의 사용자 지정 지표와 로그를 수집하고 통합하여 모니터링하는 기능도 제공하고 있습니다.
Amazon CloudWatch를 사용한 게임 모니터링 방법에서는 CloudWatch의 다양한 기능들을 이용하여 지표를 수집하고 서비스를 모니터링하기 위한 분석과 대시보드 기능들을 활용하기 위한 상세 내용을 소개하고 있습니다.

이처럼, 서비스 백엔드에 대한 지속적인 모니터링을 통해 트래픽이 증가하면서 병목이 되는 지점을 식별하게 되면, 병목 지점의 성격에 따라 다양한 문제해결 방안을 모색해볼 수 있게 됩니다. 다음 장에서는 병목 지점을 해결하기 위한 방안들을 살펴봅니다.
2. 트래픽 및 요구사항 증가에 따른 아키텍처 개선 및 진화 전략
AWS 서비스 중에는 Amazon S3, CloudFront, DynamoDB, SES, SNS, SQS, Route 53, ELB, EFS 및 AWS Lambda, Step Functions와 같이 사용자가 특별히 신경 쓰지 않아도 태생적으로 높은 확장성, 내결함성, 가용성을 제공하는 서비스들도 있습니다. 올바른 아키텍처로 구성할 경우 높은 확장성과 내결함성, 가용성을 제공할 수 있는 Amazon EC2, EBS, RDS, VPC와 같은 서비스들도 있습니다. 같은 기능을 제공한다면 가급적 태생적으로 높은 확장성을 제공하는 서비스들을 사용하거나, 올바른 아키텍처 구성을 통해 높은 확장성을 가지도록 설계하는 것이 트래픽 및 요구사항 증가에 유연하게 대처할 수 있습니다.
수직 확장
병목 지점을 식별했을 때 먼저 손쉽게 고려할 수 있는 것은 수직 확장입니다. Amazon EC2의 경우 사이즈를 키우고, Amazon EBS의 경우 프로비저닝된 IOPS를 늘리거나 용량을 늘리는 것을 검토해볼 수 있습니다. 아키텍처 상의 구조적 변경이 수반되지 않는만큼 부작용을 최소화하면서 고려할 수 있는 첫 번째 방안입니다. Amazon EC2의 경우 같은 유형 내에서의 더 큰 인스턴스를 사용하거나, CPU 클럭, 메모리 사용량, 디스크 및 네트워크 I/O 요구량에 따라 더 적합한 인스턴스 유형으로 교체하는 방안을 고려할 수 있습니다. 이러한 확장 방식은 결국 한계에 이를 수 있으며, 항상 비용 효율적이거나 가용성이 높은 방식은 아닙니다. 하지만, 다른 방안들에 비하여 구현이 매우 쉽고 특히 단기적으로 많은 사용 사례에 충분할 수 있습니다.
수평 확장
모든 워크로드가 수평 확장을 지원하는 것은 아니며, 수평 확장을 지원하게 하기 위해서는 많은 구현상의 변경이 수반되는 경우도 있습니다. 하지만 수평 확장을 지원하는 워크로드의 경우, 트래픽 증가에 따라 처리하는 노드를 늘리는 구성만으로 대응이 가능해지고, AWS Auto Scaling을 통해 수평 확장을 자동화할 수 있습니다. 기존의 지표 및 예약 설정을 기반으로 하는 Auto Scaling 뿐 아니라, 최근에는 인공 지능 기반의 자동 스케일링 기능도 출시되어 트래픽 증감에 더욱 유연하게 대처할 수 있게 되었습니다. 또한 요즘 인기를 얻고 있는 컨테이너 기반의 서비스들인 완전관리형 컨테이너 오케스트레이션 서비스인 Amazon ECS나 Amazon EKS와 같은 경우도 각각 Amazon ECS 클러스터 AutoScaling와 클러스터 Autoscaler를 통해 자동 확장을 지원하고 있습니다.


고가용성
서비스 규모가 커질수록, 장애가 발생할 수 있는 구성요소는 증가합니다. 이때 고가용성 및 자동복구 기능은 서비스 안정성 확보에 중요한 요소가 됩니다. 수평 확장 섹션에서 언급한 태생적으로 높은 가용성을 제공하는 서비스들 외의 서비스들은 고가용성 구성을 위해서 한 리전 내에서 다중 AZ(가용영역) 구성이 필수적입니다. 다중 AZ 구성을 통해 가용영역 하나에 일시적인 장애가 발생하더라도 서비스 자동 복구 및 계속적인 서비스가 가능해집니다.
EC2의 경우 여러 가용영역에 걸친 트래픽 분산을 지원하는 ELB의 교차영역 로드밸런싱과 위에서 언급한 Auto Scaling 기능을 활용하여 단일 가용영역 장애에 대비가 가능한 아키텍처를 구성할 수 있습니다. RDS도 다중 AZ 배포를 지원하고 있으며, 특히 Amazon Aurora의 경우 스토리지 레이어는 이미 다중 AZ를 통해 복제되고 있어, 다중 AZ로 읽기 복제본 구성 시 성능 영향을 최소화하면서 고가용성을 확보합니다. Amazon ElastiCache for Redis와 Amazon Elasticsearch Service와 같은 서비스들도 다중 AZ 배포를 통해 고가용성을 제공하고 있습니다.
부하 분산
부하를 수평적으로 분산시키는 방법 외에도 다양한 부하 경감 방안을 모색할 수 있습니다. 보통 병목 지점의 부하를 다른 지점으로 옮기는 방식으로 부하를 낮추는 전략을 사용합니다.
데이터베이스에 대한 높은 성능 요구량에 따른 병목 현상에 대해서는 데이터베이스 자체의 수직 확장이나 샤딩 등을 고려해볼 수도 있지만, 더 간단한 부하 경감 방안으로 읽기 복제본을 통해 데이터베이스에 대한 읽기 부하를 복제본으로 옮길 수 있습니다. RDS의 경우 클릭 몇 번으로 즉시 읽기 복제본 구성이 가능하며, 특히 Aurora의 경우 스토리지 레이어의 동기화 부하를 DB 엔진과 분리함으로써, 읽기 복제본 인스턴스의 성능을 전적으로 읽기 쿼리 처리에 활용이 가능합니다.
캐시 레이어 도입을 통해, 다양한 휘발성 데이터 및 자주 업데이트되지 않는 데이터를 적재하여 데이터베이스에 대한 부하를 낮출 수도 있습니다. Amazon ElastiCache 서비스는 캐시 레이어로 가장 인기가 높은 두 메모리 데이터베이스 엔진인 Redis와 Memcached를 지원하며, 완전관리형으로 캐시 클러스터를 구성하고 사용할 수 있습니다. 또 다른 캐시 레이어로 웹 배포에 대한 CDN 서비스인 Amazon CloudFront를 통해서 전 세계에 분포하는 엣지 로케이션에서 캐시된 리소스를 서비스하여 오리진 웹서버에 대한 부하를 대폭 낮출 수 있습니다.
네트워킹 관련해서는 SSL/TLS 인증서를 CloudFront나 ELB에 위치 시켜 SSL/TLS 인증서에 대한 암/복호화 작업을 CloudFront나 ELB에서 대신 처리하도록 하여 대상 인스턴스의 암/복호화 부하를 낮출 수 있으며, 네트워크 세션 처리에 대한 부하도 ELB 및 CloudFront에서 상당 부분을 대신 처리하게 됩니다.
리전 확장
게임의 서비스 지역 확장에 따라 단일 리전 이상에서 서비스를 구성해야 할 경우가 있습니다. 대부분의 AWS 서비스들은 리전 단위에 구현되어 있기 때문에 복수의 리전에 걸쳐 서비스를 구성할 때는 그만큼 고민할 것이 많습니다.
먼저 라스트마일 네트워크를 최적화하기 위하여 플레이어의 위치에 따라 적절한 리전의 백엔드로 서비스를 라우팅할 수 있는 솔루션이 필요합니다. Route 53의 경우 지리적 라우팅, 지리 근접 라우팅 및 레이턴시 기반 라우팅을 통해 플레이어와 가장 인접한 리전으로 트래픽을 라우팅할 수 있습니다. AWS Global Accelerator는 전 세계에 분포한 엣지 로케이션에 Anycast로 전파한 고정 IP를 통하여 플레이어와 가장 인접한 엣지 로케이션을 경유하여 최적의 엔드포인트로 AWS의 리전 간 백본을 통하여 트래픽을 전달합니다. Amazon GameLift의 경우, 다중 리전의 플릿을 대상으로 하여 클라이언트에서 수집한 지연시간을 기반으로 최적 리전의 플릿으로 세션을 배치하는 기능을 제공하고 있습니다.


Global Accelerator 미적용시


Global Accelerator 적용시
복수의 리전을 활용하게 되면 각 리전의 백엔드를 안전하게 연결할 필요가 생깁니다. 이럴 경우 고려할 수 있는 것이 VPC 피어링과 AWS Transit Gateway를 통한 리전 간 피어링입니다. 인터넷망을 경유하지 않으므로 항상 AWS의 리전 간 백본을 사용하여 리전별 백엔드들의 상호 연결이 가능해집니다.


VPC 피어링


Transit Gateway 리전 간 피어링
데이터베이스의 경우 DynamoDB의 글로벌 테이블을 다중 리전 간의 동기화된 No-SQL 데이터베이스로 활용할 수 있습니다. RDBMS로는 Aurora의 글로벌 데이터베이스와 리전 간 읽기 복제본 구성으로 통하여 빠른 로컬 읽기 및 재해 복구 용도로 활용할 수 있습니다.


DynamoDB 글로벌 테이블


Amazon Aurora 글로벌 데이터베이스
디커플링, 마이크로서비스
서비스 규모가 확장됨에 따라 단일 장애점(SPoF)를 식별하여 이를 최대한 제거하여야 서비스 안정성을 확보할 수 있게 됩니다. 이 단일 장애점을 제거하는 방편으로 고려할 수 있는 것이 상호의존성을 줄이는 디커플링이고, 마이크로서비스 아키텍처는 설계 사상부터 이러한 디커플링을 고려하고 있습니다.
디커플링
애플리케이션 간, 마이크로서비스 간 상호 의존을 줄이고 장애 전파를 최소화하기 위해 고려할 수 있는 것이 작업을 큐나 메시지로 처리하는 것입니다. 잘 알려진 SQS, SNS 외에도 Amazon MQ, AWS IoT Core, Amazon EventBridge 등 애플리케이션 간 메시지를 중개하거나 작업을 큐로 처리할 수 있는 관리형 서비스들을 사용하면 장애 전파를 최소화하고 유연하게 확장할 수 있는 아키텍처 수립에 도움이 됩니다. 한편으로, 캐시 레이어로 많이 활용하는 Redis 용 ElastiCache에서 제공하는 Pub/Sub 기능을 활용하여 애플리케이션 간 메시징을 처리하는 것으로 디커플링을 구현할 수도 있습니다.
마이크로서비스
애플리케이션들이 디커플링을 통하여 상호 의존성을 잘 낮추었다면, 마이크로서비스를 도입하여 배포 효율성과 서비스 안정성을 도모해 볼 수 있습니다. 마이크로서비스 구성에 적합한 컨테이너로 ECS나 EKS를 EC2 클러스터나 AWS Fargate를 활용하여 구현하고 자동 확장되도록 구성하고 각 노드가 마이크로서비스를 제공하도록 구축할 수 있습니다.
또한, AWS에서 제공하는 서버리스 서비스인 Lambda를 활용하면 AWS 서비스 간의 연계 및 마이크로서비스 백엔드를 완전관리형으로 서버 운영 부담 없이 자동 확장을 지원하는 형태로 운영할 수 있게 됩니다.
3. 마치며
게임 서비스 아키텍처는 장르별로도 다양하지만, 서비스 규모에 따라 그 복잡도가 천차만별입니다. 처음부터 크고 아름다운 아키텍처를 가지고 서비스를 시작할 수도 있지만, 그것이 항상 옳은 것은 아닙니다. 서비스 규모와 요구사항은 계속 변화하고 이에 유연하게 대응할 수 있는 아키텍처를 구성하기 위하여 필요한 고려사항들을 정리해 보았습니다. 짧은 지면에 조금이라도 더 다양한 영역을 간략하게라도 다루려고 하다 보니 지나치게 간략하게 다룬 부분들이 있어 아쉽습니다. 추가로 궁금하신 내용 및 기술 지원이 필요하신 내용이 있다면, 언제든지 aws-gaming-korea@amazon.com으로 문의하여 주시기 바랍니다.
– 김병수 – AWS 게임 솔루션즈 아키텍트
Source: 서비스 규모 확장에 따른 게임 서비스 아키텍처 개선