


Amazon Athena 및 Amazon QuickSight 기반 JSON 데이터 분석 및 시각화하기

구조화된 데이터는 여전히 많은 데이터 플랫폼의 근간을 이루고 있지만, 갈수록 더 많은 비구조화 또는 반구조화 데이터가 기존 정보를 강화하거나 새로운 통찰력을 창출하는 데 사용되고 있습니다. Amazon Athena는 매우 다양한 데이터에 대한 분석을 지원합니다. 이러한 데이터에는 쉼표로 분리된 값(CSV) 또는 Apache Parquet 파일을 포함된 테이블형 데이터, 정규표현식을 사용하여 로그 파일에서 추출된 데이터 및 JSON 형식의 데이터가 포함됩니다. Athena는 서버리스 솔루션이므로 관리가 필요한 인프라가 없으며 쿼리를 실행한 만큼만 요금을 지불하면 됩니다.
이 블로그 게시물에서는 JSON 형식 데이터를 사용하고 중첩된 데이터 구조를 테이블 보기로 변환하는 방법을 보여드리겠습니다. 데이터 엔지니어의 경우 이러한 유형의 데이터를 사용하는 것이 갈수록 중요해지고 있습니다. 예를 들어, 운영 시스템에서 API 기반의 데이터 피드를 사용하여 데이터 제품을 생성할 수 있습니다. 이러한 데이터는 고객에 대한 이해 및 상호 작용에 있어 보다 세분화된 관점을 추가하는 데 도움이 됩니다. 큰 그림을 이해하면 고객에 대한 이해를 높이고 맞춤화된 경험을 제공하고 결과를 예측하는 데 도움이 됩니다.
설명을 위해 처음부터 끝까지의 데이터 분석 전체 과정이 담긴 예를 들어 보겠습니다. 이 예에서는 API 작업을 통해 가져온 JSON 형식의 재무 데이터를 Amazon Athena에서 분석하고 결과는 Amazon QuickSight를 통해 시각화합니다.
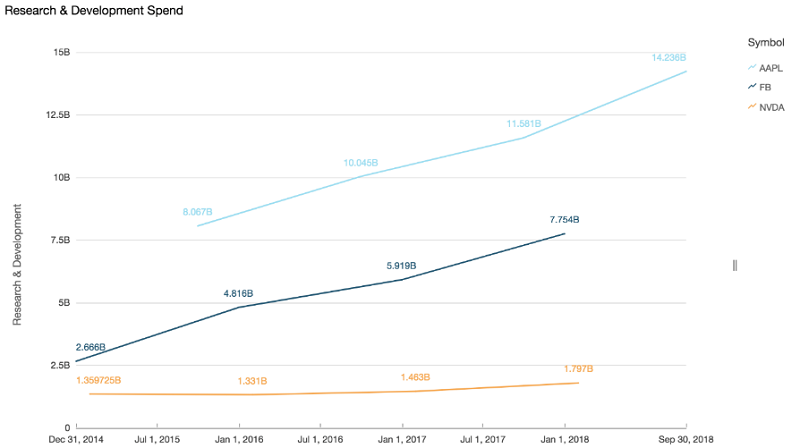
아래 그림은 분석 결과를 시각화 한 결과 입니다.

JSON 형식 데이터의 분석
이 엔드 투 엔드 예에서는 IEX에서 제공한 재무 데이터를 사용합니다. financials API 호출을 통해 특정 주식에 대해 보고된 4년 기간에 대해 수입 명세서, 대차대조표 및 현금 흐름 데이터를 가져옵니다.
아래에는 출력 예가 나와있습니다. 최상위 수준은 symbol이라는 속성으로서, APPL은 Apple을 의미합니다. 같은 수준에 있는 또 다른 속성은 financials입니다. 이 속성은 데이터 컨테이너입니다. reportDate, cashflow, researchAndDevelopment와 같은 속성을 포함하는 실제 정보는 한 수준 아래에 있습니다.
데이터 컨테이너는 배열입니다. 아래 예에는 단 1년에 대한 재무 데이터만 표시되어 있습니다. 그러나 {...}은 더 많은 정보가 있음을 가리키고 있습니다. 이 예에서는 실제 API 호출을 실행되었을 때 4년간의 데이터가 반환됩니다.
데이터는 IEX에서 무료로 제공했습니다(IEX 이용 약관 참조).
API 작업으로 가져온 외부 데이터를 Amazon S3로 저장하는 것은 이제 일반적인 방식이 되었습니다. 이 과정은 보통 자동화된 방식으로 수행되지만 여기서는 수동으로 API 호출의 결과를 가져오겠습니다.
데이터를 다운로드하려면 아래에 소개된 스크립트를 사용할 수 있습니다.
또는 세 가지 링크(1, 2, 3)를 클릭할 수 있습니다. 이를 통해 얻은 JSON 파일을 로컬 디스크에 저장한 다음 JSON을 Amazon S3 버킷에 업로드할 수 있습니다. 이 예에서는 데이터의 위치가 s3://athena-json/financials이지만 여러분이 이 예제를 따라 해 보실 때에는 자체 버킷을 생성해야 합니다. 결과는 다음과 비슷한 모습으로 나타납니다.


로컬 컴퓨터 또는 Amazon EC2 인스턴스에서 CLI 명령어를 사용하여 S3에 API 데이터를 업로드 할 수 있습니다.
테이블 구조에 JSON 구조를 매핑
이제 S3에 데이터가 채워졌으므로 Athena로 액세스 가능하도록 만들어보겠습니다. 다음은 간단한 2단계 절차입니다.
- 메타데이터를 생성합니다. 이것은 마치 DDL을 사용하여 테이블 구조를 설정하는 기존 데이터베이스와 유사합니다. 이 단계는 JSON 형식 데이터를 열에 매핑합니다.
- JSON 파일을 찾을 수 있는 위치를 지정합니다.
이 시점에서 JSON 파일의 모든 정보를 사용하거나 지금 필요한 정보를 매핑하는 데 집중할 수 있습니다. Athena의 새 데이터 구조는 파일을 S3에 가상 방식으로만 오버레이합니다. 그러므로 이 시점에 포함된 정보의 하위 세트를 매핑하더라도 모든 정보가 파일에 보존되므로 나중에 필요할 때 사용할 수 있습니다. 이는 강력한 개념으로서 데이터 모델링에 대한 반복적 접근 방식을 지원합니다.
다음의 SQL문을 사용하여 테이블을 생성할 수 있습니다. 테이블에는 financials_raw라는 이름이 지정됩니다(아래의 (1) 참조). 여기서부터는 이 이름을 사용하여 데이터에 액세스하게 됩니다. 재무 정보의 기호와 목록을 배열과 일부 수치에 매핑합니다. (2)에서 기반 파일을 JSON으로 해석할 것임을 정의하고 (3)에서 데이터가 다음 s3://athena-json/financials/에 상주함을 정의합니다.
이 SQL문은 아래와 같이 Athena 콘솔을 사용하여 실행할 수 있습니다.


왼쪽의 SQL문을 실행하면 이로 인해 생성된 financials_raw 테이블이 [Tables] 머리글 아래에 나열됩니다. 이제 이 테이블에 무엇이 있는지 살펴보겠습니다. 테이블 이름 오른쪽에 수직으로 있는 세 개의 점을 클릭하여 메뉴를 띄우고 여기서 [Preview table]을 선택합니다. Athena가 테이블에서 10개의 열을 표시하는 SELECT문을 생성합니다.


출력을 보면 Athena가 JSON 파일에 있는 기반 데이터를 이해하고 있었음을 알 수 있습니다. 구체적으로, 두 개의 열을 볼 수 있습니다.
symbol은 플랫 데이터인 주식 기호를 포함합니다.financials는 이제 재무 보고서의 배열을 포함합니다.
reportdate 속성을 자세히 보면 이 열에 둘 이상의 재무 보고서가 포함된 것을 알 수 있습니다.
데이터가 중첩되어 있더라도(이 예에서는 financials가 배열임) 열 프로젝션에서 요소에 직접 액세스할 수 있습니다.


앞에서 볼 수 있듯이 모든 데이터는 액세스 가능합니다. 여기서부터는 데이터가 구조화된 중첩 데이터로 취급되며 더 이상 JSON이 아닙니다.
그러나 아직도 테이블형은 아닙니다. 이 부분은 잠시 후에 다시 다루겠습니다. 먼저 여기까지 도달할 수 있는 또 다른 방식을 살펴 보겠습니다.
대체 접근 방식: 쿼리 시간까지 JSON 추출 지연
Athena에서 JSON 형식의 데이터를 사용하는 방법은 여러 가지가 있습니다. 이전 섹션에서는 간단하고 명시적이지만 경직된 접근 방식을 사용했습니다. 이제 이와는 대조적인 보다 일반적이고 동적인 접근 방식을 살펴 보겠습니다.
이 예에서는 데이터 구조에 대한 최종 결정을 테이블 설계 시 내리지 않고 쿼리 설계 시점까지 지연합니다. 이를 위해 데이터를 최대한 오랫동안 JSON 형식 그대로 유지합니다. 그 결과 CREATE TABLE문이 이전 섹션에서보다 훨씬 더 간결해집니다.
이는 데이터가 액세스 가능함을 보여줍니다.


이제 데이터를 액세스할 수 있지만 데이터는 string 또는 varchar로만 취급됩니다. 이 유형은 일반 유형이며 기반 데이터의 풍부한 구조 및 속성을 반영하지는 않습니다.
그러나 데이터의 풍부함을 살펴보기 전에, 쿼리 결과에서는 열이 어떤 데이터 유형인지를 보기 어렵다는 점을 강조해 드리고 싶습니다. 쿼리를 사용할 때에는 실제 데이터에 초점이 맞춰지므로 항상 데이터 유형을 보는 것은 방해가 될 수 있습니다. 그러나 이 예에서는 쿼리 및 데이터 구조를 생성할 때 typeof를 사용하는 것이 유용합니다. 예를 들어, 다음과 같은 SQL문을 사용합니다.
이 SQL문을 사용하면 열이 varchar 형식으로 취급됨을 직접 확인할 수 있습니다.
이제 쿼리 설계 중에 데이터 구조를 파악하기 위해 Athena는 JSON 형식의 데이터에서 속성을 추출하는 기능이 제공됩니다.
다음 표는 데이터를 첫 예의 레코드 루트에서 시작하여 데이터를 추출하는 방법을 보여줍니다. 그런 다음 이 표는 문서 트리 더 아래로 탐색해 내려가는 방법에 대한 추가 예를 보여줍니다. 첫 번째 열은 SELECT <expr> FROM financials_raw_json과 같은 SQL문에 사용할 수 있는 표현식을 보여줍니다(여기에서 <expr>는 첫 번째 열의 표현식으로 대체). 나머지 열은 결과를 설명합니다.
| 표현식 | 결과 | 유형 | 설명 |
json_extract(financials, '$') |
[{.., "reportdate":"2017-12-31",..},{..}, {..}, {.., "reportdate":"2014-12-31", ..}] |
json |
문서의 루트 선택(financials). |
json_extract(financials, '$[0]') |
{.., "reportdate":"2017-12-31", "totalcash":"41711000000", ..} |
json |
financials 배열의 첫 번째 요소 선택. 인덱싱은 1이 아니라 SQL의 관례에 따라 0에서 시작합니다. |
json_extract(financials, '$[0].reportdate') |
"2017-12-31" |
json |
financials 배열에서 첫 번째 요소의 totalcash 속성 선택. |
json_extract_scalar(financials, '$[0].reportdate') |
2017-12-31 |
varchar |
앞에서와 같지만 이제는 json_extract_scalar를 사용하므로 유형은 varchar가 되었습니다. |
json_size(financials, '$') |
4 |
bigint |
financials 배열의 크기. 4는 각 JSON에 포함된 4년을 가리킵니다. |
이제는 이 예를 구현하기에 충분한 스킬을 확보했으므로 여기에서 중단하도록 하겠습니다.
Athena는 JSON처리와 관련해서 이 외에도 많은 함수가 제공됩니다. 자세한 내용은 Apache Presto 설명서를 참조하십시오. Athena는 AWS가 제공하는 Apache Presto 기반의 관리형 서비스입니다. 그러므로 정보를 찾을 때에는 Presto 설명서를 참조하는 것도 도움이 될 수 있습니다.
앞에서 소개한 JSON 함수를 사용해 보겠습니다.


첫 번째 접근 방식과 마찬가지로 여전히 열 내에 중첩된 데이터를 처리해야 합니다. 이렇게 함으로써, 앞에서 사용된 재무 보고서의 명시적 인덱싱을 제거할 수 있습니다.
접근 방식 비교
뒤로 돌아가 여기에 있는 최신 SQL 쿼리를 앞에서 본 SQL 쿼리와 비교하면 둘이 모두 동일한 출력을 생성하는 것을 볼 수 있습니다. 둘 다 같은 속성을 프로젝션하므로 표면적으로는 둘이 같아 보일 수도 있습니다. 그러나 자세히 살펴 보면 첫 번째 문은 CREATE TABLE 과정에 이미 생성된 구조를 사용하는 것을 볼 수 잇습니다. 이와 대조적으로 두 번째 접근 방식은 쿼리의 일부로 각 열에 대해 JSON 문서를 해석합니다.
쿼리 설계 과정에 데이터 구조를 해석하는 것은 서로 다른 SQL 쿼리에 대해 또는 동일한 SQL 쿼리 내에서도 구조를 변경할 수 있게 해 줍니다. 동일한 쿼리 내에서의 서로 다른 열 프로젝션은 동일한 데이터, 즉 동일한 열까지도 서로 다르게 해석할 수 있습니다. 데이터의 동적이고 차별화된 해석이 가치를 지니는 상황에서는 이러한 방식이 매우 강력한 기능을 제공할 수 있습니다. 한편, 유지관리 과정에 실수로 잘못된 해석이 생기지 않게 하려면 엄격한 주의를 기울여야 합니다.
두 접근 방식 모두 기반 데이터는 건드리지 않습니다. Athena는 물리적 데이터만 오버레이하므로 해석 구조의 변경이 빠릅니다. 어느 접근 방식이 더 적합한지는 의도한 용도에 따라 달라집니다.
이를 결정하려면 다음과 같은 질문을 던져 보십시오. 간단히 요약하자면, 의도한 사용자가 데이터 엔지니어입니까 아니면 데이터 과학자입니까? 이들은 여러 가지를 시험해 보고 생각을 수시로 바꾸고자 합니까? 이들은 동일한 데이터에 대해 서로 다른 사용 사례 기반의 해석을 원할 수 있습니다. 그렇다면 쿼리 설계 시까지 JSON 데이터를 그대로 두는 두 번째 접근 방식이 더 나을 것입니다. 또한 이들은 이 동적 접근 방식에 대한 액세스를 제공하는 JSON 확장에 대해 더 자세히 학습하고자 할 가능성이 높습니다.
반대로 사용자에게 안정적인 구조의 확립된 데이터 소스가 있는 경우에는 첫 번째 접근 방식이 더 좋습니다. 이 방식을 사용하면 사용자들이 기반 JSON 데이터 구조에 대한 정보 없이도 SQL만 사용하여 데이터를 쿼리할 수 있습니다.
아래의 대조 비교표를 사용하여 해당 사례에 적합한 접근 방식을 선택하십시오.
| 테이블 생성 시 데이터 구조 해석 실행 | 쿼리 생성 시 데이터 구조 해석 실행 |
| 데이터 구조에 대한 해석이 전체 테이블에 적용됩니다. 각 후속 쿼리는 동일한 구조를 사용합니다. | 데이터 해석이 개별 쿼리로 한정됩니다. 각 쿼리는 잠재적으로 데이터를 서로 다르게 해석할 수 있습니다. |
| 데이터 구조의 해석은 중앙 집중적으로 진화합니다. | 데이터 구조의 해석은 쿼리 단위 기반으로 변경될 수 있으므로 서로 다른 쿼리가 서로 다른 속도와 방향으로 진화할 수 있습니다. |
| 기반 데이터 구조에 대한 단일 해석이므로 사실에 대한 단일 버전을 제공하기가 쉽습니다. | 사실에 대한 단일 버전을 유지하기가 어려우며 동일한 데이터를 사용하는 서로 다른 쿼리 전반에 걸친 조율이 필요합니다. 고속으로 진화하는 데이터 해석은 사용 사례에 대한 이해의 진화와 쉽게 매칭될 수 있습니다. |
| 잘 이해되어 있으며 느린 속도로 의식적으로 진화하는 데이터 구조에 적합합니다. 기반 데이터 구조의 단일 해석이 변화 속도보다 더 높은 가치를 가집니다. | 실험적이고 고속으로 진화하는 데이터 구조 해석 및 사용 사례에 적합합니다. 변화 속도가 데이터 구조의 안정적인 단일 해석보다 더 중요합니다. |
| 생산 데이터 파이프라인이 이 접근 방식의 이점을 활용할 수 있습니다. | 실험적 데이터 분석이 이 접근 방식의 이점을 활용할 수 있습니다. |
두 접근 방식 모두 개발 수명 주기의 서로 다른 시점에서 잘 이용될 수 있으며 두 접근 방식 모두 서로간의 마이그레이션이 가능합니다.
하지만 현실에서는 이분법에 의해 딱 떨어지는 경우는 많지 않습니다. 이 예에서는 financials_raw 및 financials_raw_json 테이블을 유지하고 둘 다 동일한 기반 데이터를 액세스합니다. 데이터 구조는 단지 메타데이터에 불과하므로 두 방식 모두를 사용해도 실제 데이터가 중복 저장되는 것은 아닙니다.
예를 들어 데이터 엔지니어는 financials_raw를 그 속성과 의미를 잘 이해하고 있으므로 사용 사례 전반에 걸쳐 안정화된 생산 파이프라인의 소스로 사용할 수 있습니다. 동시에 데이터 과학자는 financials_raw_json을 빠르게 쿼리별로 조정 가능한 실험적 데이터 분석에 사용할 수 있습니다.
중첩 데이터로 작업하기
이 시점에서 Athena를 통해 JSON 형식이 지정된 데이터를 액세스할 수 있습니다. 그러나 기반 구조는 여전히 계층적이며 데이터는 여전히 중첩되어 있습니다. 많은 사용 사례, 특히 분석적 용도의 경우 테이블, 즉 열 형식으로 데이터를 표현하는 것이 보다 자연스럽습니다. 이는 또한 SQL 및 비즈니스 인텔리전스 도구에 사용되는 표준 방식입니다. 계층화된 데이터의 중첩을 해제하여 평평한 열로 만들려면 이 두 가지 접근 방식을 결합해야 합니다.
간소화를 위해 잠시 재무 보고서 예제를 접어두겠습니다. 대신 더 작은 예로 실험을 해 보겠습니다. 서로 다른 생각 방식을 결합하는 것은 이해가 어려울 수 있습니다. 작은 예와 실습을 통해 좀 더 쉽게 접근해 보겠습니다. 여기서 설명하는 코드를 Athena 콘솔로 복사하여 직접 실험해 보시기 바랍니다.
다음 코드는 모든 필수 요소를 포함하고 있으며 데이터를 합성하여 사용하고 있습니다. 따라서 실험에 사용하기에 특히 유용합니다.


데이터를 보면 재무 보고서의 경우와 유사한 것을 알 수 있습니다. 앞에서는 하나의 주식 기호에 대해 여러 개의 재무 보고서, 즉 하나의 상위 항목에 대해 여러 개의 하위 항목이 있었습니다. 데이터를 플랫하게 만들기 위해 먼저 각 상위 항목에 대한 개별 하위 항목의 중첩을 해제합니다. 그런 다음 각 하위 항목을 상위 항목과 상호 연결하여 각 하위 항목에 대해 하위 항목 및 상위 항목이 포함된 개별 열을 생성합니다.


다음 SQL문에서 UNNEST는 원본 테이블의 children 열을 파라미터로 사용합니다. 이 문은 child라는 새 열을 가진 데이터 세트를 생성합니다(이 열은 나중에 상호 연결). 그러면 SELECT문이 새 child 열을 직접 참조할 수 있습니다.


간단한 예로 실험해 보면 이 방식이 재무 보고서에 어떻게 적용될 수 있는지 쉽게 알 수 있을 것입니다.


끝! 정말 쉽지 않습니까?
이를 기반으로 비즈니스 사용자에게 제공할 데이터를 추출할 쿼리를 작성해 보겠습니다. 원시 데이터는 전혀 건드리지 않았기 때문에 여전히 JSON 형식이며 중첩된 계층 구조로 표현되어 있습니다. 새 보기는 이 모든 것을 알기 쉽게 보여주는 테이블형 보기를 제공합니다.
보기를 만들어 보겠습니다.
…그리고 나서 작업을 확인합니다.


이는 좋은 비즈니스 사용자에게 통찰력을 제공하는 인터페이스 역할을 합니다.
이전 단계는 JSON 구조를 열에 직접 매핑하는 초기 접근 방식에 기반했습니다. 앞에서 설명한 대체 경로도 살펴 보겠습니다. 대체 접근 방식에서처럼 데이터를 JSON 형식으로 더 오래 유지하면 어떤 모양이 될까요?
좀 더 다양한 구성을 위해 이 접근 방식에서는 json_parse도 등장합니다. 이 요소는 전체 JSON 문서를 구문 해석하고 재무 보고서의 목록 및 포함된 키-값 쌍을 ARRAY(MAP(VARCHAR, VARCHAR))로 변환합니다. 그런 다음 이 배열은 궁극적으로 열 프로젝션에 있는 하위 항목의 중첩 해제에 사용됩니다. JSON에 있는 element_at 요소를 사용하면 이름을 사용하여 값에 액세스할 수 있습니다. 또한 하위 쿼리를 정의하여 SQL문의 구조화를 돕도록 WITH가 사용되는 것을 볼 수 있습니다.
다음 쿼리를 실행하는 경우 앞의 접근 방식과 동일한 결과가 반환됩니다. 이 쿼리를 보기로 변환할 수도 있습니다.
데이터 시각화
처음 예로 돌아가 보겠습니다. 우리는 다른 비즈니스 인텔리전스 도구와의 인터페이스 역할을 하는 financial_reports_view를 생성했습니다. 이 블로그 게시물에서는 Amazon QuickSight를 사용한 시각화를 위한 데이터를 제공하는 데 이 보기를 사용하겠습니다. Amazon QuickSight는 Athena를 통해 데이터에 직접 액세스할 수 있습니다. 이 서비스는 세션 단위로 요금이 부과되므로 조직 내 모든 사용자가 직접 분석적 통찰력을 얻을 수 있습니다.
이제 서비스를 함께 설정해 보겠습니다. 먼저 보기를 선택하여 Athena에서 새 데이터 소스를 생성한 다음 이 데이터 소스를 사용하여 시각화 데이터를 채워넣겠습니다.
지금 생성하는 것은 이 게시물 맨 위에 있는 그래프입니다. 데이터를 시각적 스토리로 압축하는 작업에 관심이 없으며 데이터만 원하는 경우에는 결론 섹션으로 건너뛰셔도 됩니다.
Amazon QuickSight에서 Athena 데이터 소스 생성
Amazon QuickSight에서 데이터를 사용하려면 먼저 기반 S3 버킷에 대한 액세스 권한을 부여해야 합니다. 이미 다른 분석을 위해 이 작업을 수행하지 않은 경우에는 설명서에서 작업 방식을 참조하십시오.
Amazon QuickSight 홈 페이지의 오른쪽 상단 모서리에서 [Manage data]를 선택한 다음 [New data set]를 선택하고 Athena를 데이터 소스로 선정합니다. 다음 대화 상자에서 데이터 소스에 적절한 이름을 지정하고 [Create data source]를 선택합니다.


기본 데이터베이스와 [financial_reports_view] 보기를 선택한 다음 [Select]를 선택하여 확인합니다. Athena에서 여러 스키마를 사용한 경우 여기에서 원하는 데이터베이스로 선정할 수 있습니다.


다음 대화 상자에서는 빠른 분석을 위해 데이터를 SPICE로 가져오거나 직접 데이터를 쿼리하도록 선택할 수 있습니다.
SPICE는 Amazon QuickSight의 초고속 병렬 인 메모리 계산 엔진입니다. 이 예에서는 두 방식 모두 가능합니다. SPICE를 사용하면 데이터를 수동으로 새로 고치거나 일정을 사용하여 자동으로 새로 고치기 전까지 데이터는 Athena로부터 한 번만 로딩됩니다. 직접 쿼리를 사용하면 모든 쿼리가 Athena에서 실행됩니다.


해당 보기는 이제 Amazon QuickSight를 위한 데이터 소스가 되었으므로 데이터 시각화를 살펴보겠습니다.
Amazon QuickSight에서 그래프 생성


왼쪽에 데이터 필드가 표시되어 있습니다. reportdate는 달력 기호와 함께 표시되어 있으며 researchanddevelopment는 숫자로 표시되어 있는 것을 볼 수 있습니다. Amazon QuickSight는 Athena에서 사용자가 정의한 데이터 유형을 가져옵니다.
오른쪽의 캔버스는 여전히 비워져 있습니다. 이 캔버스에 데이터를 채우기 전에 사용 가능한 그래프 유형에서 [Line Chart]를 선택하겠습니다.


그래프를 채우려면 왼쪽의 필드 목록에서 해당 대상 위치로 필드를 끌어 놓습니다. 이 예에서는 reportdate를 x 축에 배치합니다. researchanddevelopment 수치를 값에 배치하여 y 축에 표시되도록 합니다. 기호를 [Color]에 배치하면 서로 다른 주식을 구분하는 데 도움이 됩니다.


그래프의 최초 버전이 이제 캔버스에 표시됩니다. 오른쪽 하단 모서리의 핸들을 끌면 원하는 대로 크기를 조정할 수 있습니다. 또한 오른쪽 상단 모서리의 드롭다운 메뉴에서 [Format visual]을 선택합니다. 이렇게 하면 시각화를 향상하는 추가 옵션이 포함된 대화 상자가 열립니다.
[Data labels] 섹션을 확장하고 [Show data labels]를 선택합니다. 변경 사항은 즉시 그래프에 반영됩니다.


데이터와 직접 상호 작용할 수도 있습니다. Amazon QuickSight에서는 reportdate가 DATE임을 이해하므로 그래프 하단에 날짜 슬라이더가 표시됩니다. 이 슬라이더를 사용하면 표시된 시간 범위를 조정할 수 있습니다.
다른 사용자 지정 요소를 추가할 수 있습니다. 이러한 요소로는 그래프 또는 축의 이름 변경, 그래프 크기 조정, 시각화 추가 등이 포함됩니다. 그 외에도 데이터 필터 추가, 대시보드에 그래프의 조합 표시 등의 사용자 지정이 가능합니다. 대시보드를 예약 보고서로 변환하여 매일 이메일로 발송할 수도 있습니다.
결론
우리는 S3에 저장된 JSON 형식의 데이터를 사용하는 방법을 살펴보았습니다. 그리고 JSON 형식 데이터를 Athena의 데이터 구조로 매핑하는 두 가지 접근 방식을 비교했습니다.
- 테이블 생성 시 JSON 구조를 열에 매핑.
- JSON 구조를 그대로 두고 대신 JSON 콘텐츠가 그대로 유지될 수 있도록 콘텐츠 전체를 하나의 문자열로 매핑. JSON 콘텐츠는 나중에 해석하여 쿼리 생성 시 구조를 열에 매핑할 수 있습니다.
이러한 접근 방식은 상호 배타적이지 않으며 동일한 기반 데이터에 병렬로 사용될 수 있습니다.
그 뿐 아니라 JSON 데이터는 계층 구조를 가질 수 있으며 데이터를 플랫한 구조의 테이블 형태로 제공하려면 이 계층 구조를 중첩 해제하고 상호 연결해야 합니다.
이 예에서는 데이터를 테이블 형식으로 제공했으며 사용자에게 복잡성을 숨기도록 변환을 캡슐화하는 보기를 생성했습니다. 우리는 이 보기를 Amazon QuickSight에 대한 인터페이스로 사용했습니다. Amazon QuickSight는 Athena 보기에 직접 액세스하고 데이터를 시각화할 수 있습니다.
JSON 사용에 대한 추가 사항
JSON 기능은 Athena에 있는 기존 SQL 중심의 함수와 잘 조화되지만 ANSI SQL과는 호환되지 않습니다. 또한 JSON 파일은 각 레코드를 개별 줄에 담아야 합니다(JSON Lines 웹 사이트 참조).
JSON SerDe 라이브러리 설명서에서는 속성 ignore.malformed.json을 사용하여 형식이 잘못된 JSON 레코드를 null로 처리할지 오류를 생성할지 여부를 나타내는 방법을 찾을 수 있습니다. 가능한 JSON SerDe 구현 방식 두 가지에 대한 자세한 정보는 설명서에 링크되어 있습니다. 필요한 경우 더 깊게 들어가 열 이름이 구문 해석되는 방식을 명시적으로 제어하여 예약 키워드와의 충돌을 방지하는 방법 등을 알아 볼 수 있습니다.
데이터를 효과적으로 저장하는 방법
이 모든 작업을 해 오는 동안 원시 데이터는 전혀 건드리지 않았습니다. 데이터를 해석하는 여러 방법을 정의했을 뿐입니다. 이 예에서는 작은 양의 데이터만 취급했으므로 이 접근 방식이 잘 작동했습니다. 이러한 개념을 대규모로 사용하려는 경우에는 데이터 파티셔닝을 적용하는 방법과 데이터를 더 큰 파일로 통합하는 방법 등을 고려해야 합니다.
데이터에 따라서는 Apache Parquet과 같이 열 형식으로 저장하는 것이 더 나을 수 있습니다. 실용적인 추가 제안 사항은 AWS 빅 데이터 블로그 게시물 Top 10 Performance Tuning Tips for Amazon Athena를 참조하십시오.
이러한 옵션들은 이 게시물에서 배운 내용을 대체하는 것이 아니라 오히려 이제 JSON 형식의 데이터와 중첩된 데이터를 비교할 수 있는 능력을 갖춤에 따라 많은 도움이 될 수 있습니다. 이러한 옵션은 서로 보완적인 방식을 사용될 수 있습니다.
그 뿐 아니라 여기에 있는 AWS 빅 데이터 블로그 게시물은 실제 세계 시나리오를 통해 데이터를 효과적으로 저장하고 쿼리하는 방법을 단계적으로 안내합니다.
글쓴이 소개


그는 여가 시간에 부인과 함께 하이킹을 즐깁니다.
이 글은 AWS Big Data Blog의 Analyze and visualize nested JSON data with Amazon Athena and Amazon QuickSight의 한국어 번역으로 정도현 AWS 테크니컬 트레이너가 감수하였습니다.
Source: Amazon Athena 및 Amazon QuickSight 기반 JSON 데이터 분석 및 시각화하기