


Amazon DynamoDB Accelerator (DAX) – 읽기 작업을 위한 인-메모리 캐싱 기능
여러분은 이미 Amazon DynamoDB에 대해 잘 알고 계실 겁니다. 필요한 만큼만 사용하는 테이블 공간, 읽기 및 쓰기 용량을 자유롭게 변경가능한 확장성 높은 관리 NoSQL 데이터베이스입니다. 응답 시간은 수 밀리 초 단위로서 광고 기술, IoT, 게임, 미디어, 온라인 학습, 여행, 전자 상거래 및 금융 영역의 다양한 고객들이 여러 유형의 애플리케이션에서 사용하고 있습니다. 고객 중 일부는 단일 DynamoDB 테이블에 100 테라 바이트 이상을 저장하고 초당 수백만 건의 읽기 또는 쓰기 요청을 처리합니다. Amazon 소매 사이트는 DynamoDB를 사용하여 Black Friday, Cyber Monday 및 Prime Day와 같은 높은 트래픽을 처리하고 있습니다.
DynamoDB의 애플리케이션 및 작업 부하 성능 향상을 위해 일부 작업(게임 및 광고 서비스 등에서)에 대해 최대한 빨리 DynamoDB에서 데이터를 가져 오는 기능을 사용하면 클릭률 높은 게임 또는 광고를 더 빠르게 처리할 수 있습니다.
Amazon DynamoDB Accelerator 신규 출시
DAX는 DynamoDB 테이블 앞에 논리적으로 배치되는 완전 관리 캐싱 서비스입니다. 쓰기 모드(Write-Through)에서 작동하며 DynamoDB와 API 호환됩니다. 각 응답은 마이크로 초 단위로 캐시에서 반환되므로 DAX는 일관성 있는 읽기 집약적 작업 부하에 매우 적합합니다. DAX는 관리 서비스로서 유연하고 쉽게 사용할 수 있어, DAX 클러스터를 만들고 이를 기존 읽기 및 쓰기 방식으로 사용하면됩니다. 패치, 클러스터 유지 관리, 복제 또는 결함 관리에 대해 걱정할 필요가 없습니다.
각 DAX 클러스터에는 1-10개의 노드가 포함될 수 있습니다. 전체 읽기 처리량을 높이기 위해 노드를 추가 할 수 있습니다. 캐시 크기(작업 집합이라고도 함)는 클러스터를 만들 때 선택하는 노드 크기 (dax.r3.large에서 dax.r3.8xlarge)를 기반으로합니다. 클러스터는 노드가 가용 영역(AZ)에 걸쳐있는 VPC 내에서 실행됩니다.
DAX와 통신하려면 Java용 DAX SDK를 사용해야합니다. 이 SDK는 낮은 대기 시간과 높은 처리를 위한 저수준의 TCP 인터페이스를 사용하여 클러스터와 통신합니다 (가능한 한 빨리 다른 언어를 통한 DAX 접근 지원할 예정).
DAX 클러스터 만들기
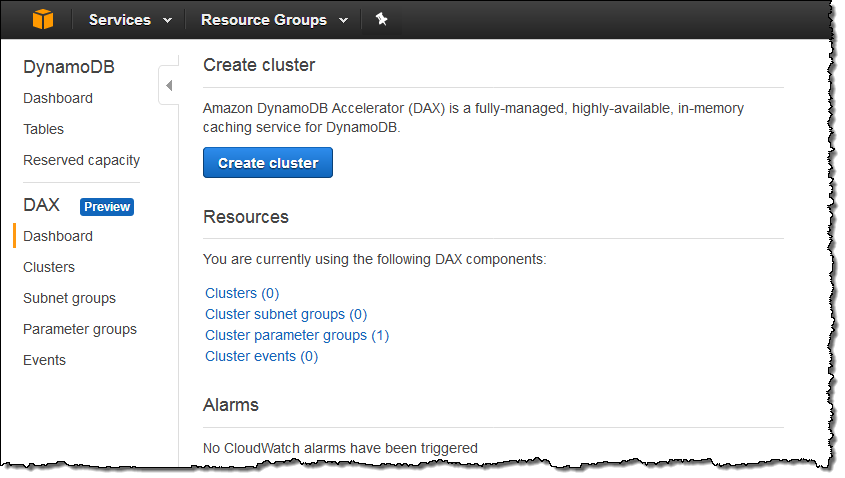
DynamoDB Console에서 DAX 클러스터를 만듭니다 (API 및 CLI 지원도 가능). 콘솔을 열고 Create cluster를 클릭하여 시작하십시오.

이름과 설명을 입력하고, 노드 유형을 선택하고, 클러스터 크기를 설정합니다. 그런 다음 DAX에서 DynamoDB 테이블에 접근할 수있는 권한을 부여하는 IAM 역할 및 정책을 만듭니다 (기존 역할을 선택할 수도 있음).
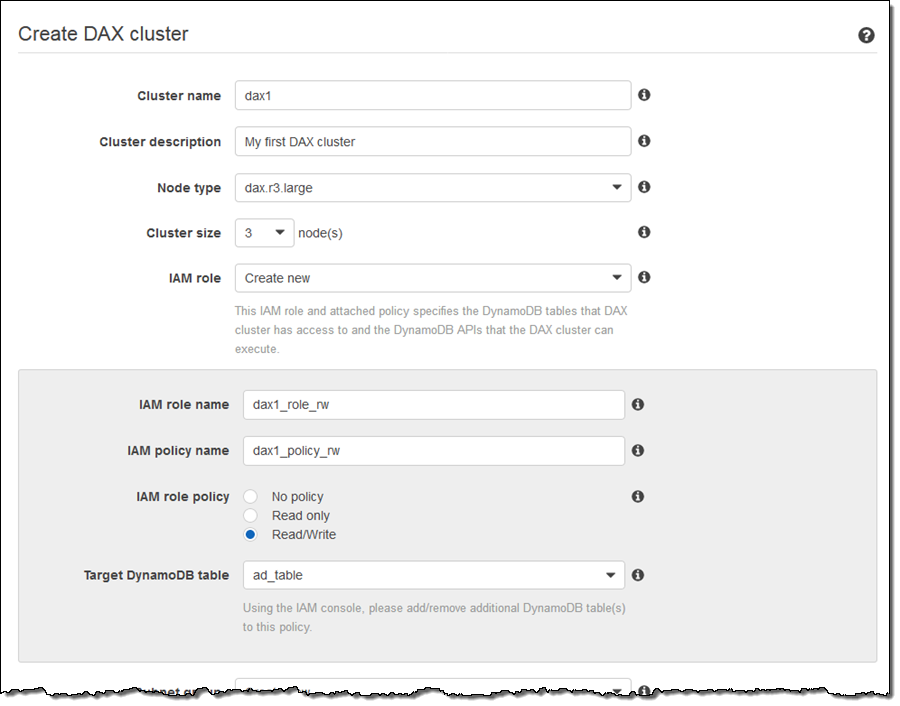

콘솔을 사용하면 단일 테이블에 대한 접근 권한을 부여하는 정책을 만들 수 있습니다. IAM Console을 사용하여 정책에 테이블을 추가합니다.
다음으로 DAX가 클러스터 노드를 배치하는 데 사용하는 서브넷 그룹을 만듭니다. 그룹의 이름을 지정하고 원하는 서브넷을 선택합니다.
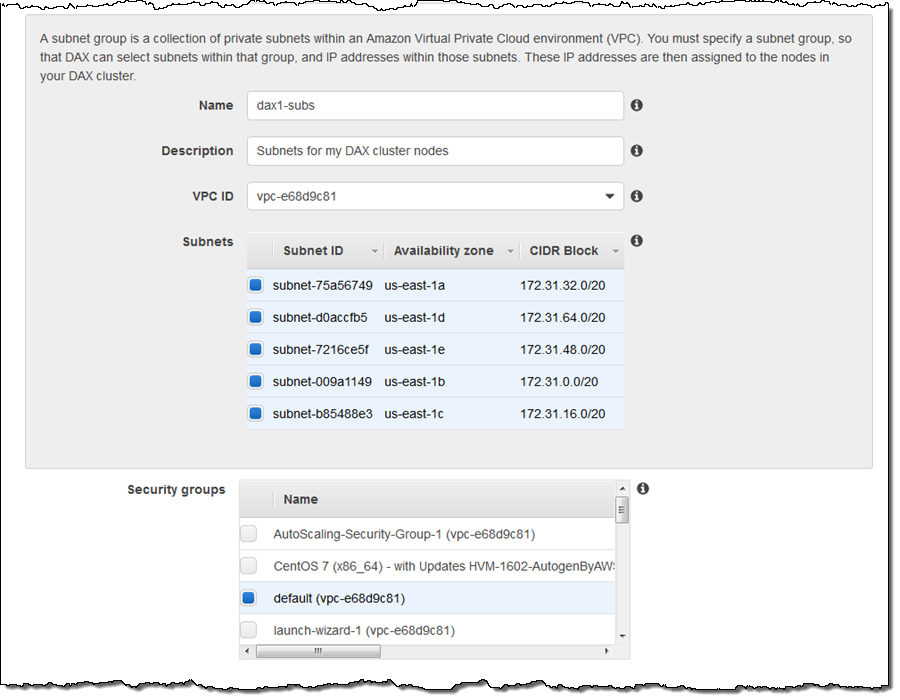

기본 설정을 그대로 사용하고 Launch cluster을 클릭합니다.

클러스터는 몇 분 안에 사용할 준비가 되었습니다.
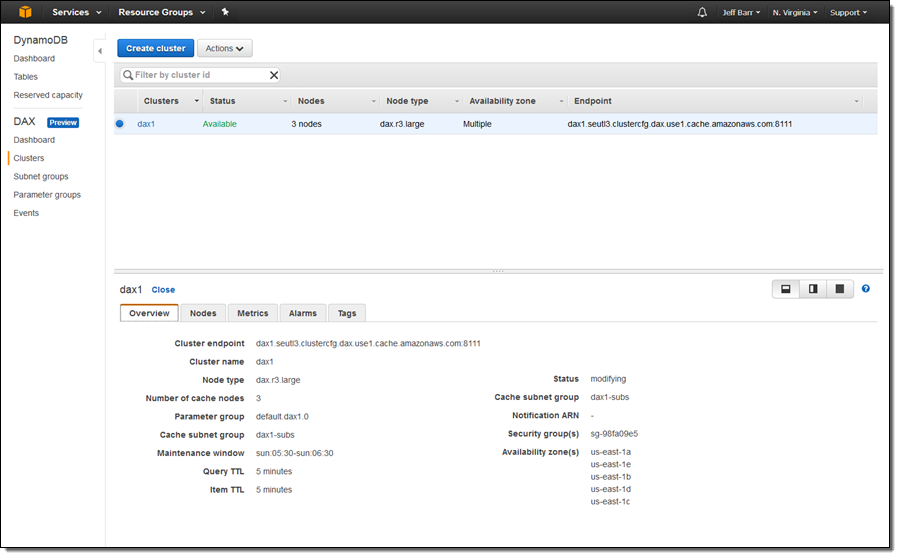

다음 단계는 애플리케이션을 업데이트하여 Java용 DAX SDK를 통해 클러스터 엔드포인트 (이 경우 dax1.seutl3.clustercfg.dax.use1.cache.amazonaws.com:8111)을 사용하도록 구성하는 것입니다.
애플리케이션이 실행되면, Metrics 탭을 방문하여 캐시 성능을 확인할 수 있습니다. Amazon CloudWatch 메트릭에는 캐시량 및 누락 횟수, 요청 횟수, 오류 카운트 등이 포함됩니다.
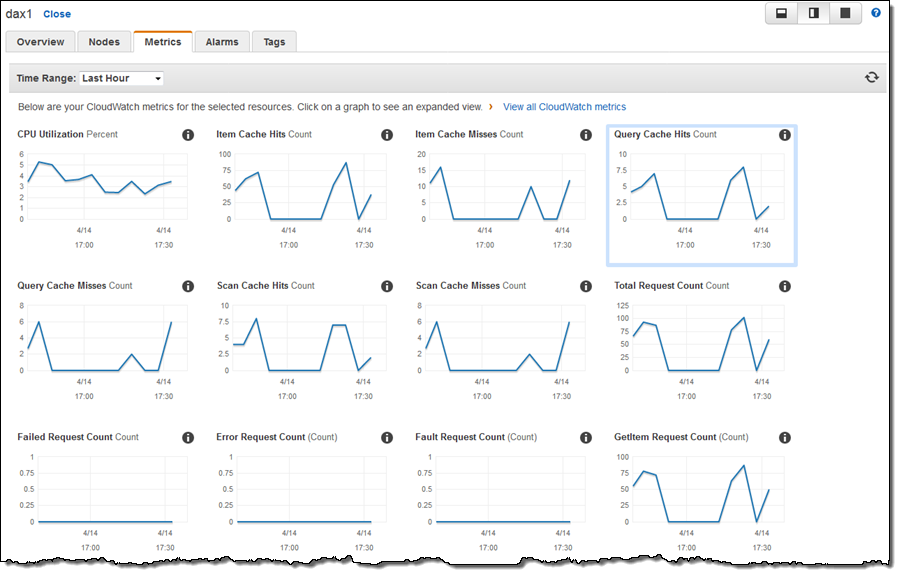

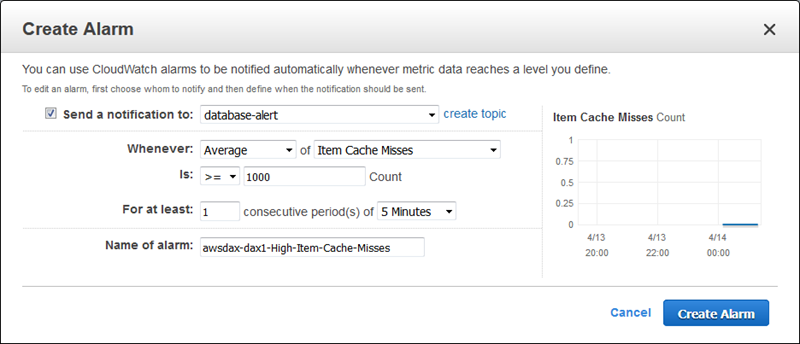
Alarms 탭을 사용하여 모든 측정 항목에 대한 CloudWatch 알람을 생성 할 수 있습니다. 캐시 누락이 발생하는지 알고 싶습니다.

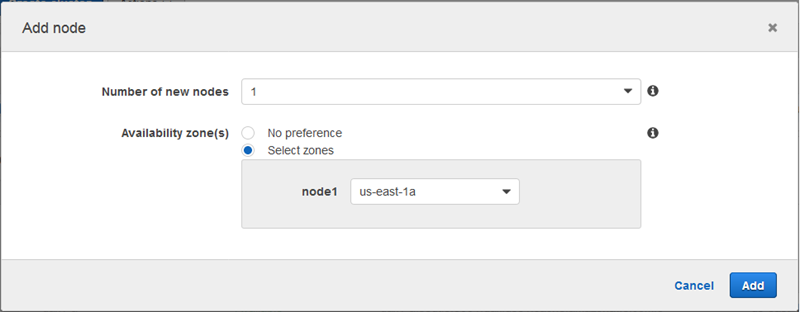
Node 탭을 사용하여 클러스터의 노드를 볼 수 있습니다. 새 노드를 추가하거나 기존 노드를 삭제할 수도 있습니다.

AX의 작동 방식을 확인하기 위해 DAX Sample Application을 설치하고 두 번 실행했습니다. 첫 번째 실행은 DynamoDB에 직접 접근하여 캐시 되지 않은 기본 성능을 시연했습니다.
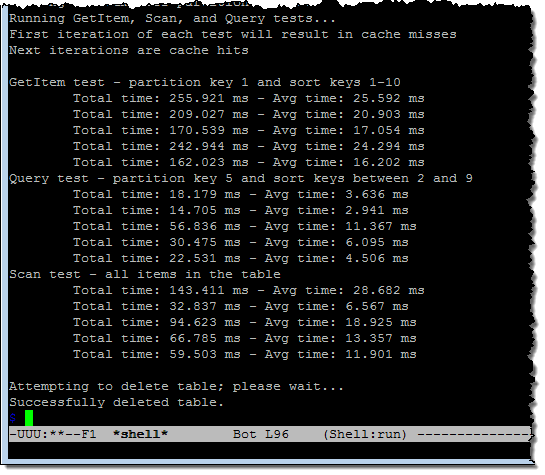

중간 결과 그룹에서 볼 수 있듯이 쿼리는 2.9에서 11.3 밀리 초 사이에 실행되었습니다. 두 번째 실행에서는 DAX를 사용하여 캐싱이 성능에 미치는 영향을 보여주었습니다.
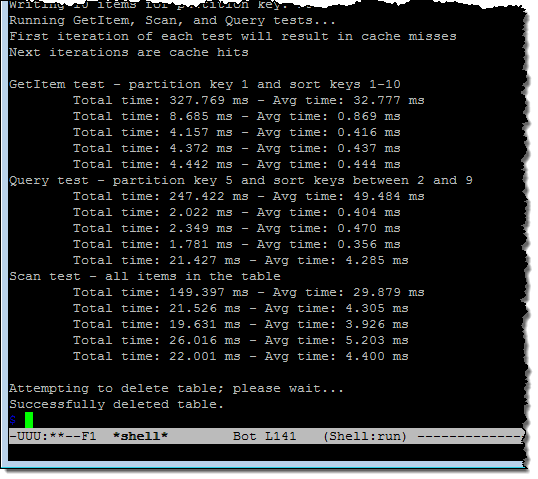

각 테스트의 첫 번째 반복은 캐시 실패를 초래합니다. 후속 실행에서는 캐시에서 결과를 검색하고 (알 수 있듯이) 상당히 빠르게 수행합니다.
알아두면 좋을 사항
다음은 DAX를 사용자 환경에서 사용하는 방법을 생각할 때 염두에 두어야 할 몇 가지 사항입니다.
- Java API – 앞서 언급했듯이 다른 언어에 대한 지원을 추가 할 계획으로 Java에 대한 지원으로 공개 미리보기를 시작합니다. DAX는 DynamoDB와 API 호환되므로 자체 캐싱 논리를 작성하거나 코드를 변경할 필요가 없습니다.
- 일관성 – DAX는 최종 일관성 있는 읽기를 사용할 때 성능 향상을 위한 최상의 기회를 제공합니다.
- 연속 쓰기(Write-throughs) – DAX는 연속 쓰기 캐시입니다. 다만, 읽기 내용과 작성한 내용 간에 약한 상관 관계가있는 경우 DynamoDB에 쓰기 작업을 할 수 있습니다. 이를 통해 DAX가 읽기에 더 큰 도움을 줄 수 있습니다.
- 프로비저닝 해제 – 사용자 환경에서 DAX를 사용하면 기본 테이블에 대해 프로비저닝 된 읽기 용량을 줄일 수 있어야합니다. 이렇게 하면 DAX가 급격한 사용량 증가에 대비 한 여유 용량을 제공 할 수 있게 하면서 비용을 절감 할 수 있습니다.
정식 출시
미국 동부 (버지니아 북부), 미국 서부 (오레곤) 및 EU (아일랜드) 지역에서 DAX의 공개 미리 보기를 사용할 수 있으며 오늘 가입 하기할 수 있습니다. 공개 미리보기를 무료로 사용할 수 있으며 DAX Developer Guide를 통해 더 많은 정보를 얻을 수 있습니다.
— Jeff;
이 글은 Amazon DynamoDB Accelerator (DAX) – In-Memory Caching for Read-Intensive Workloads의 한국어 번역입니다.
Source: Amazon DynamoDB Accelerator (DAX) – 읽기 작업을 위한 인-메모리 캐싱 기능