


Amazon ECS에서 기계 학습 추론을 위한 EC2 Inf1 인스턴스 정식 지원

기계 학습과 딥 러닝 모델이 더 정교해짐에 따라 높은 처리량으로 빠른 예측을 제공하는 데 필요한 하드웨어 가속의 중요성이 점점 더 커지고 있습니다. 오늘부터, AWS 고객은 Amazon ECS에서 Amazon EC2 Inf1 인스턴스를 사용하여 클라우드에서 성능을 개선하고 예측 비용을 절감할 수 있습니다. 이러한 인스턴스는 지난 몇 주 동안 Amazon Elastic Kubernetes Service에서도 제공되었습니다.
EC2 Inf1 인스턴스에 대한 기본 정보
Inf1 인스턴스는 AWS re:Invent 2019에서 출시되었습니다. 이 인스턴스는 AWS가 기계 학습 추론 워크로드를 가속화하기 위해 처음부터 빌드한 맞춤형 칩인 AWS Inferentia에 의해 지원됩니다.
Inf1 인스턴스는 최대 100Gbps의 네트워크 대역폭 및 최대 19Gbps의 EBS 대역폭으로 1, 4 또는 16개의 AWS Inferentia 칩과 함께 다양한 크기로 제공됩니다. AWS Inferentia 칩에는 네 개의 NeuronCore가 포함되어 있습니다. 각 코어는 고성능 시스톨릭 배열 행렬 곱셈 엔진을 구현하여 컨볼루션 및 트랜스포머와 같은 일반적인 딥 러닝 연산의 속도를 크게 높여줍니다. 또한 NeuronCore에는 대용량 온-칩(on-chip) 캐시가 장착되어 있어 외부 메모리 액세스를 줄임으로써 프로세스의 I/O 시간을 절감합니다. Inf1 인스턴스에서 여러 AWS Inferentia 칩을 사용할 수 있으면 칩 간에 모델을 분할하여 캐시 메모리에 완전히 저장할 수 있습니다. 또는 단일 Inf1 인스턴스에서 다중 모델 예측을 제공하기 위해 여러 모델 간에 AWS Inferentia 칩의 NeuronCore를 분할할 수 있습니다.
EC2 Inf1 인스턴스의 모델 컴파일
Inf1 인스턴스에서 기계 학습 모델을 실행하려면 AWS Neuron SDK를 사용하여 하드웨어에 최적화된 표현으로 기계 학습 모델을 컴파일해야 합니다. 모든 도구는 AWS Deep Learning AMI에서 쉽게 사용할 수 있습니다. 또한 자체 인스턴스에 모든 도구를 설치할 수도 있습니다. 자세한 지침은 Deep Learning AMI 설명서와 AWS Neuron SDK 리포지토리의 TensorFlow, PyTorch 및 Apache MXNet에 대한 자습서에서 찾아볼 수 있습니다.
아래 데모에서는 Inf1 인스턴스의 ECS 클러스터에 Neuron 최적화 모델을 배포하는 방법 및 TensorFlow Serving을 통해 예측을 제공하는 방법을 보여줍니다. 문제의 모델은 자연어 처리 작업을 위한 최첨단 모델인 BERT입니다. BERT는 수억 개의 파라미터가 있는 거대한 모델로, 하드웨어 가속에 아주 적합한 후보입니다.
Amazon ECS 클러스터 생성
클러스터 생성은 가장 간단한 작업입니다. CreateCluster API를 호출하면 됩니다.
$ aws ecs create-cluster --cluster-name ecs-inf1-demo
즉시 콘솔에 새 클러스터가 표시됩니다.

이 클러스터에 인스턴스를 추가하기 전에 몇 가지 사전 조건을 충족해야 합니다.
- ECS 인스턴스에 대한 AWS Identity and Access Management(IAM) 역할: 아직 없는 경우 설명서에서 지침을 확인할 수 있습니다. 여기서 제 역할의 이름은
ECSInstanceRole입니다. - ECS 에이전트와 지원 Inf1 인스턴스가 포함된 Amazon Machine Image(AMI): 직접 구축하거나 ECS-optimized AMI for Inferentia를 사용할 수 있습니다. us-east-1 리전에서 이 AMI의 ID는
ami-04450f16e0cd20356입니다. - TensorFlow Serving(gRPC의 경우 8500, HTTP의 경우 8501)을 위한 네트워크 포트를 여는 보안 그룹: 제가 사용할 식별자는
sg-0994f5c7ebbb48270입니다. - ssh 액세스를 원하는 경우 보안 그룹에서 포트 22도 열어야 하며 SSH 키 페어의 이름을 전달해야 합니다. 제 보안 그룹의 이름은
admin입니다.
인스턴스를 클러스터에 조인하려면 작은 사용자 데이터 파일을 생성해야 합니다. 이 파일을 생성하려면 ECS 에이전트의 구성 파일에 작성되는 환경 변수에 클러스터 이름을 저장합니다.
#!/bin/bash
echo ECS_CLUSTER=ecs-inf1-demo >> /etc/ecs/ecs.config
설정이 끝났습니다. 이제 RunInstances API를 사용하여 Inf1 인스턴스 몇 개를 추가합니다. 비용을 최소화하기 위해 스팟 인스턴스를 요청합니다.
$ aws ec2 run-instances
--image-id ami-04450f16e0cd20356
--count 2
--instance-type inf1.xlarge
--instance-market-options '{"MarketType":"spot"}'
--tag-specifications 'ResourceType=instance,Tags=[{Key=Name,Value=ecs-inf1-demo}]'
--key-name admin
--security-group-ids sg-0994f5c7ebbb48270
--iam-instance-profile Name=ecsInstanceRole
--user-data file://user-data.txt
두 인스턴스가 EC2 콘솔에 즉시 나타납니다.

몇 분이 지나면 클러스터에서 작업을 실행할 수 있게 됩니다.

인프라가 준비되었습니다. 이제 BERT 모델을 저장할 컨테이너를 구축합시다.
Inf1 인스턴스용 컨테이너 구축
Dockerfile은 꽤 간단합니다.
- Amazon Linux 2 이미지에서 시작하여 TensorFlow Serving에 사용할 포트 8500과 8501을 엽니다.
- 그런 다음 Neuron SDK 리포지토리를 리포지토리 목록에 추가하고 AWS Inferentia를 지원하는 TensorFlow Serving 버전을 설치합니다.
- 마지막으로 BERT 모델을 컨테이너 내부에 복사하고 시작할 때 로드합니다.
다음은 전체 파일입니다.
FROM amazonlinux:2
EXPOSE 8500 8501
RUN echo $'[neuron] n
name=Neuron YUM Repository n
baseurl=https://yum.repos.neuron.amazonaws.com n
enabled=1' > /etc/yum.repos.d/neuron.repo
RUN rpm --import https://yum.repos.neuron.amazonaws.com/GPG-PUB-KEY-AMAZON-AWS-NEURON.PUB
RUN yum install -y tensorflow-model-server-neuron
COPY bert /bert
CMD ["/bin/sh", "-c", "/usr/local/bin/tensorflow_model_server_neuron --port=8500 --rest_api_port=8501 --model_name=bert --model_base_path=/bert/"]
그런 다음 컨테이너를 구축하고 Amazon Elastic Container Registry에서 호스팅되는 리포지토리로 푸시합니다. 평상시와 마찬가지로요.
$ docker build -t neuron-tensorflow-inference .
$ aws ecr create-repository --repository-name ecs-inf1-demo
$ aws ecr get-login-password | docker login --username AWS --password-stdin 123456789012.dkr.ecr.us-east-1.amazonaws.com
$ docker tag neuron-tensorflow-inference 123456789012.dkr.ecr.us-east-1.amazonaws.com/ecs-inf1-demo:latest
$ docker push
이제 클러스터에서 이 컨테이너를 실행하기 위해 작업 정의를 생성해야 합니다.
Inf1 인스턴스에 대한 작업 정의 생성
아직 없는 경우 먼저 실행 역할(ECS 에이전트가 사용자 대신 API 호출을 수행할 수 있도록 허용하는 역할)을 생성해야 합니다. 자세한 내용은 설명서를 참조하십시오. 제 실행 역할의 이름은 ecsTaskExecutionRole입니다.
아래에 전체 작업 정의가 나와 있습니다. 보시다시피 두 개의 컨테이너가 있습니다.
- 제가 구축한 BERT 컨테이너는
neuron-rtd라는 사이드카 컨테이너입니다. 이 컨테이너는 BERT 컨테이너가 Inf1 인스턴스에 있는 NeuronCores에 액세스하는 데 사용됩니다.AWS_NEURON_VISIBLE_DEVICES환경 변수를 사용하면 컨테이너에 사용될 수 있는 환경 변수를 제어할 수 있습니다. 이 환경 변수를 사용하여 하나 이상의 특정 NeuronCores에 컨테이너를 고정할 수 있습니다.
{
"family": "ecs-neuron",
"executionRoleArn": "arn:aws:iam::123456789012:role/ecsTaskExecutionRole",
"containerDefinitions": [
{
"entryPoint": [
"sh",
"-c"
],
"portMappings": [
{
"hostPort": 8500,
"protocol": "tcp",
"containerPort": 8500
},
{
"hostPort": 8501,
"protocol": "tcp",
"containerPort": 8501
},
{
"hostPort": 0,
"protocol": "tcp",
"containerPort": 80
}
],
"command": [
"tensorflow_model_server_neuron --port=8500 --rest_api_port=8501 --model_name=bert --model_base_path=/bert"
],
"cpu": 0,
"environment": [
{
"name": "NEURON_RTD_ADDRESS",
"value": "unix:/sock/neuron-rtd.sock"
}
],
"mountPoints": [
{
"containerPath": "/sock",
"sourceVolume": "sock"
}
],
"memoryReservation": 1000,
"image": "123456789012.dkr.ecr.us-east-1.amazonaws.com/ecs-inf1-demo:latest",
"essential": true,
"name": "bert"
},
{
"entryPoint": [
"sh",
"-c"
],
"portMappings": [],
"command": [
"neuron-rtd -g unix:/sock/neuron-rtd.sock"
],
"cpu": 0,
"environment": [
{
"name": "AWS_NEURON_VISIBLE_DEVICES",
"value": "ALL"
}
],
"mountPoints": [
{
"containerPath": "/sock",
"sourceVolume": "sock"
}
],
"memoryReservation": 1000,
"image": "790709498068.dkr.ecr.us-east-1.amazonaws.com/neuron-rtd:latest",
"essential": true,
"linuxParameters": { "capabilities": { "add": ["SYS_ADMIN", "IPC_LOCK"] } },
"name": "neuron-rtd"
}
],
"volumes": [
{
"name": "sock",
"host": {
"sourcePath": "/tmp/sock"
}
}
]
}마지막으로 RegisterTaskDefinition API를 호출하여 ECS 백엔드에 작업 정의를 알립니다.
$ aws ecs register-task-definition --cli-input-json file://inf1-task-definition.json
이제 컨테이너를 실행하고 컨테이너를 사용하여 예측을 수행할 수 있습니다.
Inf1 인스턴스에서 컨테이너 실행
이 서비스는 예측 서비스이므로 클러스터에서 항상 사용할 수 있어야 합니다. 단순히 작업을 실행하는 대신 필요한 수의 컨테이너 복사본이 실행 중인지 확인하고 오류가 발생할 경우 다시 시작하는 ECS 서비스를 생성합니다.
$ aws ecs create-service --cluster ecs-inf1-demo
--service-name bert-inf1
--task-definition ecs-neuron:1
--desired-count 1
잠시 후 두 작업 컨테이너가 모두 클러스터에서 실행되고 있음을 알 수 있습니다.
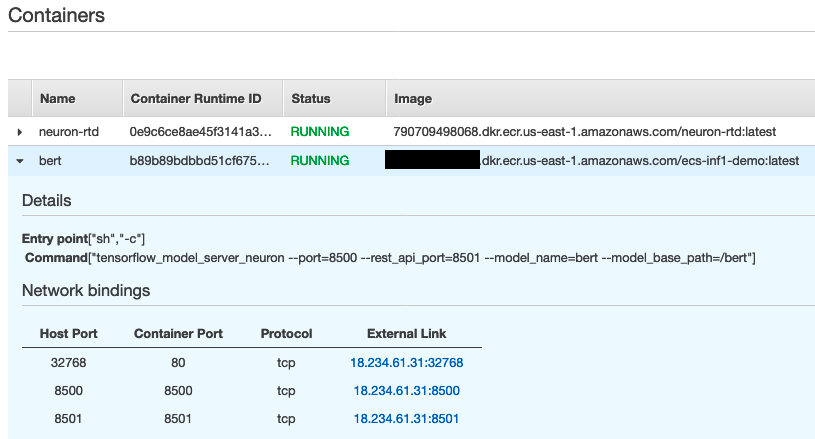

ECS 및 Inf1에서 BERT로 예측
BERT의 내부 작업은 이 게시물에서 다루지 않습니다. 이 특정 모델은 128개의 토큰 시퀀스를 예상하고 의미론적으로 동등한지 확인하기 위해 비교하려는 두 문장의 단어를 인코딩합니다.
여기서는 예측 지연 시간 측정에만 관심이 있으므로 더미 데이터가 좋습니다. 128개의 0으로 구성된 시퀀스를 저장하는 100개의 예측 요청을 빌드합니다. BERT 컨테이너의 IP 주소를 사용하여 grpc를 통해 TensorFlow Serving 엔드포인트로 요청을 보내고 평균 예측 시간을 계산합니다.
다음은 전체 코드입니다.
import numpy as np
import grpc
import tensorflow as tf
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
import time
if __name__ == '__main__':
channel = grpc.insecure_channel('18.234.61.31:8500')
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
request = predict_pb2.PredictRequest()
request.model_spec.name = 'bert'
i = np.zeros([1, 128], dtype=np.int32)
request.inputs['input_ids'].CopyFrom(tf.contrib.util.make_tensor_proto(i, shape=i.shape))
request.inputs['input_mask'].CopyFrom(tf.contrib.util.make_tensor_proto(i, shape=i.shape))
request.inputs['segment_ids'].CopyFrom(tf.contrib.util.make_tensor_proto(i, shape=i.shape))
latencies = []
for i in range(100):
start = time.time()
result = stub.Predict(request)
latencies.append(time.time() - start)
print("Inference successful: {}".format(i))
print ("Ran {} inferences successfully. Latency average = {}".format(len(latencies), np.average(latencies)))편의상 딥 러닝 AMI를 기반으로 하는 EC2 인스턴스에서 이 코드를 실행하고 있습니다. TensorFlow 및 TensorFlow Serving을 위한 Conda 환경이 사전 설치되어 있으므로 종속성을 설치하지 않아도 됩니다.
$ source activate tensorflow_p36
$ python predict.py
평균적으로 예측에는 56.5ms가 걸렸습니다. BERT를 사용할 때 이 속도는 꽤 빠른 것입니다.
Ran 100 inferences successfully. Latency average = 0.05647835493087769
시작하기
오늘부터 미국 동부(버지니아 북부) 및 미국 서부(오레곤) 리전의 Amazon ECS에 Amazon Elastic Compute Cloud(EC2) Inf1 인스턴스를 배포할 수 있습니다. Inf1 배포가 진전되면 더 많은 리전의 Amazon ECS에서 이 배포를 사용할 수 있게 될 것입니다.
이 인스턴스를 사용해 보고 기존 AWS Support 담당자, Amazon ECS의 AWS 포럼 또는 Github의 컨테이너 로드맵을 통해 피드백을 보내주십시오.