


Amazon EMR Serverless 정식 출시 – 서버리스 빅 데이터 애플리케이션 실행하기

AWS re:Invent 2021에서, 저희는 데이터 분석 서비스를 위한 세 가지 새로운 서버리스 옵션인 Amazon EMR Serverless, Amazon Redshift Serverless, 그리고 Amazon MSK Serverless을 소개합니다. 기본 인프라를 구성, 크기 조정 또는 관리할 필요 없이 모든 크기의 데이터를 더욱 쉽게 분석할 수 있습니다.
저희는 오늘 고객이 클러스터나 서버를 구성, 관리 및 크기 조정하지 않고도 Apache Spark 및 Hive와 같은 오픈 소스 프레임워크를 사용하는 빅 데이터 분석 애플리케이션을 실행할 수 있는 서버리스 배포 옵션인 Amazon EMR Serverless의 정식 출시를 발표합니다.

EMR Serverless를 사용하면 몇 초 안에 리소스의 크기를 조정하는 자동 크기 조정을 통해 모든 규모의 분석 워크로드를 실행하여, 변화하는 데이터 볼륨 및 처리 요구 사항을 충족시킬 수 있습니다. EMR Serverless는 리소스를 자동으로 확장 및 축소하여 애플리케이션에 적합한 용량을 제공하며, 사용한 만큼만 비용을 지불하면 됩니다.
사전 평가 기간 동안 EMR Serverless는 수요 급증에 대처하기 위해 리소스를 과도하게 프로비저닝해야 하는 비용이 발생하지 않기 때문에 비용 효율적이라는 고객의 의견을 들었습니다. 적절한 인스턴스 크기 조정이나 OS 업데이트 적용에 대해 걱정할 필요가 없으며 제품을 더 빨리 출시하도록 집중할 수 있습니다.
Amazon EMR은 Amazon Elastic Compute Cloud(Amazon EC2), Amazon Elastic Kubernetes Service(Amazon EKS) 클러스터, AWS Outposts, 또는 EMR Serverless의 EMR 클러스터와 같은 다양한 요구에 맞게 애플리케이션을 실행하기 위한 다양한 배포 옵션을 제공합니다.
- Amazon EC2 클러스터의 EMR은 애플리케이션 실행 방법을 최대한 제어하고 유연성이 필요한 고객에게 적합합니다. EMR 클러스터를 통해 고객은 EC2 인스턴스 유형을 선택하여 특정 애플리케이션의 성능을 향상시키고, Amazon Machine Image(AMI)를 사용자 지정하며, EC2 인스턴스 구성을 선택하고, 오픈 소스 프레임워크를 사용자 지정 및 확장하며, 클러스터 인스턴스에 추가 사용자 지정 소프트웨어를 설치할 수 있습니다.
- Amazon EKS의 EMR은 EKS로 표준화하여 여러 애플리케이션에서 클러스터를 관리하거나 동일한 클러스터에서 다양한 버전의 오픈 소스 프레임워크를 사용하려는 고객에게 적합합니다.
- AWS Outposts 상의 EMR은 Outpost 내의 데이터 센터와 더 가까운 곳에서 EMR을 실행하려는 고객을 위한 제품입니다.
- EMR Serverless는 클러스터 관리 및 운영을 피하고, 오픈 소스 프레임워크를 사용하여 애플리케이션을 실행하려는 고객에게 적합합니다.
또한 EMR 배포(예: EMR 배포 6.4를 사용하는 Spark 작업)를 사용하여 애플리케이션을 구축하는 경우, 애플리케이션을 다시 작성할 필요 없이 EMR 클러스터, EKS 상의 EMR 또는 EMR Serverless에서 실행하도록 선택할 수 있습니다. 따라서 지정된 프레임워크 버전에 대한 애플리케이션을 구축하고, 향후 운영 요구 사항에 따라 배포 모델을 변경할 수 있는 유연성을 유지할 수 있습니다.
Amazon EMR Serverless 시작하기
EMR Serverless를 시작하기 위해 엔드 투 엔드 개발 및 디버깅 환경을 제공하는 무료 EMR 기능인 Amazon EMR Studio를 사용할 수 있습니다. EMR Studio를 사용하면 EMR Serverless 애플리케이션(Spark 또는 Hive)을 생성하고, 애플리케이션의 오픈 소스 소프트웨어 버전을 선택하며, 작업을 제출하고, 실행 중인 작업의 상태를 확인하며, 작업 진단을 위해 Spark UI 또는 Tez UI를 호출할 수 있습니다.
시작 단추를 선택하면 EMR Serverless 콘솔에서 선택하면, 미리 구성된 EMR Serverless 애플리케이션을 사용하여 EMR Studio를 생성하고 설정할 수 있습니다.
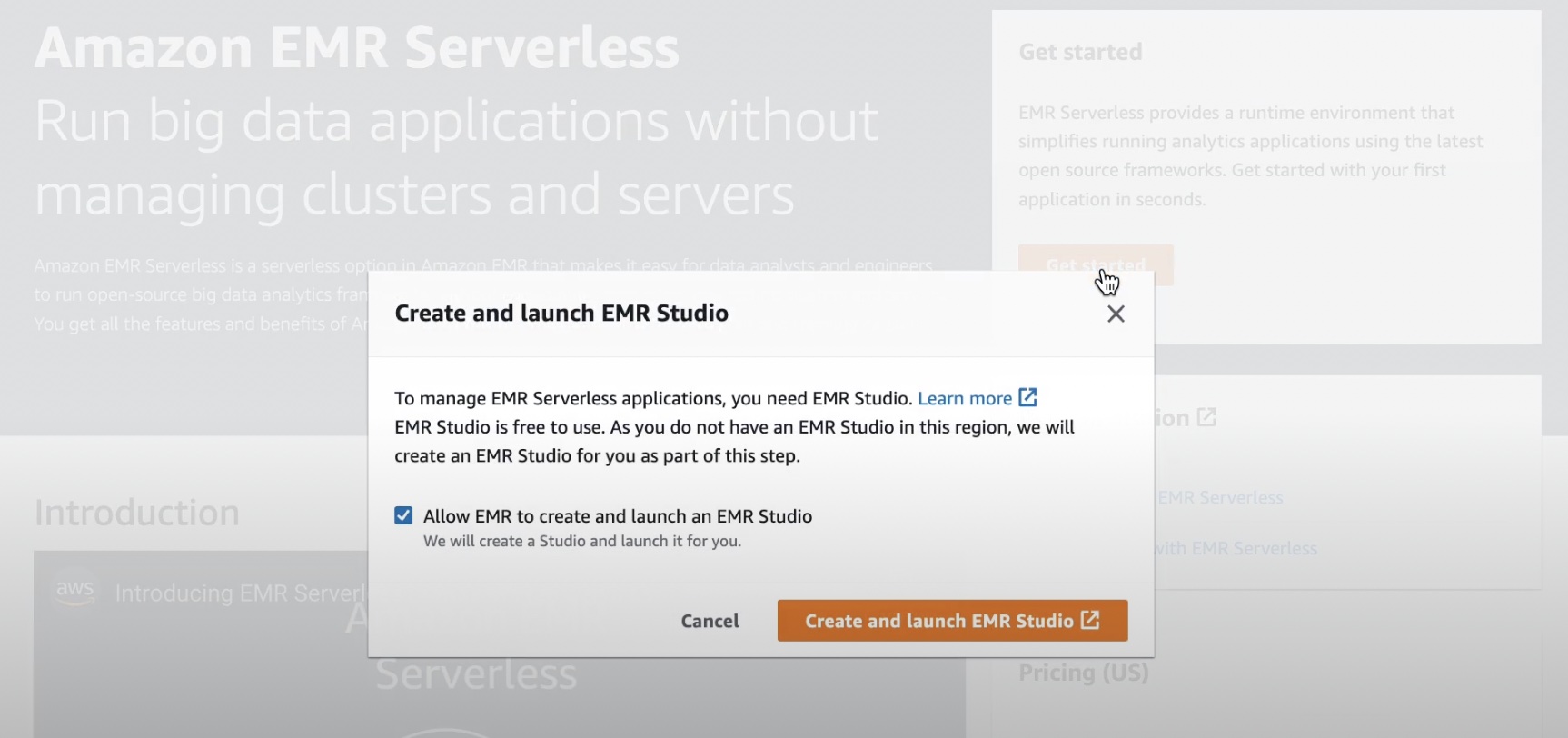

EMR Studio의 Serverless 메뉴에서 애플리케이션을 선택하면 하나 이상의 EMR Serverless 애플리케이션을 생성하고, 사용 사례에 맞는 오픈 소스 프레임워크 및 버전을 선택할 수 있습니다. 테스트 및 프로덕션 또는 서로 다른 사업 부문 사용 사례에 대해 별도의 논리 환경을 원하는 경우에는, 각 논리 환경에 대하여 별도의 애플리케이션을 생성할 수 있습니다.
EMR Serverless 애플리케이션은 (a)사용하려는 오픈 소스 프레임워크 버전의 EMR 릴리스 버전과 (b) Apache Spark 또는 Apache Hive와 같이 애플리케이션에서 사용할 특정 런타임의 조합입니다.
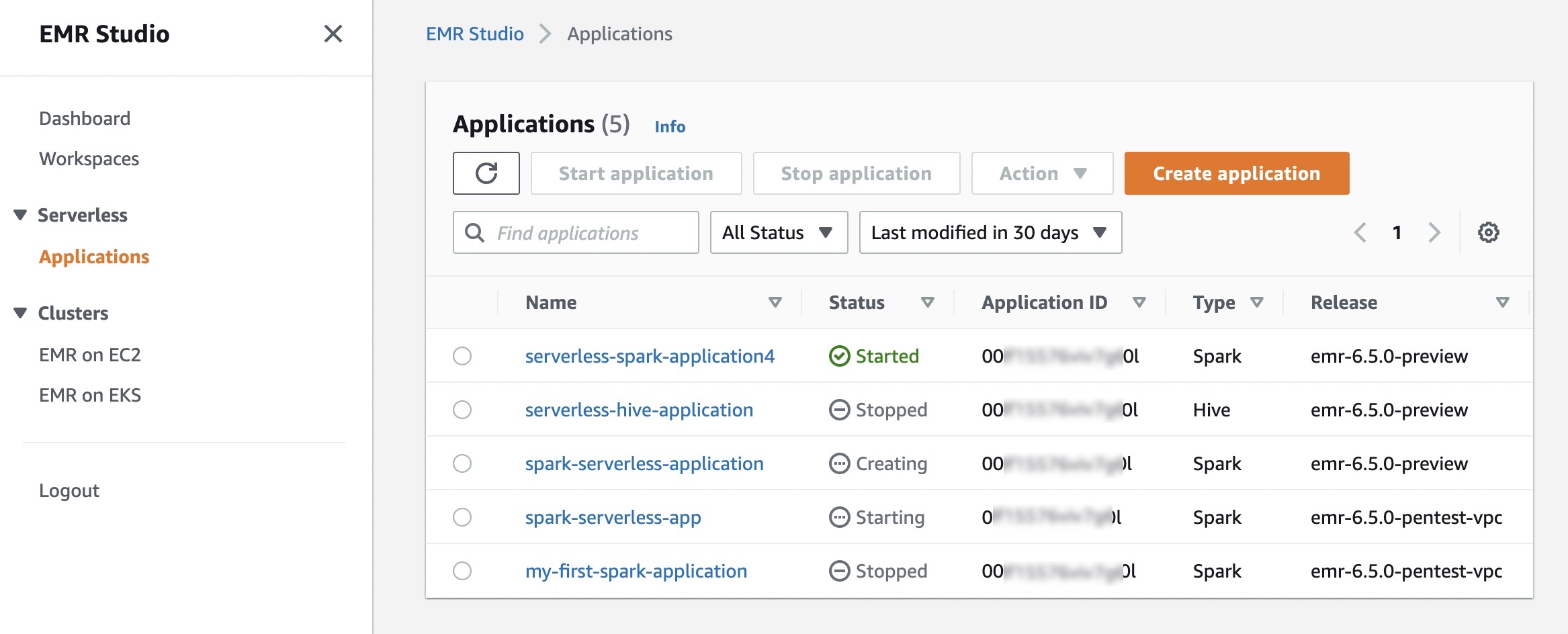

애플리케이션 생성을 선택하면, 애플리케이션 이름, Spark 또는 Hive 중 하나인 유형 및 배포 버전을 설정할 수 있습니다. 사전 초기화된 용량, 애플리케이션 제한 및 Amazon Virtual Private Cloud(VPC) 연결 옵션에 대한 기본 또는 사용자 지정 설정 옵션을 선택할 수도 있습니다. 각 EMR Serverless 애플리케이션은 다른 애플리케이션과 격리되어 있으며 보안 VPC 내에서 실행됩니다.
작업을 즉시 시작하려면 기본 옵션을 사용합니다. 그러나 신청이 시작되면 각 근로자에 대한 요금이 부과됩니다. 사전 초기화된 용량에 대한 자세한 내용은 사전 초기화된 용량 구성 및 관리를 참조하십시오.
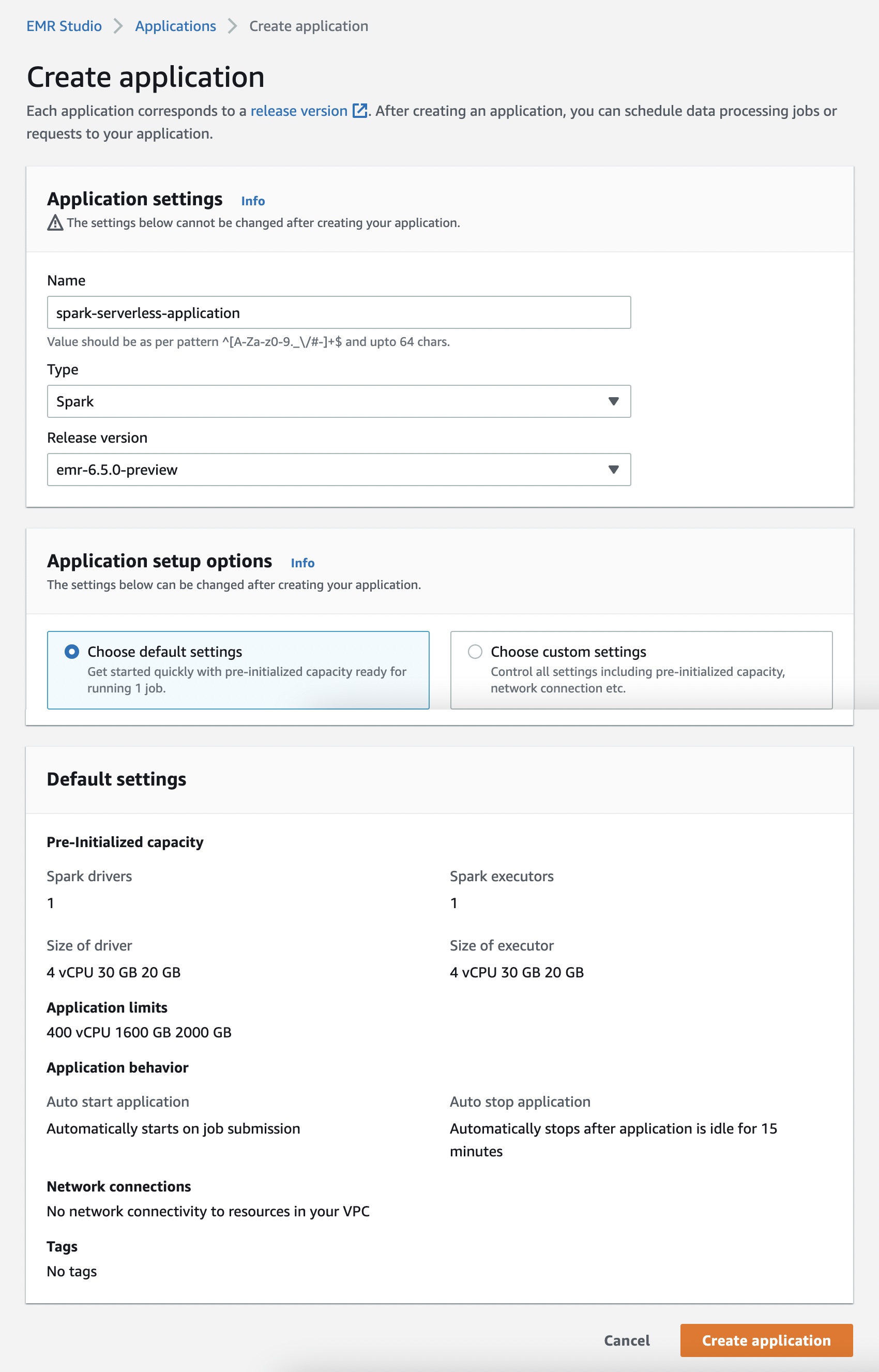

애플리케이션 시작을 선택하면 애플리케이션이 Spark 드라이버 1개와 Spark 실행기 1개로 사전 초기화된 용량으로 시작되도록 설정됩니다. 애플리케이션은 기본적으로 작업을 제출할 때 시작되고 애플리케이션이 15분 이상 유휴 상태일 때 중지되도록 구성됩니다.
사용자 지정 설정 선택을 선택하여 이러한 설정을 사용자 정의하고 다른 애플리케이션 제한을 설정할 수 있습니다.
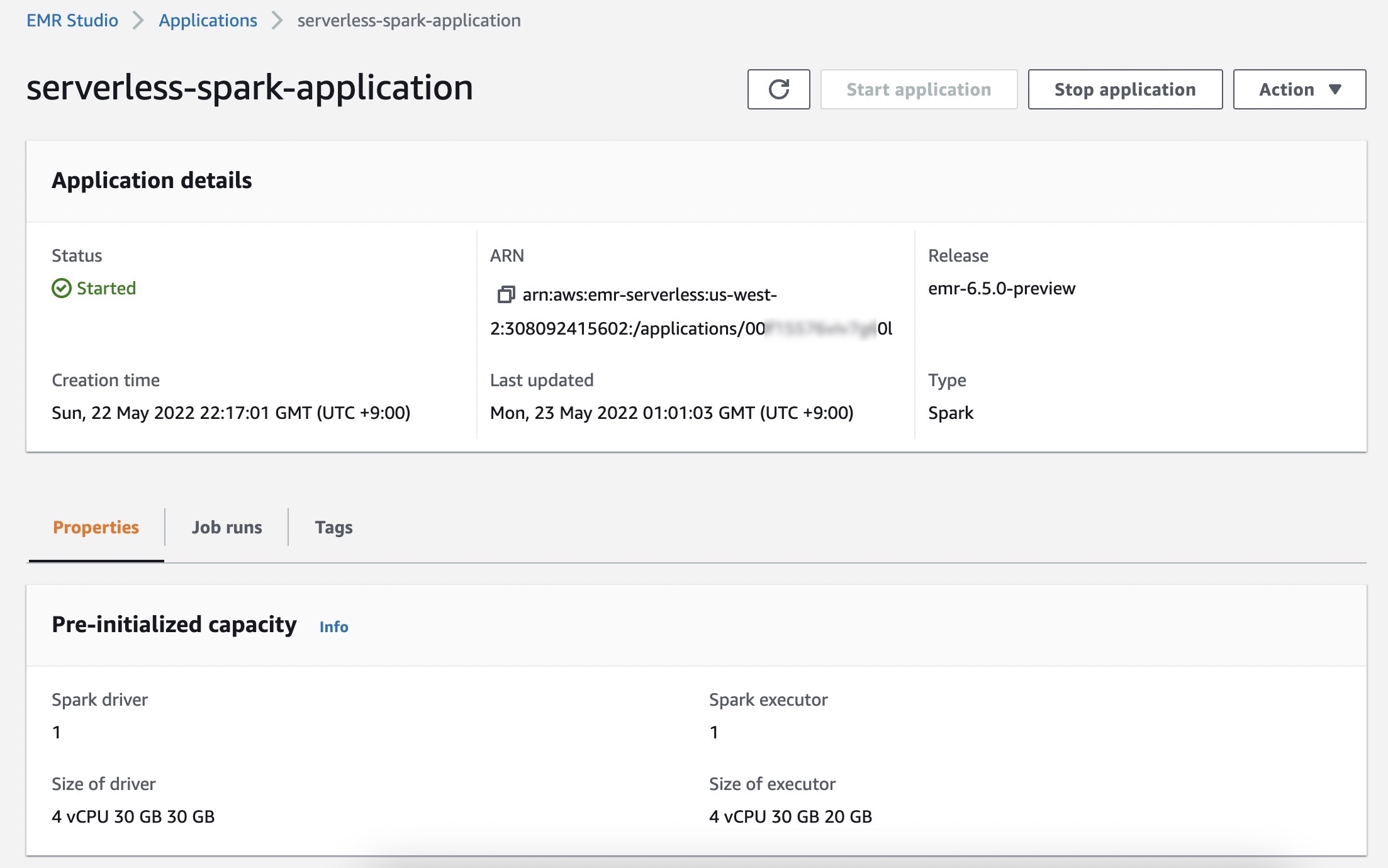

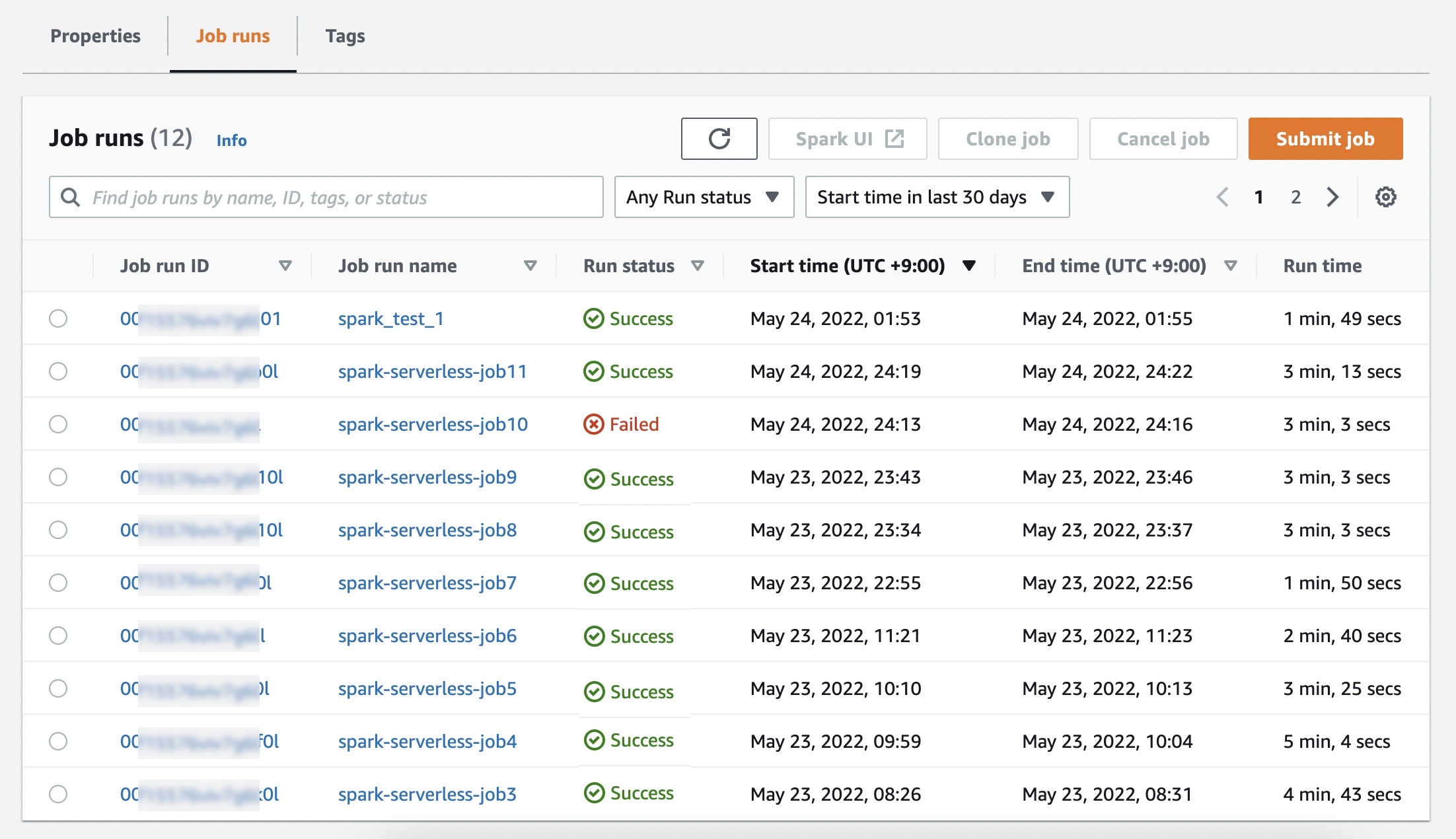
작업 실행 메뉴에서 애플리케이션에 대해 실행한 작업 목록을 볼 수 있습니다.

작업 제출을 선택하고, 작업이 사용한 AWS Identity and Access Management(IAM) 역할, 스크립트 위치 및 실행하려는 Amazon Simple Storage Service(Amazon S3) 버킷 내 JAR 또는 Python의 인수 등의 작업 세부 정보를 설정합니다.
Spark 또는 Hive 작업에 대한 로그를 S3 버킷으로 제출하려면, EMR Serverless 작업을 실행 중인 리전과 동일한 리전에 S3 버킷을 설정해야 합니다.
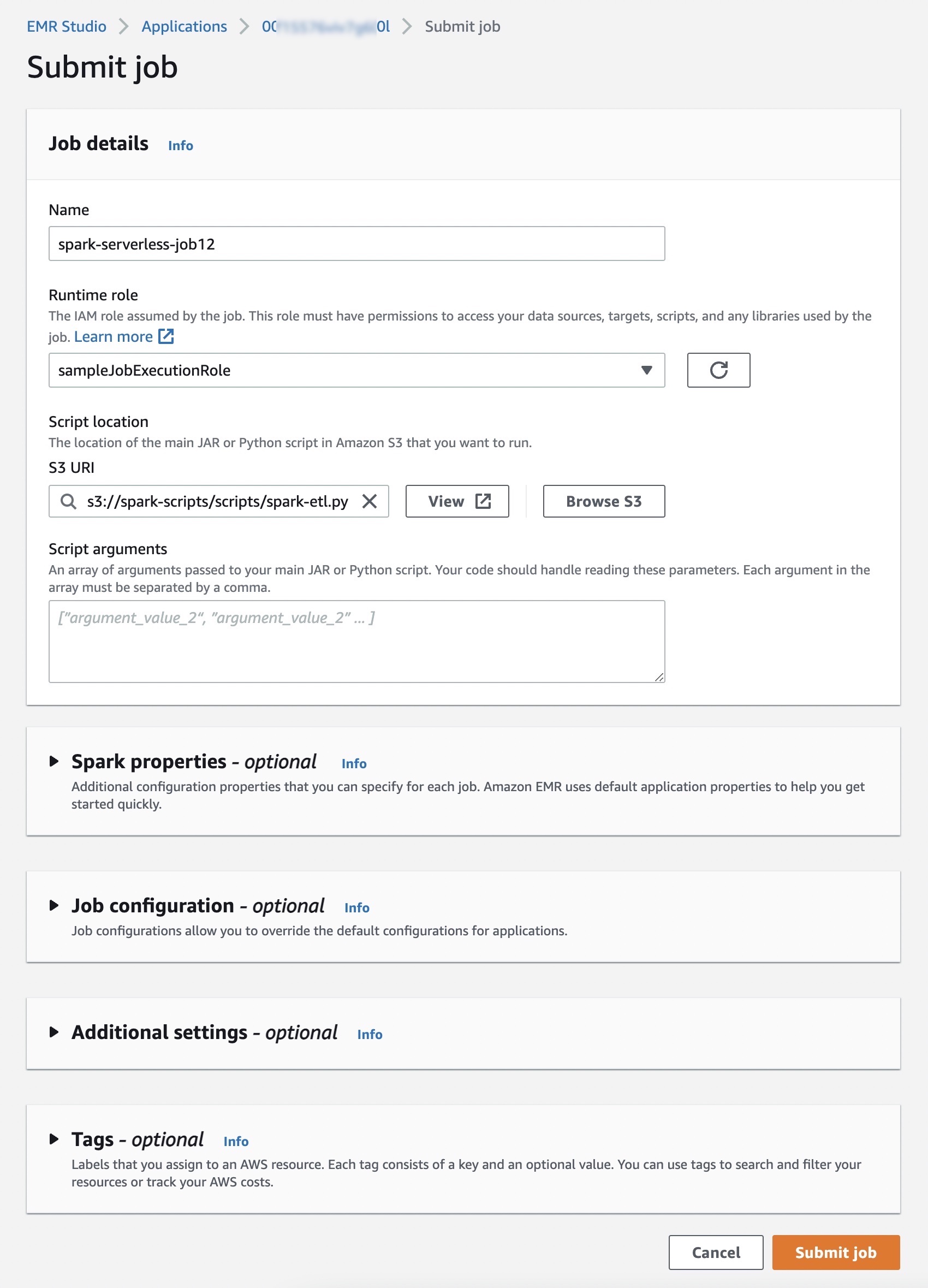

필요한 경우 Spark 속성, 애플리케이션의 기본 구성을 재정의하는 작업 구성(예: AWS Glue 데이터 카탈로그를 메타 스토어로 사용), Amazon S3에 로그 저장, 30일간 로그 유지 등 각 작업에 지정할 수 있는 추가 구성 속성을 설정할 수 있습니다.
다음은 StartJobRun API를 사용하여 Python 스크립트를 실행하는 예제입니다.
$ aws emr-serverless start-job-run
--application-id <application_id>
--execution-role-arn <iam_role_arn>
--job-driver '{
"sparkSubmit": {
"entryPoint": "s3://spark-scripts/scripts/spark-etl.py",
"entryPointArguments": "s3://spark-scripts/output",
"sparkSubmitParameters": "--conf spark.executor.cores=1 --conf spark.executor.memory=4g --conf spark.driver.cores=1 --conf spark.driver.memory=4g --conf spark.executor.instances=1"
}
}'
--configuration-overrides '{
"monitoringConfiguration": {
"s3MonitoringConfiguration": {
"logUri": "s3://spark-scripts/logs/"
}
}
}'S3 버킷에서 작업 결과를 확인할 수 있습니다. 자세한 내용은 Spark 애플리케이션용 Spark UI 및 작업 실행 메뉴의 Hive/Tez UI를 사용하여 작업 실행 방식을 이해하고, 실패한 경우에는 디버깅할 수 있습니다.

더 많이 디버깅하기 위해서, EMR Serverless는 Spark 애플리케이션의 S3 로그 대상에 있는 sparklogs 폴더로 이벤트 로그를 푸시합니다. Hive 애플리케이션의 경우 EMR Serverless는 Hive 드라이버 및 Tez 작업 로그를 S3 로그 대상의 HIVE_DRIVER 또는TEZ_TASK 폴더로 지속적으로 업로드합니다. 자세한 내용은 AWS 설명서의 로깅을 참조하십시오.
주요 사항
EMR Serverless를 사용하면 Amazon EMR 실행의 모든 이점을 누릴 수 있습니다. 사전 평가 발표의 AWS 빅 데이터 블로그 게시물에서 EMR 서버리스에 대해 알아야 할 몇 가지 사항을 인용하고 싶습니다.
- 자동 및 세분화된 확장– EMR Serverless는 작업 처리의 각 단계에서 작업자를를 자동으로 확장하고, 필요하지 않은 경우 작업자를 축소합니다. 작업자가 실행을 시작한 시점부터 중지될 때까지 사용된 총 vCPU, 메모리 및 스토리지 리소스에 대한 요금이 청구되며, 최소 1분 단위로 반올림됩니다. 예를 들어 작업을 처리하는 첫 10분 동안에는 10명의 근로자가 필요하고, 다음 5분 동안에는 50명의 근로자가 필요할 수 있습니다. 세분화된 자동 크기 조정을 사용하면 10분 동안 작업자 10명, 5분 동안 50명의 작업자에 대한 비용만 발생합니다. 따라서 활용도가 낮은 리소스에 대해서는 비용을 지불할 필요가 없습니다.
- 가용 영역 장애에 대한 복원력 – EMR Serverless는 리전 서비스입니다. EMR Serverless 애플리케이션에 작업을 제출하면 리전의 모든 가용 영역에서 작업을 실행할 수 있습니다. 가용 영역이 손상된 경우 EMR Serverless 애플리케이션에 제출된 작업이 다른 (정상) 가용 영역에서 자동으로 실행됩니다. 프라이빗 VPC에서 리소스를 사용할 때 EMR 서버리스는 여러 가용 영역에 대한 프라이빗 VPC 구성을 지정하여, EMR 서버리스가 정상 가용 영역을 자동으로 선택할 수 있도록 하는 것이 좋습니다.
- 공유 애플리케이션 활성화 – EMR Serverless 애플리케이션에 작업을 제출할 때 S3 객체와 같은 AWS 리소스에 액세스하기 위해 작업에서 사용해야 하는 IAM 역할을 지정할 수 있습니다. 따라서 서로 다른 IAM 보안 주체가 단일 EMR Serverless 애플리케이션에서 작업을 실행할 수 있으며 각 작업은 IAM 보안 주체가 액세스할 수 있는 AWS 리소스에만 액세스할 수 있습니다. 이렇게 하면 미리 초기화된 작업자 풀이 있는 단일 애플리케이션을 여러 테넌트에서 사용할 수 있는 시나리오를 설정할 수 있습니다. 각 테넌트는 다른 IAM 역할을 사용하여 작업을 제출할 수 있지만 사전 초기화된 작업자의 공통 풀을 사용하여 요청을 즉시 처리할 수 있습니다.
정식 출시
Amazon EMR Serverless는 미국 동부(버지니아 북부), 미국 서부(오레곤), 유럽(아일랜드), 아시아 태평양(도쿄) 리전에서 사용할 수 있습니다. EMR Serverless를 사용하면 선결제 비용이 없고, 사용한 리소스에 대해서만 비용을 지불하면 됩니다. 애플리케이션에서 사용하는 vCPU, 메모리 및 스토리지 리소스의 양에 대한 비용을 지불하면 됩니다. 요금 세부 정보는 EMR Serverless 요금 페이지를 참조하십시오.
자세한 내용은 Amazon EMR Serverless 사용 설명서를 참조하십시오. AWS EMR Serverless용 AWS re:Post에 피드백을 보내주시거나 일반 AWS Support 담당자를 통해 피드백을 보내주세요.
Amazon EMR Serverless에 대한 모든 세부 정보를 알아보고 지금 바로 시작하세요.
– Channy
Source: Amazon EMR Serverless 정식 출시 – 서버리스 빅 데이터 애플리케이션 실행하기