


Amazon Forecast로 MLOps를 적용한 AI 기반의 예측 자동화 구축하기

이 글은 Amazon Forecast를 사용하여 구축된 예측 모델을 개발하고 시각화하기 위한 MLOps (Machine Learning Operations) 파이프라인을 생성하는 방법을 안내합니다. 기계 학습(Machine Learning, ML) 워크로드는 확장이 필요하기 때문에 서로 다른 이해 관계자 간의 사일로를 없애고 비즈니스 가치를 파악하는 것이 중요합니다. MLOps 모델은 데이터 사이언스, 프로덕션 및 운영 팀이 자동화된 워크플로우 전반에 걸쳐서 원활하게 협력을 가능하게 하며, 문제없는 구현과 효율적이며 지속적인 모니터링을 보장하게 합니다.
소프트웨어 개발에서 말하는 데브옵스(DevOps) 모델과 마찬가지로, MLOps 모델은 ML의 코드를 빌드하고 ML 도구와 프레임워크 전반에 걸쳐 통합하는데 도움을 줍니다. 사용자 코드를 재작성하거나 기존 인프라를 고려할 필요 없이 데이터 파이프라인을 자동화, 운영 및 모니터링할 수 있습니다. MLOps는 기존 분산된 스토리지 및 인프라의 처리 과정을 확장하여 ML 모델을 규모에 맞게 배치하고 관리할 수 있도록 지원합니다. 또한 구성 전체의 모든 모델에 대해서 시간에 따른 드리프트를 중앙에서 추적 및 시각화가 가능하며 자동으로 데이터 검증에 대한 정책을 구현할 수 있습니다.
MLOps는 지속적인 통합, 지속적인 배포 및 지속적인 학습을 적용하여 DevOps와 ML 분야의 좋은 문화를 갖추고 있습니다. MLOps는 실제 프로덕션에서 ML 솔루션의 라이프사이클을 간소화하는 데 도움이 됩니다. 자세한 내용은 다음 백서인 Machine Learning Lens: AWS Well-Architected Framework를 참조하시기 바랍니다.
다음에는 Amazon Forecast, AWS Lambda 및 AWS Step Functions를 포함하는 MLOps 파이프라인을 활용해 시계열time-series 예측 모델을 구축, 학습 및 구현합니다. 생성된 예측을 시각화하기 위해 Amazon Athena 및 Amazon QuickSight와 같은 AWS 서버리스 서비스를 함께 사용합니다.
솔루션 아키텍처
여기에서는 Amazon Forecast 사용 및 배포를 자동화를 위한 블루프린트로 사용 가능한 MLOps 아키텍처를 배포합니다. 제공된 아키텍처와 샘플 코드를 사용하면 시계열 데이터에 대한 MLOps 파이프라인을 구축할 수 있으며, 이를 통해 예측을 생성해 향후 비즈니스 전략을 정의하고 고객 요구사항을 충족시킬 수 있게 됩니다
AWS 관리형 서비스를 사용하여 서버리스 아키텍처를 구축할 수 있기 때문에, ML 파이프라인을 생성하는 동안 인프라 관리에 대해 신경 쓸 필요가 없습니다. 이를 통해 새로운 데이터세트를 반복적으로 입력이 가능하고 하이퍼파라미터를 조정하여 모델 성능을 최적화가 가능합니다.
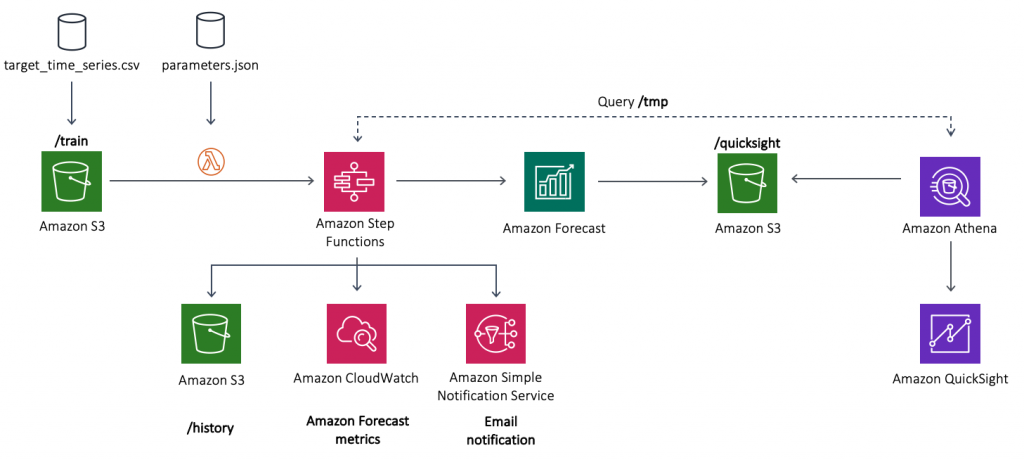
다음 다이어그램은 이 게시물 전체에 걸쳐 구축할 구성 요소를 보여 줍니다.

다이어그램 상 서버리스 MLOps 파이프라인은 Step Functions 워크플로우를 이용하여 배포됩니다. Lambda Function 은 Amazon Forecast 를 설정하고 결과를 Amazon S3(Amazon Simple Storage Service)로 출력하는 데 필요한 단계를 조정하게 됩니다.
아키텍처에는 다음 구성 요소가 포함됩니다.
- 시계열 데이터세트는/train 디렉토리(prefix접두사) 아래의 Amazon S3 클라우드 스토리지에 업로드됩니다.
- 업로드 된 파일은 Step Functions 상태 시스템State Machine을 사용하여 빌드 된 MLOps 파이프 라인을 시작하는 Lambda를 호출trigger합니다.
- 상태 시스템은 일련의 Lambda 함수를 연결하여 Amazon Forecast에서 ML 모델을 구축, 학습 및 배포합니다. 다음 섹션에서 상태 시스템의 Lambda 구성 요소에 대해 자세히 알아 봅니다.
- 로그 분석을 위해 상태 시스템은 Forecast 의 지표를 확인할 수 있는 Amazon CloudWatch 를 사용합니다. Amazon S3 버킷의 /forcast 디렉토리의 최종 예측 데이터을 사용할 수 있게 되면 Amazon SNS(Simple Notification Service) 를 사용하여 이메일 알림을 보냅니다. ML 파이프라인은 이전 예측값을 /history 디렉토리에 저장하게 됩니다.
- 마지막으로 Athena 및 QuickSight를 사용하여 현재 예측에 대한 시각적 프레젠테이션을 제공합니다.
이 게시물에서는 UCI Machine Learning 저장소에서 제공 되는 개별 가정용 전력 소비 데이터셋을 사용합니다. 시계열 데이터세트는 다양한 고객 가정의 시간당 에너지 소비를 집계하고 주중에 에너지 사용률이 급증한 것을 보여줍니다. 나중에 사용 사례에 따라 필요한 경우 샘플 데이터를 바꿀 수 있습니다.
이제 아키텍처에 대해 확인하였으므로 Step Functions 상태 시스템의 각 Lambda 구성 요소에 대한 세부 정보를 살펴보도록 하겠습니다.
Step Functions 를 사용하여 MLOps 파이프라인 구축
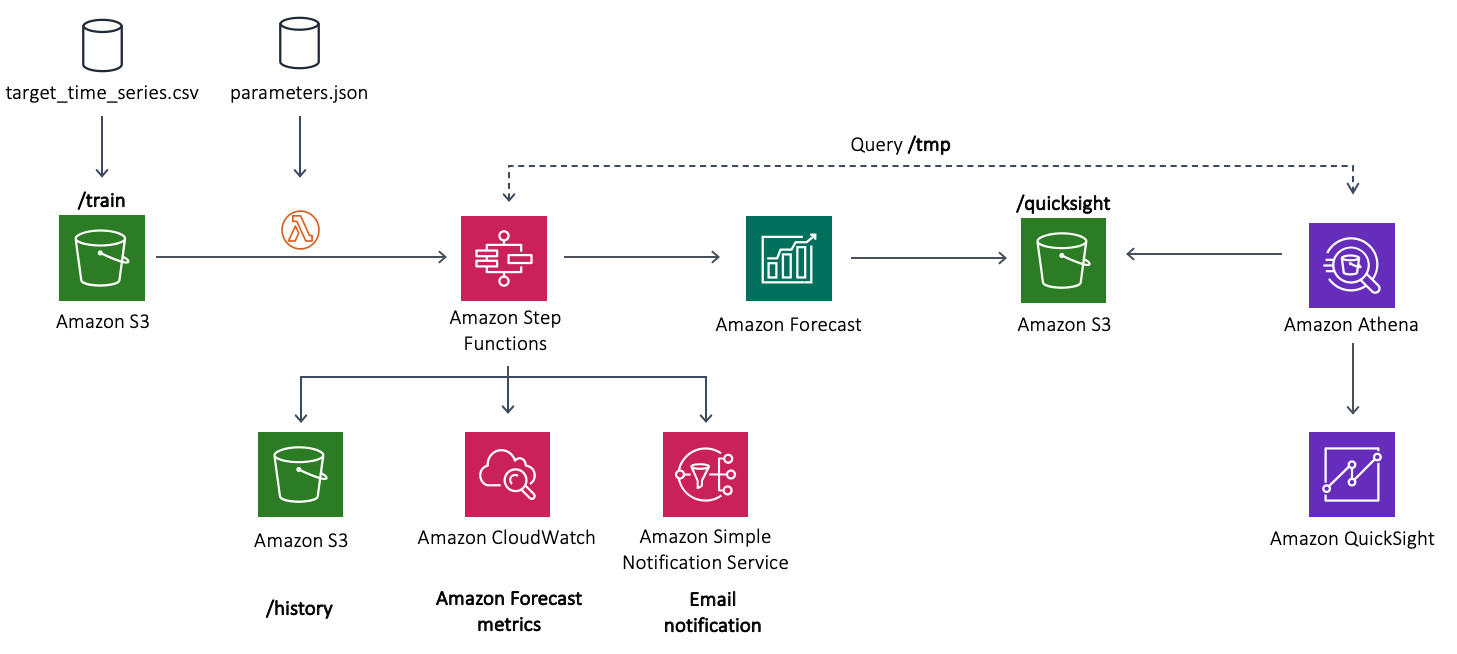
이전 섹션에서 Step Functions 상태 시스템이 전체 MLOps 파이프라인을 자동화하는 아키텍처의 핵심이라는 것을 알게 되었습니다. 다음 다이어그램에 상태 시스템을 사용하여 배포된 워크플로우를 확인할 수 있습니다.


앞의 다이어그램에서 볼 수 있듯이 Step Functions 워크플로우의 Lambda Functions 은 다음과 같습니다(이 단계에서는 Lambda Functions 과 Amazon S3에 저장된 params.json 파일에서 사용되는 파라미터 간의 매핑을 강조해 표시합니다. ).
- Create-Dataset – Forecast 데이터세트를 만듭니다. 데이터셋트에 대한 정보는 Forecast가 모델 학습을 위해 데이터를 사용하는 방법을 이해하는 데 도움이됩니다.
- Create-DatasetGroup – 데이터세트 그룹을 만듭니다.
- Import-Data – 데이터를 데이터세트 그룹에 있는 데이터세트로 가져 옵니다.
- Create-Predictor – 파리미터 파일이 지정하는 예측 범위forecast horizon을 사용하여 예측변수Predictor를 만듭니다.
- Create-Forecast – 예측을 생성하고 파라미터 파일에 지정된 분위수quantiles를 포함하여 Amazon S3로 내보내기 작업을 시작합니다.
- Update-Resources – 필요한 Athena 리소스를 만들고 내보낸 예측을 입력 데이터세트와 동일한 형식으로 변환합니다.
- Notify Success – Amazon SNS에 메시지를 게시하여 작업이 완료되면 알림 이메일을 보냅니다.
- Strategy-Choice – 파라미터 파일의 내용에 따라 Forecast 리소스를 삭제할지 여부를 확인합니다.
- Delete-Forecast – 예측을 삭제하고 내보낸 데이터를 유지합니다.
- Delete-Predictor – 예측변수를 삭제합니다.
- Delete-ImportJob – Forecast 에서 Import-Data 항목의 작업을 삭제합니다 .
Amazon Forecast에서 데이터세트 그룹은 특정 예측 집합에 대한 모든 데이터세트를 포함하는 추상화된 그룹을 의미합니다. 데이터셋트 그룹 간에는 정보를 공유할 수가 없습니다. 스키마에 대해 다양하게 선택하려면 새 데이터세트 그룹을 만들고 해당 데이터세트 내에서 변경해야 합니다. 자세한 내용은 데이터 집합 및 데이터 집합 그룹을 참조하시기 바랍니다. 이 사용 사례의 경우, 워크플로는 대상 시계열 데이터 세트를 데이터세트 그룹으로 가져오게 됩니다.
이러한 단계를 완료한 후 워크플로에서 예측변수 학습을 위한 작업the predictor training job을 시작trigger합니다. 예측 변수Predictor는 시계열 데이터를 기반으로 예측을 만드는데 사용되는 예측 학습 모델을 의미합니다. 자세한 내용은 예측 변수를 참조하시기 바랍니다.
상태 시스템State Machine은 예측을 성공적으로 Amazon S3에 내보낸 후 지정된 주소로 알림 이메일을 보내게 됩니다. 예측을 내보낸 후 Update-Resources 단계에서는 내보낸 데이터를 다시 데이터 형식을 변환 후 Athena 와 QuickSight 에서 쉽게 사용할 수 있게 합니다.
이 MLOps 파이프라인을 재사용하여 각 단계의 Lambda Functions 의 알고리즘 수정 및 데이터세트를교체하여 다른 ML 모델을 구축, 학습 및 배포할 수 있습니다.
전제 조건
아키텍처를 배포하기 전에 다음 단계를 미리 진행하시기 바랍니다.
- Git 설치합니다.
- AWS SAM (Serverless Application Model) CLI 를 설치합니다. AWS SAM CLI 설치 페이지를 참고하시기 바랍니다. 다음 코드를 이용해 최신 버전이 설치되어 있는지 확인하시기 바랍니다.
$ sam --version
AWS 계정에 샘플 아키텍처 배포
배포를 간단하게 하기 이 게시물은 AWS CloudFormation을 사용하여 전체 아키텍처를 IaC (Infrastructure as Code, 코드 기반 인프라 관리 기술)로 제공하며 Forecast Visualization Automation Blogspost 의 GitHub 리포지토리에서 확인할 수 있습니다. AWS SAM을 사용해 이 솔루션을 배포합니다.
- Git 리포지토리를 복제합니다 . 다음 코드를 참조하십시오.
git clone https://github.com/aws-samples/amazon-forecast-samples.git - 새로 생성 된 amazon-forecast-samples/ml_ops/visualization_blog 디렉토리로 이동 하고 다음 코드를 입력하여 솔루션 배포를 시작합니다.
cd amazon-forecast-samples/ml_ops/visualization_blog sam build && sam deploy --guided이 단계에서 AWS SAM은 CloudFormation 템플릿 변경 구성을 빌드합니다. 몇 초 후 AWS SAM은 CloudFormation 스택을 배포하라는 메시지를 표시합니다.
- 스택 배포를 위한 파라미터를 제공합니다.이 게시물은 다음 파라미터를 사용합니다. 기본 파라미터를 유지할 수 있습니다.
Setting default arguments for 'sam deploy' ========================================= Stack Name [ForecastSteps]: <Enter Stack Name e.g. - forecast-blog-stack> AWS Region [us-east-1]: <Enter region e.g. us-east-1> Parameter Email [youremail@yourprovider.com]: <Enter valid e-mail id> Parameter ParameterFile [params.json]: <Leave Default> #Shows you resources changes to be deployed and require a 'Y' to initiate deploy Confirm changes before deploy [Y/n]: y #SAM needs permission to be able to create roles to connect to the resources in your template Allow SAM CLI IAM role creation [Y/n]: y Save arguments to samconfig.toml [Y/n]: nAWS SAM은 AWS CloudFormation 변경 세트를 생성하고 확인을 요청합니다.
- Y 를 입력하세요.변경된 구성에 대한 자세한 정보는 Updating Stacks Using Change Sets 를 참고하십시오 . 배포에 성공하면 다음 내용이 출력됩니다.
CloudFormation outputs from the deployed stack ------------------------------------------------------------ Outputs ------------------------------------------------------------- Key AthenaBucketName Description Athena bucket name to drop your files Value forecast-blog-stack-athenabucket-1v6qnz7n5f13w Key StepFunctionsName Description Step Functions Name Value arn:aws:states:us-east-1:789211807855:stateMachine:DeployStateMachine-5qfVJ1kycEOj Key ForecastBucketName Description Forecast bucket name to drop your files Value forecast-blog-stack-forecastbucket-v61qpov2cy8c ------------------------------------------------------------- Successfully created/updated stack - forecast-blog-stack in us-east-1 - AWS CloudFormation 콘솔의Outputs 탭 ForecastBucketName에서 테스트 단계에서 사용 하는 값을 기록합니다.


샘플 아키텍처 테스트
다음 단계에서는 샘플 아키텍처를 테스트 하는 방법을 간단하게 설명합니다. Step Functions 워크플로를 트리거하려면 새로 생성된 S3 버킷에 파라미터 파일과 시계열 학습 데이터세트, 두가지를 업로드해야 합니다.
- GitHub 리포지토리를 복사clone한 동일한 디렉토리에 다음 코드를 입력합니다. YOURBUCKETNAME 은, 이전에 복사한 AWS CloudFormation 의 Outputs 탭의 값으로 변경해 줍니다.
aws s3 cp ./testing-data/params.json s3://{YOURBUCKETNAME}앞의 명령은 Lambda Functions 이 Forecast API 호출을 구성하기 위해 사용이 필요한 파라미터 파일을 복사합니다.
- 다음 코드를 입력하여 시계열 데이터세트를 업로드합니다.
aws s3 sync ./testing-data/ s3://{YOURBUCKETNAME} - Step Functions 대시 보드에서 DeployStateMachine- <random string> 이라는 상태 시스템 항목을 찾습니다.
- 실행중인 워크플로를 탐색하려면 상태 시스템State Machine을 선택합니다.


이전 스크린 샷에서 성공적으로 실행 된 모든 단계 (Lambda Functions)는 녹색으로 있습니다. 파란색은 해당 단계가 아직 진행 중임을 나타냅니다. 색상이 없는 모든 상자는 실행 보류중인 단계입니다. 이 워크플로의 모든 단계를 완료하는 데 최대 2시간이 걸릴 수 있습니다.
워크플로를 성공적으로 완료 한 후 Amazon S3 콘솔로 이동하여 다음 디렉토리가 있는 Amazon S3 버킷을 찾을 수 있습니다.
/params.json # Your parameters file.
/train/ # Where the training CSV files are stored
/history/ # Where the previous forecasts are stored
/history/raw/ # Contains the raw Amazon Forecast exported files
/history/clean/ # Contains the previous processed Amazon Forecast exported files
/quicksight/ # Contains the most updated forecasts according to the train dataset
/tmp/ # Where the Amazon Forecast files are temporarily stored before processing파라미터 파일인 params.json 에는 Lambda Functions에서 Forecast API를 호출하는 속성들을 저장합니다. 이러한 파라미터 구성에는 예측 도메인, 빈도 및 차원 외에도 예측 유형 , 예측변수 설정 및 데이터세트 설정 과 같은 정보가 포함됩니다. API 작업에 대한 자세한 내용은 Amazon Forecast Service 를 참조하십시오 .
이제 데이터가 Amazon S3에 있으므로 결과를 시각화 할 수 있습니다.
Amazon Athena와 QuickSight로 예측된 데이터 분석하기
예측 파이프라인을 완료한 후, 데이터에 대한 쿼리와 시각화가 필요하게 됩니다. Athena 는 표준 SQL을 사용하여 Amazon S3의 데이터를 쉽게 분석할 수 있는 대화형 쿼리 서비스입니다. QuickSight 는 빠른 클라우드 기반의 BI 서비스입니다. 데이터 분석을 시작하려면 먼저 데이터 소스로 Athena를 사용하여 QuickSight 에 데이터를 수집합니다.
AWS를 처음 사용하는 경우 QuickSight 설정으로 QuickSight의 계정을 생성합니다. AWS 계정이 있는 경우 QuickSight에 가입하여 계정을 생성합니다.
QuickSight 에서 Athena 를 처음 사용한다면, Amazon S3 데이터를 쿼리하기 위해서 QuickSight 에 권한을 부여해야 합니다. 자세한 내용은 Amazon QuickSight에서 Athena 사용 시 권한 부족을 참조하시기 바랍니다.
- QuickSight 콘솔에서 New Analysis를 선택합니다.
- New Data Set을 선택합니다.
- Athena를 선택합니다.
- New Athena data source 창에서 Data source name에 Utility Prediction 와 같이 입력합니다.
- Validate connection 을 선택합니다.
- Create data source 를 선택합니다.

Choose your table 창이 나타납니다. - Use custom SQL 버튼을 선택합니다.
- Enter custom SQL query 창에서 다음과 같이 쿼리 이름을 입력합니다. 예)
Query to merge Forecast result with training data - 쿼리 입력 창에 다음 코드를 입력합니다.
SELECT LOWER(forecast.item_id) as item_id, forecast.target_value, date_parse(forecast.timestamp, '%Y-%m-%d %H:%i:%s') as timestamp, forecast.type FROM default.forecast UNION ALL SELECT LOWER(train.item_id) as item_id, train.target_value, date_parse(train.timestamp, '%Y-%m-%d %H:%i:%s') as timestamp, 'history' as type FROM default.train - Confirm query 를 선택합니다.

이제 데이터를 SPICE 로 가져오거나 S3 데이터를 직접 쿼리할 수 있습니다.


- Visualize 옵션 중 하나를 선택합니다. Field List에는 다음 필드가 표시됩니다.
item_id
target_value
timestamp
type
내보낸 예측에는 다음 필드가 포함됩니다.
item_id
date
The requested quantiles (P10, P50, P90)
Field List 의type필드에는 예측된 창에 대한 분위수 유형 (P10, P50, P90)과history학습 데이터의 값이 포함됩니다. 이 작업은 과거의 데이터와 출력된 예측 값 사이에 일관된 과거 행을 가지기 위해 사용자 지정 쿼리를 통해 수행되었습니다.CreateForcast API의 옵션 파라미터인 ForecastType을 사용하여 분위수를 선택할 수 있습니다. 이 게시물의 경우 Amazon S3의 params.json 파일을 통해 구성할 수 있습니다.
- X축은
timestamp를 선택합니다. - Value 에는
target_value를 선택합니다. - Color 는
type을 선택합니다. 파라미터 상에서 72-hour horizon 을 지정합니다. 결과를 시각화 하려면 시간 별 빈도로 timestamp 필드를 집계해야 합니다. - timestamp 드롭다운 메뉴에서 Aggregate 와 Hour 를 선택합니다.


다음 스크린샷은 최종 Forecast 예측입니다. 그래프는 확률론적 예측이 생성되는 분위수 p10, p50m 및 p90의 앞으로의 예측 값을 보여줍니다.


마무리
모든 조직은 보다 정확한 예측을 통해 제품 수요를 더 잘 예측하고 계획 및 공급망을 최적화하는 등의 장점을 가질 수 있습니다. 수요 예측은 어려운 작업이며, ML은 예측과 현실 사이의 격차를 좁힐 수 있습니다.
이 게시물에서는 반복 가능한 AI 기반 자동 예측 생성 프로세스를 만드는 방법을 설명했습니다. 또한 서버리스 기술을 사용하여 ML 운영 파이프라인을 구현하는 방법을 배웠으며, 관리형 분석 서비스를 사용하여 데이터를 쿼리하고 시각화를 생성하여 데이터에 대한 통찰력을 얻었습니다.
Forecast로 할 수 있는 작업은 굉장히 많습니다. 에너지 소비 예측에 대한 자세한 내용은 Making accurate energy consumption predictions with Amazon Forecast 를 참조하시기 바랍니다. 분위수quantiles에 대한 더 자세한 내용은 Amazon Forecast now supports the generation of forecasts at a quantile of your choice 를 참조하세요.
만약 이 게시물이 문제를 해결하는데 도움이 된다면, 여러분의 생각과 질문을 댓글로 공유해 주시기 바랍니다. GitHub 저장소 에서 코드를 활용하고 더욱 확장할 수 있습니다.
– Luis Lopez Soria, AI/ML specialist solutions architect
– Saurabh Shrivastava, Solutions Architect Leader
– Pedro Sola Pimentel, R&D solutions architect
이 글은 AWS Machine Learning 블로그의 Building AI-powered forecasting automation with Amazon Forecast by applying MLOps의 한국어 번역으로 AWS한국사용자모임의 김정민님이 번역해 주셨습니다.