


Amazon Forecast – 시계열 데이터 예측을 위한 AI 서비스 정식 출시

AWS는 기계 학습에 대한 경험 없이도 고도로 정확한 예측을 제공할 수 있는 완전관리형 서비스인 Amazon Forecast를 출시 예고한 바 있습니다. 그동안 많은 고객들의 베타 테스트를 거쳐 오늘 정식 출시합니다.

Amazon Forecast를 별도 서버를 구성하거나 관리할 필요 없이, 데이터를 제공하고, 예측에 영향을 미칠 수 있다고 생각되는 메타데이터만 추가하면 됩니다. 예를 들어, 구입 또는 생산해야 하는 특정 제품에 대한 수요를 예측할 때는 날씨, 계절 및 제품 사용 위치 등에 대한 데이터를 입력합니다.
입력한 데이터는 Amazon 내부에서 사용하는 것과 동일한 기술을 기반으로 설계한 확장 가능한 고가용성 고정밀도 예측 기술을 구축 및 사용해 온 다년간의 경험을 사용하여 예측 결과를 제공합니다. 또한 딥 러닝을 사용하여 다수의 데이터 세트로부터 학습하고 자동으로 서로 다른 알고리즘을 시도하므로 제품 수요 예측, 클라우드 컴퓨팅 사용량 예측, 재무 계획 작성, 공급망 관리 시스템의 리소스 계획 작성 등 다양한 사용 사례에 활용할 수 있습니다.
Amazon Forecast 사용해보기
Amazon Forecast를 통해 흥미로운 예제를 보여드리기 위해 UCI Machine Learning Repository에 있는 개별 가정 전력 소모 데이터 세트를 선택했습니다. 전력 사용 데이터가 시간별로 집계된 버전의 CSV 형식 파일을 사용하겠습니다. 다음에 표시된 처음 몇 줄을 보면 타임스탬프, 에너지 소비량 및 고객 ID가 있는 것을 알 수 있습니다.
2014-01-01 01:00:00,38.34991708126038,client_12 2014-01-01 02:00:00,33.5820895522388,client_12 2014-01-01 03:00:00,34.41127694859037,client_12 2014-01-01 04:00:00,39.800995024875625,client_12 2014-01-01 05:00:00,41.044776119402975,client_12
Amazon Forecast 콘솔을 사용하여 얼마나 쉽게 예측기를 구축하여 예측을 생성할 수 있는지 알아보겠습니다. (고급 사용자는 Jupyter 노트북과 AWS SDK for Python을 사용할 수도 있습니다. GitHub 리포지토리에 있는 일부 샘플 노트북을 참조하십시오.)
Amazon Forecast 콘솔에서 수행할 첫 단계는 데이터 세트 그룹을 생성하는 것입니다. 데이터 세트 그룹은 서로 관련성이 있는 데이터 세트를 하나로 담은 컨테이너 역할을 합니다.
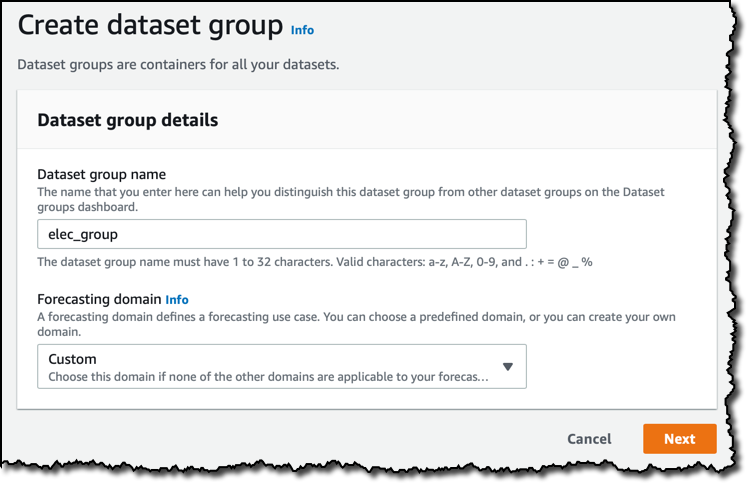
여기서 해당 데이터 세트 그룹을 위한 예측 도메인을 선택할 수 있습니다. 각 도메인은 소매, 재고 계획 또는 웹 트래픽과 같은 특정 사용 사례를 지원하며 훈련에 사용될 데이터 유형을 기반으로 자체 데이터 세트 유형을 제공합니다. 지금은 다른 범주에 속하지 않는 모든 사용 사례를 지원하는 [custom] 도메인을 사용하겠습니다.
다음에는, 데이터 세트를 생성합니다. 업로드할 데이터는 시간별로 집계되어 있으므로 데이터 주기는 [1 hour]입니다. 기본 데이터 스키마는 앞에서 선택한 예측 도메인에 따라 달라집니다. 사용자 지정 도메인을 사용 중이므로, 데이터 스키마가 이 게시물 시작 부분의 샘플 데이터 줄에 등장하는 순서대로 timestamp, target_value 및 item_id를 가지도록 변경합니다.
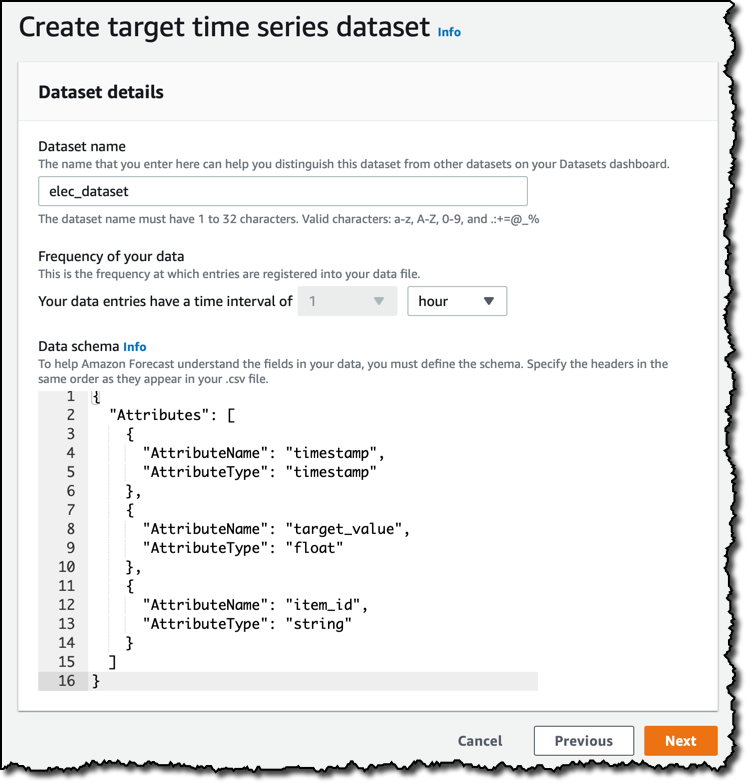
이제 Amazon Simple Storage Service(S3)에서 해당 데이터 세트로 시계열 데이터를 업로드해야 합니다. 기본 타임스탬프 형식은 데이터에 있는 것과 똑같으므로 아무 것도 변경하지 않아도 됩니다. Amazon Forecast에 S3 버킷에 대한 액세스 권한을 부여하려면 AWS Identity and Access Management(IAM) 역할이 필요합니다.
여기에서 권한을 선택하거나 이 사용 사례를 위한 새 권한을 생성할 수 있습니다. 항상 그렇듯이 지나치게 많은 권한을 허용하는 IAM 역할을 생성하지 않도록 주의하고 대신 최소 권한 접근 방식을 사용하여 권한 수준이 이 작업에 필요한 최소한의 권한이 되도록 줄입니다.
Amazon Forecast이 어느 S3 버킷 및 폴더에서 해당 기록 데이터를 찾아야 할지 지정했으면 가져오기 작업을 시작합니다.
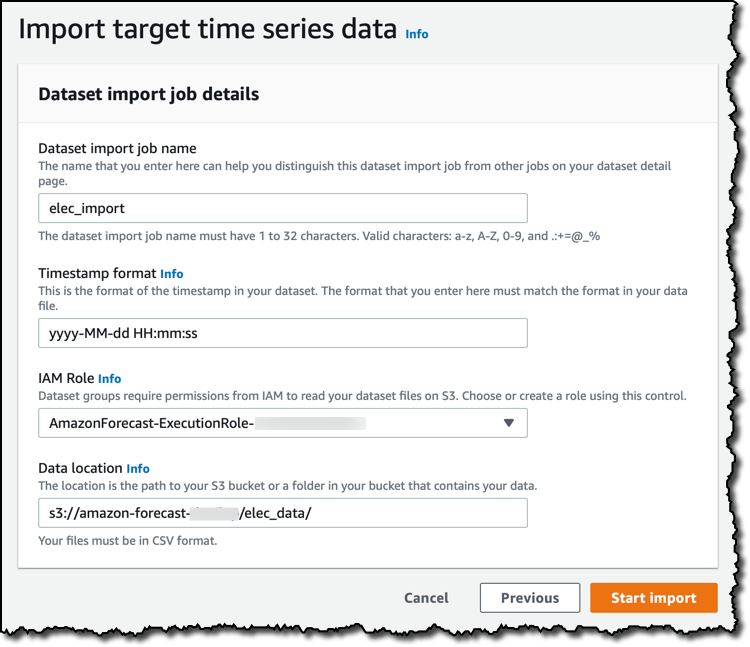
데이터 세트 그룹 대시보드는 프로세스에 대한 개요를 제공합니다. 대상 시계열 데이터를 가져오는 동안 다음과 같은 사항을 선택적으로 추가할 수 있습니다.
- 항목 메타데이터 – 예측하고자 하는 항목에 대한 정보입니다. 예들 들어, 소매 시나리오에서 품목의 색상 또는 이 전기 관련 사용 사례의 경우 주택 유형(아파트 또는 단독 주택) 등이 이에 포함됩니다.
- 관련 시계열 – 예측하고자 하는 대상 변수는 포함하지 않지만 모델 개선에 도움이 되는 데이터입니다. 예를 들어, 전자상거래 회사가 사용하는 가격 및 프로모션은 실제 판매량과 관련이 있을 수 있습니다.

이 사용 사례에서는 다른 데이터를 추가하지 않겠습니다. 데이터 세트를 가져왔으면 나중에 예측을 생성하는 데 사용될 예측기의 훈련을 시작합니다. 예측기에 이름을 부여한 다음 예측 구간(여기에서는 24시간)과 예측 생성 주기를 선택합니다.
예측기를 훈련할 때 ARIMA 또는 DeepAR+ 같이 자신이 원하는 특정 기계 학습 알고리즘을 선택할 수 있지만, 간단하게 AutoML을 사용하여 Amazon Forecast가 스스로 모든 알고리즘을 평가하여 해당 데이터 세트에 가장 뛰어난 성능을 발휘하는 알고리즘을 선택하도록 하겠습니다.
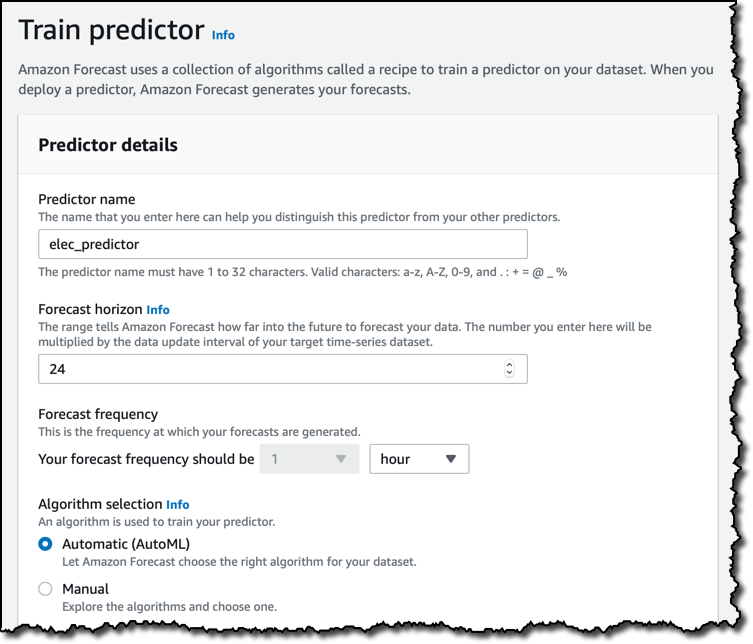
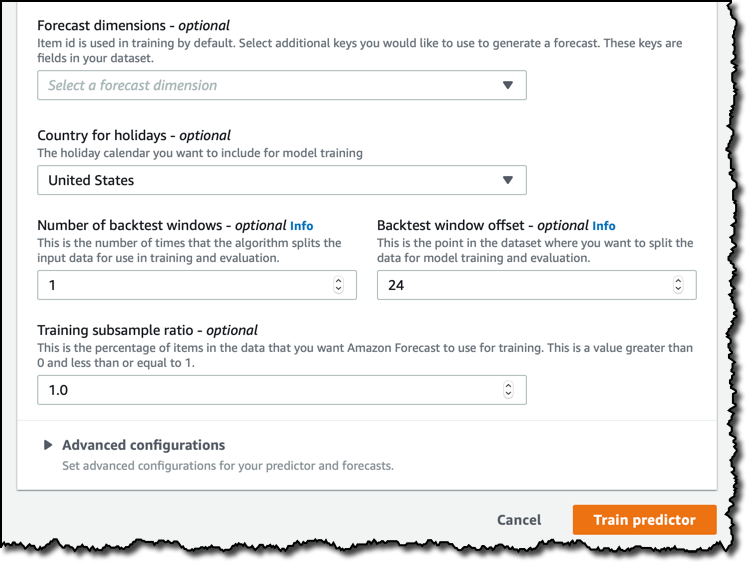
이 데이터 세트에서는 각 가정이 단일 변수(item_id)에 의해 식별되지만 필요한 경우 더 많은 차원을 추가할 수 있습니다. 이렇게 하면 [Country for holidays]를 선택할 수 있게 됩니다. 이는 선택 사항이지만 사람들이 휴가 중인지 여부에 따라 데이터가 영향을 받는 경우 결과가 개선될 수 있습니다. 휴가철에는 에너지 사용량이 달라지므로 이 데이터 세트가 생성된 국가인 [United States]를 선택하겠습니다.
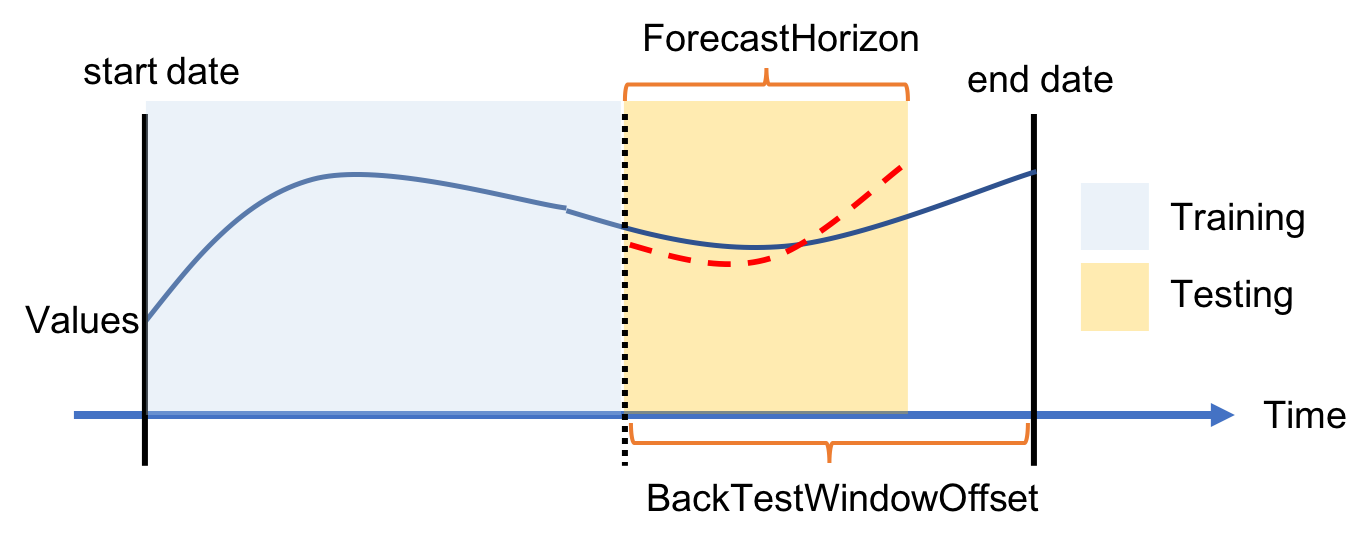
백테스트 윈도우 구성은 여기서 다루지 않을 고급 주제입니다. 기계 학습 모델이 시계열의 경우 어떻게 평가되는지에 대한 자세한 내용에 관심이 없는 경우 다음 항목으로 건너뛸 수 있습니다. 여기에서는 기본값을 그대로 유지하겠습니다.
기계 학습 모델을 훈련할 때에는 데이터 세트를 2개로 분할해야 합니다. 하나는 기계 학습 알고리즘으로 훈련하는 데 사용할 훈련 데이터 세트이고 다른 하나는 훈련된 모델의 성능을 평가하는 데 사용할 평가 데이터 세트입니다. 시계열의 경우 데이터 요소의 순서가 중요하므로 평소처럼 무작위로 두 개의 데이터 하위 세트를 생성할 수 없습니다.
Amazon Forecast에서 사용되는 접근 방식은 시계열을 백테스트 윈도우라고 불리는 하나 이상의 부분으로 분할하여 데이터의 순서를 보존하는 것입니다. 백테스트 윈도우를 기준으로 모델을 평가할 때에는 항상 같은 길이의 평가 데이터 세트를 사용해야 합니다. 그러지 않는 경우 서로 다른 결과를 비교하는 것이 매우 어려워집니다.
[backtest window offset]은 분할 지점 앞에 얼마나 많은 요소를 평가용으로 사용할 것인지 지정하며 이 값은 모든 분할에 대해 동일합니다. 예를 들어, 24(시간)를 그대로 두면 여러 윈도우 오프셋을 기준으로 모델을 평가할 때 항상 1일치의 데이터를 사용하게 됩니다.
고급 구성에서는 지원되는 알고리즘에 대해 hyperparameter optimization(HPO) 및 featurizations를 활성화하여 데이터의 관련 정보로부터 추가적인 기능을 개발할 수 있습니다. 지금은 이러한 설정을 건드리지 않겠습니다.
몇 분이 지나면 예측기가 활성화됩니다. 예측기의 품질을 이해하려면 자동으로 계산된 일부 지표를 살펴볼 수 있습니다.

분위 손실(QL)은 특정 분위의 예측이 실제 수요와 얼마나 차이가 나는지를 계산합니다. 이 지표는 특정 분위에 따라 과소 및 과도 예측의 가중치를 계산합니다. 예를 들어, 보정을 거친 P90 예측은 90%의 경우 예측 값이 실제 수요보다 적음을 의미합니다. 따라서 수요가 예측보다 큰 경우 손실이 그 반대의 경우보다 더 클 것입니다.
예측기가 준비되고 지표가 만족스러우면 이를 사용하여 예측을 생성할 수 있습니다.

예측이 활성화되면 쿼리를 통해 예상값을 얻을 수 있습니다. 전체 예측을 CSV 파일 형태로 내보내거나 특정 조회를 위해 쿼리를 실행할 수 있습니다. 조회를 수행해 보겠습니다. 이 데이터 세트의 경우 한 가정이 특정 기간 동안 사용하는 에너지를 예측할 수 있습니다. 여기에서는 오래된 데이터 세트를 사용했기 때문에 날짜가 과거의 날짜입니다. 물론 여러분은 Amazon Forecast를 사용하여 미래를 예측하실 것입니다.

예측에 있는 각 타임스탬프에 대해 값의 범위가 제공됩니다. P10, P50 및 P90 예측은 각각 실제 수요를 충족시킬 가능성이 10%, 50% 및 90%입니다. 이 세 값을 사용하는 방식은 해당 사용 사례 그리고 수요의 과도 또는 과소 예측이 미치는 영향에 따라 달라집니다. P50 예측은 해당 수요에 대해 가장 가능성이 높은 예측값입니다. P10 및 P90 예측은 기대치에 대해 80%의 신뢰도 간격을 제공합니다.

정식 출시
Amazon Forecast는 콘솔, AWS CLI(명령줄 인터페이스) 및AWS SDK를 통해 사용할 수 있습니다. 예를 들어, AWS SDK for Python과 함께 Jupyter 노트북 내에서 Amazon Forecast를 사용하여 새 예측기를 생성하거나, 브라우저에서 AWS SDK for JavaScript를 사용하여 웹 또는 모바일 앱 내에서 예측을 생성하거나, AWS SDK for Java 또는 AWS SDK for .NET을 사용하여 기존 엔터프라이즈 애플리케이션에 예측 기능을 추가할 수 있습니다.
데이터 세트 그룹의 생성에서부터 예측 쿼리 및 추출에 이르는 Amazon Forecast API의 흐름도는 다음과 같습니다.

이 설명에 사용된 데이터 세트와 기타 예제는 다음 GitHub 리포지토리에서 찾을 수 있습니다.
Amazon Forecast는 현재 미국 동부(버지니아 북부), 미국 서부(오레곤), 미국 동부(오하이오), 유럽(아일랜드), 아시아 태평양(싱가포르) 및 아시아 태평양(도쿄)에서 사용할 수 있습니다.