


Amazon Kinesis Data Analytics를 위한 Java 언어 지원 출시 및 활용 예제

AWS 고객은 Amazon Kinesis를 사용하여 실시간 스트리밍 데이터를 수집하고 처리하고 분석하여, 비즈니스나 인프라 또는 고객으로부터 얻은 새로운 정보에 빠르게 대처할 수 있습니다. 예를 들어, Epic Games는 인기 있는 온라인 게임, Fornite에서 초당 150만 이상의 게임 이벤트를 소화합니다.
Amazon Kinesis Data Analytics를 사용하면 표준 SQL을 사용하여 실시간으로 데이터를 처리할 수 있습니다. SQL에서는 새로운 프레임워크나 언어를 배우지 않고도 많은 양의 스트리밍 데이터를 빠르게 조회하는 쉬운 방법을 제공하지만, 많은 고객이 범용 프로그래밍 언어를 통해 보다 정교한 데이터 처리 애플리케이션을 구축하길 원합니다.
Kinesis Data Analytics를위한 Java 언어 지원
오늘 Amazon Kinesis Data Analytics에서 Java 언어 지원을 시작합니다. Java 코드를 사용하여 지속적으로 데이터를 변환하여 해당 데이터 레이크로 로드하거나, 지표를 생성하여 실시간 게이밍 리더보드에 정보를 공급하거나, 기계 학습 모델을 연결된 디바이스에서 데이터 스트림에 적용하는 방식으로 스트리밍 데이터를 처리하는 강력한 실시간 애플리케이션을 만들 수 있습니다.
이 새로운 기능을 사용하기 위해 개발자는 애플리케이션이 모든 규모에서 데이터를 구성하고 변환하고 집계하고 분석할 수 있는 공통된 데이터 처리 함수에 대한 기본 연산자를 포함하는 오픈 소스 라이브러리를 사용하여 애플리케이션을 구축할 수 있습니다. 다음과 같은 라이브러리도 모두 오픈 소스이므로, 어디서나 실행할 수 있습니다.
- Apache Flink. 데이터 스트림 처리를 위한 오픈 소스 프레임워크 및 엔진입니다.
- AWS SDK for Java. 많은 AWS 서비스에 대한 Java API를 제공합니다.
개발자는 원하는 IDE(Integrated Development Environment)에서 이러한 Java 라이브러리를 사용할 수 있습니다. 이 라이브러리를 사용하여 다음 AWS 서비스를 한 줄의 코드로 매우 간단하게 통합할 수 있습니다.
- 스트리밍 데이터 원본: Amazon Kinesis Data Streams
- 스트리밍 대상: Amazon S3, Amazon DynamoDB, Amazon Kinesis Data Streams, Amazon Kinesis Data Firehose
Java 라이브러리는 사전 구축된 AWS 통합 외에도, Cassandra, ElasticSearch, RabbitMQ, Redis 등과 같은 도구에 대한 추가 커넥터와 함께 사용자 정의 통합 구축 기능을 포함합니다.
Kinesis Data Streams Java 애플리케이션 구축
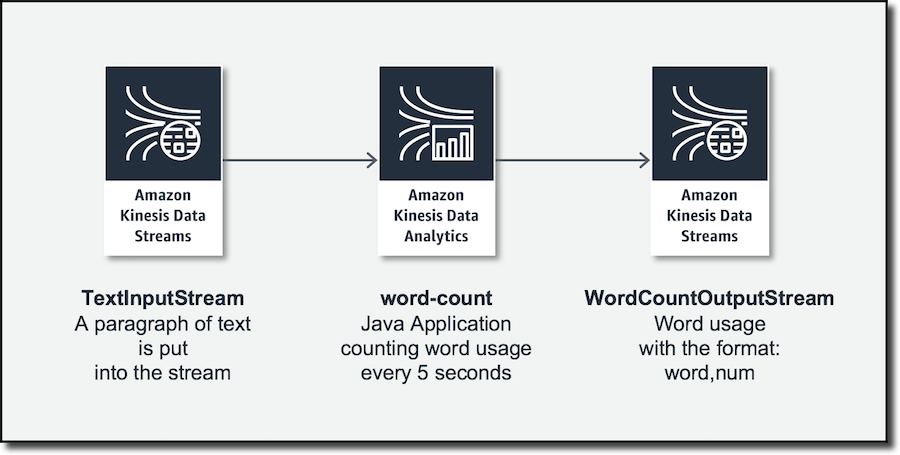
데이터 처리에 “필요한” 단어 계산 예제를 구현하는 간단한 Java 애플리케이션을 준비했습니다. 입력으로 몇 가지 텍스트 단락을 보내고 5초마다 각 단어를 출력으로 사용한 횟수를 받습니다.
먼저, 두 개의 Kinesis Data Streams를 생성합니다.
- TextInputStream. 내 입력 레코드를 보내려는 위치입니다.
- WordCountOutputStream. Java 애플리케이션 출력을 읽으려는 위치입니다.

다음은 word-count Java 애플리케이션의 코드입니다. Kinesis Data Streams에서 읽고 쓸 때 Apache Flink 프로젝트의 Kinesis Connector를 사용합니다.
public class StreamingJob {
private static final String region = "us-east-1";
private static final String inputStreamName = "TextInputStream";
private static final String outputStreamName = "WordCountOutputStream";
private static DataStream<String> createSourceFromStaticConfig(
StreamExecutionEnvironment env) {
Properties inputProperties = new Properties();
inputProperties.setProperty(ConsumerConfigConstants.AWS_REGION, region);
inputProperties.setProperty(ConsumerConfigConstants.STREAM_INITIAL_POSITION,
"LATEST");
return env.addSource(new FlinkKinesisConsumer<>(inputStreamName,
new SimpleStringSchema(), inputProperties));
}
private static FlinkKinesisProducer<String> createSinkFromStaticConfig() {
Properties outputProperties = new Properties();
outputProperties.setProperty(ConsumerConfigConstants.AWS_REGION, region);
FlinkKinesisProducer<String> sink = new FlinkKinesisProducer<>(new
SimpleStringSchema(), outputProperties);
sink.setDefaultStream(outputStreamName);
sink.setDefaultPartition("0");
return sink;
}
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> input = createSourceFromStaticConfig(env);
input.flatMap(new Tokenizer())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
.map(new MapFunction<Tuple2<String, Integer>, String>() {
@Override
public String map(Tuple2<String, Integer> value) throws Exception {
return value.f0 + "," + value.f1.toString();
}
})
.addSink(createSinkFromStaticConfig());
env.execute("Word Count");
}
public static final class Tokenizer
implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
String[] tokens = value.toLowerCase().split("W+");
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}
}애플리케이션에서 가장 중요한 부분은 입력 개체를 조작하는 위치로, 여기에서 몇 가지 DataStream 변환을 적용합니다.
- 입력 스트림에서 String을 포함하는 DataFrame부터 시작합니다.
- FlatMap에서 Tokenizer를 사용하여 문장을 “단어”로 분할합니다. 각 단어 뒤에는 숫자 “1”이 옵니다.
- KeyBy 연산자를 적용하여 “단어”를 기준으로 스트림을 논리적으로 파티션합니다.
- 5초를 변경 기간으로 사용합니다.
- 이 기간에 집계를 수행하여 각 단어에서 숫자 “1”이 나오는 횟수의 합계를 계산합니다.
- 각 레코드에서 간단한 맵을 사용하여 단어와 숫자를 쉼표로 구분된 값(CSV) 문자열로 결합한 후, 이를 출력 스트림으로 전송합니다.
여기에서 가장 강력한 연산자 중 하나는 바로, KeyBy 연산자입니다. 이를 통해 실시간으로 지정된 키를 사용하여 특정 스트림을 재구성할 수 있습니다. 이러한 유형의 키 재정렬 작업을 통해 집계, 계산 등의 추가 다운스트림 작업을 수행할 수 있습니다. 그리고 동일한 애플리케이션의 서로 다른 키에서 스트리밍 맵 축소를 설정할 수 있습니다.
Maven을 사용하여 Java 애플리케이션을 구축하고, 애플리케이션을 배포할 리전에서 Amazon Simple Storage Service(S3) 버킷에 출력 JAR을 로드합니다. Kinesis Data Analytics 콘솔에서 새로운 애플리케이션을 만들고 런타임으로 “Flink”를 선택합니다.
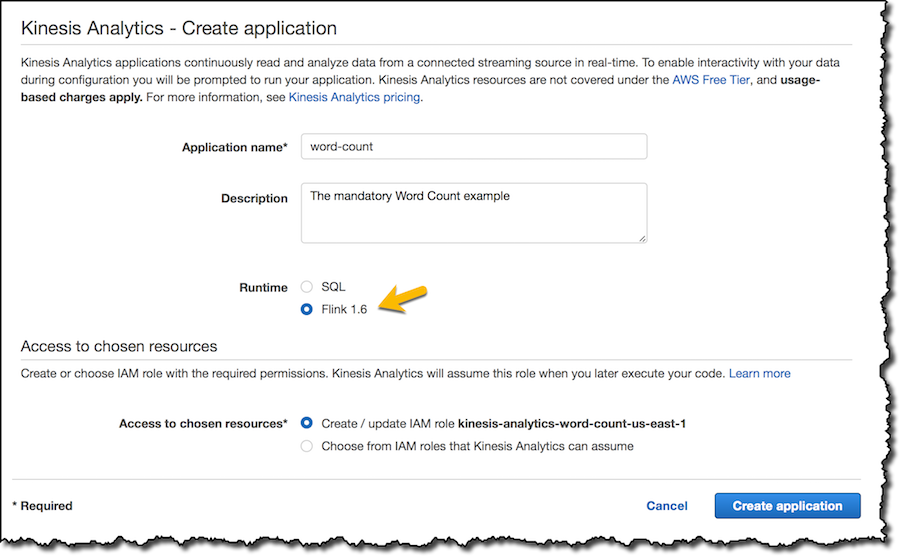
그리고 S3 버킷에서 코드를 사용하도록 애플리케이션을 구성합니다. 그러면 콘솔에서는 코드를 읽을 권한을 포함하도록 애플리케이션에 대한 IAM 역할을 업데이트합니다.

선택적으로 애플리케이션 구성에 키/값 속성을 추가할 수 있습니다. 애플리케이션에서 이러한 속성을 읽어 배포 시 사용자 정의 내용을 제공할 수 있습니다.
모니터링을 위해 기본 지표는 남겨 둡니다. Amazon CloudWatch에는 오류만 기록하도록 설정합니다.

콘솔에서 생성한 IAM 역할에 권한 추가를 잊지 마십시오. 그래야 Kinesis Analytics 애플리케이션에서 입력 및 출력에 사용한 스트림(이 경우 TextInputStream 및 WordCountOutputStream)으로부터 읽고 쓸 수 있습니다.
이제 “Run” 버튼을 눌러 애플리케이션을 시작할 수 있습니다. 실행 중에 입력 스트림에서 몇 가지 텍스트(Amazon Kinesis 플랫폼에 대한 설명)를 입력하도록 준비한 스크립트를 사용합니다.
$ python put_records.py TextInputStream Amazon Kinesis를 사용하면 실시간 스트리밍 데이터를 쉽게 수집하고 처리하고 분석합니다.
이 애플리케이션의 동작은 연산자와 즉각적 결과로 구성된 데이터 플로우를 시각적으로 표시하는 Application Graph 콘솔에서 요약합니다. (여러 스트림을 사용하는 복잡한 애플리케이션에 대한 그래프는 훨씬 흥미롭습니다.)

출력 스트림을 읽기 위해 Python으로 작성한 Lambda 함수를 사용합니다. Kinesis Record Aggregation & Deaggregation Modules for AWS Lambda에서 제공하는 함수를 사용합니다. 이 함수는 Amazon Kinesis Producer Library(KPL)에서 집계한 레코드의 자동 “집계 해제” 기능을 제공합니다.
예상한 대로, CloudWatch Logs 콘솔에서 단어와 단어가 사용된 횟수 목록을 확인할 수 있으며, 이 정보는 Lambda 함수로 5초마다 업데이트됩니다.

요금 및 가용성
Amazon Kinesis Data Analytics for Java를 사용하는 경우 사용한 기능에 대해서만 비용을 지불합니다. 요금은 Amazon Kinesis Data Analytics for SQL과 비슷하지만, 몇 가지 차이가 있습니다.
Java 애플리케이션의 경우 애플리케이션 오케스트레이션에 사용된 애플리케이션당 하나의 추가 Amazon Kinesis Processing Unit(KPU)에 대한 비용이 청구됩니다. 또한 Java 애플리케이션에서는 애플리케이션 스토리지와 지속 가능한 애플리케이션 백업 운영 비용도 청구됩니다. 애플리케이션 스토리지 운영은 Amazon Kinesis Data Analytics의 상태 기반 처리 기능에 사용되며, 매월 GB 기준으로 비용이 청구됩니다. 지속 가능한 애플리케이션 백업은 선택 사항이며, 애플리케이션의 지정 시간 복구 기능을 제공하고, 매월 GB 기준으로 비용이 청구됩니다.
예를 들어, 미국 동부(버지니아 북부)에서 요금은 KPU 시간당 0.11 USD이며, 애플리케이션 스토리지 운영 비용(매월 GB당 0.10 USD) 및 지속 가능한 애플리케이션 백업(매월 GB당 0.023 USD) 운영에 대한 비용이 청구됩니다.
현재 Amazon Kinesis Data Analytics for Java는 미국 동부(버지니아 북부), 미국 동부(오하이오), 미국 서부(오레곤), EU 서부(아일랜드)에서 사용할 수 있습니다.
Amazon Kinesis Data Analytics에서 Java 지원으로 활성화된 스트리밍 처리 기능에 대해 대략적으로만 살펴보았습니다. 하지만 이 기능은 새로운 사용 사례를 지원할 강력한 도구임을 확신합니다.
– Danilo Poccia;
Source: Amazon Kinesis Data Analytics를 위한 Java 언어 지원 출시 및 활용 예제