


Amazon Neptune Global Database 정식 출시 – 리전간 그래프 기반 앱 구축

Amazon Neptune Global Database를 정식 출시했습니다. Neptune 글로벌 데이터베이스를 사용하여 동일한 그래프 데이터베이스를 사용하는 여러 AWS 리전에서 그래프 기반 애플리케이션을 구축할 수 있습니다.
Amazon Neptune은 지식 그래프, 사기 그래프, ID 그래프 및 보안 그래프와 같이 고도로 연결된 데이터 세트로 애플리케이션을 구축 및 실행하기 위한 빠르고 안정적이며 완전 관리되는 그래프 데이터베이스 서비스입니다. Neptune은 개발자에게 세 가지 개방형 그래프 쿼리 언어인 openCypher, Apache TinkerPop, Gremlin 및 W3C(World Wide Web Consortium) SPARQL 1.1를 지원합니다. Neptune 글로벌 데이터베이스는 여러 리전에 걸쳐 전 세계적으로 분산된 애플리케이션을 위해 설계되었습니다. Neptune 글로벌 데이터베이스는 데이터베이스 성능에 영향을 주지 않고 데이터를 복제하고, 각 리전에서 짧은 지연 시간으로 빠른 로컬 읽기를 가능하게 하고, 리전 전체 중단으로부터 재해 복구를 제공합니다.
AWS 고객은 여러 리전으로 확장할 때, 리전 전체에 장애가 발생할 경우, 애플리케이션에 대한 비즈니스 연속성을 유지하기 위해 여러 리전에 Neptune 클러스터를 배포하기를 원했습니다. 여러 리전에서 동일한 데이터 세트로 작업할 수 있습니다. 이제 한 리전에 기본 Neptune 데이터베이스 클러스터를 배포하고 다른 리전에 있는 최대 5개의 보조 읽기 전용 데이터베이스 클러스터(각각 최대 16개의 읽기 전용 복제본 포함)에 데이터를 복제할 수 있습니다. 이를 통해 애플리케이션을 보조 클러스터 중 하나로 이동하고 애플리케이션 다운타임을 최소화할 수 있습니다.
Neptune 클러스터는 지역에서 예기치 않은 중단이 발생할 경우 몇 분 안에 복구할 수 있습니다. 이는 애플리케이션에 1초의 효과적인 RPO(복구 시점 목표)와 1분의 RTO(복구 시간 목표)를 제공하여 글로벌 비즈니스 연속성 계획을 위한 강력한 기반을 제공합니다. 여러 리전의 데이터에 액세스해야 하는 글로벌 애플리케이션의 경우 이제 글로벌 데이터베이스를 사용하여 가장 가까운 리전에서 그래프를 쿼리하여 쿼리 지연 시간을 줄일 수 있습니다. Neptune 콘솔에서 클릭 몇 번으로 글로벌 데이터베이스를 생성하거나 최신 AWS SDK 또는 CLI 있습니다. 이글에서는 Neptune 콘솔을 사용하여 글로벌 데이터베이스를 생성하는 방법을 안내합니다.
Amazon Netpune 글로벌 데이터베이스 사용해 보기
Neptune 글로벌 데이터베이스를 생성하려면 기본으로 사용할 Neptune 클러스터가 필요합니다. 기존 클러스터를 사용하거나 새 클러스터를 생성을 해보시기 바랍니다.
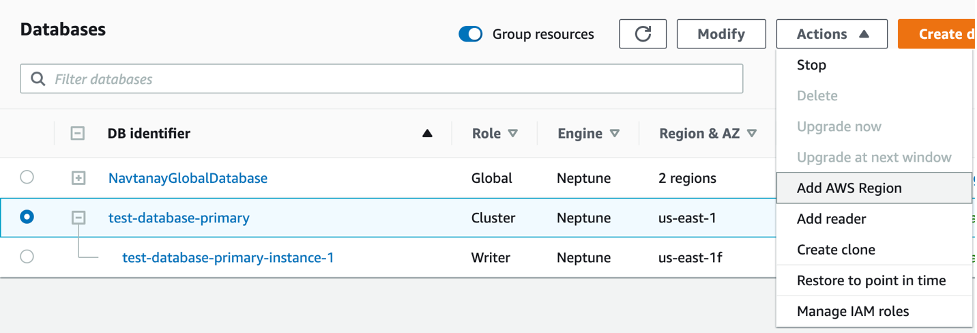
이제 Neptune 글로벌 데이터베이스를 생성하려면, 다음 단계를 완료하십시오.
- Neptune 콘솔에서 클러스터를 선택합니다.
- 지역 클러스터를 선택합니다.
- AWS 작업 메뉴에서 리전 추가를 선택합니다.

- 보조 리전의 경우 글로벌 데이터베이스 이름을 제공하고 보조 클러스터를 포함할 리전을 지정하고 보조 클러스터의 인스턴스 유형을 선택합니다. 성능 불일치를 방지하려면 기본 클러스터의 리더와 동일한 인스턴스 유형을 선택하는 것이 좋습니다.
- 다른 모든 옵션을 기본값으로 수락하여 클러스터를 생성할 수 있습니다.


이제 Neptune 클러스터가 전역 데이터베이스로 업그레이드되고 기본 클러스터의 데이터가 보조 클러스터로 자동 복제됩니다.


Neptune 글로벌 데이터베이스의 장애 조치
Neptune 글로벌 데이터베이스는 두 가지 다른 장애 조치 방식을 제공합니다.
- 분리 및 승격(계획되지 않은 수동 복구) – 계획되지 않은 중단에서 복구하기 위해 전역 데이터베이스의 보조 DB 클러스터 중 하나에서 리전 간 분리 및 승격을 수행할 수 있습니다. 더 자세한 사항은 Neptune 글로벌 데이터베이스에서 장애 조치를 살펴보세요. 이 시나리오에서는 기본 데이터베이스에 액세스할 수 없으며 기본으로 승격할 보조 클러스터를 식별해야 합니다.
- 관리형 계획 장애 조치 – 글로벌 데이터베이스의 기본 DB 클러스터를 보조 리전 중 하나로 재배치하는 것과 같은 계획된 운영 절차를 위한 것입니다. 이 시나리오는 기본 클러스터를 사용할 수 있는 경우에만 적용됩니다(중단 없음).
Neptune 콘솔에서 관리형 장애 조치를 수행하는 방법을 살펴보겠습니다. 다음 단계를 완료하십시오.
- Neptune 콘솔에서 데이터베이스를 선택합니다.
- 장애 조치(failover)할 전역 데이터베이스를 선택합니다.
- 장애 작업 메뉴에서 조치 전역 데이터베이스를 선택합니다.

- 기본으로 승격할 보조 클러스터를 선택합니다.



워크플로는 모든 쓰기를 중지하고 기본 클러스터의 쓰기 인스턴스를 읽기 전용 복제본으로 내리는 것으로 시작됩니다. 그런 다음 대상 보조 클러스터에서 우선 순위가 가장 높은 읽기 전용 복제본을 쓰기 인스턴스로 승격하고 선택한 보조 데이터베이스를 기본으로 승격하기 위해 전체 클러스터를 수정합니다. 이 장애 조치 중에는 클러스터에 쓸 수 없습니다.


워크플로가 성공적으로 완료되면 보조 데이터베이스가 이제 기본 데이터베이스로 승격된 것을 볼 수 있습니다.


정식 출시<
Neptune 글로벌 데이터베이스의 경우 모든 리전에서 사용하는 Neptune 리소스(예: 인스턴스, 스토리지, 데이터 전송 요금)에 대해 표준 가격이 적용됩니다. 또한 기본 및 보조 Neptune 클러스터 간의 쓰기, 삽입 및 삭제를 캡처하는 복제된 쓰기 I/O에 대해 요금이 부과됩니다. 더 자세한 것은 Amazon Neptune 요금을 참고하세요.
Neptune 글로벌 데이터베이스는 미국 동부(버지니아 북부), 미국 동부(오하이오), 미국 서부(캘리포니아 북부), 미국 서부(오레곤), 유럽(아일랜드), 유럽(런던) 및 아시아 태평양(도쿄)에서 사용할 수 있습니다.
더 자세한 것은 자세한 내용은 Amazon Neptune에서 글로벌 데이터베이스 사용 기술 문서를 참고하세요.
– Navtanay Sinha, AWS 수석 제품 관리자
이 글은 AWS Database Blog의 Introducing Amazon Neptune Global Database의 한국어 번역본입니다.
Source: Amazon Neptune Global Database 정식 출시 – 리전간 그래프 기반 앱 구축