


Amazon Neptune Serverless 정식 출시 – 서버리스 기반 완전관리형 그래프 데이터베이스

Amazon Neptune은 완전관리형 그래프 데이터베이스 서비스로, 고도로 연결된 데이터 세트를 사용하는 애플리케이션을 쉽게 구축하고 실행할 수 있습니다. Neptune을 사용하면 널리 사용되는 개방형 그래프 쿼리 언어를 사용하여 작성하기 쉽고 연결된 데이터에서 잘 작동하는 강력한 쿼리를 실행할 수 있습니다. 추천 엔진, 사기 탐지, 지식 그래프, 신약 개발, 네트워크 보안과 같은 그래프 사용 사례에 Neptune을 사용할 수 있습니다.
Neptune은 항상 완전관리형이었으며 프로비저닝, 패치, 백업, 복구, 장애 감지, 복구와 같이 시간이 많이 걸리는 작업을 처리합니다. 그러나 최적의 비용 및 성능을 위해 데이터베이스 용량을 관리하려면 워크로드 특성 변화에 따라 용량을 모니터링하고 재구성해야 합니다. 또한 가변적이거나 예측할 수 없는 워크로드가 있는 애플리케이션이 많은데, 그럴 경우 데이터베이스 쿼리의 양과 복잡성이 크게 달라질 수 있습니다. 예를 들어 소셜 미디어용 지식 그래프 애플리케이션은 갑작스러운 인기 때문에 일시적으로 쿼리가 급증할 수 있습니다.
Amazon Neptune Serverless 소개
오늘부터 Amazon Neptune Serverless 출시로 이 작업을 더 쉽게 수행할 수 있게 되었습니다. Neptune Serverless는 쿼리 및 워크로드의 변화에 따라 자동으로 확장되므로 애플리케이션에 필요한 적절한 양의 데이터베이스 리소스를 제공할 수 있도록 용량을 세밀하게 조정합니다. 그리고 사용한 용량에 대해서만 비용을 지불하면 됩니다. 개발, 테스트 및 프로덕션 워크로드에 Neptune Serverless를 사용하고 피크 용량을 위한 프로비저닝과 비교하여 데이터베이스 비용을 최적화할 수 있습니다.
Neptune Serverless를 사용하면 최신 애플리케이션을 위한 그래프를 신속하고 비용 효율적으로 배포할 수 있습니다. 소규모 그래프에서 시작해 워크로드가 증가하면 Neptune Serverless가 자동으로 그래프 데이터베이스를 원활하게 확장하여 필요한 성능을 제공합니다. 더 이상 데이터베이스 용량을 관리할 필요가 없으며, 이제 오버프로비저닝으로 인한 비용 증가 또는 언더프로비저닝으로 인한 용량 부족 위험 없이 그래프 애플리케이션을 실행할 수 있습니다.
Neptune Serverless를 사용하면 이미 Neptune에서 사용 가능한 동일한 쿼리 언어(Apache TinkerPop Gremlin, openCypher, RDF/SPARQL) 및 기능(예: 스냅샷, 스트림, 고가용성 및 데이터베이스 복제)을 계속 사용할 수 있습니다.
실제로 어떻게 작동하는지 알아보겠습니다.
Amazon Neptune Serverless 데이터베이스 생성
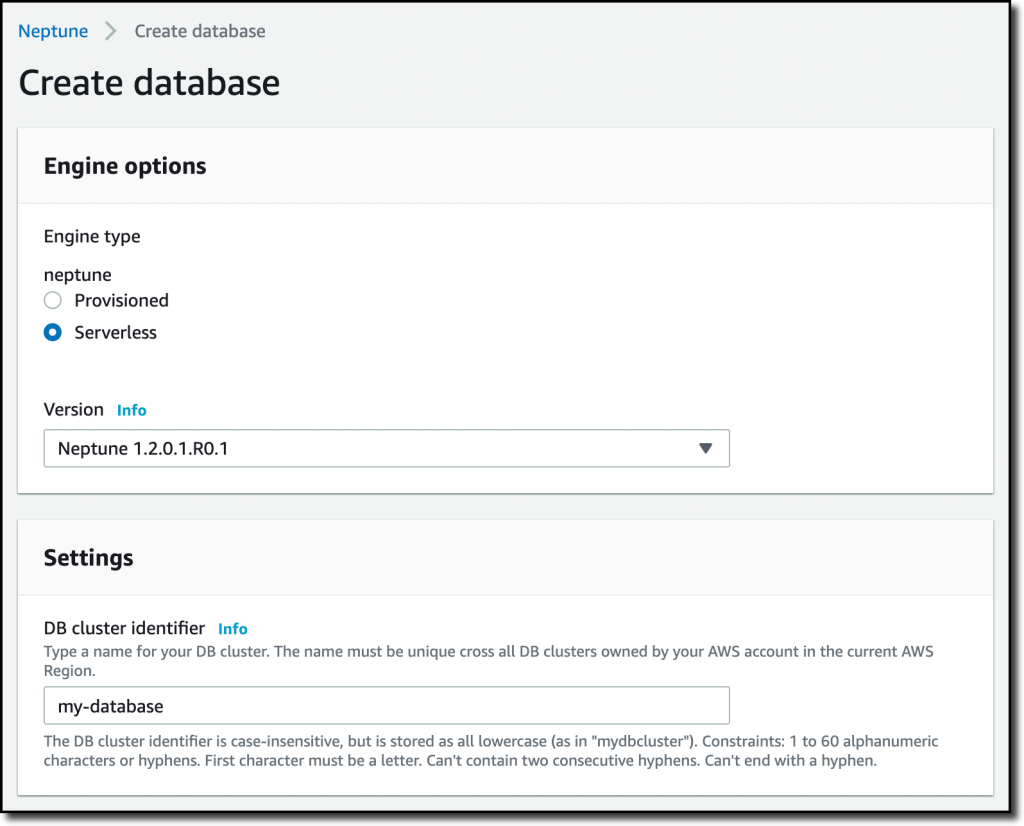
Neptune 콘솔의 탐색 창에서 Databases(데이터베이스), Create database(데이터베이스 생성)를 차례로 선택합니다. Engine type(엔진 유형)에서 Serverless(서버리스)를 선택하고 DB cluster identifier(DB 클러스터 식별자)로 my-database를 입력합니다.

이제 Neptune Serverless가 워크로드에 따라 사용할 수 있는 용량 범위를 Neptune 용량 단위(NCU)로 구성할 수 있습니다. 이제 다음 옵션 중 몇 가지를 구성할 템플릿을 선택할 수 있습니다. 기본적으로 다른 가용 영역에 읽기 전용 복제본을 생성하는 Production(프로덕션) 템플릿을 선택합니다. Development and Testing(개발 및 테스트) 템플릿은 읽기 전용 복제본을 생성하지 않고 버스트 가능한 용량을 제공하는 DB 인스턴스에 대한 액세스 권한을 부여하여 비용을 최적화할 수 있습니다.

Connectivity(연결)의 경우 default VPC(기본 VPC) 및 해당 기본 보안 그룹을 사용합니다.

마지막으로 Create database(데이터베이스 생성)를 선택합니다. 몇 분이면 데이터베이스를 사용할 수 있습니다. 데이터베이스 목록에서 DB identifier(DB 식별자)를 선택하여 나중에 데이터베이스에 액세스하는 데 사용할 Writer 및 Reader 엔드포인트를 가져옵니다.
Amazon Neptune Serverless 사용
Neptune Serverless를 사용하는 방법은 프로비저닝된 Neptune 데이터베이스와 비교했을 때 차이가 없습니다. Neptune에서 지원하는 모든 쿼리 언어를 사용할 수 있습니다. 이 연습에서는 원래 Neo4j에서 개발한 속성 그래프에 대한 선언형 쿼리 언어인 openCypher를 사용하겠습니다. 이 쿼리 언어는 2015년에 오픈 소스로 전환되어 openCypher 프로젝트에 기부되었습니다.
데이터베이스에 연결하기 위해 동일한 AWS 리전에서 Amazon Linux Amazon Elastic Compute Cloud(Amazon EC2) 인스턴스를 시작하고 기본 보안 그룹과 SSH 액세스 권한을 부여하는 두 번째 보안 그룹을 연결합니다.
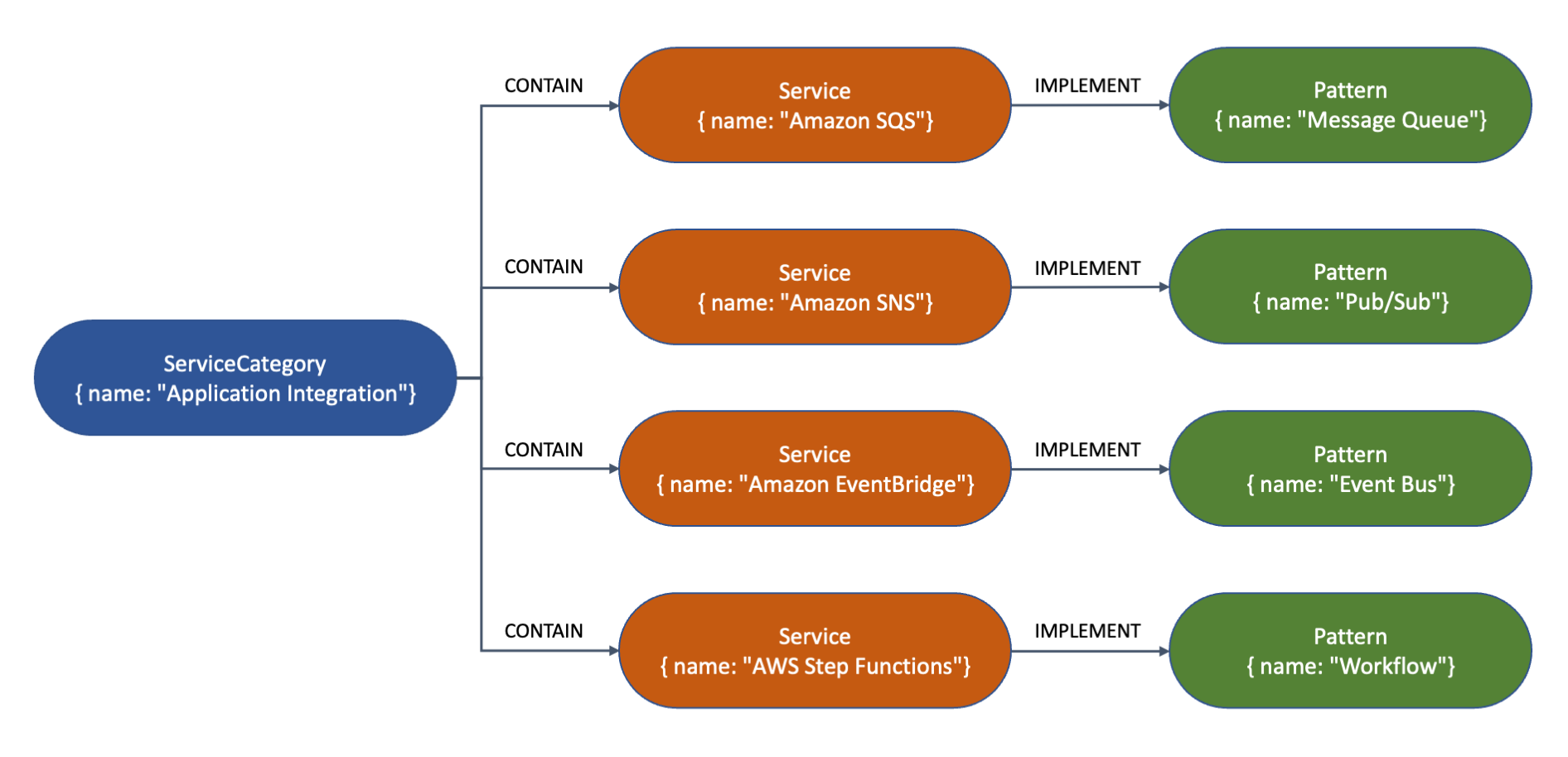
속성 그래프를 사용하면 연결된 데이터를 표현할 수 있습니다. 이 예제에서는 일부 AWS 서비스가 서비스 범주로 분류되는 방식을 보여주는 간단한 그래프를 만들고 일반적인 엔터프라이즈 통합 패턴을 구현하려고 합니다.
curl을 사용하여 Writer openCypher HTTPS 엔드포인트에 액세스하고 패턴, 서비스 및 서비스 범주를 나타내는 몇 개의 노드를 만듭니다. 다음 명령은 가독성을 위해 여러 줄로 나뉘어져 있습니다.
다음은 위의 명령으로 생성한 그래프의 노드 및 노드 관계를 시각적으로 표현한 것입니다. 유형(예: Service 또는Pattern) 및 속성(예: name)이 각 노드 안에 표시됩니다. 화살표는 노드 간의 관계(예: CONTAIN 또는IMPLEMENT)를 나타냅니다.
이제 데이터베이스를 쿼리하여 인사이트를 얻습니다. 데이터베이스를 쿼리하려면 Writer 또는 Reader 엔드포인트를 사용할 수 있습니다. 먼저 ‘메시지 큐’ 패턴을 구현하는 서비스의 이름을 알고 싶습니다. openCypher의 구문은 SELECT 대신 MATCH를 사용하는 SQL 구문과 비슷합니다.
{
"results" : [ {
"s.name" : "Amazon SQS"
} ]
}다음 쿼리를 사용하여 ‘Application Integration’ 범주에 속하는 서비스 수를 확인합니다. 이번에는 WHERE 절을 사용하여 결과를 필터링합니다.
{
"results" : [ {
"count(s)" : 4
} ]
}이제 이 그래프 데이터베이스를 가동할 수 있는 옵션이 많이 생겼습니다. 더 많은 데이터(서비스, 범주, 패턴)와 더 많은 노드 간 관계를 추가할 수 있습니다. Neptune Serverless가 용량 및 인프라를 관리하도록 두고 애플리케이션에만 집중할 수 있습니다.
가용성 및 요금
Amazon Neptune Serverless는 현재 미국 동부(오하이오, 버지니아 북부), 미국 서부(캘리포니아 북부, 오리건), 아시아 태평양(도쿄) 및 유럽(아일랜드, 런던) AWS 리전에서 제공됩니다.
Neptune 서버리스를 사용하면 사용한 만큼만 비용을 지불하면 됩니다. 데이터베이스 용량은 Neptune 용량 단위(NCU) 기준으로 필요한 적절한 양의 리소스를 제공하도록 조정됩니다. 각 NCU는 약 2GiB(기비바이트)의 메모리, 해당 CPU, 네트워킹의 조합입니다. NCU 사용량은 초당 요금이 청구됩니다. 자세한 내용은 Neptune 요금 페이지를 참조하세요.
서버리스 그래프 데이터베이스를 구축하면 많은 새로운 가능성이 열립니다. 자세히 알아보려면 Neptune Serverless 설명서를 참조하세요. 이 새로운 기능으로 무엇을 구축했는지 알려주세요!
Neptune Serverless를 사용하여 고도로 연결된 데이터로 작업하는 방식을 간소화
— Danilo
Source: Amazon Neptune Serverless 정식 출시 – 서버리스 기반 완전관리형 그래프 데이터베이스