


Amazon Redshift용 AWS Data Exchange 신규 기능 출시

2019년에는 AWS Data Exchange에 대해 설명하고 데이터 제품을 검색, 구독, 사용하는 방법을 보여드렸습니다. 현재 10가지 범주에서 3,600개 이상의 데이터 제품 중에서 선택할 수 있습니다.

소개 게시물에서, 데이터 제품을 구독한 다음 데이터 세트를 Amazon Simple Storage Service(Amazon S3) 버킷으로 다운로드하는 방법을 보여드렸습니다. 그리고 추가 처리를 위해 AWS Lambda 함수, AWS Glue 크롤러 또는 Amazon Athena 쿼리를 포함하는 다양한 옵션을 제안했습니다.
이제 Amazon Redshift용 AWS Data Exchange를 도입하여 서드 파티 데이터를 더욱 쉽게 검색, 구독, 사용할 수 있도록 지원합니다. 구독자는 추가 처리 없이 공급자의 데이터를 바로 사용할 수 있으며 추출, 변환, 로드(ETL) 프로세스가 필요하지 않습니다. 데이터를 처리할 필요가 없으므로 데이터는 항상 최신 상태로 유지되며 Amazon Redshift 쿼리에서 바로 사용할 수 있습니다. Amazon Redshift용 AWS Data Exchange는 고객의 모든 권한 및 결제를 관리하며, 모든 요금은 AWS 계정으로 청구됩니다.
공급자로서 이제 데이터에 라이선스를 부여하고 고객에게 제공할 수 있는 새로운 방법이 생겼습니다.
이 글을 작성하면서 Redshift의 기존 특성이 얼마나 많은지와, Data Exchange가 중심적 역할을 어떻게 해내는지를 생각할 수 있어 즐거웠습니다. Redshift는 내장된 데이터 공유 기능과 함께 스토리지와 컴퓨팅이 깔끔하게 분리되어 있기 때문에 데이터 공급자는 스토리지를 할당하여 스토리지 비용을 지불하며 데이터 구독자는 컴퓨팅에 대해서도 동일한 작업을 수행합니다. 공급자는 구독자 기반 규모에 비례하여 클러스터를 확장할 필요가 없으며 데이터 수집 및 제공에 집중할 수 있습니다.
데이터 제품 구독 및 데이터 제품 게시라는 두 가지 강점에서 이 기능을 살펴보겠습니다.
Amazon Redshift용 AWS Data Exchange – 데이터 제품 구독
데이터 구독자는 AWS Data Exchange 카탈로그를 통해 자신의 비즈니스와 관련된 데이터 제품을 찾아서 구독할 수 있습니다.
또한 데이터 공급자는 프라이빗 오퍼를 생성해서 AWS Data Exchange 콘솔을 통해 사용자에게 제시할 수 있습니다. 내 제품 오퍼(My product offers)를 클릭하고 사용자에게 제시된 오퍼를 검토합니다. 계속하려면 구독 진행(Continue to subscribe)을 클릭합니다.


그런 다음 오퍼 및 구독 약관을 검토하고 오퍼를 통해 얻게 될 데이터 세트를 확인한 다음 구독(Subscribe)을 클릭하여 구독을 완료합니다.

구독이 완료되면 알림을 받고 다음으로 진행합니다.
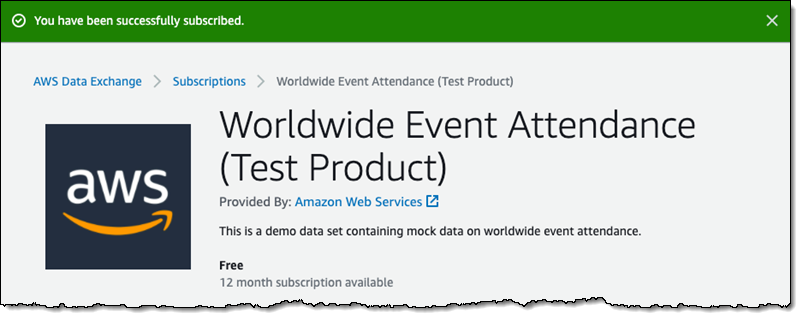

Redshift 콘솔에서 Datashares를 클릭하고 다른 계정에서(From other accounts)를 선택하면 구독한 데이터 세트를 볼 수 있습니다.


다음으로, 구독한 datashare를 가리키는 데이터베이스를 만들어 하나 이상의 Redshift 클러스터에 연결하고 테이블, 뷰 및 저장 프로시저를 사용하여 Redshift 쿼리 및 애플리케이션을 실행합니다.
Amazon Redshift용 AWS Data Exchange – 데이터 제품 게시
데이터 공급자로서 AWS Data Exchange 제품에 Redshift 테이블, 뷰, 스키마 및 사용자 정의 함수를 포함할 수 있습니다. 간단하게 진행하기 위해 Redshift 테이블이 하나만 포함된 제품을 생성하겠습니다.
새로운 Redshift 쿼리 편집기 V2를 사용하여 미국 지역 번호를 도시 및 주에 매핑하는 테이블을 생성합니다.

그런 다음 내 Redshift 클러스터에 대한 기존 datashare 목록을 검토하고 datashare 생성(Create datashare)을 클릭하여 새 datashare를 생성합니다.

다음으로, datashare를 생성하는 일반적인 프로세스를 진행합니다. AWS Data Exchange datashare를 선택하고, 이름(area_code_reference)을 할당하고, 클러스터 내에서 데이터베이스를 선택하고, 퍼블릭 액세스가 가능한 클러스터에서 datashare에 액세스할 수 있도록 설정합니다.
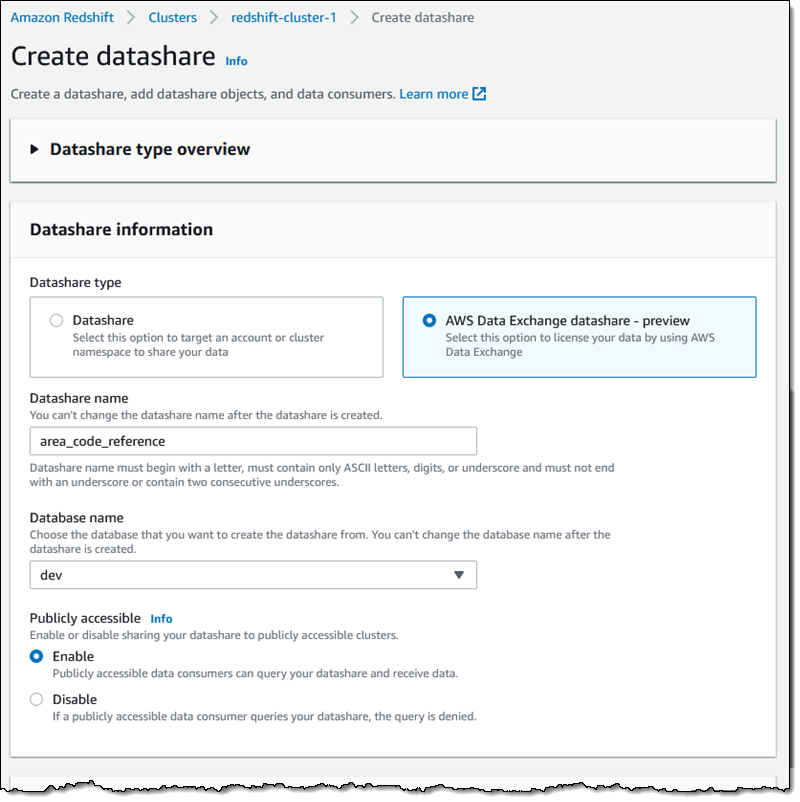

그런 다음 아래로 스크롤하고 추가(Add)를 클릭하여 다음으로 진행합니다.


내 스키마(public)를 선택하고 내 datashare에 테이블과 뷰만 포함하도록 선택한 다음 area_codes 테이블을 추가합니다.
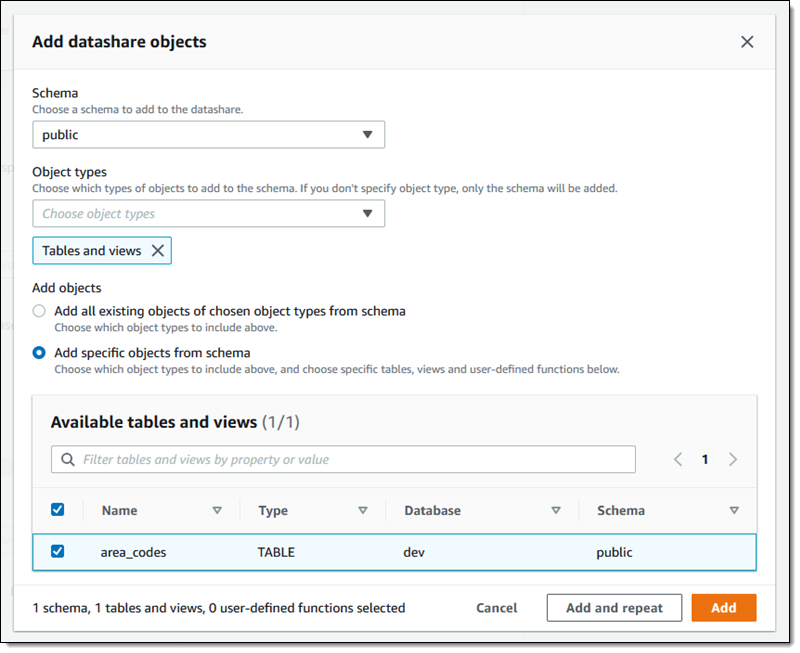

이 시점에서 추가(Add)를 클릭하여 마무리하거나 추가 및 반복(Add and repeat)을 클릭하여 추가 객체가 포함된 더 복잡한 제품을 만들 수 있습니다.
datashare에 테이블이 포함되어 있는지 확인하고 datashare 생성(Create datashare)을 클릭하여 다음으로 진행합니다.

이제 데이터 게시를 시작할 준비가 되었습니다! AWS Data Exchange 콘솔로 이동하여 왼쪽의 탐색을 확장하고 소유한 데이터 세트(Owned data sets)를 클릭합니다.


데이터 세트 만들기 단계(Data set creation steps)를 검토하고 데이터 세트 생성(Create data set)을 클릭하여 계속 진행합니다.
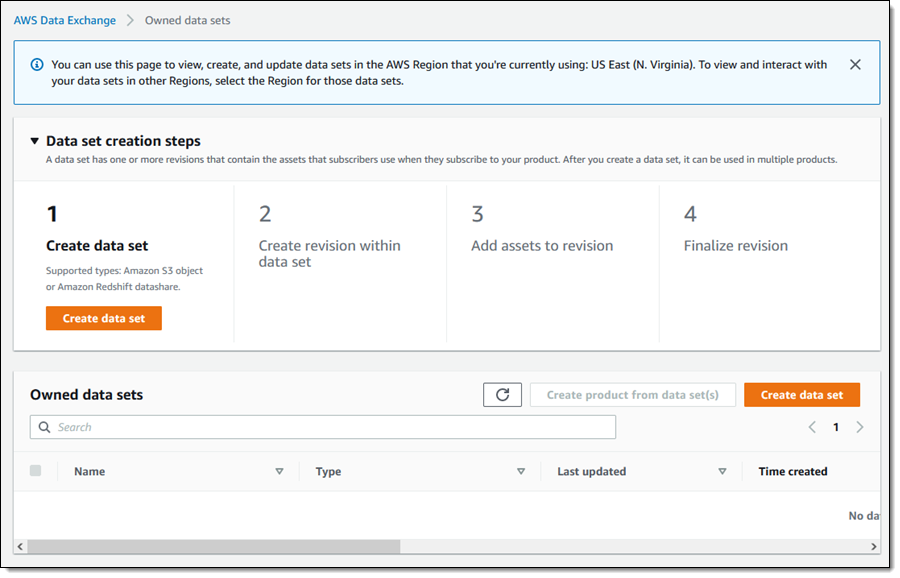

Amazon Redshift datashare를 선택하고 내 데이터 세트에 이름(United States Area Codes)을 지정하고 설명을 입력한 다음 데이터 세트 생성(Create data set)을 클릭하여 계속 진행합니다.
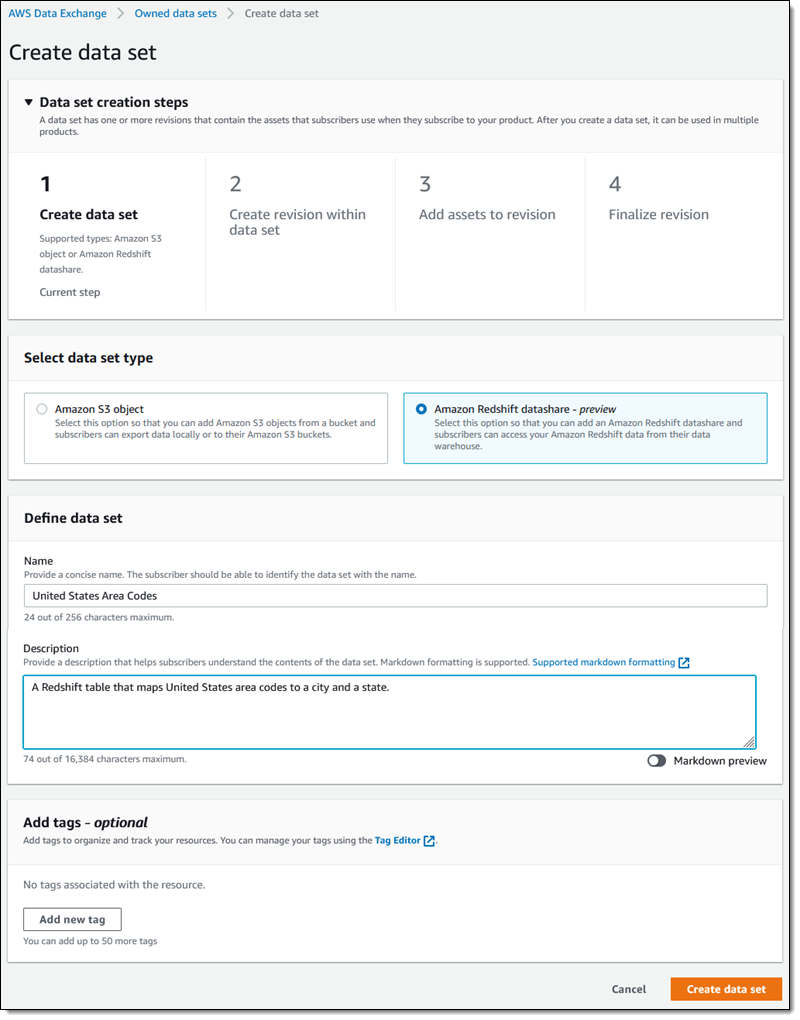

v1이라는 개정판을 만듭니다.


내 datashare를 선택하고 datashare 추가(Add datashare)를 클릭합니다.
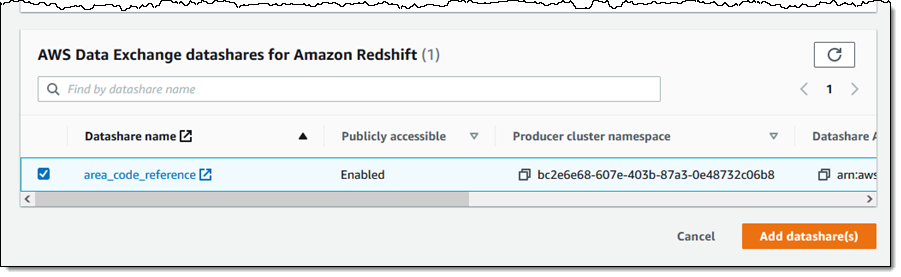

그런 다음 개정판을 마무리합니다.


datashare와 데이터 세트를 생성하고 콘솔을 사용하여 제품을 게시하는 방법을 보여드렸습니다. 여러 제품을 게시하거나 정기적으로 개정판을 만드는 경우 AWS Command Line Interface(CLI) 및 Amazon Data Exchange API를 사용하여 이러한 모든 단계를 자동화할 수 있습니다.
초기 데이터 제품
여러 데이터 공급자가 Amazon Redshift용 AWS Data Exchange를 통해 그들의 데이터 제품을 사용자에게 제공하는 업무를 하고 있습니다. 다음은 몇 가지 초기 오퍼링과 공식 설명입니다.
- FactSet 공급망 관계 – FactSet Revere 공급망 관계 데이터는 전 세계 기업 간의 비즈니스 관계 상호 연결 정보를 제공하기 위해 작성되었습니다. 이 피드는 연간 자료 제출, 투자자 프레젠테이션 및 보도 자료에서 수집한 기업의 주요 고객, 공급업체, 경쟁사 및 전략적 파트너의 복잡한 네트워크에 대한 액세스를 제공합니다.
- Foursquare Places 2021: 뉴욕시 샘플 – 이 시범 데이터 세트에는 Redshift Data Share로 액세스할 수 있는 뉴욕시에 대한 Foursquare’ss integrated Places(POI) 데이터베이스가 포함되어 있습니다. 추가 처리 및 분석을 위해 Foursquare’s Places 데이터를 Redshift 테이블에 즉시 로드합니다. Foursquare 데이터는 개인정보 보호를 준수하고, 고유하게 소싱되며, Uber, Samsung, Apple과 같은 최고의 기업들이 신뢰합니다.
- Mathematica Medicare 지표 데이터 세트 – Medicare HCC 카운트와 유병률을 주, 카운티, 지급인별로 집계하여 2017년부터 2019년까지의 당뇨병 인구로 필터링합니다.
- 캐나다의 COVID-19 예방 접종 – 이 목록에는 캐나다의 COVID-19 예방 접종 데이터에 대한 샘플 데이터 세트가 포함되어 있습니다.
- Revelio Labs 인력 구성 및 추세 데이터(시험 데이터) – 모든 회사의 인력 구성 및 추세를 파악합니다.
- Facteus – 미국 카드 소비자 지불 – CPG 백테스트 – 미국 전역의 9,000개 이상의 시내 편의점 및 잡화점에서 판매되는 수백 종의 소비재 상품에 대한 현금 및 카드 거래의 SKU 수준 거래 세부 정보 패널의 역사적 샘플입니다.
- Decadata Argo 공급망 시험 데이터 – 미국 식료품 소매 업체에 제품을 공급하는 CPG 기업을 위한 공급망 데이터입니다.
— Jeff;