


Amazon Redshift 를 위한 10가지 성능 튜닝 기법

최근 국내의 많은 고객 분들이 Amazon Redshift 도입을 고려하고 계시거나, 또는 이미 도입하여 사용하고 계십니다. 도입 전, PoC(Proof of Concept) 등의 과정을 통해서 기존 업무와의 호환성 또는 원하는 성능에 대한 평가 등을 하신 후에 사용하고 계시겠지만, 제목과 같이 Redshift 의 성능 튜닝에 도움이 될 수 있는 내용을 다시 한번 살펴보시라는 의미에서, 좋은 블로그 포스트를 번역하여 제공하고자 합니다.
원문은 Top 10 Performance Tuning Techniques for Amazon Redshfit(Ian Meyers is a Solutions Architecture Senior Manager with AWS, Zach Christopherson, an Amazon Redshift Database Engineer, contributed to this post)
—
Amazon Redshift는 완벽하게 관리되는 페타 바이트 규모의 대규모 병렬 데이터 웨어하우스로서 간단한 조작을 통한 높은 성능을 제공합니다. 확장에 어려움을 겪고있는 기존 데이터베이스 환경 가속화에서부터 빅데이터 분석을 위한 웹 로그 처리에 이르기까지 많은 고객들이 Amazon Redshift를 사용합니다. Amazon Redshift는 업계 표준 JDBC/ODBC 드라이버 인터페이스를 제공하므로 고객은 기존 비즈니스 인텔리전스 도구를 연결하고, 분석을 위해 사용하던 기존 쿼리를 재사용 할 수 있습니다.
Amazon Redshift는 프로덕션 트랜잭션 시스템 제 3 정규형 모델(3NF)에서 스타 및 스노플레이크 스키마 또는 간단한 플랫 테이블에 이르기까지 모든 유형의 데이터 모델을 실행할 수 있습니다. 고객이 Amazon Redshift를 채택하면 데이터 모델이 데이터베이스에 올바르게 배치되고 유지 관리되도록 아키텍처를 고려해야합니다. 이 게시물을 통해 고객은 Amazon Redshift를 채택 할 때 가장 많이 발견되는 문제를 해결할 수 있으며 각 문제를 해결하는 방법에 대한 구체적인 지침을 제공합니다. 여기에서 언급하는 각 항목을 처리하면 최적의 쿼리 성능을 달성하고 고객 요구 사항을 충족시키기 위해 효과적으로 확장 할 수 있을 것입니다.
이슈 #1 : 잘못된 컬럼 인코딩
Amazon Redshift는 열(Column) 기반 데이터베이스로, 행(Row)별로 디스크에 데이터를 구성하는 대신 데이터를 열 별로 저장하고, 런타임에 행들은 열 기반 스토리지에서 추출됩니다. 이 아키텍처는 대부분의 쿼리가 가능한 모든 차원과 측정의 특정 하위 집합 만을 액세스 하는, 많은 수의 열이 있는 테이블에 대한 분석 쿼리에 특히 적합합니다. Amazon Redshift는 SELECT 또는 WHERE 절에 포함 된 열의 디스크 블록에만 액세스 할 수 있으며, 쿼리를 평가하기 위해 모든 테이블 데이터를 읽을 필요가 없습니다. 열에 저장된 데이터도 인코딩 됩니다. (Amazon Redshift 데이터베이스 개발자 가이드에서 열 압축 유형 선택 참조), 이는 높은 읽기 성능을 제공하기 위해 많이 압축되어 있음을 의미합니다. 또한 Amazon Redshift는 색인(Index)을 생성하고 관리할 필요가 없다는 것을 의미합니다. 즉, 모든 열은 저장되는 데이터에 적합한 구조와 함께 자체 색인과 거의 같습니다.
열 인코딩을 사용하지 않고 Amazon Redshift 클러스터를 실행하는 것은 좋지 않은 방법이며, 열 인코딩이 최적으로 적용될 때 고객이 큰 성능을 얻을 수 있습니다. 이 모범 사례에서 벗어나는 경우 다음 쿼리를 실행하여 열 인코딩이 적용되지 않은 테이블이 있는지 확인하십시오.
SELECT database, schema || '.' || "table" AS "table", encoded, size
FROM svv_table_info
WHERE encoded='N'
ORDER BY 2;
그렇게 난 후, 다음 쿼리를 실행하여 인코딩되지 않은 테이블과 열을 검토하십시오.
SELECT trim(n.nspname || '.' || c.relname) AS "table",trim(a.attname) AS "column",format_type(a.atttypid, a.atttypmod) AS "type",
format_encoding(a.attencodingtype::integer) AS "encoding", a.attsortkeyord AS "sortkey"
FROM pg_namespace n, pg_class c, pg_attribute a
WHERE n.oid = c.relnamespace AND c.oid = a.attrelid AND a.attnum > 0 AND NOT a.attisdropped and n.nspname NOT IN ('information_schema','pg_catalog','pg_toast') AND format_encoding(a.attencodingtype::integer) = 'none' AND c.relkind='r' AND a.attsortkeyord != 1 ORDER BY n.nspname, c.relname, a.attnum;
최적으로 열 인코딩을 하지 않은 테이블이 있으면 AWS Labs GitHub의 Amazon Redshift Column Encoding 유틸리티를 사용하여 인코딩을 적용하십시오. 이 명령 행 유틸리티는 각 테이블에서 ANALYZE COMPRESSION 명령을 사용합니다. 만약 인코딩이 필요한 경우, 올바른 인코딩으로 새 테이블을 만들고 모든 데이터를 새 테이블에 복사 한 다음 원래 데이터를 유지하면서 새 테이블의 이름을 이전 이름으로 트랜잭션 방식으로 변경하는 SQL 스크립트를 생성합니다. (복합 정렬 키(compound sort key)의 첫 번째 열은 인코딩 하면 안되며, 이 유틸리티로 인코딩 되지 않습니다.)
이슈 #2 : 왜곡된 테이블 데이터
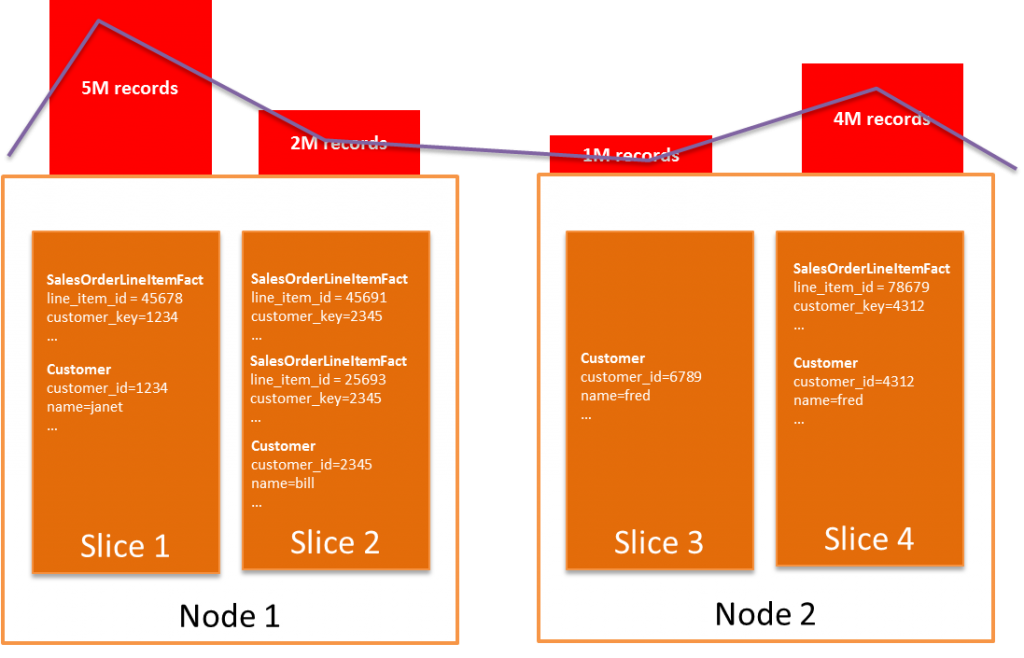
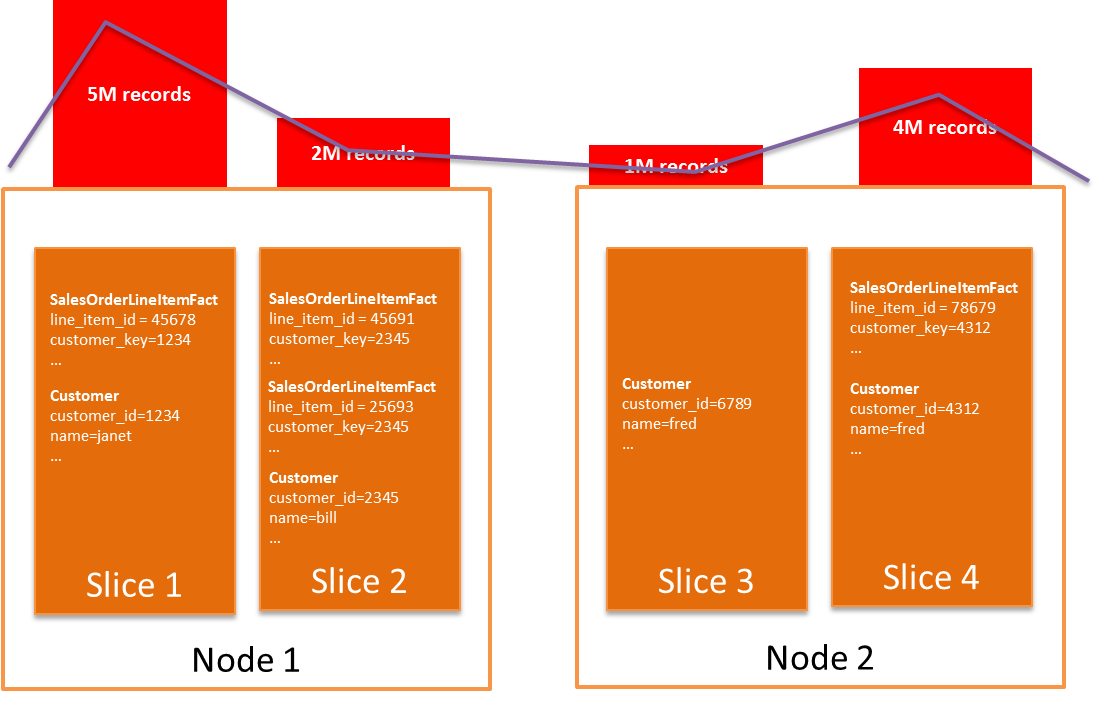
Amazon Redshift는 클러스터의 각 노드가 전체 데이터의 일부를 저장하는 분산된 비 공유 데이터베이스 아키텍처입니다. 테이블을 만들 때 노드 간에 데이터를 고르게 분산(기본값) 할지 또는 열 중 하나를 기준으로 노드에 데이터를 분산할지 결정해야 합니다. 일반적으로 함께 조인되는 열을 분산의 기준으로 선택하면, 조인 중에 네트워크를 통해 전송되는 데이터의 양을 최소화 할 수 있습니다. 이렇게 하면 여러가지 유형의 쿼리에서 성능이 크게 향상 될 수 있습니다.
좋은 분산 키(Distribution Key)를 선택하는 것은 “가장 적합한 분산 스타일 선택“을 포함한 많은 AWS 관련 글들의 주제입니다. Amazon Redshift 에서 스타 스키마 최적화 및 인터리빙된 정렬 블로그 게시물을 통해 스타 스키마의 분산과 정렬에 대한 확실한 안내를 받으시기 바랍니다. 일반적으로 좋은 분산 키는 다음과 같은 속성을 가지고 있습니다.
- 높은 카디널리티 – 클러스터의 노드 수에 비례하여 열에 많은 수의 고유 한 데이터 값이 있어야 합니다.
- 균일 분산 / 저 왜곡 – 분산 키의 각 고유 값은 테이블에서 짝수 번 발생해야 합니다. 이렇게 하면 Amazon Redshift가 클러스터의 각 노드에 동일한 수의 레코드를 넣을 수 있습니다.
- 일반적으로 조인 – 분산 키의 열은 일반적으로 다른 테이블에 조인하는 열 이어야 합니다. 이 기준에 맞는 여러 개의 가능한 열이 있는 경우 가장 큰 테이블에 조인하는 열을 선택할 수 있습니다.
왜곡된 분산 키는 쿼리 실행 시 각 노드들이 똑같이 힘들지 않고, CPU 또는 메모리의 불균형이 발생하며 그리고 궁극적으로 가장 느린 노드의 속도만큼 실행됩니다.


왜곡 문제가 있는 경우 일반적으로 노드들의 성능이 클러스터에서 고르지 않은 것으로 나타납니다. Amazon Redshift Utils GitHub 저장소의 관리 스크립트 중 하나(예 : table_inspector.sql)를 사용하여 분산 키의 데이터 블록을 클러스터의 슬라이스 및 노드에 매핑하는 방법을 확인하십시오.
왜곡된 분산 키가 있는 테이블이 있는 경우, 배포 키를 높은 카디널리티와 균일 한 분포를 나타내는 열로 변경하십시오. CTAS를 사용하여 새 테이블을 작성하여 후보 열을 분산 키로 평가하십시오.
CREATE TABLE MY_TEST_TABLE DISTKEY (<COLUMN NAME>) AS SELECT * FROM <TABLE NAME>;테이블에 대해 table_inspector.sql 스크립트를 다시 실행하여 데이터 왜곡을 분석하십시오.
레코드에 좋은 분산 키가 없으면 단일 노드를 핫스폿으로 만들지 않기 위해 EVEN 방식으로 분산하는 것이 효과적이라는 것을 알 수 있습니다. 작은 테이블의 경우 DISTSTYLE ALL을 사용하여 테이블 데이터를 클러스터 내의 모든 노드에 저장 할 수 있습니다.
이슈 #3 : 정렬 키를 사용하지 않는 쿼리
Amazon Redshift 테이블에는 다른 데이터베이스의 인덱스처럼 작동하지만 다른 플랫폼과는 달리 저장소 비용이 발생하지 않는 정렬 키 열을 설정할 수 있습니다. 자세한 내용은 정렬 키 선택을 참조하십시오. 정렬 키는 WHERE 절에서 가장 일반적으로 사용되는 열에 작성되어야 합니다. 알려진 쿼리 패턴이 있는 경우 COMPOUND 정렬 키가 최상의 성능을 제공합니다. 최종 사용자가 다른 열을 똑같이 쿼리하면 INTERLEAVED 정렬 키를 사용하십시오.
정렬 키가 없는 테이블을 찾고, 얼마나 자주 쿼리가 되었는지 확인하려면 다음 쿼리를 실행합니다.
SELECT database, table_id, schema || '.' || "table" AS "table", size, nvl(s.num_qs,0) num_qs
FROM svv_table_info t
LEFT JOIN (SELECT tbl, COUNT(distinct query) num_qs
FROM stl_scan s
WHERE s.userid > 1
AND s.perm_table_name NOT IN ('Internal Worktable','S3')
GROUP BY tbl) s ON s.tbl = t.table_id
WHERE t.sortkey1 IS NULL
ORDER BY 5 desc;
Amazon Redshift Developer Guide에서 정렬되지 않은 테이블을 처리하는 방법론을 참고하실 수 있습니다. 또한 쿼리 활동을 기반으로 정렬 키 권장 이라는 GitHub 의 관리 스크립트를 활용할 수도 있습니다. 정렬 키 열에 대해 평가 된 조회는 정렬 키에 SQL 함수를 적용해서는 안됩니다. 대신 비교 값에 함수를 적용하여 정렬 키가 사용되는지 확인하십시오. 이것은 일반적으로 정렬 키로 사용되는 TIMESTAMP 컬럼에서 발견됩니다.


이슈 #4 : 통계가 없거나 버큠(vacuum)이 필요한 테이블
Amazon Redshift는 다른 데이터베이스와 마찬가지로 쿼리를 계획 할 때 올바른 결정을 내리기 위해 테이블 및 저장될 테이터 블록의 구성에 대한 통계정보가 필요합니다(자세한 내용은 테이블 분석 참조). 좋은 통계가 없으면 옵티마이저는 테이블에 액세스하는 순서나 데이터 세트를 조인하는 방법에 대해 최선이 아니거나 잘못된 선택을 할 수 있습니다.
Amazon Redshift Developer Guide의 ANALYZE Command History 항목은 누락되거나 부실한 통계를 해결하는 데 도움이 되는 쿼리를 제공하며, missing_table_stats.sql 관리 스크립트를 실행하여 통계가 누락 된 테이블을 확인하거나 아래 구문을 사용하여 오래된 통계정보를 가지고 있는 테이블을 확인할 수 있습니다.
SELECT database, schema || '.' || "table" AS "table", stats_off
FROM svv_table_info
WHERE stats_off > 5
ORDER BY 2;
Amazon Redshift에서 데이터 블록은 변경 불가능합니다. 행이 삭제되거나 업데이트되면 단순히 논리적으로 삭제되고 (삭제 플래그가 있음) 디스크에서 물리적으로 제거되지는 않습니다. 업데이트로 인해 새로운 블록이 작성되고 새로운 데이터가 추가됩니다. 이 두 가지 조작으로 인해 행의 이전 버전이 계속해서 디스크 스페이스를 소비하고 특정 쿼리가 테이블을 스캔할 때 논리적으로 삭제된 행이 계속 읽히게 됩니다. 결과적으로, 테이블의 저장 공간이 증가하고, 스캔 중에 디스크 I/O를 피할 수 없으므로 성능이 저하됩니다. VACUUM 명령은 삭제 된 행에서 공간을 복구하고 정렬 순서를 복원합니다.
누락되거나 오래된 통계가 있거나 버큠이 필요한 테이블 문제를 해결하려면 AWS Labs 유틸리티인 Analyze & Vacuum Schema 를 실행하십시오. 이렇게 하면 항상 최신 통계를 유지하고 실제로 재구성이 필요한 테이블들만 버큠을 할 수 있습니다.
이슈 # 5 – 매우 큰 VARCHAR 열을 가진 테이블
복잡한 쿼리를 처리하는 동안 중간 쿼리 결과를 임시 블록에 저장해야 할 수 있습니다. 이러한 임시 테이블은 압축되지 않으므로 불필요하게 넓은 열은 과도한 메모리 및 임시 디스크 공간을 소비하므로 쿼리 성능에 영향을 줄 수 있습니다. 자세한 내용은 가능한 가장 작은 열 크기 사용을 참조하십시오.
다음 쿼리를 사용하여 최대 열 너비를 포함하는 테이블 목록을 검토할 수 있습니다.
다음 쿼리를 사용하여 최대 열 너비를 포함하는 테이블 목록을 검토할 수 있습니다.
SELECT database, schema || '.' || "table" AS "table", max_varchar
FROM svv_table_info
WHERE max_varchar > 150
ORDER BY 2;
테이블 목록을 얻은 후에는, 다음 쿼리를 사용하여 넓은 varchar 열을 가진 테이블 열을 식별 한 다음 각 열에 대한 실제 최대 너비를 결정하십시오.
SELECT max(len(rtrim(column_name)))
FROM table_name;
경우에 따라 JSON 함수를 사용하여 쿼리하는 JSON 조각을 테이블에 저장하기 때문에 큰 VARCHAR 유형 열이 있을 수 있습니다. top_queries.sql 관리 스크립트를 사용하여 데이터베이스에 대해 가장 많이 실행되는 쿼리를 찾는 경우, JSON 조각 열을 포함하는 SELECT * 쿼리에 특히 주의하십시오. 최종 사용자가 이러한 큰 열을 쿼리하지만 실제로 JSON 함수를 사용하지 않으면, 원래 테이블의 기본 키 열과 JSON 열만 포함하는 다른 테이블로 데이터를 이동하는 것이 좋습니다.
필요한 것보다 넓은 열이 테이블에 있는 경우 deep copy 를 수행하여 적절한 너비의 열로 구성되는 새로운 버전의 테이블을 만들어야 합니다.
이슈# 6 – 큐(Queue) 슬롯에서 대기중인 쿼리
Amazon Redshift는 작업 부하 관리(WLM)라는 큐 시스템을 사용하여 쿼리를 실행합니다. 서로 다른 작업 부하를 분리하기 위해 최대 8 개의 큐를 정의 할 수 있으며 전체 처리량 요구 사항을 충족하도록 개별 큐의 동시성을 설정할 수 있습니다.
어떤 경우에는 사용자 또는 쿼리가 할당 된 큐가 완전히 사용 중이어서 추가 쿼리는 슬롯이 열릴 때까지 대기 해야합니다. 이 시간 동안 시스템은 추가 쿼리를 전혀 실행하지 못하기 때문에 이는 동시성을 높여야 한다는 신호입니다.
먼저 queuing_queries.sql 관리 스크립트를 사용하여 쿼리가 대기 중인지 여부를 확인해야합니다. 그리고 난 후 wlm_apex.sql을 사용하여 과거에 클러스터가 필요로 했던 최대 동시성을 검토하고 wlm_apex_hourly.sql을 사용하여 시간별 히스토리 분석을 진행하십시오. 동시성을 높이면, 동시에 더 많은 쿼리를 실행할 수 있지만 동일한 양의 메모리(증가시키지 않는 한)를 공유한다는 점을 유의하십시오. 동시성을 높이면 일부 쿼리는 실행 중에 임시 디스크 저장소를 사용하여야 하며, 다음 문제에서 볼 수 있듯이 최적의 방안은 아닙니다.
이슈 # 7 – 디스크 기반 쿼리
쿼리가 메모리에서 완전히 실행될 수 없는 경우, Explain 플랜의 일부에 대해 디스크 기반의 임시 저장 영역을 사용해야 할 수도 있습니다. 추가적인 디스크 I/O는 쿼리 속도를 늦추게 되는데, 이는 세션에 할당 된 메모리 양을 늘림으로써 해결할 수 있습니다(자세한 내용은 WLM 동적 메모리 할당 참조).
디스크에 사용하는 쿼리가 있는지 확인하려면 다음 쿼리를 사용하십시오.
SELECT
q.query, trim(q.cat_text)
FROM (SELECT query, replace( listagg(text,' ') WITHIN GROUP (ORDER BY sequence), 'n', ' ') AS cat_text FROM stl_querytext WHERE userid>1 GROUP BY query) q
JOIN
(SELECT distinct query FROM svl_query_summary WHERE is_diskbased='t' AND (LABEL LIKE 'hash%' OR LABEL LIKE 'sort%' OR LABEL LIKE 'aggr%') AND userid > 1) qs ON qs.query = q.query;
사용자 또는 큐 할당 규칙에 따라 선택한 큐에 지정된 메모리 양을 늘려서 완료해야하는 쿼리가 디스크를 사용하지 않도록 할 수 있습니다. 세션의 WLM_QUERY_SLOT_COUNT 를 기본값인 1에서 큐의 최대 동시성으로 늘릴 수도 있습니다. 문제# 6에서 설명한 것처럼 쿼리 대기열이 생길 수 있으므로 주의해서 사용해야 합니다.
이슈 # 8 – 커밋 큐 대기
Amazon Redshift는 트랜잭션 처리가 아닌 분석 쿼리를 위해 설계 되었습니다. COMMIT 비용이 상대적으로 높기 때문에 COMMIT를 과도하게 사용하면 쿼리가 커밋 큐를 액세스하기 위해 기다릴 수 있습니다.
데이터베이스에 너무 자주 커밋하는 경우commit_stats.sql 관리 스크립트로 커밋 큐에서 대기하는 쿼리가 증가하는 것을 볼 수 있습니다. 이 스크립트는 지난 2 일 동안 실행 된 쿼리의 최대 큐 길이 및 큐 시간을 보여줍니다. 만약 커밋 큐에서 대기중인 쿼리가 있는 경우, 진행상황을 로깅하거나 비효율적인 데이터 로드를 구행하는 ETL 작업과 같이, 세션 당 다수의 커밋을 수행하는 세션을 찾아야 합니다.
이슈 # 9 – 비효율적인 데이터 로드
Amazon Redshift 모범 사례는 COPY 명령을 사용하여 데이터로드를 수행 할 것을 제안합니다. 이 API 작업은 클러스터의 모든 컴퓨트 노드를 사용하여 Amazon S3, Amazon DynamoDB, Amazon EMR HDFS 파일 시스템 또는 SSH 연결과 같은 원본에서 데이터를 병렬로 로드 합니다.
데이터 로드를 수행 할 때 가능하다면 로드 할 파일을 압축해야 합니다. Amazon Redshift는 GZIP 및 LZO 압축을 모두 지원합니다. 하나의 큰 파일보다 많은 수의 작은 파일을 로드하는 것이 더 효율적이며 이상적인 파일 수는 슬라이스 수의 배수입니다. 노드 당 슬라이스 수는 클러스터의 노드 크기에 따라 다릅니다. 예를 들어, 각 DS1.XL 컴퓨트 노드에는 두 개의 슬라이스가 있고 각 DS1.8XL 컴퓨트 노드에는 16 개의 슬라이스가 있습니다. 슬라이스 당 짝수 개의 파일을 사용함으로써 COPY 실행이 클러스터 리소스를 고르게 사용하고 최대한 빨리 완료됨을 알 수 있습니다.
안티 패턴은 단일 레코드를 INSERT 하거나 또는 한 번에 최대 16MB 데이터를 INSERT 할 수 있는 다중 값 INSERT 문의 사용으로 Amazon Redshift에 직접 데이터를 INSERT하는 것입니다. 이는 리더 노드 기반 작업이며 리더 노드의 CPU 또는 메모리 사용을 극대화하여 성능 병목 현상을 유발할 수 있습니다.
이슈 # 10 – 비효율적인 임시 테이블 사용
Amazon Redshift는 임시 테이블을 제공합니다. 이 테이블은 단일 세션 내에서만 볼 수 있다는 것을 제외하면 일반 테이블과 같습니다. 사용자가 세션의 연결을 끊으면 테이블은 자동으로 삭제됩니다. 임시 테이블은 CREATE TEMPORARY TABLE 구문을 사용하거나 SELECT … INTO #TEMP_TABLE 쿼리를 실행하여 만들 수 있습니다. SELECT … INTO 및 C(T)TAS 명령은 입력 데이터를 사용하여 열 이름, 크기 및 데이터 유형을 결정하고 기본 저장소 특성을 사용하는 반면 CREATE TABLE 문은 임시 테이블의 정의를 완벽하게 제어합니다.
이러한 기본 저장소 속성은 신중하게 고려하지 않으면 문제가 발생할 수 있습니다. Amazon Redshift의 기본 테이블 구조는 열 인코딩이 없는 EVEN 분산 방법을 사용하는 것입니다. 이것은 많은 유형의 쿼리에 대해 차선의 데이터 구조이며, select/into 구문을 사용하는 경우 열 인코딩이나 분산 및 정렬 키를 설정할 수 없습니다.
CREATE 문을 사용하려면 모든 select/into 구문을 변환하실 것을 권장합니다. 이렇게 하면 임시 테이블에 열 인코딩이 적용되고 워크플로의 일부인 다른 엔터티에 동정적인 방식으로 분산됩니다. 사용하는 명령문을 변환하려면 다음을 수행하십시오.
select column_a, column_b into #my_temp_table from my_table;
최적의 열 인코딩을 위해 임시 테이블을 분석합니다.


그런 다음 select/into 문을 다음으로 변환합니다.
BEGIN;
create temporary table my_temp_table(
column_a varchar(128) encode lzo,
column_b char(4) encode bytedict)
distkey (column_a) -- Assuming you intend to join this table on column_a
sortkey (column_b); -- Assuming you are sorting or grouping by column_b
insert into my_temp_table select column_a, column_b from my_table;
COMMIT;
임시 테이블이 후속 쿼리의 조인 테이블로 사용되는 경우 임시 테이블의 통계를 분석 할 수도 있습니다.
analyze my_temp_table;
이렇게 하면, 분산 키를 지정하고 열 인코딩을 사용하여 Amazon Redshift의 열 기반 특성의 장점을 취함으로써, 임시 테이블을 사용하는 기능은 그대로 유지되지만 클러스터에 데이터 위치를 제어 할 수 있습니다.
Tip: Explain plan 경고 사용
마지막 팁은 쿼리 실행 중에 클러스터의 진단 정보를 사용하는 것입니다. 이것은 STL_ALERT_EVENT_LOG라는 매우 유용한 뷰(view)에 저장됩니다. perf_alert.sql 관리 스크립트를 사용하여 지난 7 일 동안 클러스터에서 발생한 문제를 진단할 수 있습니다. 이는 시간이 지남에 따라 클러스터가 어떻게 발전 하는지를 이해하는 데 매우 귀중한 자료입니다.
요약
Amazon Redshift는 클라우드 기반에서 성능을 크게 향상시키고 비용을 절감 할 수 있는 완벽하게 관리되는 강력한 데이터 웨어하우스 입니다. Amazon Redshift는 모든 유형의 데이터 모델을 실행할 수 있지만 데이터를 저장하고 관리하는 방법을 알고 있으면 성능이 저하되거나 비용이 증가 할 수 있는 오류를 피할 수 있습니다. 일반적인 문제에 대한 간단한 진단 쿼리들을 실행하고 최상의 성능을 얻을 수 있도록 하십시오.
—
데이터 로딩 성능을 높이려면, Amazon Redshift에서 빠르게 데이터 로딩하기 글을 참고하시기 바랍니다.
본 글은 아마존웹서비스 코리아의 솔루션즈 아키텍트가 국내 고객을 위해 전해 드리는 AWS 활용 기술 팁을 보내드리는 코너로서, 이번 글은 양승도 솔루션즈 아키텍트께서 번역해주셨습니다.

