


Amazon Redshift 신규 기능 – Kinesis Data Streams 및 Kafka용 관리형 스트리밍 수집 정식 출시

10년 전, 제가 AWS에 입사한 지 불과 몇 달 만에 Amazon Redshift가 출시되었습니다. 수년에 걸쳐 성능을 개선하고 더 쉽게 사용할 수 있게 많은 기능을 추가했습니다. Amazon Redshift를 사용하면 이제 데이터 웨어하우스, 운영 데이터베이스 및 데이터 레이크에 걸쳐 구조화된 데이터와 반정형 데이터를 분석할 수 있습니다. 최근에는 데이터 웨어하우스 인프라를 관리하지 않고도 분석을 쉽게 실행하고 확장할 수 있는 Amazon Redshift Serverless를 정식 출시했습니다.
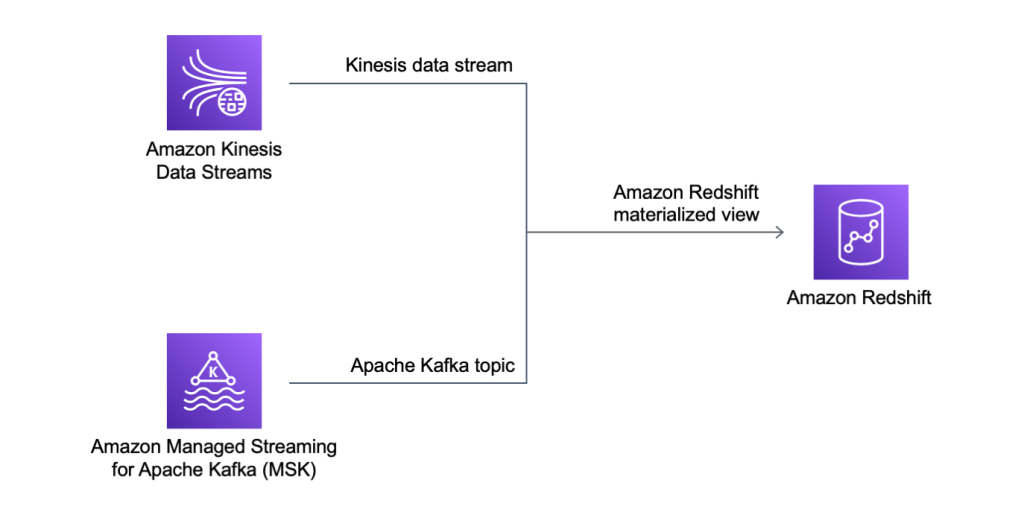
실시간 애플리케이션의 데이터를 최대한 빠르게 처리하기 위해 고객은 Amazon Kinesis와 Apache Kafka용 Amazon 관리형 스트리밍과 같은 스트리밍 엔진을 채택하고 있습니다. 이전에는 스트리밍 데이터를 Amazon Redshift 데이터베이스로 로드하려면 로드하기 전에 Amazon Simple Storage Service(S3)에 데이터를 스테이징하는 프로세스를 구성해야 했습니다. 이렇게 하면 데이터의 양에 따라 1분 이상의 지연 시간이 발생합니다.
오늘은 Amazon Redshift 스트리밍 수집의 일반 가용성에 대해 알려드리게 되어 기쁩니다. 이 새로운 기능을 통해 Amazon Redshift는 기본적으로 Amazon Kinesis Data Streams과 Amazon MSK로부터 초당 수백 메가바이트의 데이터를 Amazon Redshift 구체화된 뷰로 수집하여 몇 초 만에 쿼리할 수 있습니다.

스트리밍 수집은 구체화된 뷰를 통해 쿼리 성능 최적화 기능을 활용하고 Amazon Redshift를 운영 분석에 더 효율적으로 사용하며 실시간 대시보드의 데이터 소스로 사용할 수 있습니다. 스트리밍 수집의 또 다른 흥미로운 사용 사례는 게이머의 실시간 데이터를 분석하여 게임 경험을 최적화하는 것입니다. 또한 이 새로운 통합을 통해 IoT 장치, 클릭스트림 분석, 애플리케이션 모니터링, 사기 탐지 및 실시간 순위표에 대한 분석을 더 쉽게 구현할 수 있습니다.
실제로 어떻게 작동하는지 알아보겠습니다.
Amazon Redshift 스트리밍 수집 구성
권한 관리 외에도 Amazon Redshift 스트리밍 수집은 Amazon Redshift 내에서 SQL을 사용하여 완전히 구성할 수 있습니다. 이는 AWS Management Console에 대한 액세스 권한이 없거나 AWS 서비스 간 통합을 구성할 전문 지식이 부족한 비즈니스 사용자에게 특히 유용합니다.
다음 세 단계로 스트리밍 수집을 설정할 수 있습니다.
- AWS Identity and Access Management(IAM) 역할을 생성 또는 업데이트하여 사용 중인 스트리밍 플랫폼(Kinesis Data Streams 또는 Amazon MSK)에 액세스할 수 있습니다. IAM 역할에는 Amazon Redshift가 해당 역할을 맡을 수 있도록 허용하는 신뢰 정책이 있어야 한다는 점에 유의하십시오.
- 스트리밍 서비스에 연결하기 위한 외부 스키마를 생성합니다.
- 외부 스키마의 스트리밍 객체(Kinesis 데이터 스트림 또는 Kafka 주제)를 참조하는 구체화된 뷰를 생성합니다.
그런 다음 구체화된 뷰를 쿼리하여 스트림의 데이터를 분석 워크로드에 사용할 수 있습니다. 스트리밍 수집은 Amazon Redshift 프로비저닝 클러스터 및 새로운 서버리스 옵션에서 작동합니다. 이번 실습에서는 단순성을 극대화하기 위해 Amazon Redshift 서버리스를 사용하겠습니다.
환경을 준비하려면 Kinesis 데이터 스트림이 필요합니다. Kinesis 콘솔의 탐색창에서 데이터 스트림, 데이터 스트림 생성을 차례로 선택합니다. 데이터 스트림 이름의 경우 my-input-stream을 사용하고 다른 모든 옵션은 기본값으로 설정된 상태로 둡니다. 몇 초 후 Kinesis 데이터 스트림이 준비됩니다. 참고로 저는 기본적으로 온디맨드 용량 모드를 사용하고 있습니다. 개발 또는 테스트 환경에서는 비용을 최적화하기 위해 프로비저닝된 용량 모드를 한개의 샤드로 선택할 수 있습니다.
이제 IAM 역할을 생성하여 Amazon Redshift에 my-input-stream Kinesis Data Streams에 대한 접근 권한를 부여합니다. IAM 콘솔에서 다음 정책으로 역할을 생성합니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"kinesis:DescribeStreamSummary",
"kinesis:GetShardIterator",
"kinesis:GetRecords",
"kinesis:DescribeStream"
],
"Resource": "arn:aws:kinesis:*:123412341234:stream/my-input-stream"
},
{
"Effect": "Allow",
"Action": [
"kinesis:ListStreams",
"kinesis:ListShards"
],
"Resource": "*"
}
]
}Amazon Redshift가 역할을 맡을 수 있도록 하기 위해 다음과 같은 신뢰 정책을 사용합니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "redshift.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}Amazon Redshift 콘솔의 탐색 창에서 Redshift 서버리스를 선택하고 이 블로그 게시물에서 수행한 것과 비슷한 새 작업 그룹과 네임스페이스를 생성합니다. 네임스페이스를 생성할 때 권한 섹션의 드롭다운 메뉴에서 IAM 역할 연결을 선택합니다. 그런 다음 방금 생성한 역할을 선택합니다. 이 선택 항목에는 신뢰 정책에서 Amazon Redshift가 역할을 맡도록 허용하는 경우에만 해당 역할이 표시된다는 점에 유의하십시오. 그런 다음 기본 옵션을 사용하여 네임스페이스 생성을 완료합니다. 몇 분 후 서버리스 데이터베이스를 사용할 수 있습니다.
Amazon Redshift 콘솔에서 쿼리 편집기 v2를 선택합니다. 리소스 목록에서 새 서버리스 데이터베이스를 선택하여 연결합니다. 이제 SQL을 사용하여 스트리밍 수집을 구성할 수 있습니다. 먼저 스트리밍 서비스에 매핑되는 외부 스키마를 생성합니다. 저는 예제로 시뮬레이트된 IoT 데이터를 사용할 것이기 때문에 센서라고 하는 외부 스키마를 만듭니다.
CREATE EXTERNAL SCHEMA sensors
FROM KINESIS
IAM_ROLE 'arn:aws:iam::123412341234:role/redshift-streaming-ingestion';스트림 데이터에 액세스하기 위해 스트림에서 데이터를 조회하는 구체화된 뷰를 생성합니다. 일반적으로 구체화된 뷰는 쿼리 결과를 기반으로 미리 계산된 결과 집합을 포함합니다. 이러한 경우 쿼리는 스트림에서 데이터를 읽고 Amazon Redshift는 스트림의 소비자가 됩니다.
스트리밍 데이터가 JSON 데이터로 수집될 것이기 때문에 아래와 같은 두 가지 옵션이 있습니다.
- 모든 JSON 데이터를 하나의 컬럼에 저장하고, Amazon Redshift 는 반정형 데이터를 쿼리합니다.
- JSON 속성을 여러 개의 컬럼으로 추출합니다.
위 두 옵션의 장단점을 살펴보겠습니다.
SELECT 구문에 있는 approximate_arrival_timestamp, partition_key, shard_id 및 sequence_number 컬럼은 Kinesis Data Streams에서 제공됩니다. 스트림의 레코드는 kinesis_data 컬럼에 있습니다. refresh_time 컬럼은 Amazon Redshift에서 제공됩니다.
JSON 데이터를 sensor_data 구체화된 뷰의 단일 열에 저장하려면 JSON_PARSE 함수를 사용합니다.
CREATE MATERIALIZED VIEW sensor_data AUTO REFRESH YES AS
SELECT approximate_arrival_timestamp,
partition_key,
shard_id,
sequence_number,
refresh_time,
JSON_PARSE(kinesis_data, 'utf-8') as payload
FROM sensors."my-input-stream";
CREATE MATERIALIZED VIEW sensor_data AUTO REFRESH YES AS
SELECT approximate_arrival_timestamp,
partition_key,
shard_id,
sequence_number,
refresh_time,
JSON_PARSE(kinesis_data) as payload
FROM sensors."my-input-stream";AUTO REFRESH YES 파라미터를 사용했기 때문에 스트림에 새 데이터가 있으면 구체화된 뷰의 내용이 자동으로 새로 수정됩니다.
JSON 속성을 sensor_data_extract 구체화된 뷰의 개별 컬럼으로 추출하려면 JSON_EXTRACT_PATH_TEXT 함수를 사용합니다.
CREATE MATERIALIZED VIEW sensor_data_extract AUTO REFRESH YES AS
SELECT approximate_arrival_timestamp,
partition_key,
shard_id,
sequence_number,
refresh_time,
JSON_EXTRACT_PATH_TEXT(FROM_VARBYTE(kinesis_data, 'utf-8'),'sensor_id')::VARCHAR(8) as sensor_id,
JSON_EXTRACT_PATH_TEXT(FROM_VARBYTE(kinesis_data, 'utf-8'),'current_temperature')::DECIMAL(10,2) as current_temperature,
JSON_EXTRACT_PATH_TEXT(FROM_VARBYTE(kinesis_data, 'utf-8'),'status')::VARCHAR(8) as status,
JSON_EXTRACT_PATH_TEXT(FROM_VARBYTE(kinesis_data, 'utf-8'),'event_time')::CHARACTER(26) as event_time
FROM sensors."my-input-stream";Kinesis 데이터 스트림으로 데이터 로드
my-input-stream Kinesis 데이터 스트림에 데이터를 넣으려면 IoT 센서의 데이터를 시뮬레이션하는 다음의 random_data_generator.py Python 스크립트를 사용합니다.
import datetime
import json
import random
import boto3
STREAM_NAME = "my-input-stream"
def get_random_data():
current_temperature = round(10 + random.random() * 170, 2)
if current_temperature > 160:
status = "ERROR"
elif current_temperature > 140 or random.randrange(1, 100) > 80:
status = random.choice(["WARNING","ERROR"])
else:
status = "OK"
return {
'sensor_id': random.randrange(1, 100),
'current_temperature': current_temperature,
'status': status,
'event_time': datetime.datetime.now().isoformat()
}
def send_data(stream_name, kinesis_client):
while True:
data = get_random_data()
partition_key = str(data["sensor_id"])
print(data)
kinesis_client.put_record(
StreamName=stream_name,
Data=json.dumps(data),
PartitionKey=partition_key)
if __name__ == '__main__':
kinesis_client = boto3.client('kinesis')
send_data(STREAM_NAME, kinesis_client)스크립트를 실행하고 스트림에 저장되는 레코드를 확인합니다. 이 레코드는 JSON 구문을 사용하며 임의의 데이터를 포함합니다.
Amazon Redshift에서 스트리밍 데이터 쿼리하기
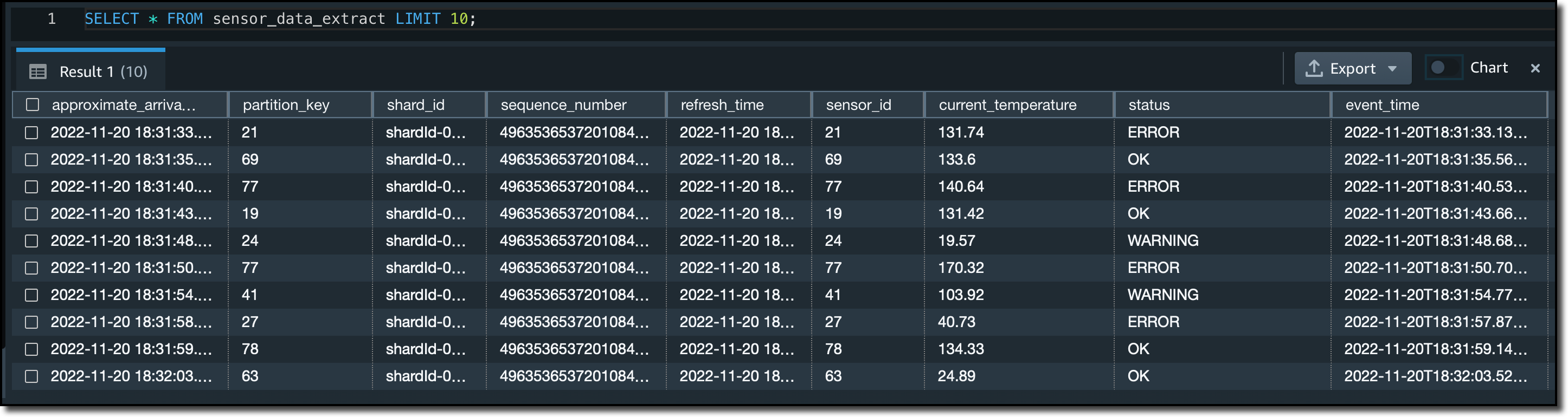
두 개의 구체화된 뷰를 비교하기 위해 각 뷰에서 처음 10개 행을 조회합니다.
sensor_data구체화된 뷰에서 스트림의 JSON 데이터는페이로드컬럼에 있습니다. Amazon Redshift JSON 함수를 사용하여 JSON 형식으로 저장한 데이터에 액세스할 수 있습니다.
sensor_data_extract구체화된 뷰에서 스트림의 JSON 데이터는sensor_id,current_temperature,status및event_time등의 여러 컬럼으로 추출되었습니다.

이제 분석 워크로드에서 이러한 뷰의 데이터를 데이터 웨어하우스, 운영 데이터베이스 및 데이터 레이크의 데이터와 함께 사용할 수 있습니다. 이러한 뷰의 데이터를 Redshift ML과 함께 사용하여 기계 학습 모델을 학습하거나 예측 분석을 사용할 수 있습니다. 구체화된 뷰는 증분 업데이트를 지원하므로 Amazon Redshift를 Amazon Managed Grafana의 데이터 소스로 사용하는 등 이러한 뷰의 데이터를 대시보드의 데이터 소스로 효율적으로 사용할 수 있습니다.
가용성 및 요금
Kinesis Data Streams과 Apache Kafka용 관리형 스트리밍에 대한 Amazon Redshift 스트리밍 수집은 현재 모든 상용 AWS 리전에서 출시되었습니다.
Amazon Redshift 스트리밍 수집을 사용할 때 추가 비용이 들지 않습니다. 자세한 내용은 Amazon Redshift 요금을 참조하십시오.
데이터 웨어하우스와 데이터 레이크에서 지연 시간이 짧은 스트리밍 데이터를 사용하는 것이 그 어느 때보다 쉬워졌습니다. 이 새로운 기능으로 무엇을 구축했는지 알려주세요!
— Danilo
Source: Amazon Redshift 신규 기능 – Kinesis Data Streams 및 Kafka용 관리형 스트리밍 수집 정식 출시