


Amazon Redshift 쿼리 캐싱을 위해 pgpool 및 Amazon ElastiCache 사용
최근 국내의 많은 고객 분들이 Amazon Redshift 도입을 고려하고 계시거나, 또는 이미 도입하여 사용하고 계십니다. OLTP 뿐만 아니라 데이터 웨어하우스 시스템에서도 쿼리 캐싱은 전체적인 사용자 체감 속도를 개선할 수 있는 아주 좋은 방법입니다. 쿼리 캐싱을 위한 다양한 방법이 있겠지만, pgpool 및 Amazon ElastiCache 사용에 대한 좋은 블로그 글이 있어 소개하도록 하겠습니다.
원문은 Using pgpool and Amazon ElastiCache for Query Caching with Amazon Redshift (https://aws.amazon.com/blogs/big-data/using-pgpool-and-amazon-elasticache-for-query-caching-with-amazon-redshift/)입니다.
이 글에서는 실제 고객 시나리오를 사용하여 pgpool 및 Amazon ElastiCache를 사용하여 Amazon Redshift 앞에 캐시 레이어를 만드는 방법을 보여줍니다.
거의 모든 애플리케이션은 아무리 간단한 것이든 어떤 종류의 데이터베이스를 사용합니다. SQL 쿼리를 자주 사용하게 되면 때때로 중복 실행이 발생할 수 있습니다. 이러한 중복성은 다른 작업에 할당 될 수 있는 자원을 낭비합니다.
예를 들어 Amazon Redshift에 위치한 데이터를 사용하는 BI 도구 및 애플리케이션은 일반적인 쿼리를 실행할 가능성이 높습니다. 최종 사용자 환경을 개선하고 데이터베이스의 경합을 줄이기 위해 그중 일부를 캐시 할 수 있습니다. 사실 좋은 데이터 모델링 및 분류 정책을 사용하여 클러스터 크기를 줄임으로써 비용을 절약 할 수 있습니다.
캐싱이란 무엇입니까?
컴퓨팅에서 캐시는 데이터를 저장하는 하드웨어 또는 소프트웨어 구성 요소이므로 향후 해당 데이터에 대한 요청을 더 빨리 처리 할 수 있습니다. 캐시에 저장된 데이터는 이전 계산의 결과이거나 다른 곳에 저장된 데이터의 복제 일 수 있습니다. 요청 된 데이터가 캐시에서 발견되면 캐시 히트가 발생합니다. 그렇지 않은 경우 캐시 미스가 발생합니다. 캐시 히트는 캐시에서 데이터를 읽어 제공하기 때문에 결과를 다시 계산하거나 느린 데이터 저장소에서 읽는 것보다 빠릅니다. 캐시가 더 많은 요청을 처리 할수록 시스템은 더 빠르게 운영될 수 있습니다.
고객 사례 : 실험실 분석
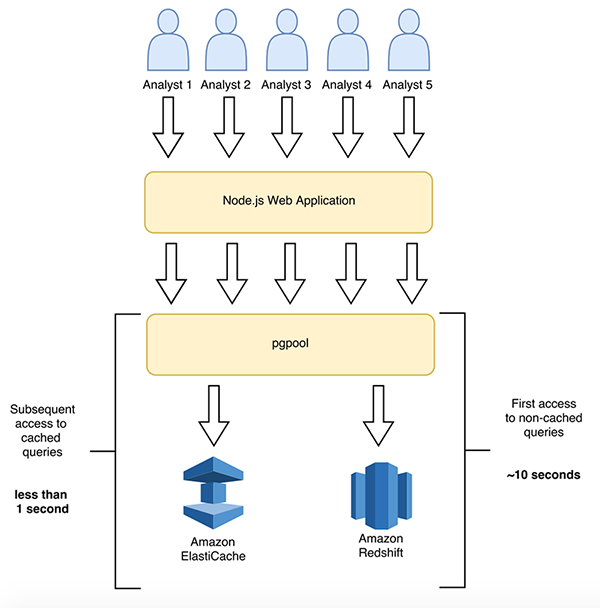
임상 분석 실험실에서, 6-10 명의 과학자 (유전 학자, 의사 및 생물 학자)로 이루어진 특정 팀이 특정 유전자 변형을 찾는 약 200 만 줄의 유전자 코드를 검색합니다. 변형된 유전자 옆의 유전자는 질병이나 장애를 확인할 수 있기 때문에 매우 흥미롭습니다.
과학자들은 동시에 하나의 DNA 샘플을 분석 한 다음, 회의를 통해 서로의 의견을 공유하여 결론을 내립니다.
Node.js 웹 애플리케이션에는 Amazon Redshift 에 대해 쿼리를 실행하는 로직이 포함되어 있습니다. Amazon Redshift에 연결된 웹 애플리케이션을 사용함에 있어서 과학자 팀은 약 10 초의 대기 시간을 경험했습니다. pgpool을 사용하도록 아키텍처를 수정한 후, 이 과학자들은 동일한 쿼리를 1 초 미만 (즉, 10 배 더 빨리)에 실행할 수 있었습니다.

pgpool 소개
Pgpool은 데이터베이스 클라이언트와 데이터베이스 서버 사이에 위치하는 소프트웨어입니다. 역방향 프록시(reverse proxy) 역할을 하며 클라이언트로부터 연결을 수신하여 데이터베이스 서버로 전달합니다. 원래 PostgreSQL 용으로 작성된 pgpool은 캐싱 외에도 연결 풀링(pooling), 복제(replication), 로드 밸런싱 및 초과 연결 큐와 같은 다른 흥미로운 기능을 가지고 있습니다. 이러한 기능을 자세히 찾아보지 않았지만 PostgreSQL과 Amazon Redshift 간의 호환성으로 인해 Amazon Redshift와 함께 사용할 수 있다고 생각됩니다.
Pgpool은 Amazon EC2 인스턴스 또는 사내 구축 환경에서 실행할 수 있습니다. 예를 들어, 개발 및 테스트를 위해 한개의 EC2 인스턴스가 있고 프로덕션 환경에 Elastic Load Balancing 및 Auto Scaling을 사용하는 EC2 인스턴스 그룹이 있을 수 있습니다.
임상 분석 실험실이라는 우리의 사용 예제에서는 psql (command line) 및 Node.js 애플리케이션을 사용하여 Amazon Redshift에 대한 쿼리를 실행했으며 예상대로 동작했습니다. 그러나 아키텍처를 변경하기 전에 PostgreSQL 클라이언트에서 pgpool을 테스트 할 것을 강력하게 권장합니다.
pgpool 캐싱 기능 살펴보기
pgpool 캐싱 기능은 기본적으로 비활성화 되어 있습니다. 다음 두 가지 방법으로 구성 할 수 있습니다.
- On-memory (shmem)
- 캐시를 활성화 하고, 설정을 전혀 변경하지 않았을 때 기본적으로 제공하는 방법입니다. Memcached 보다 약간 빠르며 구성 및 유지 관리가 더 쉽습니다. 반면에 고 가용성 시나리오에서는, 서버 당 쿼리를 캐싱하고 각 서버에 대해 적어도 한 번 캐싱할 쿼리를 처리하기 때문에 메모리와 일부 데이터베이스 처리를 낭비하는 경향이 있습니다. 예를 들어 4대로 구성된 pgpool 클러스터에서 20GB 캐시가 필요할 경우, 4대의xlarge 인스턴스를 준비하고 각 서버당 20GB메모리를 캐시를 위해 사용해야 합니다. 데이터베이스에 의해 처리되는 각 쿼리는 각 서버에 캐싱이 되어야 하기 때문에 최소한 4 번 캐싱 되어야 합니다.
- Memcached (memcached)
- 이 방법에서 캐시는 서버의 외부에서 유지 관리됩니다. 장점은 캐시 저장 영역 (Memcached)이 캐시 처리 영역(pgpool)에서 분리된다는 것입니다. 이는 쿼리가 Memcached에서만 처리되고 외부에서 캐싱되기 때문에 서버 메모리 및 데이터베이스 처리 시간을 낭비하지 않는다는 것을 의미합니다.
- Memcached를 구성할 수 있는 방법은 많지만, Amazon ElastiCache에서 제공하는Memcached를 함께 사용하는 것이 좋습니다. Amazon ElastiCache는 실패한 노드를 자동으로 감지하고 교체하는 기능을 제공하므로 직접 인프라를 관리하는 오버헤드가 줄어듭니다. 웹 사이트 및 애플리케이션 실행 시간을 지연시키는 데이터베이스의 과부화 위험을 완화시켜 안정적인 서비스를 가능하게 합니다.
pgpool을 이용한 쿼리 캐싱
다음의 흐름도는 쿼리 캐싱이 pgpool과 함께 작동하는 방법을 보여줍니다.
![]()

다음 다이어그램은 개발/테스트 환경을 위해 pgpool을 설치하고 구성하는 데 필요한 최소 아키텍처를 보여줍니다.


다음 다이어그램은 프로덕션 환경에 권장되는 최소 아키텍처를 보여줍니다.


선결 요건
이 단계는 AWS CLI (Command Line Interface)를 사용할 것입니다. Mac, Linux 또는 Microsoft Windows 시스템을 이용하여 구성해 보시려면AWS CLI가 설치되어 있어야합니다. 설치 방법은 AWS Command Line Interface 설치를 참조하십시오.
pgpool 설치 및 구성 단계
1. 변수 설정 :
IMAGEID=ami-c481fad3
KEYNAME=<set your key name here>
IMAGEID 변수는 미국 동부 (버지니아) 지역의 Amazon Linux AMI를 사용하도록 설정합니다.
KEYNAME 변수를 여러분이 사용할 EC2 Key pair 이름으로 설정하십시오. 이 Key pair는 미국 동부 (버지니아) 지역에서 생성 된 것이어야 합니다.
미국 동부 (버지니아) 이외의 지역을 사용하는 경우 IMAGEID 및 KEYNAME을 적절하게 수정하시기 바랍니다.
2. EC2 인스턴스 만들기 :
aws ec2 create-security-group --group-name PgPoolSecurityGroup --description "Security group to allow access to pgpool"
MYIP=$(curl eth0.me -s | awk '{print $1"/32"}')
aws ec2 authorize-security-group-ingress --group-name PgPoolSecurityGroup --protocol tcp --port 5432 --cidr $MYIP
aws ec2 authorize-security-group-ingress --group-name PgPoolSecurityGroup --protocol tcp --port 22 --cidr $MYIP
INSTANCEID=$(aws ec2 run-instances
--image-id $IMAGEID
--security-groups PgPoolSecurityGroup
--key-name $KEYNAME
--instance-type m3.medium
--query 'Instances[0].InstanceId'
| sed "s/"//g")
aws ec2 wait instance-status-ok --instance-ids $INSTANCEID
INSTANCEIP=$(aws ec2 describe-instances
--filters "Name=instance-id,Values=$INSTANCEID"
--query "Reservations[0].Instances[0].PublicIpAddress"
| sed "s/"//g")
3. Amazon ElastiCache 클러스터 생성 :
aws ec2 create-security-group --group-name MemcachedSecurityGroup --description "Security group to allow access to Memcached" aws ec2 authorize-security-group-ingress --group-name MemcachedSecurityGroup --protocol tcp --port 11211 --source-group PgPoolSecurityGroup MEMCACHEDSECURITYGROUPID=$(aws ec2 describe-security-groups --group-names MemcachedSecurityGroup --query 'SecurityGroups[0].GroupId' | sed "s/"//g") aws elasticache create-cache-cluster --cache-cluster-id PgPoolCache --cache-node-type cache.m3.medium --num-cache-nodes 1 --engine memcached --engine-version 1.4.5 --security-group-ids $MEMCACHEDSECURITYGROUPID aws elasticache wait cache-cluster-available --cache-cluster-id PgPoolCache
4. SSH를 통해 EC2 인스턴스 접근 후 필요한 패키지 설치 :
ssh -i <your pem file goes here> ec2-user@$INSTANCEIP sudo yum update -y sudo yum group install "Development Tools" -y sudo yum install postgresql-devel libmemcached libmemcached-devel -y
5. pgpool 소스코드 tarball 을 다운로드 :
curl -L -o pgpool-II-3.5.3.tar.gz http://www.pgpool.net/download.php?f=pgpool-II-3.5.3.tar.gz
6. 소스 추출 및 컴파일 :
tar xvzf pgpool-II-3.5.3.tar.gz cd pgpool-II-3.5.3 ./configure --with-memcached=/usr/include/libmemcached-1.0 make sudo make install
7. pgpool과 함께 제공되는 샘플 conf를 통해 pgpool.conf 생성
sudo cp /usr/local/etc/pgpool.conf.sample /usr/local/etc/pgpool.conf
8. pgpool.conf 편집 :
사용하기 편한 편집기(vi editor 등)를 사용하여 /usr/local/etc/pgpool.conf를 열고 다음 매개변수를 찾아서 설정하십시오 :
- Setlisten_addresses 를 *로 변경
- Setport 를 5432로 변경
- Setbackend_hostname0 을 여러분의 Amazon Redshift 클러스터 endpoint로 변경
- Setbackend_port0를 5439로 변경.
- Setmemory_cache_enabled를 on으로 변경
- Setmemqcache_method를 memcached로 변경
- Setmemqcache_memcached_host를 ElastiCache endpoint 주소로 변경
- Setmemqcache_memcached_port를 ElastiCache endpoint 포트로 변경
- Setlog_connections를 on으로 변경
- Setlog_per_node_statement를 on으로 변경
- Setpool_passwd를 “으로 변경
여러분의 설정 파일에서 수정된 매개변수는 아래와 같을 것입니다:
listen_addresses = '*' port = 5432 backend_hostname0 = '<your redshift endpoint goes here>' backend_port0 = 5439 memory_cache_enabled = on memqcache_method = 'memcached' memqcache_memcached_host = '<your memcached endpoint goes here>' memqcache_memcached_port = 11211 log_connections = on log_per_node_statement = on
9. 사용권한 설정 :
sudo mkdir /var/run/pgpool sudo chmod u+rw,g+rw,o+rw /var/run/pgpool sudo mkdir /var/log/pgpool sudo chmod u+rw,g+rw,o+rw /var/log/pgpool
10. pgpool 시작 :
pgpool -n
pgpool은 이미 포트 5432에서 수신 대기 중입니다.
2016-06-21 16:04:15: pid 18689: LOG: Setting up socket for 0.0.0.0:5432 2016-06-21 16:04:15: pid 18689: LOG: Setting up socket for :::5432 2016-06-21 16:04:15: pid 18689: LOG: pgpool-II successfully started. version 3.5.3 (ekieboshi)
11. 구성 테스트 :
이제 pgpool이 실행 중이므로 Amazon Redshift 클라이언트가 Amazon Redshift 클러스터 엔드포인트 대신 pgpool 엔드포인트를 가리키도록 구성합니다. 엔드포인트 주소를 얻으려면 콘솔이나 CLI를 사용하여 EC2 인스턴스의 공개 IP 주소를 확인하거나 $INSTANCEIP 변수에 저장된 값을 인쇄하여 확인 할 수 있습니다.
#psql –h <pgpool endpoint address> -p 5432 –U <redshift username>
쿼리를 처음 실행하면 pgpool 로그에 다음 정보가 표시됩니다 :
2016-06-21 17:36:33: pid 18689: LOG: DB node id: 0 backend pid: 25936 statement: select
s_acctbal,
s_name,
p_partkey,
p_mfgr,
s_address,
s_phone,
s_comment
from
part,
supplier,
partsupp,
nation,
region
where
p_partkey = ps_partkey
and s_suppkey = ps_suppkey
and p_size = 5
and p_type like '%TIN'
and s_nationkey = n_nationkey
and n_regionkey = r_regionkey
and r_name = 'AFRICA'
and ps_supplycost = (
select
min(ps_supplycost)
from
partsupp,
supplier,
nation,
region
where
p_partkey = ps_partkey,
and s_suppkey = ps_suppkey,
and s_nationkey = n_nationkey,
and n_regionkey = r_regionkey,
and r_name = 'AFRICA'
)
order by
s_acctbal desc,
n_name,
s_name,
p_partkey
limit 100;
로그의 첫 번째 줄은 쿼리가 Amazon Redshift 클러스터에서 직접 실행되는 것을 보여줍니다. 이는 캐시 미스입니다. 데이터베이스에 대해 쿼리를 실행하면 결과를 반환하는데 6814.595ms 가 걸렸습니다.
동일한 조건을 사용하여 이 쿼리를 다시 실행하면 로그에 다른 결과가 표시됩니다 :
2016-06-21 17:40:19: pid 18689: LOG: fetch from memory cache
2016-06-21 17:40:19: pid 18689: DETAIL: query result fetched from cache. statement:
select
s_acctbal,
s_name,
p_partkey,
p_mfgr,
s_address,
s_phone,
s_comment
from
part,
supplier,
partsupp,
nation,
region
where
p_partkey = ps_partkey
and s_suppkey = ps_suppkey
and p_size = 5
and p_type like '%TIN'
and s_nationkey = n_nationkey
and n_regionkey = r_regionkey
and r_name = 'AFRICA'
and ps_supplycost = (
select
min(ps_supplycost)
from
partsupp,
supplier,
nation,
region
where
p_partkey = ps_partkey,
and s_suppkey = ps_suppkey,
and s_nationkey = n_nationkey,
and n_regionkey = r_regionkey,
and r_name = 'AFRICA'
)
order by
s_acctbal desc,
n_name,
s_name,
p_partkey
limit 100;
로그의 처음 두 줄을 통해 원하는 결과가 캐시를 통해 검색되는 것을 알 수 있습니다. 이는 캐시 히트입니다. 차이점은 엄청납니다. 쿼리를 실행하는데 247.719ms 밖에 걸리지 않았습니다. 즉, 이전 시나리오보다 30 배 빠르게 실행됩니다.
pgpool 캐싱 동작 이해
Pgpool은 여러분의 SELECT 쿼리를 가져온 결과의 키로 사용합니다.
캐싱 동작과 무효화는 몇 가지 방법으로 구성 할 수 있습니다.
- 자동 무효화
- 기본적으로 memqcache_auto_cache_invalidation은 on으로 설정됩니다. Amazon Redshift의 테이블을 업데이트하면 pgpool의 캐시가 무효화됩니다.
- 만료
- memqcache_expire는 결과가 캐시에 남아 있어야하는 시간을 초로 정의합니다. 기본값은 0이며 무한대를 의미합니다.
- 블랙리스트와 화이트리스트
- white_memqcache_table_list
- 캐시되어야 하는 테이블의 목록을 쉼표로 구분하여 정의. 정규 표현식이 허용됩니다.
- black_memqcache_table_list
- 캐시해서는 안되는 테이블의 목록을 쉼표로 구분하여 정의. 정규 표현식이 허용됩니다.
- 캐시 무시
- / * NO QUERY CACHE * /
- white_memqcache_table_list
쿼리에 * / NO QUERY CACHE * / 주석을 지정하면 쿼리는 pgpool 캐시를 무시하고 데이터베이스에서 결과를 가져옵니다.
예를 들어, 만약 pgpool이 DNS 이름 확인 또는 라우팅 문제로 인해 캐시에 연결하지 못하면, 데이터베이스 엔드포인트로 직접 연결하고 캐시를 전혀 사용하지 않습니다.
결론
Amazon Redshift 및 Amazon ElastiCache와 함께 pgpool을 사용하여 캐싱 솔루션을 쉽게 구현할 수 있습니다. 이 솔루션은 최종 사용자 경험을 크게 향상시키고 클러스터의 부하를 크게 줄일 수 있습니다.
이 글은 pgpool과 이 캐싱 아키텍처가 여러분에게 어떤 도움이 되는지 보여주는 한 가지 간단한 예제 입니다. pgpool 캐싱 기능에 대한 자세한 내용은 pgpool 설명서의 이곳 및 이곳 을 참조하시기 바랍니다. 해피 쿼리 (물론 캐싱). 질문이나 제안이 있으시면 아래에 의견을 남겨주십시오.
본 글은 아마존웹서비스 코리아의 솔루션즈 아키텍트가 국내 고객을 위해 전해 드리는 AWS 활용 기술 팁을 보내드리는 코너로서, 이번 글은 양승도 솔루션즈 아키텍트께서 번역해주셨습니다.


Source: Amazon Redshift 쿼리 캐싱을 위해 pgpool 및 Amazon ElastiCache 사용