


Amazon S3 Batch Operations 기능 정식 출시 (서울 리전 포함)
S3 Batch Operations 정식 출시
Amazon S3 Batch Operations이라는 새로운 기능을 이용하면 수백, 수백만 또는 수십억 개의 S3 객체를 간단하고 간편한 방식으로 처리할 수 있습니다. 다른 버킷에 객체를 복사하거나, 태그 또는 ACL(액세스 제어 목록)을 설정하거나, Glacier에서 복원을 시작하거나, 각 객체별로 AWS Lambda 함수를 호출할 수 있습니다.
이 기능은 S3에서 기존에 지원되는 인벤토리 보고서(자세한 내용은 S3 스토리지 관리 기능 업데이트 게시물 참조)를 기반으로 하며, 보고서 또는 CSV 파일을 통해 배치 작업을 지원할 수 있습니다. 코드를 작성하거나, 서버 플릿을 설정하거나, 작업을 어떻게 분할하여 플릿에 분산할지를 고민하지 않아도 됩니다. 대신, 클릭 몇 번으로 몇 분 만에 작업을 생성하고 실행하면 S3가 대규모 병렬 프로세스를 통해 자동으로 작업을 처리합니다. 사용자는 S3 콘솔, S3 CLI 또는 S3 API를 사용하여 배치 작업을 생성하고 모니터링하고 관리할 수 있습니다.
간단한 용어 설명
본격적으로 시작하고 배치 작업을 생성하기 전에, 중요한 용어를 몇 가지 소개하고 설명하겠습니다.
- 버킷 – S3 버킷은 개수에 관계없이 S3 객체를 포함할 수 있으며, 필요한 경우 객체별로 버전을 관리할 수 있습니다.
- 인벤토리 보고서 – S3 인벤토리 보고서는 일별 또는 주별 버킷 인벤토리를 실행할 때마다 생성됩니다. 보고서는 버킷의 모든 객체를 포함하도록 구성하거나, 접두사로 구분된 일부에 대한 정보만 보여주도록 구성할 수 있습니다.
- 매니페스트 – 배치 작업에서 처리할 객체를 식별하는 목록(인벤토리 보고서 또는 CSV 형식의 파일)입니다.
- 배치 액션 – 매니페스트에 설명되어 있는 객체에 대해 실행할 액션입니다. 객체에 액션을 적용하면 S3 배치 태스크가 됩니다.
- IAM 역할 – 인벤토리 보고서의 객체를 읽고, 원하는 작업을 수행하고, 선택 사항인 완료 보고서를 작성할 권한을 S3에 부여하는 IAM 역할입니다. AWS Lambda 함수 호출 작업을 선택한 경우, 함수의 실행 역할을 통해 원하는 AWS 서비스 및 리소스에 액세스할 수 있는 권한이 부여되어야 합니다.
- 배치 작업 – 위에서 설명한 모든 항목을 나타냅니다. 각 작업에는 상태와 우선 순위가 설정됩니다. 우선 순위(숫자)가 높은 작업이 우선 순위가 낮은 작업보다 먼저 실행됩니다.
배치 작업 실행하기
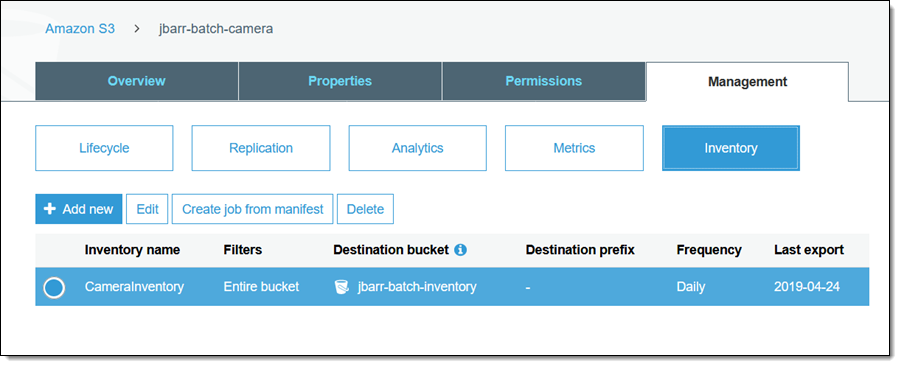
자, 이제 S3 콘솔을 사용하여 배치 작업을 생성하고 실행해보겠습니다. 이 블로그 게시물의 준비하면서 이번 주 초에 S3 버킷 중 하나(jbarr-batch-camera)에 대해 인벤토리 보고서를 활성화했습니다. 해당 보고서는 jbarr-batch-inventory로 라우팅됩니다.

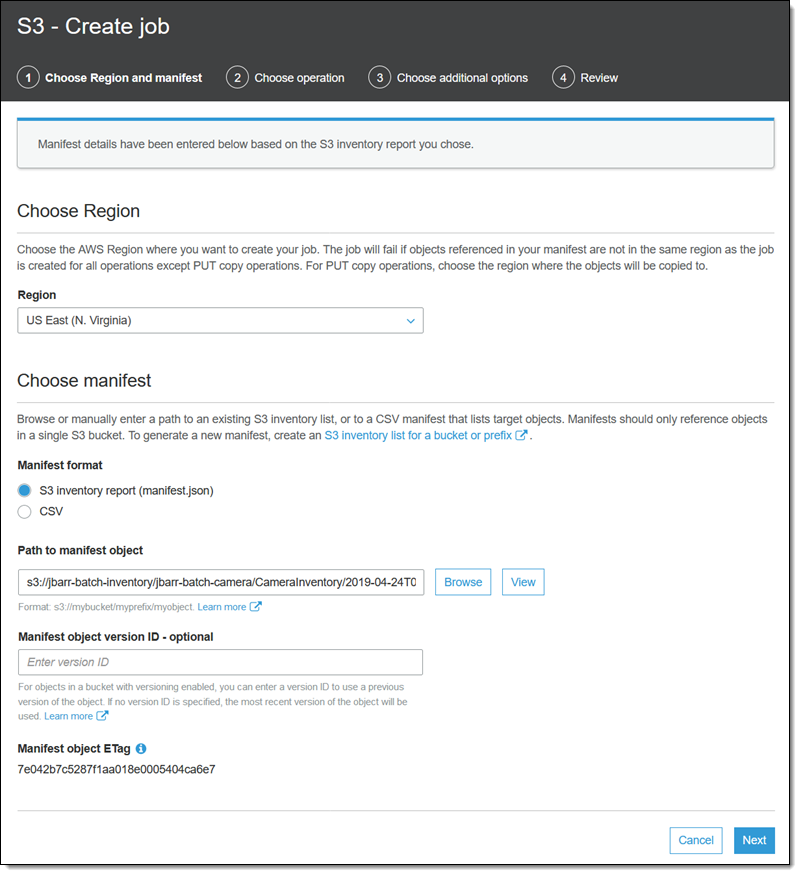
매니페스트에서 작업을 생성하여 시작합니다. 버킷 목록을 탐색하는 동안 [Batch operations(배치 작업)]을 선택해도 됩니다. 모든 관련 정보는 이미 입력되어 있지만, 원하는 경우 이전 버전의 매니페스트를 선택할 수 있습니다. 이 옵션은 버전 관리가 활성화된 버킷에 매니페스트가 저장되어 있는 경우에만 사용할 수 있습니다. [Next(다음)]를 클릭하여 계속 진행합니다.

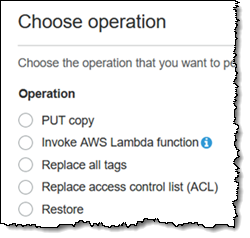
작업([Replace all tags(모든 태그 교체)])을 선택하고, 해당 작업에 해당하는 옵션(다른 작업은 잠시 후에 설명)을 입력한 후, [Next(다음)]를 클릭합니다.
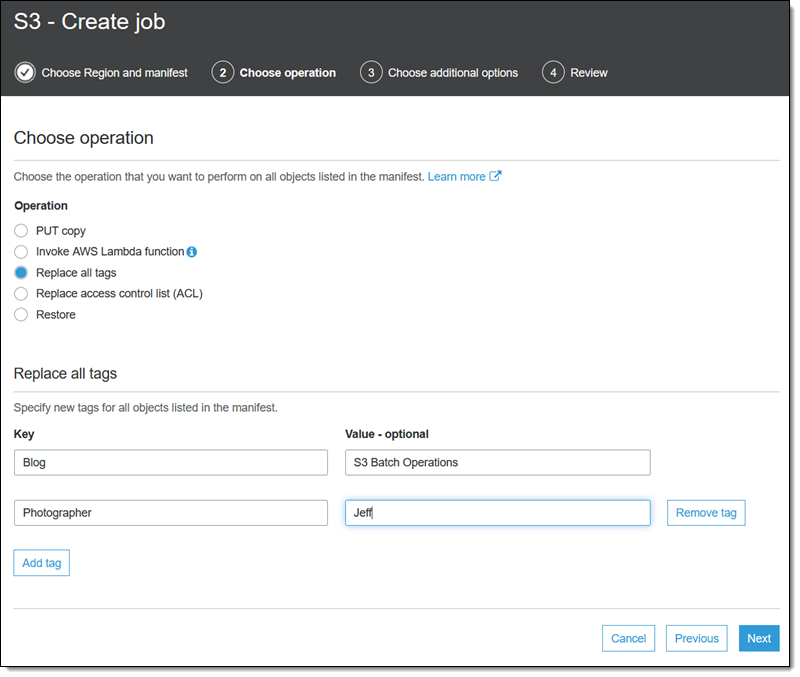

작업의 이름을 입력하고, 우선 순위를 설정하고, 모든 태스크에 대한 정보가 포함된 완료 보고서를 요청합니다. 그런 다음, 보고서에 해당하는 버킷을 선택하고, 필요한 권한을 부여하는 IAM 역할(콘솔에는 복사해 사용할 수 있는 역할 정책과 신뢰 정책도 표시됨)을 선택한 후, [Next(다음)]를 클릭합니다.
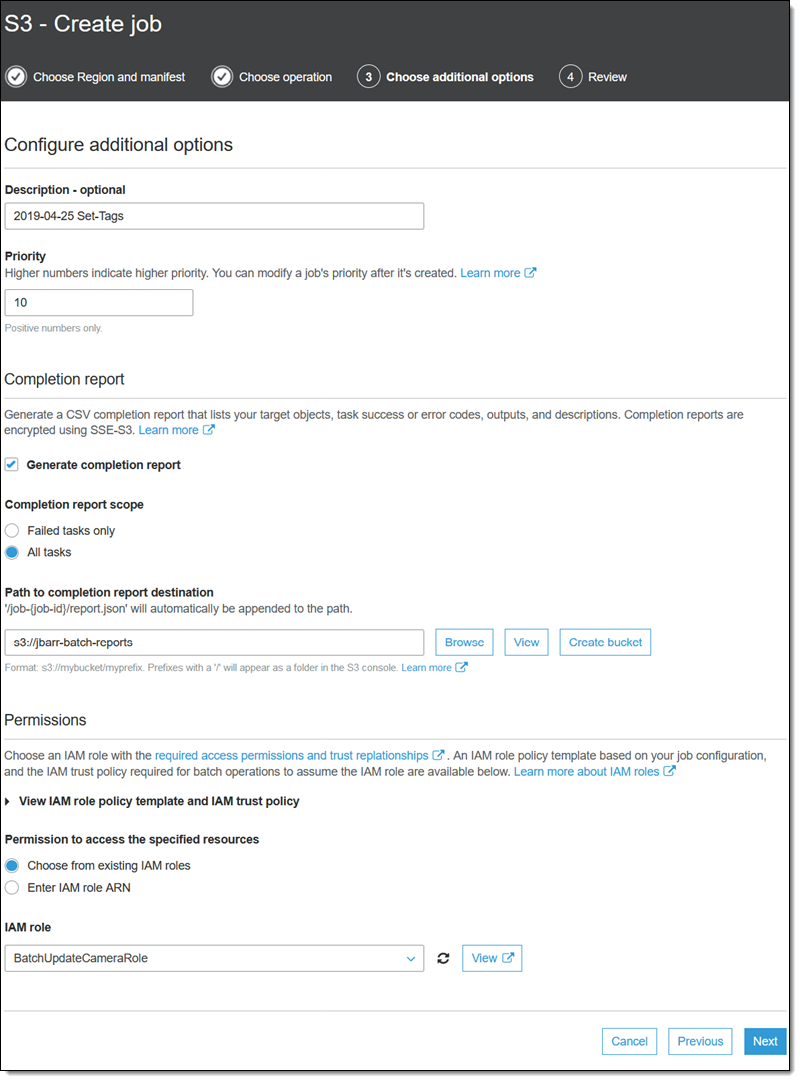

마지막으로, 작업을 검토한 후 [Create job(작업 생성)]을 클릭합니다.
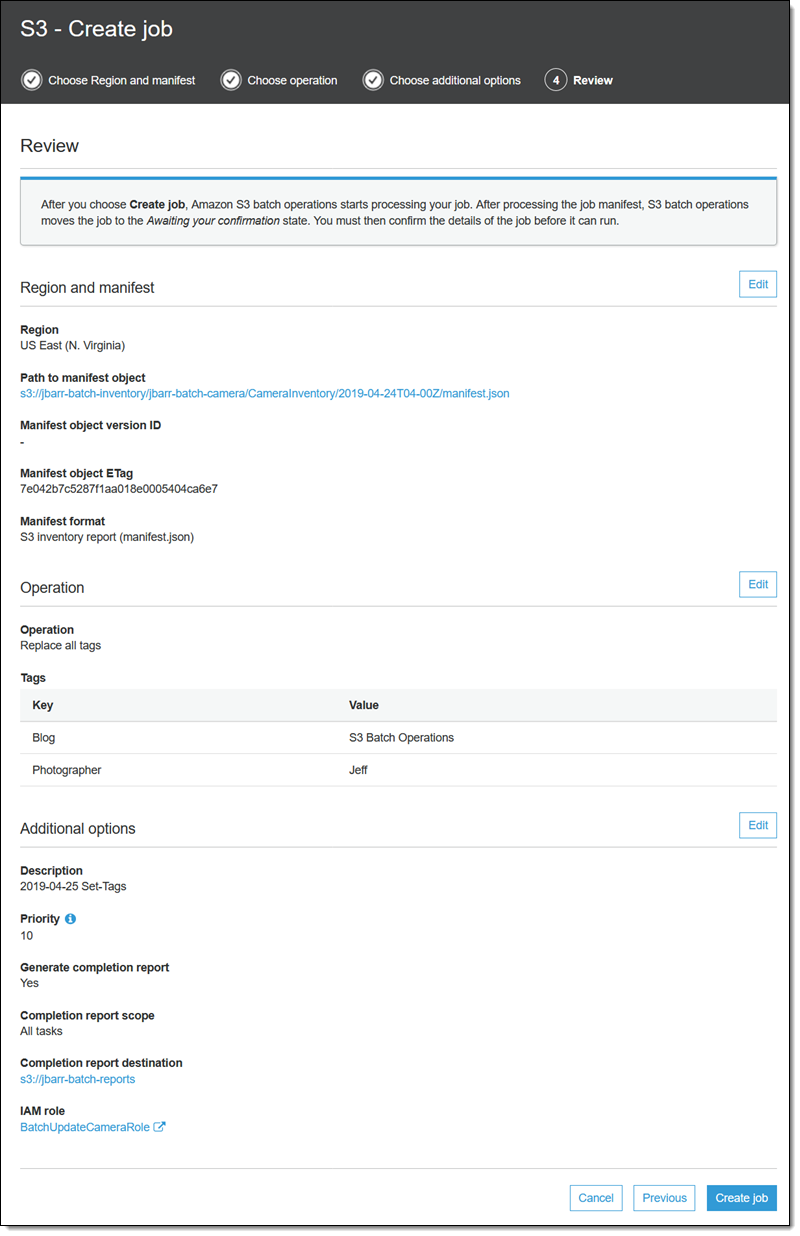

작업이 [Preparing(준비 중)] 상태로 바뀝니다. S3 Batch Operations이 매니페스트를 확인하고 다른 몇 가지 검증을 수행하며, 작업이 [Awaiting your confirmation(사용자 확인 대기 중)] 상태로 바뀝니다(콘솔을 사용하는 경우에만 해당). 해당 작업을 선택하고 [Confirm and run(확인 및 실행)]을 클릭합니다.

확인 정보(그림 없음)를 검토하여 수행할 작업을 확인하고, [Run job(작업 실행)]을 클릭합니다. 작업이 [Ready(준비)] 상태로 바뀌고, 곧 실행되기 시작합니다. 작업이 완료되면 [Complete(완료)] 상태로 바뀝니다.
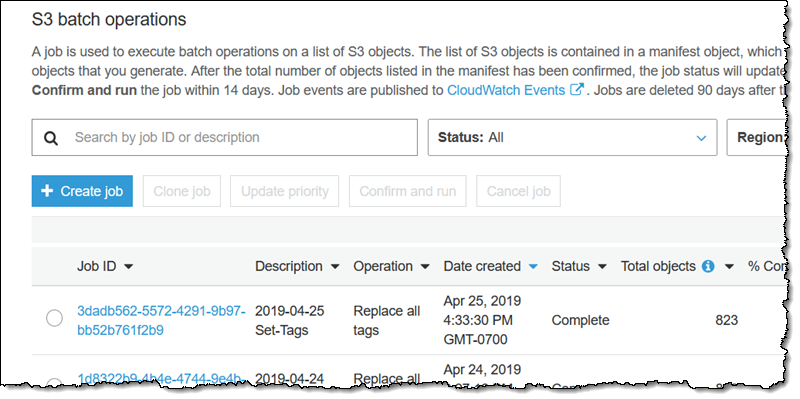

아주 많은 수의 객체를 처리하는 작업을 실행한다면, 이 페이지를 새로 고쳐 상태를 모니터링할 수 있습니다. 여기서 한 가지 유의할 점은 처음 1,000개의 객체가 처리되고 나면, S3 Batch Operations가 전반적인 실패율을 검사하고 모니터링하여 실패율이 50%를 넘으면 작업을 중지한다는 사실입니다.
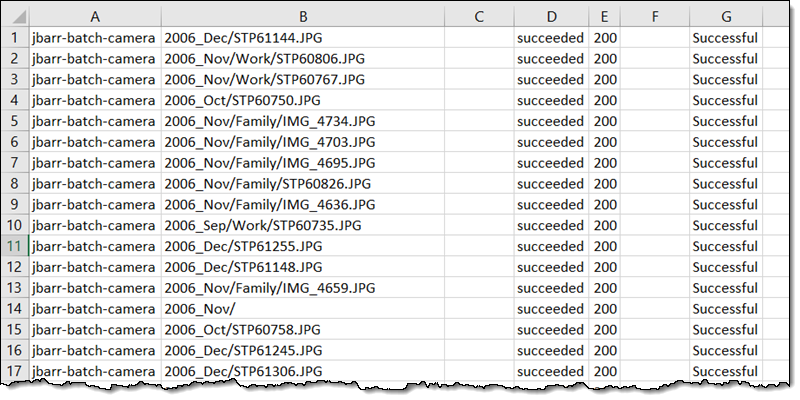
완료 보고서에는 다음과 같이 객체마다 한 줄씩 정보가 표시됩니다.

기타 기본 제공 배치 작업 진행하기
여기서 기타 기본 제공 배치 작업의 실행 과정을 모두 설명하기에는 지면이 부족합니다. 개요만 간단히 살펴보면 다음과 같습니다.
[PUT copy(PUT 복사)] 작업은 스토리지 클래스, 암호화, 액세스 제어 목록 및 메타데이터를 제어하면서 객체를 복사합니다.
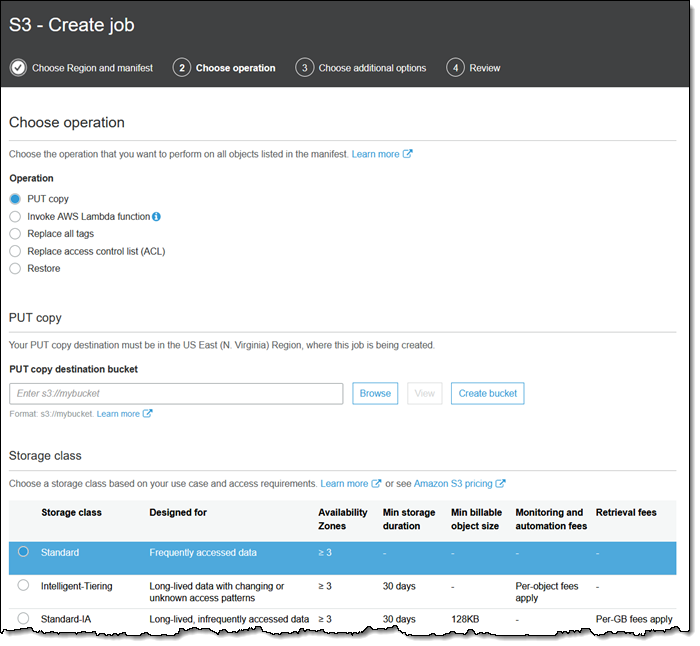

객체를 동일한 버킷에 복사하여 암호화 상태를 변경할 수 있습니다. 또한 객체를 다른 리전에 복사하거나, 다른 AWS 계정이 소유한 버킷에 복사할 수도 있습니다.
[Replace Access Control List (ACL)(ACL 교체)] 작업이 바로 그러한 작업을 실행합니다. 이 작업을 실행할 경우 부여되는 권한을 제어할 수 있습니다.
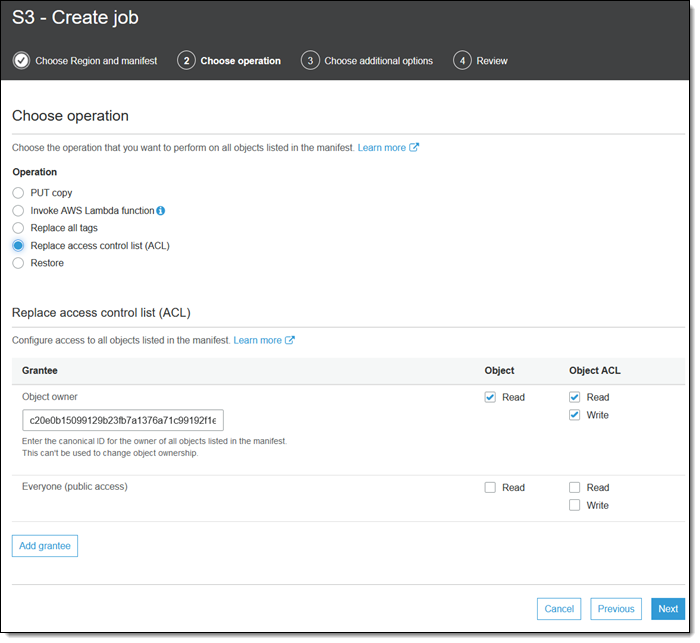

[Restore(복원)] 작업은 Glacier 또는 Glacier Deep Archive에서 객체 수준으로의 복원을 시작합니다.
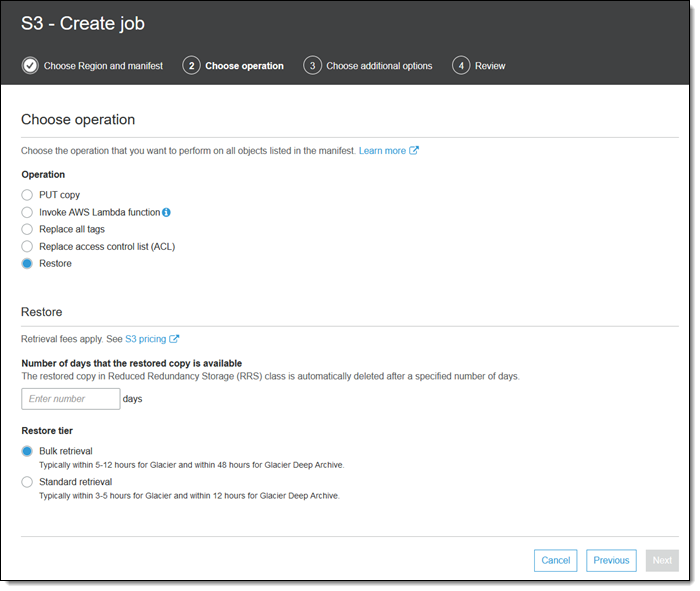

AWS Lambda 함수 호출하기
마지막으로, 가장 일반적인 옵션을 설명하겠습니다. 각 개체에 대해 Lambda 함수를 호출하면, Lambda 함수가 각 객체를 프로그래밍 방식으로 분석하여 조작합니다. 이 경우 함수의 실행 역할에서 S3 Batch Operations를 신뢰해야 합니다.
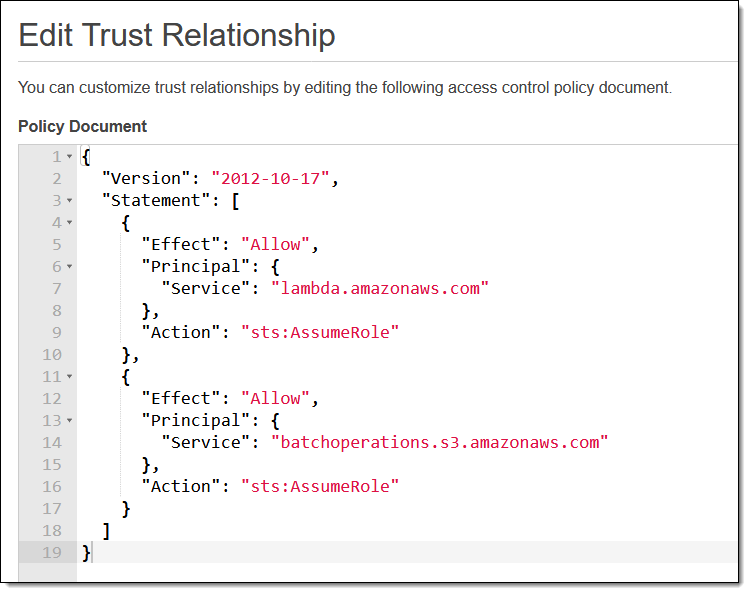

또한 배치 작업의 역할에서 Lambda 함수 호출을 허용해야 합니다.
필요한 역할이 설정되고 나면, 각 이미지에 대해 Amazon Rekognition이라는 간단한 함수를 생성할 수 있습니다.
함수가 생성되고 나면 작업 생성 시에 [Invoke AWS lambda function(AWS Lambda 함수 호출)] 작업을 선택하고, BatchProcessObject 함수를 선택합니다.
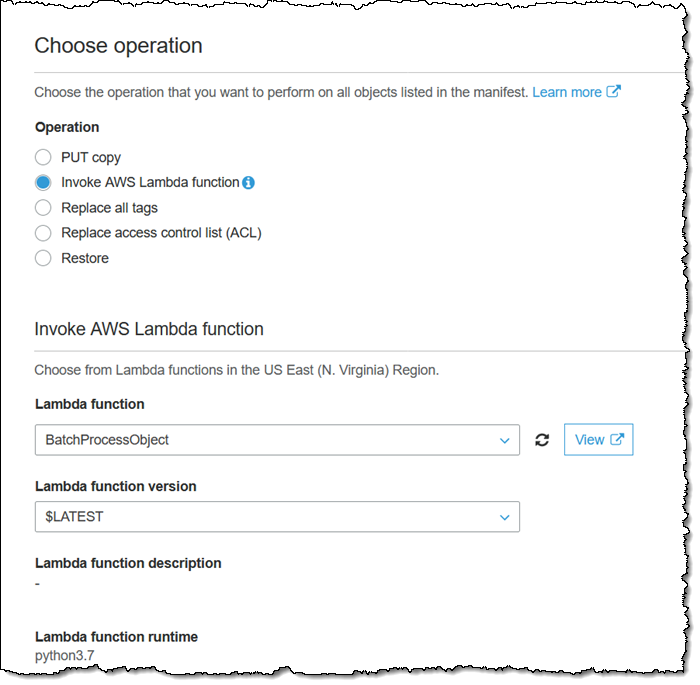

그런 다음 일반적인 방법으로 작업을 생성하고 확인합니다. 이 함수는 각 개체에 대해 호출되어, Lambda의 확장성을 활용하며 이 중간 크기의 작업을 1분 안에 실행 완료합니다.
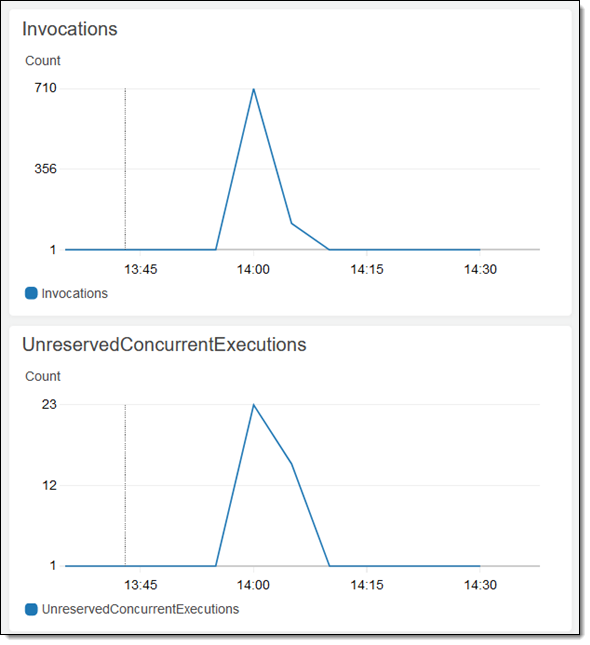

CloudWatch Logs 콘솔에서 “Detected(탐지됨)” 메시지를 확인할 수 있습니다.
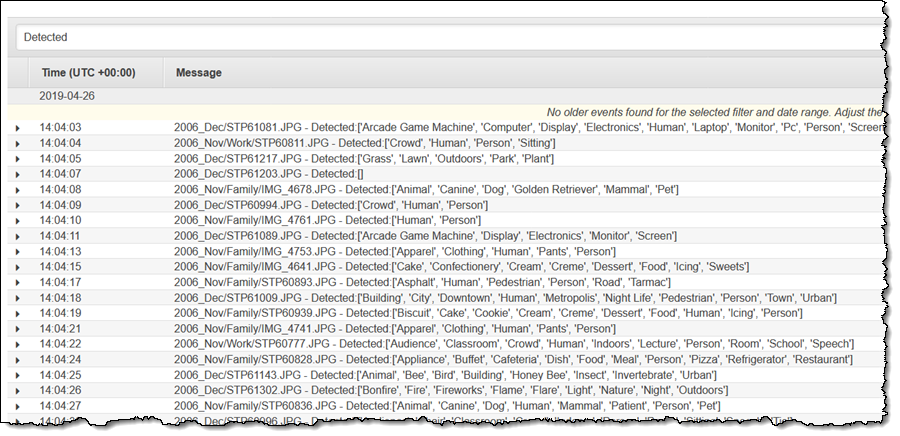

이 간단한 예에서 보듯이, 많은 수의 S3 객체에 대해 Lambda 함수를 손쉽게 실행하는 이러한 기능은 갖가지 흥미로운 애플리케이션을 개발할 수 있는 가능성을 열어줍니다.
알아 두실 점
여러분들이 S3 Batch Operations의 가능성을 발견해가는 다양한 사용 사례를 보고 듣게 되기를 바랍니다. 마치기 전에, 마지막으로 몇 가지만 짚어보겠습니다.
작업 복제 – 기존 작업을 복제하고, 파라미터를 세부적으로 조정한 후, 새 작업으로 다시 제출할 수 있습니다. 이 기능은 실패한 작업을 재실행하거나, 필요한 설정을 조정하는 데 이용할 수 있습니다.

프로그래밍 방식 작업 생성 – 인벤토리 보고서를 생성하는 버킷에 Lambda 함수를 연결하여 보고서가 생성될 때마다 새 배치 작업을 생성할 수 있습니다. 프로그래밍 방식으로 생성되는 작업은 사용자가 확인할 필요가 없으며, 즉시 실행될 수 있습니다.
CSV 객체 목록 – 버킷에 있는 객체 중 일부만 처리해야 하는데 공통적인 접두사로 해당 객체를 식별할 수 없는 경우, CSV 파일을 생성하여 작업을 실행하는 데 사용할 수 있습니다. 인벤토리 보고서에서 시작하고, 이름을 기준으로 객체를 필터링하거나 데이터베이스 또는 다른 참조와 대조하여 객체를 필터링할 수 있습니다. 예를 들어 Amazon Comprehend를 사용하여 저장된 모든 문서에 대해 정서 분석을 수행할 수 있습니다. 인벤토리 보고서를 처리하여 아직 분석되지 않은 문서를 찾아 CSV 파일에 추가할 수 있습니다.
작업 우선 순위 – 각 AWS 리전에서 한 번에 여러 개의 작업을 실행할 수 있습니다. 우선 순위가 높은 작업이 먼저 실행되며, 기존 작업을 일시적으로 중지할 수 있습니다. 활성 작업을 선택하고 [Update priority(우선 순위 업데이트)]를 클릭하여 실행 중에 변경할 수 있습니다.

다음은 S3 Batch Operations를 익히는 데 도움이 되는 몇 가지 리소스입니다.
설명서 – 작업 생성, Batch Operations 및 Batch Operations 작업 관리에 대해 알아볼 수 있습니다.
자습서 동영상 – S3 Batch Operations 동영상 자습서를 통해 작업을 생성하고, 작업을 관리 및 추적하고, 권한을 부여하는 방법을 배울 수 있습니다.
정식 출시
S3 Batch Operations는 현재 아시아 태평양(오사카)을 제외한 모든 상용 AWS 리전 (서울 리전 포함)에서 사용할 수 있습니다. 모든 AWS GovCloud(미국) 리전에서도 S3 Batch Operations를 사용할 수 있습니다.
— Jeff;