


Amazon S3 Glacier Flexible Retrieval 최대 85% 복원 속도 향상 – S3 일괄 작업을 통한 표준 검색 계층 지원

작년에 Amazon S3 Glacier가 출시 10주년을 맞았습니다. 저는 클라우드 콜드 스토리지의 선두 주자인 Amazon S3 Glacier의 10년간의 혁신에 대한 글을 쓴적이 있습니다.
Amazon S3 Glacier 스토리지 클래스는 가장 저렴한 비용으로 데이터를 최적으로 아카이브할 수 있는 안전하며 내구성 있는 장기 스토리지 옵션을 제공합니다. Amazon S3 Glacier 스토리지 클래스(Amazon S3 Glacier Instant Retrieval, Amazon S3 Glacier Flexible Retrieval 및 Amazon S3 Glacier Deep Archive)는 더 오래된 데이터용으로 특별히 설계되었으며, 밀리초에서 며칠에 이르는 검색 유연성을 제공할 뿐만 아니라 매월 테라바이트당 1 USD의 저렴한 비용으로 아카이브 데이터를 저장할 수 있는 기능을 제공합니다.
많은 고객이 데이터의 미래 가치 잠재력을 인식하여 데이터를 더 오랜 기간 동안 보관하고 있으며, 이미 아카이브 데이터의 하위 세트로 수익을 창출하고 있거나 향후 대량의 아카이브 데이터 세트를 사용할 계획이라고 말합니다. 최신 데이터 아카이빙은 콜드 데이터의 스토리지 비용을 최적화하는 것만이 아니라, 해당 데이터를 비즈니스에 적용해야 할 때 비즈니스 요구 사항에 따라 신속하게 액세스할 수 있도록 메커니즘을 설정하는 것입니다.
2022년, AWS 고객은 Amazon S3 Glacier에서 320억 개 이상의 객체를 복원했습니다. 고객은 미디어 트랜스코딩, 운영 백업 복원, 기계 학습(ML) 모델 학습 또는 기록 데이터 분석 시 아카이브된 객체를 신속하게 검색해야 합니다. S3 Glacier Instant Retrieval을 사용하는 고객은 단 몇 밀리초 만에 데이터에 액세스할 수 있는 한편, S3 Glacier Flexible Retrieval은 비용이 저렴하고 1~5분 내 신속 검색, 3~5시간 내 표준 검색, 5~12시간 내 무료 대량 검색의 세 가지 검색 옵션을 제공합니다. S3 Glacier Deep Archive는 최저 비용 스토리지 클래스로 표준 검색 옵션을 사용하여 12시간 내에 데이터를 검색하거나 대량 검색 옵션을 사용하여 48시간 내에 데이터를 검색할 수 있습니다.
2022년 11월, Amazon S3 Glacier는 S3 Glacier Flexible Retrieval과 S3 Glacier Deep Archive에서 대량의 아카이브 데이터를 검색할 때 추가 비용 없이 복원 처리량을 최대 10배 개선했습니다. Amazon S3 배치 작업을 사용하면 더 신속하게 요청을 자동으로 시작하여 페타바이트 규모의 데이터를 포함하는 수십억 개의 객체를 복원할 수 있습니다.
10년에 걸친 콜드 스토리지 혁신의 추세를 이어가기 위해 AWS는 오늘 추가 비용 없이 최대 85% 더 빠른 S3 Glacier Flexible Retrieval의 표준 검색 정식 출시를 발표합니다. S3 배치 작업을 사용할 때 더 빠른 데이터 복원이 표준 검색 계층에 자동으로 적용됩니다.
S3 배치 작업을 사용하면 검색할 객체의 매니페스트를 제공하고 검색 계층을 지정하여 아카이브된 데이터를 규모에 맞게 복원할 수 있습니다. 또한 이제 표준 검색 티어에서 복원의 객체 반환 속도가 일반적으로 3~5시간에서 몇 분으로 줄어 아카이브에서 데이터 복원 속도를 쉽게 높일 수 있습니다.
S3 배치 작업은 작업에 새로운 성능 최적화를 적용하여 전체 복원 처리량을 개선하기도 합니다. 따라서 데이터를 더 신속하게 복원하고 복원된 객체를 더 빨리 처리할 수 있습니다. 지속적 복원과 병행하여 복원된 데이터를 처리하면 데이터 워크플로를 가속화하고 비즈니스 요구에 신속하게 대응할 수 있습니다.
S3 Glacier Flexible Retrieval의 더 빠른 표준 검색 시작하기
이렇게 향상된 성능을 이용하여 아카이브된 데이터를 복원하려면 S3 배치 작업으로 S3 객체에서 대규모 및 소규모 배치 작업을 모두 수행합니다. S3 배치 작업은 사용자가 지정하는 S3 객체 목록에서 단일 작업을 수행할 수 있습니다. AWS Management Console, AWS Command Line Interface(AWS CLI), SDK 또는 REST API를 통해 S3 배치 작업을 사용할 수 있습니다.
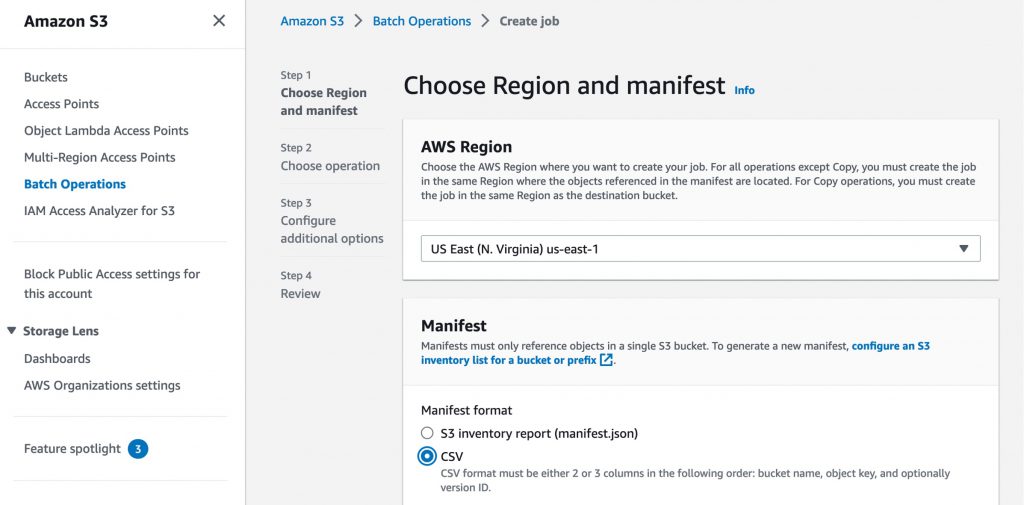
배치 작업을 생성하려면 Amazon S3 콘솔의 왼쪽 탐색 창에서 배치 작업을 선택하고 작업 생성을 선택합니다. 검색하려는 객체 키가 들어 있는 S3 객체 목록인 매니페스트 형식 중 하나를 선택할 수 있습니다. 매니페스트 형식이 CSV 파일인 경우 파일의 각 행에 버킷 이름, 객체 키 및 객체 버전(선택 사항)이 포함되어야 합니다.

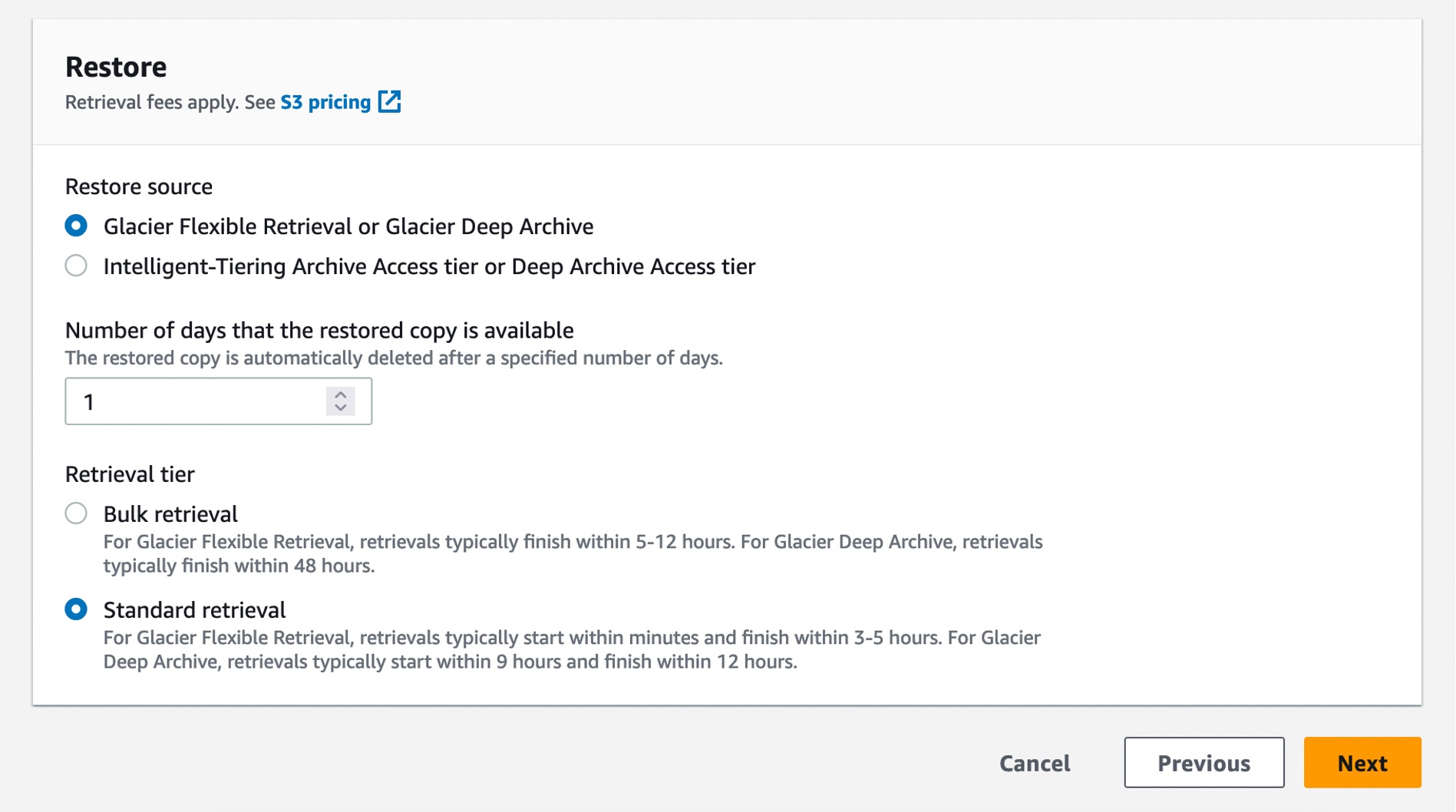
다음 단계에서는 매니페스트에 나열된 모든 객체에서 수행할 작업을 선택합니다. 복원 작업은 사용자가 지정하는 S3 객체 목록에서 아카이브된 객체에 대한 복원 요청을 시작합니다. 복원 작업을 사용하면 매니페스트에 지정된 모든 객체에 대한 복원 요청이 발생합니다.
S3 Glacier Flexible Retrieval 스토리지 클래스에서 표준 검색 티어를 사용하여 복원하면 자동으로 검색 속도가 빨라집니다.

AWS CLI를 사용하여 S3InitiateRestoreObject 작업으로 복원 작업을 생성할 수도 있습니다.
$aws s3control create-job
--region us-east-1
--account-id 123456789012
--operation '{"S3InitiateRestoreObject": { "ExpirationInDays": 1, "GlacierJobTier":"STANDARD"} }'
--report '{"Bucket":"arn:aws:s3:::reports-bucket ","Prefix":"batch-op-restore-job", "Format":" S3BatchOperations_CSV_20180820","Enabled":true,"ReportScope":"FailedTasksOnly"}'
--manifest '{"Spec":{"Format":"S3BatchOperations_CSV_20180820", "Fields":["Bucket","Key"]},"Location":{"ObjectArn":"arn:aws:s3:::inventory-bucket/inventory_for_restore.csv", "ETag":"<ETag>"}}'
--role-arn arn:aws:iam::123456789012:role/s3batch-role그리고 다음 CLI 명령을 실행하여 요청의 작업 제출 상태를 확인할 수 있습니다.
$ aws s3control describe-job
--region us-east-1
--account-id 123456789012
--job-id <JobID>
--query 'Job'.'ProgressSummary'작업 상태를 보고 업데이트하고, 알림과 로깅을 추가하고, 작업 실패를 추적하고, 완료 보고서를 생성할 수 있습니다. S3 배치 작업 활동은 AWS CloudTrail에 이벤트로 기록됩니다. 작업 이벤트를 추적하기 위해 Amazon EventBridge에서 사용자 지정 규칙을 생성하고 Amazon Simple Notification Service(SNS) 등의 선택한 대상 알림 리소스로 해당 이벤트를 전송할 수 있습니다.
S3 배치 작업을 생성할 때 모든 태스크 또는 실패한 태스크에 대한 완료 보고서를 요청할 수도 있습니다. 완료 보고서에는 객체 키 이름 및 버전, 상태, 오류 코드, 오류 설명 등 각 태스크에 대한 추가 정보가 포함됩니다.
자세한 내용은 Amazon S3 사용 설명서의 작업 상태 및 완료 보고서 추적을 참조하세요.
다음은 각각 크기가 100MB인 250개의 객체가 포함된 샘플 검색 작업의 결과입니다. 이전 복원 성능 선(오른쪽의 파란색 선)에서 볼 수 있듯이 이러한 복원은 표준 검색을 사용하여 대개 3~5시간 안에 끝납니다. 이제 S3 배치 작업에서 표준 검색을 사용하면 향상된 복원 성능 선(왼쪽의 주황색 선)에 표시된 것처럼 대개 몇 분 안에 작업이 시작되어 데이터 복원 시간이 최대 85% 단축됩니다.


자세한 내용은 AWS Storage Blog의 Restoring archived objects at scale from the Amazon S3 Glacier storage classes와 Amazon S3 사용 설명서의 아카이브된 객체 복원을 참조하세요.
정식 출시
이제 AWS GovCloud(미국) 리전과 중국 리전을 포함한 모든 AWS 리전에서 Amazon S3 Glacier Flexible Retrieval의 더 빠른 표준 검색을 사용할 수 있습니다. 이러한 성능 향상은 추가 비용 없이 제공됩니다. S3 배치 작업과 데이터 검색에 대한 요금은 부과됩니다. 자세한 내용은 S3 요금 페이지를 참조하세요.


자세한 내용은 S3 Glacier storage classes 페이지와 시작 안내서를 참조하고 평소 이용하는 AWS Support 담당자를 통해 또는 AWS re:Post for S3 Glacier로 피드백을 보내주세요.
이 새로운 기능을 사용하기 시작하게 되어 매우 기쁘며, 아카이브된 데이터로 비즈니스를 재창조하는 더 많은 방법에 대해 들을 수 있기를 기대합니다.
– Channy
Source: Amazon S3 Glacier Flexible Retrieval 최대 85% 복원 속도 향상 – S3 일괄 작업을 통한 표준 검색 계층 지원