Amazon SageMaker와 Deep Graph Library를 이용한 이종 네트워크에서 사기 탐지하기
KENNETH
Amazon SageMaker와 Deep Graph Library를 이용한 이종 네트워크에서 사기 탐지하기
이상 행위자나 의심스러운 계정으로 인해서 매년 수 십조 원의 손실이 발생하고 있습니다. 시스템에서 악의적인 행동들이 일어나는 것을 방지하기 위해서 많은 기업들은 규칙 기반 필터를 적용하고 있지만, 이 필터들은 다루기 힘들기도 하고 악의적인 행동 전체를 잡아내지 못합니다.
하지만 그래프 기술과 같은 솔루션들은 이상 행위자나 악의적인 사용자를 탐지하는데 아주 적합합니다. 이상 행위자는 규칙 기반의 시스템이나 단순한 특징 기반의 모델을 속이기 위해서 그들이 사용하는 방법을 진화시키지만, 그래프 구조나 사용자와 다른 참여자들 사이의 거래나 상호 활동 로그에 담긴 관계를 속이는 것은 어렵습니다. 그래프 뉴럴 네트워크(GNN)은 사용자나 거래의 속성과 함께 그래프 구조로부터 정보를 조합해서 이상 행위자나 이벤트를 적법한 행위나 이벤트로부터 구별할 수 있는 표현을 배웁니다.
우리는 Amazon SageMaker를 이용한 데이터 전처리와 모델 학습을 다루겠습니다. GNN 모델을 학습하기 위해서, 우선 거래 테이블 또는 접근 로그로부터 이종 그래프(heterogeneous graph)를 만들어야 합니다. 이종 그래프는 서로 다른 종류의 노드와 에지를 갖는 그래프입니다. 노드가 사용자나 거래를 대표하는 경우, 노드는 다른 사용자와 별개의 관계를 여러 개 가질 수 있습니다. 예를 들면, 디바이스 구별자, 기관, 어플리케이션, IP 주소와 같은 것들이 될 수 있습니다.
이 그래프 케이스에 알맞은 예들은 다음과 같습니다.
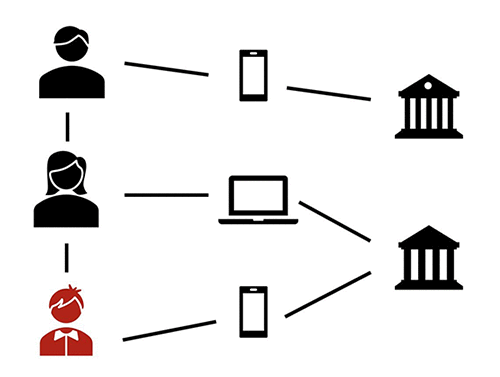
사용자가 다른 사용자나 특정 금융기관 또는 어플리케이션들과 거래하는 금융 네트워크
사용자가 다른 사용자와 서로 작용하면서 다른 게임 또는 디바이스들과도 작용하는 게임 네트워크
사용자가 다른 사용자와 여러 종류의 연결을 갖는 소셜 네트워크
아래 다이어그램은 이종 금융 거래 네트워크의 예시입니다.
GNN은 인구 통계 정보와 같은 사용자 특성이나 활동 빈도와 같은 거래 특성을 활용할 수 있습니다. 즉, 노드와 에지의 메타데이터에 대한 특성를 사용해서 이종 그래프를 더 풍부하게 만들 수 있습니다. 관련된 특징과 함께 이종 그래프의 노드와 관계를 구성한 후, 그래프 구조와 함께 노드 또는 에지의 특성을 사용해서 노드를 이상 또는 정상으로 구분하는 모델을 학습시킬 수 있습니다. 모델 학습은 준지도 학습(semi-supervised learning)으로 구성할 수 있는데, 그래프의 일부 노드만 이상인지 정상인지 레이블이 있는 데이터를 사용한 학습을 말합니다. 이 레이블이 있는 그래프의 일부를 GNN의 파라미터들을 학습시키는 학습 시그널로 사용합니다. 학습된 GNN 모델은 그래프의 나머지 레이블이 되지 않은 노드들의 레이블을 예측할 수 있게 됩니다.
아키텍처 소개
전체 솔루션 아키텍처는 Amazon SageMaker를 사용해서 데이터 처리 및 학습을 수행하도록 구성합니다. Amazon Simple Storage Service (Amazon S3)의 put 이벤트가 발생하면 AWS Lambda 함수를 통해서 Amazon SageMaker 작업을 자동으로 수행할 수 있도록 구성합니다. 또는 Amazon SageMaker 예제 노트북의 셀을 하나씩 실행하는 방법도 있습니다. 아래 다이어그램의 아키텍처를 시각화한 것입니다.
여기서 우리는 예제 데이터셋을 어떻게 전처리하는지, 그리고 이종 그래프를 만들기 위해서 관계를 어떻게 식별해야 하는지 살펴봅니다.
데이터셋
이 예제에서 우리는 IEEE-CIS fraud dataset 를 사용해서 모델링 접근법에 대한 벤치마킹을 수행하겠습니다. 이 데이터셋은 익명화 처리된 것으로 사용자간의 50만건의 거래를 담고 있습니다. 이 데이터셋은 두 가지 주요 테이블이 있습니다.
거래 테이블 – 거래에 대한 정보와 사용자 사이의 상호 활동에 대한 정보를 담고 있습니다.
식별 테이블 – 거래를 수행한 사용자에 대한 접근 로그, 디바이스, 네트워크 정보에 대한 내용을 담고 있습니다.
이 거래들 중에서 레이블이 있는 일부를 지도학습 시그널로 사용해서 모델을 학습시킬 수 있습니다. 테스트 데이터셋의 거래는 학습 과정에서 모두 마스킹 처리를 하고, 마스크 처리된 거래가 이상 거래인지 정상 거래인지를 예측하는 것이 과제입니다.
아래 코드는 데이터를 구한 후, 이를 Amazon SageMaker가 전처리와 학습에 사용할 수 있도록 S3 버킷에 올리는 일을 합니다. (전처리와 학습은 Jupyter 노트북 셀에서 수행)
# Replace with an S3 location or local path to point to your own dataset
raw_data_location = 's3://sagemaker-solutions-us-west-2/Fraud-detection-in-financial-networks/data'
bucket = 'SAGEMAKER_S3_BUCKET'
prefix = 'dgl'
input_data = 's3://{}/{}/raw-data'.format(bucket, prefix)
!aws s3 cp --recursive $raw_data_location $input_data
# Set S3 locations to store processed data for training and post-training results and artifacts respectively
train_data = 's3://{}/{}/processed-data'.format(bucket, prefix)
train_output = 's3://{}/{}/output'.format(bucket, prefix)
이상 거래자들의 행동을 가리기 위한 노력에도 불구하고, 이상 또는 악의적인 행동들은 그래프 구조에서 높은 아웃-디그리(out-degree) 또는 행동 집계(activity aggregation)과 같은 증거로 종종 남습니다. 다음 절들에서는 이런 패턴들을 활용한 이상 예측 GNN 모델을 만들기 위한, 특성 추출과 그래프 생성을 어떻게 해야하는지 설명하겠습니다.
특성 추출(Feature Extraction)
특성 추출은 카테고리 특성들에 대한 수치화와 수치 컬럼들에 대한 몇 가지 변환으로 이뤄집니다. 예를 들어, 상대적인 거래의 크기를 구분하기 위해서 거래량에 로그를 적용한 변화를 하거나, 카테고리 속성들은 원-핫-벡터를 사용한 수치 형태로 변경할 수 있습니다. 각 거래는 이전 거래와 시간 차이, 이름 및 주소 일치, 그리고 수량에 대한 일치 등의 정보를 담고 있는 거래 테이블로부터 얻은 속성을 특성 벡터에 담고 있습니다.
그래프 구성하기
전체 상호작용 그래프를 만들기 위해서, 데이터의 관계 정보를 각 관계 종류별 에지 리스트로 나눕니다. 각 에지 리스트는 거래 노드와 다른 엔터티 종류들 사이의 이분 그래프(bipartite graph)가 됩니다. 엔터티 종류들은 거래에 대한 속성을 구분하는 정보들입니다. 예를 들어, 거래에 사용된 카드의 종류(신용카드 또는 직불카드), 거래에 사용된 디바이스의 IP 주소 또는 사용된 디바이스의 ID나 운영체계와 같은 것이 엔터티의 종류들이 될 수 있습니다. 그래프 구성에 사용되는 엔터티 종류는 식별 테이블과 거래 테이블의 일부 속성(신용 카드 정보 또는 이메일 도메인)에 대한 모든 속성을 포함합니다. 이종 그래프는 각 관계 타입에 대한 에지 목록과 노드들의 특성 행렬을 사용해서 만들어집니다.
Amazon SageMaker Processing 사용하기
Amazon SageMaker Processing을 사용해서 데이터 전처리 및 특성 추출 단계를 수행합니다. Amazon SageMaker Processing은 Amazon SageMaker의 기능으로 완전 관리형 인프라를 활용해서 전처리 및 후처리 워크로드를 수행할 수 있도록 해줍니다. 상세한 내용은 Process Data and Evaluate Models를 참조해주세요.
우선 Amazon SageMaker Processing 작업이 사용할 컨테이너를 정의합니다. 이 컨테이너는 데이터 전처리 스크립트가 필요한 모든 관련 패키지를 담고 있어야 합니다. 이 예제는 pandas 라이브러리만 사용해서 데이터를 전처리를 하기 때문에, 최소한의 라이브러리가 포함된 Dockerfile을 사용해서 컨테이너를 아래 코드와 같이 정의합니다.
FROM python:3.7-slim-buster
RUN pip3 install pandas==0.24.2
ENV PYTHONUNBUFFERED=TRUE
ENTRYPOINT ["python3"]
데이터 전처리 컨테이너가 준비된 후, 그 전처리 컨테이너를 이용하는 Processing 작업을 구성할 Amazon SageMaker ScriptProcessor 를 만듭니다. 이 ScriptProcessor 를 통해서 Python script가 수행되는데, 이 스크립트는 컨테이너로 정의된 환경에서 수행될 데이터 전처리가 구현되어 있습니다. Python 스크립트가 성공적으로 수행이 완료되면 Processing 작업도 종료되며, 전처리가 완료된 데이터는 다시 Amazon S3로 저장됩니다. 이 과정들은 완전히 Amazon SageMaker에 의해서 관리됩니다. ScriptProcessor 를 수행할 때, 데이터 전처리 스크립트에 명령 변수들을 전달 할 수 있는 옵션이 있습니다. 거래 테이블에서 어떤 컬럼이 식별 컬럼인지, 어떤 컬럼들이 카테고리 특성들인지를 설정합니다. 모든 컬럼들은 수치 특성으로 간주됩니다. 아래 코드를 참조하세요.
관계 에지리스트 파일들은 학습에 필요한 이종 그래프를 만드는 데 사용되는 서로 다른 에지 종류들을 담고 있습니다. features.csv 파일은 거래 노드의 변경이 완료된 특성들을 가지고 있고, tags.csv 파일은 지도 학습의 시그널로 사용할 노드에 대한 레이블을 담고 있습니다. test.csv 파일은 모델의 성능을 평가하기 위한 테스트 데이터셋으로 사용할 TransactionID 데이터를 담고 있습니다. 이 노드들에 대한 레이블은 학습 과정에서 가려집니다.
GNN 모델 학습하기
자, 이제 Deep Graph Library(DGL)를 사용해서 그래프와 GNN 모델을 정의할 수 있고, Amazon SageMaker를 사용해서 GNN 학습을 위한 인프라를 만들 수 있습니다. 이 문제는 Relational Graph Convolutional 뉴럴 네트워크 모델을 사용해서 이종 그래프의 각 노드의 임베딩을 학습하고, 완전 연결 레이어를 사용해서 최종 노드 분류 모델을 학습합니다.
하이퍼파라미터들
GNN을 학습하기 위해서 몇 가지 하이퍼파라미터들을 정의하겠습니다. 하이퍼파라미터에는 만들 그래프 종류, 사용할 모델의 클래스, 네트워크 구조, 최적화 알고리즘과 최적화 파라미터들이 있습니다. 아래 코드를 참고하세요.
위 코드에서 몇 가지 하이퍼파라미터들을 설정하고 있는데, 모든 하이퍼파라미터와 기본 값들은 Github 리포지토리의 estimator_fns.py 를 참고히세요.
Amazon SageMaker를 이용한 모델 학습
하이퍼파라미터들을 정의하면, 학습 작업을 시작할 수 있습니다. 학습 작업은 GNN을 정의하고 학습하기 위해서 MXNet을 백앤드로 DGL을 사용합니다. Amazon SageMaker는 딥러닝 프레임워크 환경이 미리 설정되어 있는 프레임워크 estimator들을 사용해서 GNN 모델을 쉽게 학습할 수 있도록 만들어 줍니다. Amazon SageMaker에서 DGL을 사용한 GNN 학습에 대한 더 많은 정보는 Train a Deep Graph Network를 참조하세요.
이제 Amazon SageMaker MXNet estimator를 생성합니다. 이 때, 모델 학습 스크립트, 하이퍼파라미터, 학습에 사용할 인스턴스 개수를 지정합니다. estimator 객체에 fit 을 호출하면서, Amazon S3에 저장되어 있는 학습 데이터 위치를 전달합니다.
GNN 학습이 완료되면, 모델은 적법한 거래와 이상 거래를 구분할 수 있게 됩니다. 학습 작업은 pred.csv 파일을 생성하는데, 이 파일은 test.csv 파일에 있는 거래에 대한 예측 결과를 담고 있습니다. ROC 커브는 true positive 비율과 false positive 비율의 관계를 여러 임계치에 대해서 보여주며, AUC(Area Under the Curve)는 평가 지표로 사용할 수 있습니다. 아래 그래프는 우리가 학습시킨 GNN 모델이 완전 연결 피드 포워드 네트워크와 gradient boosted tree 보다 성능이 우수한 것을 보여주고 있습니다. 이 두 모델은 그래프 구조에 대한 이점을 살리지 못하고, 특성들만 사용합니다.
결론
이 글에서 우리는 사용자 거래 및 활동 데이터를 사용해서 이종 그래프를 만드는 방법과 그래프와 수집된 다른 정보를 사용해서 거래가 이상 거래인지 예측하는 모델을 학습하는 법을 살펴봤습니다. 또한 이 과제에 대해서 높은 성능을 보여주는 GNN을 정의하고 학습하는데 있어서 DGL과 Amazon SageMaker를 어떻게 활용할 수 있는지 살펴보기도 했습니다. 이 프로젝트와 다른 GNN 모델들에 대한 전체 구현은 GitHub repo에서 찾을 수 있습니다.
추가적으로 우리는 Amazon SageMaker Processing을 사용해서 원본 거래 로그에서 의미 있는 특성과 관계를 추출하는 데이터 처리를 어떻게 수행하는지도 살펴봤습니다. 여러분은 제공된 CloudFormation 템플릿을 사용해서 배포하고, 여러분의 데이터를 이용하면, 악의적인 사용자나 이상 거래를 탐지하는 프로젝트를 바로 시작할 수 있습니다.
Soji Adeshina는 AWS 고객을위한 딥 러닝 기반 솔루션 개발을 담당하는 기계 학습 개발자입니다. 현재 금융 서비스 및 광고 응용 프로그램을 사용하여 그래프 학습을하고 있지만 컴퓨터 비전 및 추천 시스템에 대한 배경 지식도 보유하고 있습니다.