


Amazon SageMaker의 MXNet 추론 컨테이너를 활용한 KoGPT2 모델 배포하기

기계 학습 기반 자연어 처리를 위한 다양한 학습 모델이 나오고 있는 가운데, 다국어로 학습된 BERT의 한국어 성능 한계를 극복하기 위해 SK텔레콤의 T-Brain에서는 KoBERT라는 한국형 사전 훈련 모델을 개발하였습니다.
위키피디아나 뉴스 등에서 수집한 수백만 개의 한국어 문장으로 이루어진 대규모 말뭉치(corpus)를 기반으로 학습하였으며, 한국어의 불규칙한 언어 변화의 특성을 반영하기 위해 데이터 기반 토큰화(Tokenization) 기법을 적용하여 Apache MXNet을 비롯하여 PyTorch, ONNX 등 다양한 딥러닝 API를 지원합니다.
또한, 기존 KoBERT 의 뒤를 이어 OpenAI의 대용량 언어 모델인 GPT2를 한글 데이터로 학습시킨 KoGPT2 모델을 구축했습니다. 이를 위해 SK텔레콤 Conv.AI팀이 대규모 언어 모델 학습 로직을 구현하고, Amazon Machine Learning Solutions Lab이 대규모 분산 학습 인프라 구성 및 최적화, GluonNLP팀에서 학습 성능 개선에 협업으로 참여하였습니다.
이를 통해 기존 학습 과정 대비 학습 효율이 2배 이상 향상되었으며, 한국어 대화 데이터에 해당 모델을 적용했을 때 대화의 자연스러움이 크게 향상되었습니다.
KoGPT2와 같이 확장성 높은 대용량 언어 학습 모델을 배포하기 위해서는 Amazon SageMaker에서 제공하는 MXNet 추론 컨테이너를 활용하는 것이 유리합니다. 이 글에서는 KoGPT2 및 관련 패키지를 설치하여 맞춤형 컨테이너 이미지를 만든 후, 이를 Amazon SageMaker로 모델을 배포하는 것을 살펴보겠습니다.
1. 추론 컨테이너 이미지 생성하기
우선 Amazon SageMaker의 MXNet 컨테이너를 복제합니다. 도커(Docker)가 설치되어 있는 곳에서 수행해야 하며, Amazon EC2 인스턴스 또는 Amazon SageMaker의 노트북 인스턴스를 사용하는 것을 추천합니다.
$ git clone https://github.com/aws/sagemaker-mxnet-serving-container.git
$ cd sagemaker-mxnet-serving-container다음으로는 Dockerfile을 수정합니다. GPU 및 Apache MXNet 1.6.0, Python 3.6를 지원하는 컨테이너 이미지를 만들기 위해서 ./docker/1.6.0/py3/Dockerfile.gpu 파일을 수정할 것입니다. Apache MXNet 및 관련 패키지를 설치하는 문장 다음에 KoGPT2를 설치하는 명령행들을 추가합니다. 아래 예제에서 마지막 7 줄이 추가해야 할 내용입니다. (CPU 버전의 컨테이너 이미지를 만들고 싶다면 ./docker/1.6.0/py3/Dockerfile.cpu 파일을 수정합니다.)
RUN ${PIP} install --no-cache-dir
${MX_URL}
git+git://github.com/dmlc/gluon-nlp.git@v0.9.0
gluoncv==0.6.0
mxnet-model-server==$MMS_VERSION
keras-mxnet==2.2.4.1
numpy==1.17.4
onnx==1.4.1
"sagemaker-mxnet-inferenc>2"
# For KoGPT2 installation
RUN git clone https://github.com/SKT-AI/KoGPT2.git
&& cd KoGPT2
&& ${PIP} install -r requirements.txt
&& ${PIP} install .
RUN ${PIP} uninstall -y mxnet ${MX_URL}
RUN ${PIP} install ${MX_URL}이제 컨테이너 이미지를 만들어 보겠습니다. $ docker build 명령을 수행하기 전에, 필요한 파일들을 ./docker/1.6.0/py3 디렉토리에 복사합니다. 여기서는 컨테이너 이름과 태그로preprod-mxnet-serving:1.6.0-gpu-py3를 사용합니다.
$ cp -r docker/artifacts/* docker/1.6.0/py3
$ cd docker/1.6.0/py3
$ docker build -t preprod-mxnet-serving:1.6.0-gpu-py3 -f Dockerfile.gpu .CPU 버전의 컨테이너 이미지를 만드는 경우, 위 마지막 명령행의 Dockerfile.gpu를 Dockerfile.cpu로 바꿔서 수행합니다.
컨테이너 이미지 만들기가 완료되었다면, 잘 동작하는지 확인해보겠습니다. 컨테이너 이미지로 컨테이너를 실행한 후, 쉘 접근이 잘되는지 확인합니다. 방법은 $ docker run 및 $ docker exec 명령을 여러분의 컨테이너 ID와 컨테이너 이름을 사용해서 수행합니다. 그리고, $ pip list|grep kogpt 명령을 수행해서 패키지가 잘 설치되었는지 확인해봅니다.
GPU가 있는 인스턴스에서 GPU 테스트를 하고자 하는 경우에는 nvidia-docker2를 설치한 후, 아래 docker run 명령에 --gpus all을 사용합니다. 만약 GPU를 사용하지 않을 경우에는 --gpus all을 생략해주세요.
# find docker image id
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
preprod-mxnet-serving 1.6.0-gpu-py3 0012f8ebdcab 24 hours ago 6.56GB
nvidia/cuda 10.1-cudnn7-runtime-ubuntu16.04 e11e11484e2e 3 months ago 1.71GB
# run docker
$ docker run --gpus all 'docker image id'
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
af357bce0c53 0012f8ebdcab "python /usr/local/b…" 7 hours ago Up 7 hours 8080-8081/tcp xxxxxxx
# access shell of the running docker
$ docker exec -it 'container name' /bin/bash2. Amazon ECR에 컨테이너 이미지 올리기
이제 우리는 KoGPT2 패키지가 설치된 컨테이너 이미지를 Amazon Elastic Container Registry(ECR)에 올릴 준비가 되었습니다. Amazon SageMaker에서 Amazon ECR에 등록된 이미지를 사용할 예정입니다. 자세한 내용은 Amazon ECR 문서의 Pushing an Image를 참조해주세요. 간단히 설명하자면, 4단계를 따르면 됩니다.
첫번째 단계는, docker를 Amazon ECR 레지스트리에 인증하는 것입니다. get-login-password 명령을 사용합니다. AWS CLI 1.17.0 또는 이전 버전을 사용하는 경우, docker login 명령을 얻기 위해서 아래 명령을 수행합니다. 만약 AWS CLI 1.17.0 보다 높은 버전을 사용하는 경우에는 Using an Authorization Token 문서를 참고하세요. 아래 명령 수행 결과를 복사해서 수행하면 docker가 인증을 받습니다. 서울 리전을 사용하기 위해서 AWS region name을 ap-northeast-2로 지정하세요.
$ aws ecr get-login --region 'AWS region name' --no-include-email두 번째로 해야 할 일은 Amazon ECR 리포지토리를 만드는 것입니다. AWS 콘솔을 이용하거나 AWS CLI를 이용할 수 있는데, 여기서는 AWS CLI를 이용하겠습니다. 사용할 명령은 $ aws ecr create-repository 입니다. 만약 이미 만들어져 있는 리포지토리를 사용할 예정이면 다음 단계로 넘어가세요. 리포지토리 이름은 kogpt2라고 지정합니다.
$ aws ecr create-repository --repository-name 'repository name' --region 'AWS region name'리포지토리 이름을 사용해서 이미지에 새로운 태그를 부여합니다. docker image 명령으로 컨테이너 이미지 ID를 얻은 후, docker tag 명령에 이미지 ID와 리포지토리 URI를 사용해서 수행합니다. 아래 명령에서 AWS account ID, AWS region, 그리고 repository name 을 적당하게 바꾸는 것을 잊지 마세요.
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
preprod-mxnet-serving 1.6.0-gpu-py3 698f5cefa0cf 5 hours ago 6.56GB
nvidia/cuda 10.1-cudnn7-runtime-ubuntu16.04 e11e11484e2e 3 months ago 1.71GB
$ docker tag 'image id' xxxxxx.dkr.ecr.ap-northeast-2.amazonaws.com/kogpt2
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
preprod-mxnet-serving 1.6.0-gpu-py3 0012f8ebdcab 2 minutes ago 6.56GB
xxxxxxx.dkr.ecr.ap-northeast-2.amazonaws.com/kogpt2 latest 0012f8ebdcab 2 minutes ago 6.56GB
nvidia/cuda 10.1-cudnn7-runtime-ubuntu16.04 e11e11484e2e 3 months ago 1.71GB마지막 단계로 이미지를 Amazon ECR 리포지토리에 올리면 됩니다. $ docker image 명령 수행 결과로 얻은 리포지토리 이름을 사용합니다. 올린 후, $ aws ecr list-images 명령으로 이미지가 잘 올라갔는지 확인합니다.
$ docker push xxxxxxx.dkr.ecr.ap-northeast-2.amazonaws.com/kogpt2
$ aws ecr list-images --repository-name kogpt2
{
"imageIds": [
{
"imageDigest": "sha256:66bc1759a4d2e94daff4dd02446024a11c5af29d9259175f11701a0b9ee2d2d1",
"imageTag": "latest"
}
]
}3. KoGPT2 모델을 Amazon SageMaker에 배포하기
여러분의 자연어 처리(NLP) 문제를 직접 해결하기 위해서 미리 훈련된(pre-trained) KoGPT2 모델을 활용해서 개선된 모델을 만들 수 있습니다. 이러한 작업을 파인튜닝(fine-tuning)이라고 합니다. 하지만, 여기서는 미리 훈련된 KoGPT2 모델을 Amazon SageMaker에 배포해서 한국어 문장을 완성하는 예제를 살펴보겠습니다. 우선 KoGPT2 리포지터리에 있는 예제를 수행해서, ~/kogpt2 디렉토리에 2개 파일이 생성된 것을 확인합니다. 하나는 Apache MXNet 모델 매개변수(parameter) 파일이고, 다른 하나는 문장 단어(vocabulary) 파일입니다. 이 두 파일을 .tar.gz으로 묶어서 여러분의 Amazon S3 버킷에 올립니다.
$ cd ~/kogpt2
$ tar cvfz model.tar.gz ./*.params ./*.spiece
$ aws s3 cp ./model.tar.gz s3://your-bucket-name/gpt2-model/model.tar.gz자, 드디어 MXNet 추론 컨테이너 이미지와 모델 아티팩트(.tar.gz 파일)를 Amazon ECR 및 Amazon S3 버킷에 준비하였습니다. 이제 Amazon SageMaker를 이용하면 모델을 배포할 수 있습니다. 모델을 배포하는 것은 모델 객체와 서비스용 엔드포인트를 만드는 것입니다. SageMaker Python SDK를 이용해서 MXNetModel 객체를 정의해서 deploy() 함수를 호출하는 것으로 간단히 만들 수 있습니다.
MXNetModel 객체를 정의하고 배포를 수행하기에 앞서 추론에 사용할 python 코드를 준비해야 합니다. 이 코드는 멀티 모델 서버(Multi Model Server)에서 정의한 인터페이스인 model_fn() 및 transform_fn()을 구현합니다. model_fn() 함수는 모델을 메모리로 올리는 방법을 정의하고, tranform_fn()은 사용자로부터 입력받은 내용을 변환하고, inference를 수행하고 결과를 변환하는 역할을 합니다. (즉, 전처리, 추론, 후처리 과정입니다.) 만약 이를 서로 다른 함수로 정의하고자 한다면, transform_fn()를 구현하는 대신 input_fn(), predict_fn(), 그리고 output_fn()에 전처리, 추론, 그리고 후처리를 각각 구현합니다. 보다 자세한 내용은 SageMaker Python SDK문서의 The SageMaker MXNet Model Server를 참고하세요.
import os
import json
import glob
import time
import mxnet as mx
import gluonnlp as nlp
from gluonnlp.data import SentencepieceTokenizer
from kogpt2.model.gpt import GPT2Model as MXGPT2Model
from kogpt2.utils import get_tokenizer
def get_kogpt2_model(model_file,
vocab_file,
ctx=mx.cpu(0)):
vocab_b_obj = nlp.vocab.BERTVocab.from_sentencepiece(vocab_file,
mask_token=None,
sep_token=None,
cls_token=None,
unknown_token='',
padding_token='',
bos_token='', eos_token='')
mxmodel = MXGPT2Model(units=768,
max_length=1024,
num_heads=12
num_layers=12
dropout=0.1,
vocab_size=len(vocab_b_obj))
mxmodel.load_parameters(model_file, ctx=ctx)
return (mxmodel, vocab_b_obj)
def model_fn(model_dir):
voc_file_name = glob.glob('{}/*.spiece'.format(model_dir))[0]
model_param_file_name = glob.glob('{}/*.params'.format(model_dir))[0]
# check if GPU is available
if mx.context.num_gpus() > 0:
ctx = mx.gpu()
else:
ctx = mx.cpu()
model, vocab = get_kogpt2_model(model_param_file_name, voc_file_name, ctx
tok = SentencepieceTokenizer(voc_file_name)
return model, vocab, tok, ctx
def transform_fn(model, request_body, content_type, accept_type):
model, vocab, tok, ctx = model
sent = request_body.encode('utf-8')
sent = sent.decode('unicode_escape')[1:]
sent = sent[:-1]
toked = tok(sent)
t0 = time.time()
inference_count = 0
while 1:
input_ids = mx.nd.array([vocab[vocab.bos_token]] + vocab[toked]).expand_dims(axis=0)
pred = model(input_ids.as_in_context(ctx))[0]
gen = vocab.to_tokens(mx.nd.argmax(pred, axis=-1).squeeze().astype('int').asnumpy().tolist())[-1]
if gen == '':
break
sent += gen.replace('▁', ' ')
toked = tok(sent)
inference_count +=
response_body = json.dumps([sent, inference_count, time.time() - t0])
return response_body, content_typeMXNetModel 객체를 만들 때, Amazon SageMaker에서 기본으로 제공하는 MXNet 추론 컨테이너 대신에 앞에서 만든 컨테이너 이미지를 사용하기 위해서, 앞에서 생성한 컨테이너 이미지 URI를 image 파라미터로 전달합니다. GPU를 사용한 추론을 원하는 경우에는 GPU 용으로 만든 컨테이너 이미지의 URI를 사용하고, CPU를 사용한 추론을 원하는 경우에는 CPU 용으로 만든 이미지 URI를 사용합니다. 그리고, 추론 코드가 구현되어 있는 python 파일 이름은 entry_point 값으로 전달합니다. model_data 변수의 Amazon S3 버킷 이름은 모델 아티팩트를 올린 여러분의 것으로 변경합니다.
하나의 추론용 인스턴스에 몇 개의 동시 작업자(worker)를 수행할지를 model_server_workers를 통해서 지정할 수 있습니다. 이 글을 쓰는 2020년 4월 28일 현재, 기본 worker는 1로 설정되어 있습니다. 배포에 사용되는 인스턴스의 CPU 또는 GPU들을 모두 사용하기 위해서는 이 값을 늘려주는 것이 필요합니다. 하지만, 너무 큰 수를 설정하면 메모리 부족 오류가 발생할 수 있으니, CPU 개수 또는 GPU 개수보다 같거나 작도록 설정합니다.
import sagemaker
from sagemaker.mxnet.model import MXNetModel
from sagemaker import get_execution_role
sagemaker_session = sagemaker.Session()
role = get_execution_role()
model_data = 's3:///s3-bucket-name/gpt2-model/model.tar.gz'
entry_point = './gpt2-inference.py'
mxnet_model = MXNetModel(model_data=model_data,
role=role,
entry_point=entry_point,
py_version='py3',
framework_version='1.6.0',
image='xxxxxxxxx.dkr.ecr.ap-northeast-2.amazonaws.com/kogpt2:latest',
model_server_workers=2
)드디어 우리는 deploy() 함수를 수행해서 모델을 배포할 수 있습니다. 마지막으로 필요한 설정은 인스턴스 종류 및 최소 인스턴스 개수입니다.
predictor = mxnet_model.deploy(instance_type='ml.c5.large', initial_instance_count=1)
print(predictor.endpoint)자동 스케일링(Auto Scaling)은 기본으로 비활성화되어 있습니다. AWS 콘솔을 통해서 설정할 수 있고, 자세한 내용은 Amazon SageMaker 자동 스케일링 기능 출시 블로그와 Amazon SageMaker 문서의 Define a scaling policy를 참고하세요. 여기서는 간단한 방법으로 활성화 해보겠습니다.
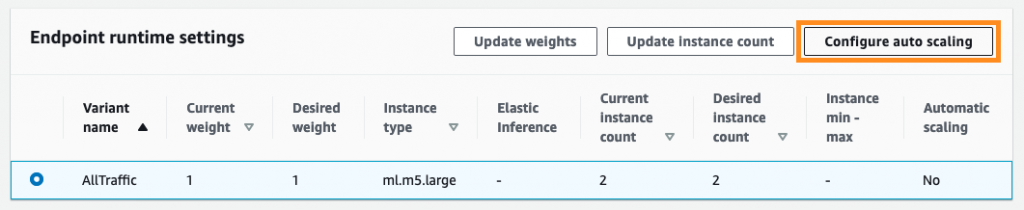
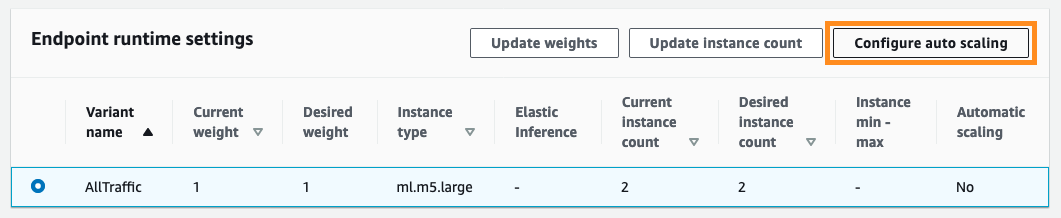
Amazon SageMaker콘솔로 이동해서, 자동 스케일링을 설정하고자 하는 엔드포인트(endpoint)를 선택하세요. 엔드포인트 상세 페이지의 “Endpoint runtime setting”로 이동합니다. 수정하고자 하는 설정(Variant)을 선택하고, ‘Configure auto scaling’ 버튼을 클릭합니다.

설정 페이지에서 최소/최대 인스턴스 개수 및 확장 정책을 설정합니다. 확장 정책은 언제 인스턴스 확장이 일어나야 하는지, 인스턴스 축소를 위한 기간을 어떻게 할지를 정의합니다. 원하는 설정을 적용하기 위해서 “Save” 버튼을 누릅니다.


자동 스케일링이 설정이 완료되면 “Automatic scaling”의 값이 “Yes”로 바뀐 것을 확인할 수 있습니다.


4. SageMaker 엔드포인트로 KoGPT2 모델 추론 및 속도 측정해보기
우리가 배포한 모델을 운영 환경에서 사용하기 전에, 모델 추론 속도를 측정해서 적당한 인스턴스 종류를 선택했는지를 확인하는 것은 중요한 검증 과정입니다. 만일 부하 테스트를 수행하고자 한다면, AWS ML 블로그의 Load test and optimize an Amazon SageMaker endpoint using automatic scaling을 참고하세요.
이제 모델 엔드포인트에 API를 반복적으로 호출해서 각 응답이 오는 시간의 평균을 구해보겠습니다. 이를 위해 “아기 공룡 둘리는 희동이와”라는 문장의 일부를 입력으로 모델에 전달해서 문장을 완성해보는 예제를 살펴봅니다. 문장의 종료 토큰이 생성될 때까지 다음 토큰에 대한 추론을 반복하면서 다음과 같이 문장을 완성합니다.
아기 공룡 둘리는 희동이와 아기 공룡 둘리는 희동이와 함께 아기 공룡 둘리는 희동이와 함께 공룡 아기 공룡 둘리는 희동이와 함께 공룡을 아기 공룡 둘리는 희동이와 함께 공룡을 사냥 아기 공룡 둘리는 희동이와 함께 공룡을 사냥하는 아기 공룡 둘리는 희동이와 함께 공룡을 사냥하는 모습을 아기 공룡 둘리는 희동이와 함께 공룡을 사냥하는 모습을 담았다 아기 공룡 둘리는 희동이와 함께 공룡을 사냥하는 모습을 담았다.
아래 샘플 코드에서 end-point-name은 위에서 배포한 엔드포인트 이름으로 바꿔주세요.
import sagemaker
from sagemaker.mxnet.model import MXNetPredictor
sagemaker_session = sagemaker.Session()
endpoint_name = 'end-point-name'
predictor = MXNetPredictor(endpoint_name, sagemaker_session)
input_sentence = '아기 공룡 둘리는 희동이와'
pred_latency_sum = 0
pred_count_sum = 0
pred_cnt = 0
for i in range(20):
try:
pred_out = predictor.predict(input_sentence)
if i == 0:
continue
predicted_sentence= pred_out[0]
predict_count = pred_out[1]
predict_latency = pred_out[2]
pred_latency_sum += predict_latency
pred_count_sum =+ predict_count
pred_cnt += 1
except:
print('Error and ingore it.')
avg_latency = pred_latency_sum / pred_cnt
avg_latency_per_inf = avg_latency / pred_count_sum
print('Input sentence: {}'.format(input_sentence))
print('Predicted sentence: {}'.format(predicted_sentence))
print('Average number of inferenced token: {:.2f}'.format(pred_count_sum))
print('Average inference latency for a sentence completion: {:.2f}'.format(avg_latency))
print('Average inference latency per a token: {:.2f}n'.format(avg_latency_per_inf))위 예제를 사용하여 여러 인스턴스 종류별로 모델을 배포해서 추론 속도를 측정한 결과를 보면, GPU를 사용하는 경우가 CPU 보다 약 4배 정도 빠른 것으로 측정되고 있습니다. 이를 고려하면, 더 빠른 실시간 추론에 필요한 서비스에 사용할 경우에는 GPU 인스턴스를 사용하고, 그렇지 않은 경우에는 CPU 인스턴스를 선택할 수 있습니다.
단, 아래 부분은 예시이며 실제 상황을 반영한 부하 테스트를 위해서 여러분의 모델 및 다양한 설정(인스턴스 종류, 개수, 동시 작업자(worker) 수)에 따라 달라질 수 있습니다.
| CPU/GPU | ML 인스턴스 종류 | 평균 inference 시간 (초/토큰) |
|---|---|---|
| CPU | ml.c4.2xlarge | 0.15 |
| ml.c5.2xlarge | 0.19 | |
| ml.m4.2xlarge | 0.17 | |
| ml.m5.2xlarge | 0.21 | |
| ml.r5.2xlarge | 0.21 | |
| ml.t2.2xlarge | 0.17 | |
| GPU | ml.p2.xlarge | 0.09 |
| ml.p3.2xlarge | 0.05 | |
| ml.g4dn.2xlarge | 0.04 |
자, 이제 테스트가 모두 끝났고 더 이상 클라우드 자원들을 사용할 필요가 없다면, 아래 명령으로 SageMaker endpoint 및 모델을 삭제합니다. 더 이상의 요금이 나오지 않게 하기 위해서는 Amazon ECR 콘솔에서 이미지 및 리포지토리를 삭제하고, Amazon S3 버킷도 삭제하세요.
predictor.delete_endpoint()
predictor.delete_model()지금까지 MXNet 추론 컨테이너 이미지를 확장해서 KoGPT2 모델의 컨테이너 이미지를 빌드하고, Amazon SageMaker에 배포하여 높은 확장성을 가진 대용량 모델 추론 서비스 환경을 구축하는 것을 살펴보았습니다.
이를 통해 여러분의 다양한 한국어 처리 문제를 해결하기 위한 딥러닝 모델을 손쉽게 만들고, 이를 클라우드가 제공하는 완전 관리형 모델 학습 및 추론 서비스 환경을 통해 제공해 보시기 바랍니다.
좀 더 자세한 것은 5월 13일에 열리는 AWS Summit Online에서 심화 트랙(10:40am – 11:10am) ‘대용량 한글 자연어처리 모델의 클라우드 분산 학습 및 배포 사례’ 세션에서 살펴보실 수 있습니다. 본 세션에서는 AWS EC2 p3dn.24xlarge, EFA(Elastic Fabric Adapter), 및 Amazon FSx for Lustre를 활용한 딥러닝 분산 학습 환경 구성 및 한글 BERT 모델 및 GPT2 모델 학습 사례를 공유합니다. 또한, SK텔레콤에서 공개한 한글 BERT 모델 및 한글 GPT2 모델 소개와 Amazon SageMaker의 모델 배포를 이용한 활용 방법을 소개합니다. 지금 참가 등록하시기 바랍니다!
– 김무현 데이터 사이언티스트, Amazon Machine Learning Solutions Lab, AWS
– 강지양 딥러닝 아키텍트, Amazon Machine Learning Solutions Lab, AWS
– 전희원 연구원, SK Telecom
이 글에서 사용한 추론 코드 및 주피터 노트북 파일은 Github 리포지토리(https://github.com/aws-samples/kogpt2-sagemaker)에서 받을 수 있습니다.
참고 자료
- KoGPT2 https://github.com/SKT-AI/KoGPT2
- GluonNLP https://gluon-nlp.mxnet.io/
- SageMaker MXNet serving container git repository https://github.com/aws/sagemaker-mxnet-serving-container
- Amazon SageMaker Python SDK – Deploy Endpoints from Model Data https://sagemaker.readthedocs.io/en/stable/using_mxnet.html#deploy-endpoints-from-model-data
- MXNet Model Serving sample https://github.com/awslabs/amazon-sagemaker-examples/blob/master/sagemaker-python-sdk/mxnet_gluon_sentiment