


Amazon SageMaker 자동 모델 튜닝 기능 출시 – 기계 학습을 위한 인공 지능

오늘 Amazon SageMaker 자동 모델 튜닝 기능을 출시합니다. 자동 모델 튜닝은 모델의 정확성을 높이기 위한 하이퍼파라미터(Hyperparameter)을 조정하는 힘든 작업을 단순화합니다. 이 기능을 사용하면 개발자 및 데이터 과학자가 기계 학습 모델을 훈련하고 튜닝할 때 상당한 시간과 노력을 절약할 수 있습니다. 하이퍼파라미터 튜닝 작업은 완료된 훈련 작업의 결과를 기준으로 서로 다른 하이퍼파라미터 조합을 사용하는 다수의 훈련 작업을 시작합니다.
SageMaker는 Bayesian 최적화를 기반으로 “메타” 기계 학습 모델을 훈련하여 훈련 작업의 하이퍼파라미터 조합을 유추합니다. 이 프로세스를 좀 더 자세히 살펴보겠습니다.
기계 학습 모델 튜닝 프로세스
개발자들이 진행하는 일반적인 기계 학습 과정은 탐색적 데이터 분석(Exploratory data analysis), 모델 설계, 모델 훈련 및 모델 평가의 4개 단계로 구성됩니다. SageMaker에서는 강력한 Jupyter Notebook 인스턴스, 기본 알고리즘 및 서비스 내 모델 훈련 기능에 접근하여 이 각 단계를 손쉽게 수행할 수 있습니다. 이 과정 중에도 모델 훈련 부분을 집중적으로 설명하자면, 일반적으로 개발자가 데이터를 모델에 공급한 후 예상된 결과를 기준으로 모델의 예측 성능을 평가합니다. 전체 입력 데이터의 일부인 평가 데이터는 모델 훈련에 사용되는 훈련 데이터와 별개로 유지됩니다. 평가 데이터를 사용하면 데이터에 대한 모델의 관찰되지 않은 동작을 검사할 수 있습니다. 많은 경우, 입력 데이터에 대한 결과를 최적화하려면 알고리즘을 선택하거나 사용자 지정 모델을 구축한 후 알고리즘의 가능한 하이퍼파라미터 구성 공간을 검색해야 합니다.
하이퍼파라미터는 기반 알고리즘의 작동 방식과 이 기반 알고리즘이 모델의 성능에 미치는 영향을 제어합니다. 예를 들어 훈련할 에폭(Epoch)의 갯수, 네트워크의 계층 갯수, 훈련 속도, 최적화 알고리즘 등을 제어합니다. 일반적으로, 임의의 값 또는 다른 문제에 대한 일반 값에서 시작한 다음 조정을 통해 반복하면서 변경의 효과를 관찰하게 됩니다. 과거에는 이 작업을 힘들게 수동으로 수행해야 했습니다. 그러나 뛰어난 몇몇 연구원 덕에 SageMaker를 사용하여 거의 모든 수동 오버헤드를 제거할 수 있습니다. 사용자는 튜닝할 하이퍼파라미터, 각 파라미터의 탐색 범위 및 예상되는 훈련 작업의 총 수를 선택하기만 하면 됩니다. 이 작업을 실제로 살펴봅시다.
하이퍼파라미터 튜닝
이 기능의 데모를 위해 표준 MNIST 데이터 세트, Apache MXNet 프레임워크 및 SageMaker Python SDK를 사용하겠습니다. 아래에서 보는 모든 내용은 SageMaker 예제 Notebook에서 확인할 수 있습니다.
먼저, SageMaker Python SDK를 사용하여 Notebook 인스턴스에 기존 MXNet 추정기를 생성합니다.
import boto3
import sagemaker
from sagemaker.mxnet import MXNet
role = sagemaker.get_execution_role()
region = boto3.Session().region_name
train_data_location = 's3://sagemaker-sample-data-{}/mxnet/mnist/train'.format(region)
test_data_location = 's3://sagemaker-sample-data-{}/mxnet/mnist/test'.format(region)
estimator = MXNet(entry_point='mnist.py',
role=role,
train_instance_count=1,
train_instance_type='ml.m4.xlarge',
sagemaker_session=sagemaker.Session(),
base_job_name='HPO-mxnet',
hyperparameters={'batch_size': 100})
지금까지는 다른 SageMaker 예제와 꽤 유사합니다.
이제 자동 모델 튜닝에 사용할 일부 도구를 가져오고 하이퍼파라미터 범위를 생성할 수 있습니다.
from sagemaker.tuner import HyperparameterTuner, IntegerParameter, CategoricalParameter, ContinuousParameter
hyperparameter_ranges = {'optimizer': CategoricalParameter(['sgd', 'Adam']),
'learning_rate': ContinuousParameter(0.01, 0.2),
'num_epoch': IntegerParameter(10, 50)}
튜닝 작업에서는 이러한 범위에서 파라미터를 선택하고 선택한 파라미터를 사용하여 훈련 작업을 집중할 최적의 위치를 결정하게 됩니다. 몇 가지 파라미터 유형은 다음과 같습니다.
- 범주형 파라미터는 불연속 세트의 값 하나를 사용합니다.
- 연속형 파라미터는 최소값과 최대값 사이의 모든 실수 값을 사용할 수 있습니다.
- 정수 파라미터는 지정된 경계 내의 모든 정수를 사용할 수 있습니다.
이제, 범위가 정의되었으니 성공 지표를 정의하고 훈련 작업 로그에서 해당 지표를 찾는 정규식을 정의합니다.
objective_metric_name = 'Validation-accuracy'
metric_definitions = [{'Name': 'Validation-accuracy',
'Regex': 'Validation-accuracy=([0-9.]+)'}]
몇 가지 정의된 항목을 사용하여 튜닝 작업을 시작할 수 있습니다.
tuner = HyperparameterTuner(estimator,
objective_metric_name,
hyperparameter_ranges,
metric_definitions,
max_jobs=9,
max_parallel_jobs=3)
tuner.fit({'train': train_data_location, 'test': test_data_location})
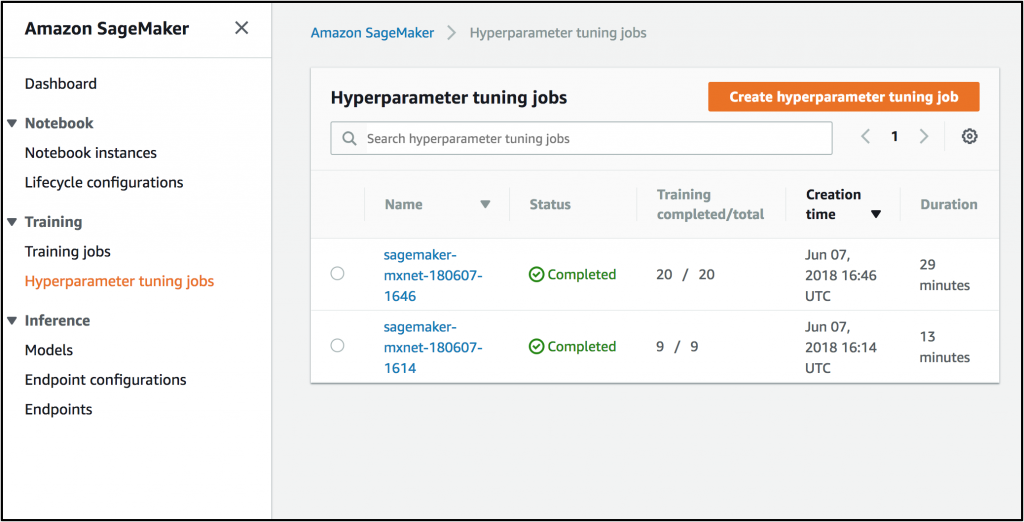
SageMaker 콘솔을 열고 [Hyperparameter tuning jobs] 하위 콘솔을 선택한 다음 모든 튜닝 작업을 확인합니다.

방금 생성한 작업을 클릭하여 추가 세부 정보를 확인하고 튜닝의 결과를 탐색할 수 있습니다.

기본적으로 콘솔에는 결과가 가장 좋은 작업과 사용된 파라미터가 표시되지만 다른 각 작업을 확인할 수도 있습니다.


Notebook 인스턴스로 돌아온 후 tuner.analytics()의 편리한 분석 객체를 사용하여 훈련 결과를 시각화할 수 있습니다. 여기서는 bokeh 플롯을 사용합니다. 이 작업에 대한 몇 가지 예제가 SageMaker 예제 Notebook에 나와 있습니다.


이 기능은 기본 알고리즘, SageMaker Python SDK를 통해 생성된 작업 또는 도커의 BYO(Bring-Your-Own) 훈련 작업에 사용할 수 있습니다.
콘솔에서 [Create hyperparameter tuning job]을 클릭하여 바로 튜닝 작업을 생성할 수도 있습니다.
먼저, 작업 이름, IAM 역할 및 실행할 VPC를 선택합니다.


다음으로 훈련 작업을 구성합니다. 기본 알고리즘을 사용하거나 사용자 지정 도커 이미지를 사용할 수 있습니다. 사용자 지정 이미지를 사용하는 경우 로그의 객체 지표를 찾기 위해 정규식을 정의한 위치에서 사용할 수 있습니다. 지금은 XGBoost를 선택하고 [Next]를 클릭합니다.


이제 예제 Notebook에 나와 있는 것과 같은 튜닝 작업 파라미터를 구성합니다. AUC(곡선하면적)를 최적화할 객체 지표로 선택하겠습니다. 현재 사용하는 알고리즘이 기본 알고리즘이므로 지표에 대한 정규식이 이전 단계에서 이미 입력되어 있습니다. 최소 및 최대 라운드 수를 설정하고 [Next]를 클릭합니다.


다음 화면에서 알고리즘의 예상 입력 채널과 모델의 출력 위치를 구성할 수 있습니다. 일반적으로 “train” 채널 외의 추가 채널을 사용할 수 있으며 “eval” 채널도 있습니다.


마지막으로, 이 튜닝 작업의 리소스 제한을 구성할 수 있습니다.


관련 자료
자동 모델 튜닝을 활용할 때, 몇 가지 항목만 정의하면 됩니다. 즉, 하이퍼파라미터 범위, 성공 지표 및 성공 지표를 찾는 정규식, 병렬로 실행할 작업의 수와 실행할 작업의 최대 수를 정의하기만 하면 자동 모델 튜닝을 사용할 수 있습니다. 기본 알고리즘을 사용하는 경우에는 정규식을 정의할 필요도 없습니다. 사용되는 병렬 작업의 수와 최종 모델의 정확성 간에는 약간의 상충이 존재합니다. 병렬 작업 수를 나타내는 max_parallel_jobs를 늘리면 튜닝 작업이 훨씬 더 빠르게 완료되지만 일반적으로 최종 결과는 병렬 처리 수가 낮을 때 조금 더 좋아집니다.
Amazon SageMaker 자동 모델 튜닝은 무료로 제공되며 사용자는 튜닝 작업에서 시작하는 훈련 작업에 사용되는 기반 리소스에 대한 요금만 지불하면 됩니다. 이제 SageMaker가 제공되는 모든 리전에서 이 기능을 사용할 수 있습니다. 이 기능은 API로 제공되며 자동 모델 튜닝에 의해 시작되는 훈련 작업을 콘솔에서 볼 수 있습니다. 설명서에서 더 자세한 내용을 확인할 수 있습니다.
이 기능으로 기존의 개발자의 시간과 노력이 절약될 것이며, AWS 고객은 본 기능을 사용하여 놀라운 성과를 얻을 수 있을 것입니다. 언제나 그렇듯이 여러분의 의견을 기다립니다.
– Randall;