


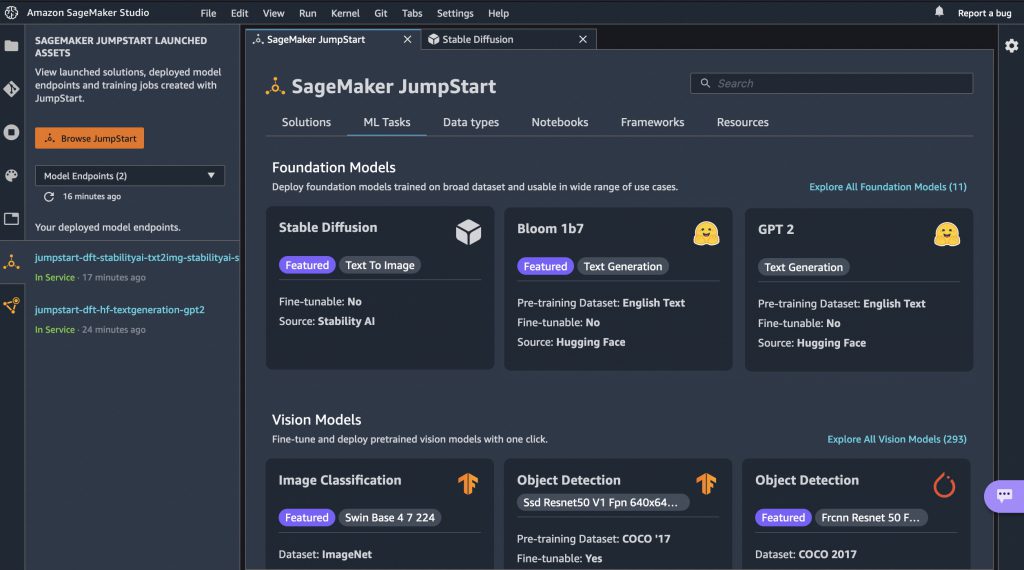
Amazon SageMaker JumpStart를 통해 다양한 생성 AI 모델 활용하기

Amazon SageMaker JumpStart는 이미 공개되어 사전 훈련된 다양한 기계 학습 모델을 통해 기업 내의 원하는 문제를 좀 더 쉽게 해결하도록 도움을 주고 기능을 제공합니다. SageMaker JumpStart는 TensorFlow Hub, PyTorch Hub, HuggingFace 및 MxNet GluonCV를 포함한 모델 허브에서 사전 훈련된 모델을 사용하는 수백 개의 기본 제공 알고리즘을 제공합니다.

사전 훈련된 기계 학습 모델 중 기초 모델(Foundation Model)은 이른바 생성 AI (Generative AI) 기능인 문서 요약 및 이미지 생성과 같은 작업을 수행하는 대규모 학습 모델로서, 기업 내에서 이들 모델을 활용하여 다양한 실험 및 비지니스 적용이 가능합니다. 이 글에서는 Amazon SageMaker JumpStart에서 제공하는 몇 가지 기초 모델을 살펴 보고, 이를 배포하는 방법에 대해 소개합니다.
기초 모델(Foundation Model)이란?


기초 모델을 사용하면 문서 요약과 텍스트, 이미지 또는 비디오 생성과 같은 다양한 작업을 수행할 수 있습니다. 이들 기초 모델은 사전 훈련되어 있으므로 훈련 및 인프라 비용을 낮추고 사용 사례에 적합한 사용자 지정을 지원하는 데 도움이 될 수 있습니다.
대규모 언어 모델의 경우, 매우 적은 양의 입력 예제만으로도 다른 언어로 질문 및 답변과 같은 새로운 작업을 수행하도록 모델을 가르칠 수 있습니다. 이를 상황 내 학습( in-context learning)이라고 합니다. 또한, 추론을 위한 컨텍스트로 제공되는 새로운 작업의 몇 가지 예만 있으면 언어 간에도 대규모 사전 훈련 중에 학습한 지식을 전달할 수 있습니다. 이것을 퓨샷 학습(few-shot learning)이라고 합니다. 경우에 따라서 해당 모델은 훈련 데이터 없이 예측해야 할 사항에 대한 설명만 있으면 잘 수행할 수 있습니다. 이를 제로샷 학습(zero-shot learning)이라고 합니다.
이러한 기초 모델은 간단한 텍스트 지침에서 텍스트, 이미지, 오디오, 비디오, 프로그래밍 코드 등을 생성할 수 있습니다. 예를 들어, 모델에게 “스위스 알프스에서 자전거를 타는 네 사람, 르네상스 그림, 장엄한 숨막히는 자연 풍경”이라는 문장을 제공하면 위와 같은 이미지를 만들수 있습니다.
Amazon SageMaker JumpStart에서는 잘 알려진 공개형 기초 모델인 Stability AI 이미지 생성 모델, Cohere 언어 모델, Bloom 및 GPT2 언어 모델, AI21 Jurassic-1 언어 모델, AlexaTM 20B i 언어 모델, LightOn Lyra-fr 언어 모델 같은 주요 기초 모델을 제공하고 있습니다. 이들 모델을 직접 배포하여 회사 내의 민감한 데이터와 함께 안전하게 테스트하거나 추가적인 모델 훈련을 통해 원하는 기능을 구현해 볼 수 있습니다.
Stable Diffusion 이미지 생성 모델 사용하기
Stability AI 는 이미지, 언어, 오디오, 비디오 및 3D 콘텐츠 생성을 위한 AI 모델을 개발하는 커뮤니티 중심의 오픈 소스 인공 지능(AI) 회사입니다. Stable Diffusion 이미지 생성 모델은 심층 신경망과 확산 프로세스의 조합을 사용하여 안정적이고 다양한 이미지 샘플을 생성하는 공개된 모델입니다. 확산 프로세스는 이미지 생성 프로세스의 안정성을 보장하기 위해 일련의 중간 표현을 통해 노이즈 벡터를 최종 이미지로 반복적으로 변환하는 방식입니다.
이 모델의 심층 신경망 구성 요소는 이러한 확산 프로세스를 가이드하고, 최종 이미지의 고품질과 시각적으로 매력적인지 확인하는 데 사용됩니다. 이 두 구성 요소의 조합으로 일관되고 안정적인 특성을 가진 고품질 이미지를 생성할 수 있는 동시에 생성된 이미지에 높은 수준의 다양성을 허용하는 모델이 생성됩니다.


최근 출시 기능에서는 이전보다 최대 10배 빠르게 일관된 이미지를 생성할 수 있는 안정적인 확산 모델을 발표하여, 이미지의 해상도를 높이고 깊이 있는 정보를 추론하여 새 이미지를 생성하는 모델도 도입되었습니다. 위의 이미지는 새로운 depth2img 모델을 사용하여 원본 이미지의 깊이와 일관성을 유지하면서 새 이미지를 생성하는 방법의 예를 보여줍니다.
이제 Amazon SageMaker Studio에서 JumpStart 모델을 훈련하고 배포하는 방법을 간단히 알아보겠습니다. 아래 동영상은 사전 학습된 Stable Diffusion 업스케일러 모델을 JumpStart에서 찾아 손쉽게 배포하는 방법을 보여줍니다.
모델 배포와 추론을 위해 ml.p3.2xlarge 인스턴스 유형을 사용합니다. 이는 저렴한 가격으로 낮은 추론 지연 시간에 필요한 GPU 가속 기능을 제공하기 때문입니다. 해당 SageMaker 호스팅 인스턴스를 구성한 후 배포(Deploy)를 선택하면, 5~10분이 소요 된 후 엔드포인트가 실행되어 추론 요청에 응답할 수 있습니다.
JumpStart UI를 사용하여 단 몇 번의 클릭만으로 사전 훈련된 모델을 대화식으로 배포할 수도 있지만, SageMaker Python SDK에 통합된 API를 사용하여 프로그래밍 방식으로 JumpStart 모델을 사용할 수도 있습니다.
더 자세한 정보는 AWS ML 블로그의 Generate images from text with the stable diffusion model on Amazon SageMaker JumpStart 및 Upscale images with Stable Diffusion in Amazon SageMaker JumpStart를 참고하시기 바랍니다.
GPT-2 및 Bloom 대규모 언어 생성 모델 사용하기
대규모 언어모델(LLM, Large Language Model)이란 대규모 데이터 세트에서 얻은 지식을 기반으로 텍스트와 다양한 콘텐츠를 인식하고 요약 및 번역 하여 사람이 쓴 텍스트와 구별할 수 없는 텍스트를 생성하는 할 수 있게 해 줍니다.
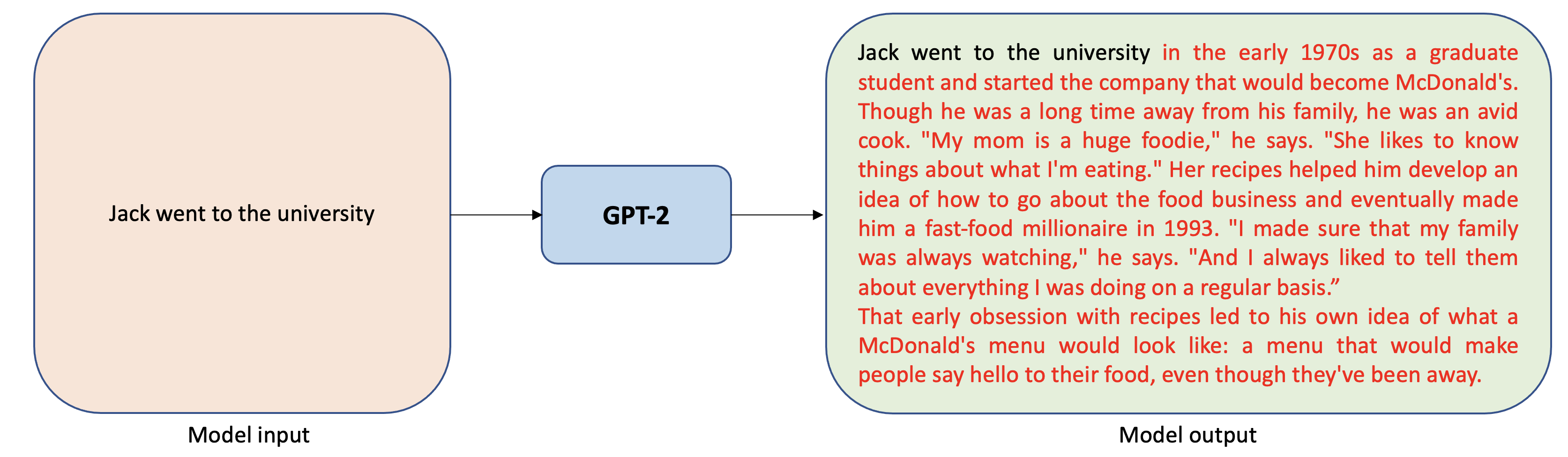
가장 대표적인 공개형 대규모 언어 모델인 GPT-2는 널리 사용되는 변환기(Transformer) 기반 텍스트 생성 모델입니다. 사람이 레이블을 지정하지 않은 영어 텍스트의 대규모 코퍼스를 사전 학습합니다. 학습 중에 부분 시퀀스(문장 또는 텍스트 조각)가 주어지면 모델은 시퀀스의 다음 토큰(예: 단어 또는 문자)을 예측합니다. GPT-2는 아래 그림과 같이 작은 입력 텍스트에서 긴 이야기를 생성하는 데 사용할 수 있습니다.

Bloom 역시 변환기 기반 텍스트 생성 모델이며 GPT-2와 유사합니다. 그러나, Bloom은 46개의 다른 언어와 13개의 프로그래밍 언어로 사전 훈련하였습니다. 다음은 Bloom 모델로 텍스트 생성을 실행하는 예입니다.


이들 모델의 특징은 텍스트 생성을 위해 미리 훈련되어 있지만 프롬프트를 통해 번역 또는 키워드 추출과 같은 다른 작업에 적용할 수 있다는 점입니다. Prompting은 사용 가능한 학습 샘플과 함께 문제 설명을 입력하여 여러 개의 텍스트 생성 작업을 할 수 있습니다. 예를 들어 아래의 경우 두 개의 학습 샘플을 사용할 수 있을 때, 번역 작업을 텍스트 생성 작업으로 정규화 할 수 있습니다.

아래 동영상은 SagaMaker JumpStart에서 Bloom 텍스트 생성 모델을 찾아 배포하는 방법을 보여줍니다. 역시 모델 추론을 위해 ml.p3.2xlarge 인스턴스 유형을 선택합니다. SageMaker 호스팅 인스턴스를 구성한 후, 추론 엔드포인트가 가동되어 실행될 때까지 20~25분이 소요될 수 있습니다.
SageMaker Python SDK에 통합된 API를 사용하여 프로그래밍 방식으로 Bloom 및 GPT2 모델을 사용하고자 한다면, AWS ML 블로그의 Run text generation with Bloom and GPT models on Amazon SageMaker JumpStart를 참고하시기 바랍니다.
AlexaTM 20B 언어 모델 활용하기
Amazon Alexa에서 만든 Alexa Teacher Model (AlexaTM)을 통해 대규모 다국어 딥 러닝 모델(주로 Transformer 기반)을 구축할 수 있습니다. AlexaTM 20B는 Amazon에서 개발한 다국어 대규모 sequence-to-sequence(seq2seq) 언어 모델입니다. 200억 개의 매개변수를 가진 대규모 사전 훈련을 통해 희소 데이터에서 새로운 작업을 학습하고, 개발자가 다운스트림 작업의 성능을 개선하도록 할 수 있습니다.
AlexaTM 20B는 기계 번역, 데이터 생성 및 요약과 같은 일반적인 자연어 처리(NLP) 벤치마크 및 작업에서 경쟁력 있는 성능을 보여주고 있습니다. 재무 보고서 요약에서 고객 서비스 챗봇에 대한 질문 답변에 이르기까지 광범위한 산업 사용 사례에 AlexaTM 20B를 사용할 수 있습니다. 특히, AlexaTM 20B는 SuperGLUE와 같은 제로샷 학습 작업에서 1,750억 GPT-3 모델을 능가하며 XNLI와 같은 다국어 제로샷 작업에서 높은 성능을 보여주었습니다.
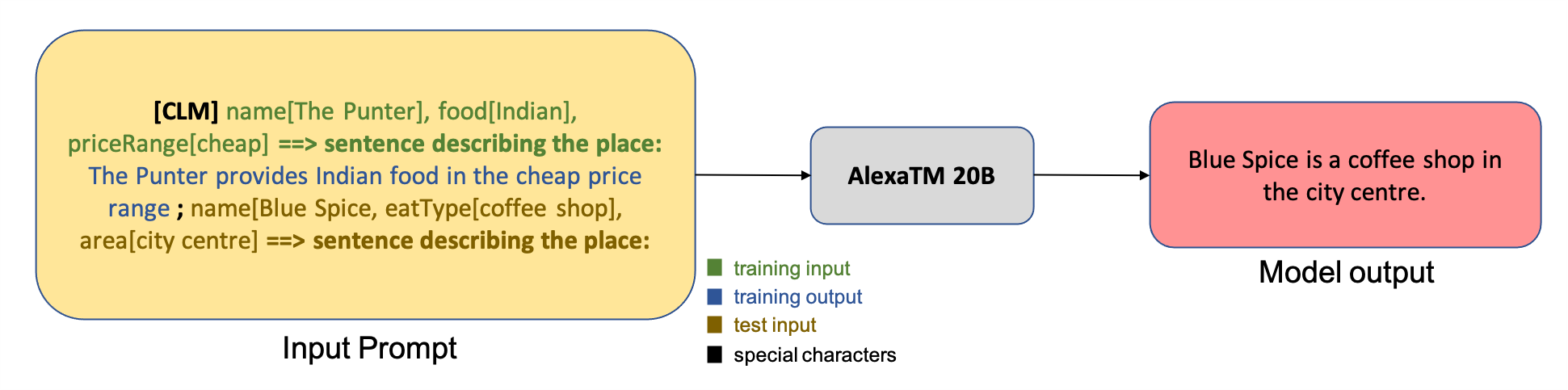
다른 언어 모델과 같이, AlexaTM 20B 모델에 전달된 입력은 해당 출력 텍스트 내러티브와 함께 속성-값 쌍 형식의 학습 예제가 추가되어 다음 그림과 같이 전체 입력 프롬프트를 형성합니다.

Amzon SageMaker Python SDK에서 사용할 수 있는 JumpStart API를 통해 프로그래밍 방식으로 AlexaTM 20B 모델을 배포하고 추론을 실행하는 방법에 대해서는 AWS ML 블로그의 AlexaTM 20B is now available in Amazon SageMaker JumpStart 를 참고하시기 바랍니다.
KoGPT2 한국어 언어 모델 활용하기
2020년 SK텔레콤에서는 OpenAI의 대용량 언어 모델인 GPT2를 한글 데이터로 학습시킨 KoGPT2 모델을 구축했습니다. 이를 위해 SK텔레콤 Conv.AI팀이 대규모 언어 모델 학습 로직을 구현하고, Amazon Machine Learning Solutions Lab이 대규모 분산 학습 인프라 구성 및 최적화, GluonNLP팀에서 학습 성능 개선에 협업으로 참여하였습니다.
위키피디아나 뉴스 등에서 수집한 수백만 개의 한국어 문장으로 이루어진 대규모 말뭉치(corpus)를 기반으로 학습하였으며, 한국어의 불규칙한 언어 변화의 특성을 반영하기 위해 데이터 기반 토큰화(Tokenization) 기법을 적용하여 Apache MXNet을 비롯하여 PyTorch, ONNX 등 다양한 딥러닝 API를 지원하였습니다. 이를 통해 당시에 기존 학습 과정 대비 학습 효율이 2배 이상 향상되었으며, 한국어 대화 데이터에 해당 모델을 적용했을 때 대화의 자연스러움이 크게 향상되었습니다.
예를 들어, “아기 공룡 둘리는 희동이와”라는 문장의 일부를 입력으로 모델에 전달해서 문장을 완성해보는 예제를 살펴봅니다. 문장의 종료 토큰이 생성될 때까지 다음 토큰에 대한 추론을 반복하면서 다음과 같이 문장을 완성합니다.
아기 공룡 둘리는 희동이와
아기 공룡 둘리는 희동이와 함께
아기 공룡 둘리는 희동이와 함께 공룡
아기 공룡 둘리는 희동이와 함께 공룡을
아기 공룡 둘리는 희동이와 함께 공룡을 사냥
아기 공룡 둘리는 희동이와 함께 공룡을 사냥하는
아기 공룡 둘리는 희동이와 함께 공룡을 사냥하는 모습을
아기 공룡 둘리는 희동이와 함께 공룡을 사냥하는 모습을 담았다
아기 공룡 둘리는 희동이와 함께 공룡을 사냥하는 모습을 담았다.KoGPT2와 같이 확장성 높은 대용량 언어 학습 모델을 배포하기 위해서는 Amazon SageMaker에서 제공하는 MXNet 추론 컨테이너를 활용하는 것이 유리합니다. KoGPT2 및 관련 패키지를 설치하여 맞춤형 컨테이너 이미지를 만든 후, 이를 Amazon SageMaker로 모델을 배포하는 더 자세한 방법은 Amazon SageMaker의 MXNet 추론 컨테이너를 활용한 KoGPT2 모델 배포하기를 참고하시기 바랍니다.
SageMaker JumpStart를 통한 생성 AI 모델 배포하기
SageMaker JumpStart를 통해서 다양한 생성 AI 모델을 배포할 수 있습니다. 예를 들어, 언어 생성 AI 스타트업인 Cohere는 자사의 사전 훈련된 생성 언어 모델을 JumpStart를 통해 배포할 수 있습니다. 이를 통해 일반 개발자와 기업 고객이 언어 AI를 기술 스택에 추가하고 이를 통해 다양한 애플리케이션을 구축할 수 있도록 지원 합니다.
Cohere 모델을 통해 카피라이팅, 엔터티 인식, 의역, 텍스트 요약 및 분류와 같은 광범위한 작업을 자동화할 수 있도록 지원합니다. 회사는 범용 LLM(대형 언어 모델)을 구축하고 지속적으로 개선하고, 고객은 모델을 사용하거나 고유한 사용자 지정 데이터를 사용하여 특정 요구 사항에 맞게 모델을 조정할 수 있습니다. 일반 AWS 고객은 AWS Marketplace를 통해 Cohere의 언어 모델을 SaaS형 API 서비스로도 구매가 가능합니다.
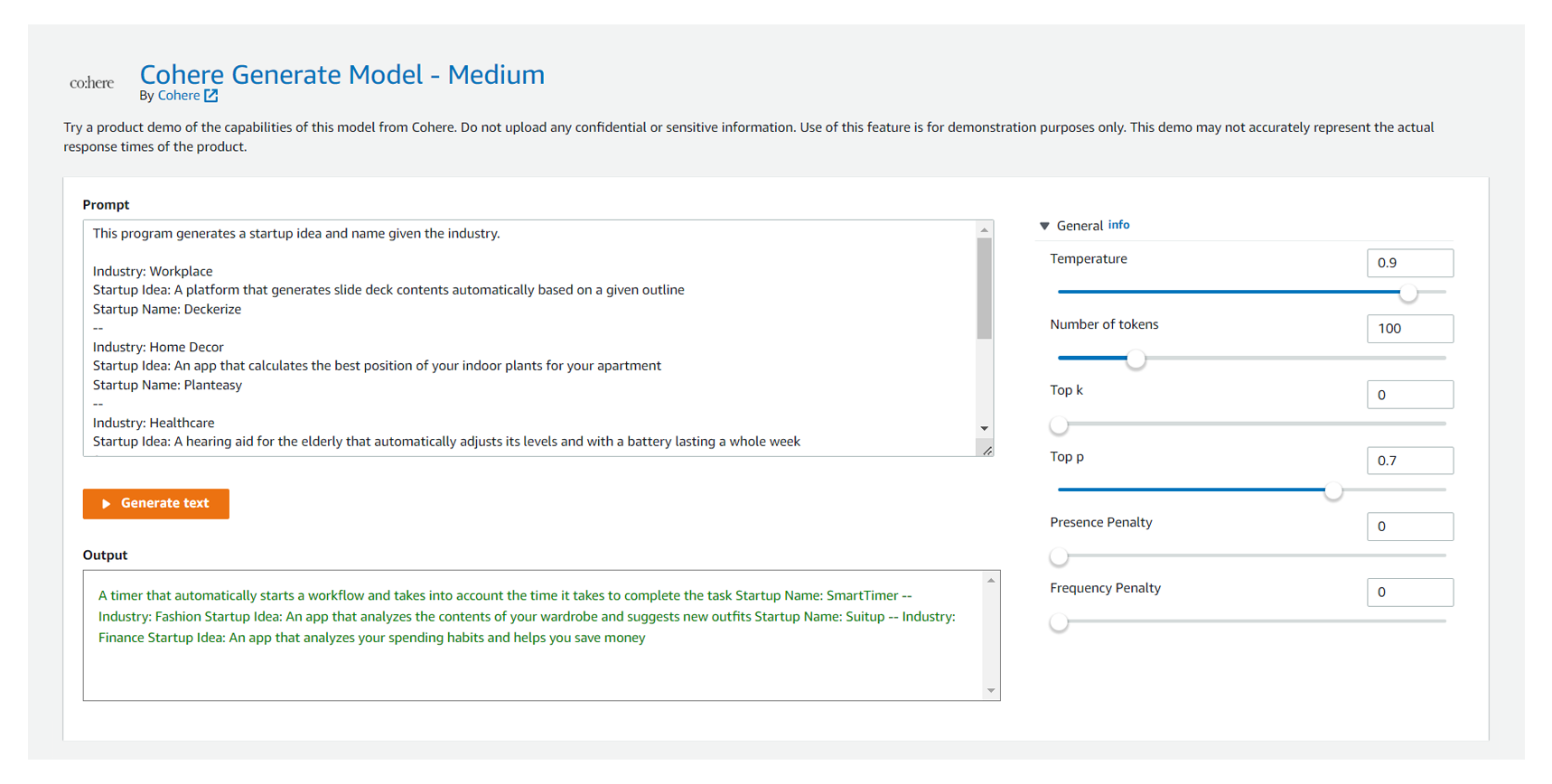

그리고, SageMaker JumpStart 기반 모델의 시각적 인터페이스를 사용하여 한 줄의 코드를 작성하지 않고도 Cohere의 모델을 테스트할 수 있습니다. 손쉽게 특정 언어 이해 작업에서 모델을 평가하고 생성 언어 모델 사용의 기본 사항을 배울 수도 있습니다. 언어 모델링과 관련된 다양한 자습서 및 팁과 요령은 AWS ML 블로그의 Cohere brings language AI to Amazon SageMaker 이나 Cohere’s 기술 문서 및 블로그 를 참고하시기 바랍니다.
마무리
지금까지 Amazon SageMaker JumpStart를 통해 기 훈련된 주요 생성 AI 기초 모델을 손쉽게 배포하고 테스트하는 방법을 살펴보았습니다. 생성 AI 모델을 비지니스로 활용하기 위해서는 자사 서비스 및 데이터를 보호하면서 맞춤형 모델을 제작해야 합니다. 기 훈련된 생성 AI 기초 모델을 통해 여러분이 원하는 목적의 AI 애플리케이션을 만들 수 있습니다. 만약, 생성 AI 모델을 만드는 스타트업이라면, JumpStart를 통해 고객에게 모델을 배포하고 테스트하면서 AWS Marketplace를 통한 SaaS 비지니스도 가능합니다.
SageMaker JumpStart는 대규모 생성 AI 모델 뿐만 아니라 다양한 기-훈련된 기계 학습 모델도 함께 지원합니다. 더 자세한 것은 아래 링크를 참고해 보시기 바랍니다.
- Amazon SageMaker JumpStart로 이미지 분할 실행하기
- Amazon SageMaker JumpStart로 TensorFlow Hub 및 Hugging Face 모델을 사용한 텍스트 분류 실행하기
- Amazon SageMaker의 TensorFlow 객체 감지 모델에 대한 전이 학습
- Amazon SageMaker의 TensorFlow 텍스트 분류 모델에 대한 전이 학습
- Amazon SageMaker의 TensorFlow 이미지 분류 모델에 대한 전이 학습
– Channy(윤석찬)