


Apache Spark과 Amazon Redshift 통합 기능 정식 출시

Apache Spark는 빅 데이터 워크로드에 일반적으로 사용되는 오픈 소스 분산 처리 시스템입니다. Amazon EMR, Amazon SageMaker 및 AWS Glue에서 작업하는 Spark 애플리케이션 개발자는 Amazon Redshift로 데이터를 읽고 쓸 수 있는 타사 Apache Spark 커넥터를 사용하는 경우가 많습니다. 이러한 타사 커넥터는 다양한 버전의 Spark에서 정기적으로 유지 관리, 지원 또는 테스트되지 않습니다.
오늘 Apache Spark용 Amazon Redshift 통합의 정식 출시를 발표합니다. 이를 통해 Amazon Redshift 및 Redshift Serverless에서 Spark 애플리케이션을 쉽게 구축하고 실행할 수 있으며, 고객은 더 광범위한 AWS 분석 및 기계 학습(ML) 솔루션을 위한 데이터 웨어하우스를 운영할 수 있습니다.
Apache Spark용 Amazon Redshift를 사용하면 몇 초 만에 시작하고 Java, Scala 및 Python과 같은 다양한 언어로 Apache Spark 애플리케이션을 손쉽게 구축할 수 있습니다.
여러분의 애플리케이션은 애플리케이션 성능이나 데이터의 트랜잭션 일관성을 손상시키지 않고 Amazon Redshift 데이터 웨어하우스에서 데이터를 읽고 쓸 수 있을 뿐만 아니라 푸시다운(Pushdown) 최적화를 통해 성능을 개선할 수 있습니다.
Apache Spark용 Amazon Redshift 통합은 기존 오픈 소스 커넥터 프로젝트를 기반으로 하며 성능 및 보안을 향상시켜 고객이 최대 10배 더 빠른 애플리케이션 성능을 확보할 수 있도록 지원합니다. 이를 실현하기 위해 협력해 주신 프로젝트의 최초 기여자들께 감사드립니다. 추가 개선을 통해 계속해서 오픈소스 프로젝트에 기여할 것입니다.
Amazon Redshift용 Spark Connector 시작하기
시작하려면 AWS 분석 및 ML 서비스로 이동하여 Spark 작업 또는 노트북에서 데이터 프레임 또는 Spark SQL 코드를 사용하여 Amazon Redshift 데이터 웨어하우스에 연결하고 몇 초 만에 쿼리 실행을 시작할 수 있습니다.
이번 출시에서는 Amazon EMR 6.9, EMR Serverless 및 AWS Glue 4.0이 사전 패키징된 커넥터 및 JDBC 드라이버와 함께 제공되며, 코드 작성을 시작하면 됩니다. EMR 6.9는 샘플 노트북을 제공하며 EMR Serverless는 샘플 Spark Job도 제공합니다.
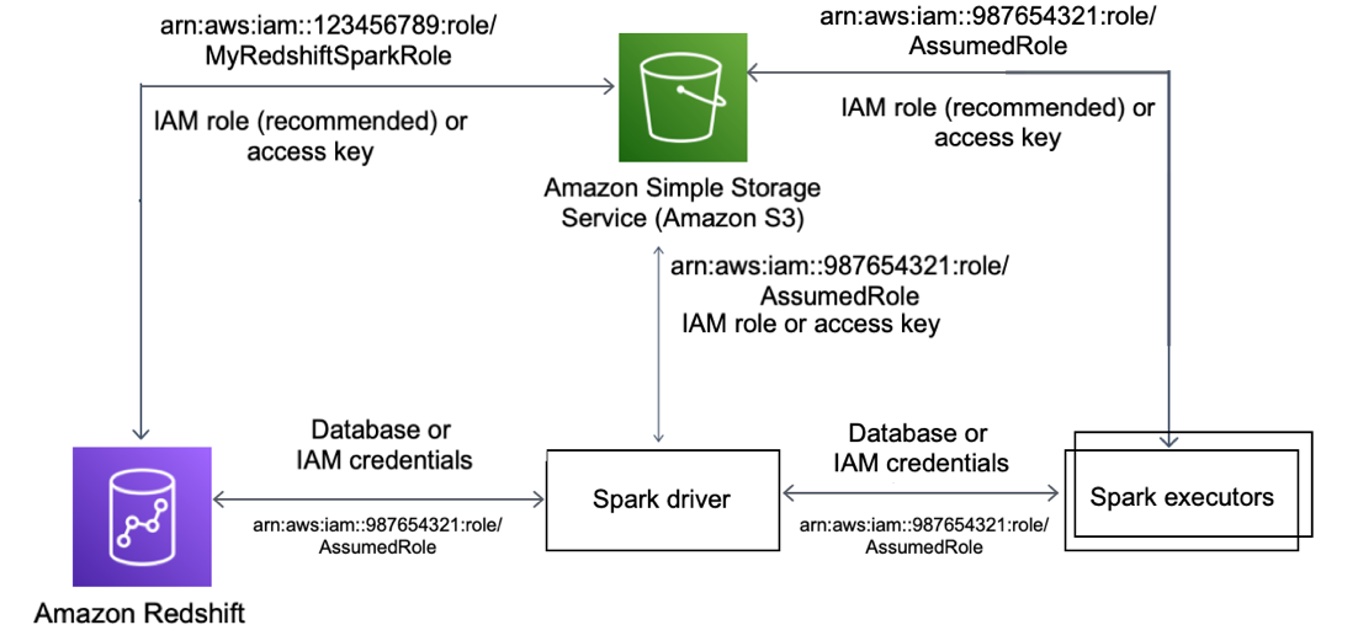
먼저 Redshift와 Spark 간, Amazon Simple Storage Service(S3)와 Spark 간, Redshift와 Amazon S3 간에 AWS Identity and Access Management(AWS IAM) 인증을 설정해야 합니다. 다음 다이어그램은 Amazon S3, Redshift, Spark 드라이버 및 Spark 실행기 간의 인증을 설명합니다.

자세한 내용은 AWS 설명서의 Identity and access management in Amazon Redshift(Amazon Redshift의 자격 증명 및 액세스 관리)를 참조하세요.
Amazon EMR
Amazon Redshift 데이터 웨어하우스와 사용 가능한 데이터가 이미 있는 경우 데이터베이스 사용자를 생성하여 데이터베이스 사용자에게 적절한 수준의 권한을 제공할 수 있습니다. Amazon EMR에서 이 기능을 사용하려면 spark-redshift 커넥터 패키지가 포함된 Amazon EMR 6.9의 최신 버전으로 업그레이드해야 합니다. Amazon EC2에서 EMR 클러스터를 생성할 때 emr-6.9.0 릴리스를 선택하세요.


EMR Serverless를 사용하여 emr-6.9.0 릴리스를 사용하여 워크로드를 실행하는 Spark 애플리케이션을 생성할 수 있습니다.


EMR Studio는 빠르게 시작하는 데 사용할 수 있는 샘플 데이터를 활용하여 Amazon Redshift Serverless 엔드포인트에 연결하도록 구성된 Jupyter Notebook 예시도 제공합니다.
다음은 Spark Dataframe과 Spark SQL을 모두 사용하여 애플리케이션을 빌드하는 Scalar 예시입니다. Redshift에 연결하는 데 IAM 기반 보안 인증을 사용하고 S3에서 데이터를 언로드 및 로드하는 데 IAM 역할을 사용합니다.
// JDBC 연결 URL 생성 및 Redshift 컨텍스트 정의
val jdbcURL = "jdbc:redshift:iam://<RedshiftEndpoint>:<Port>/<Database>?DbUser=<RsUser>"
val rsOptions = Map (
"url" -> jdbcURL,
"tempdir" -> tempS3Dir,
"aws_iam_role" -> roleARN,
)
// Redshift의 판매 테이블 참조
val sales_df = spark
.read
.format("io.github.spark_redshift_community.spark.redshift")
.options(rsOptions)
.option("dbtable", "sales")
.load()
sales_df.createOrReplaceTempView("sales")
// 데이터 프레임을 사용하여 Redshift의 날짜 테이블 참조
sales_df.join(date_df, sales_df("dateid") === date_df("dateid"))
.where(col("caldate") === "2008-01-05")
.groupBy().sum("qtysold")
.select(col("sum(qtysold)"))
.show() Amazon Redshift와 Amazon EMR이 서로 다른 VPC에 있는 경우 VPC 피어링을 구성하거나 VPC 간 액세스를 활성화해야 합니다. Amazon Redshift와 Amazon EMR이 모두 Virtual Private Cloud(VPC)에 있다고 가정한다면, Spark 작업 또는 Notebook을 생성하고 Amazon Redshift 데이터 웨어하우스에 연결하고 Spark 코드를 작성하여 Amazon Redshift 커넥터를 사용할 수 있습니다.
자세히 알아보려면 AWS 설명서의 Use Spark on Amazon Redshift with a connector(커넥터로 Amazon Redshift에서 Spark 사용)을 참조하세요.
AWS Glue
AWS Glue 4.0을 사용하는 경우 spark-redshift 커넥터를 소스 및 대상 모두로 사용할 수 있습니다. Glue Studio에서는 내장된 Redshift 소스 또는 대상 노드 내에서 사용할 Redshift 연결을 선택하기만 하면 시각적 ETL 작업을 사용하여 Redshift 데이터 웨어하우스에 읽거나 쓸 수 있습니다.
Redshift 연결에는 적절한 권한으로 Redshift에 액세스하는 데 필요한 보안 인증 정보와 함께 Redshift 연결 세부 정보가 포함되어 있습니다.
시작하려면 Glue Studio 콘솔의 왼쪽 메뉴에서 Jobs(작업)을 선택합니다. 시각 모드 중 하나를 사용하여 소스 또는 대상 노드를 쉽게 추가 및 편집하고 코드를 작성하지 않고도 데이터에 대한 변환 범위를 정의할 수 있습니다.


Create(생성)을 선택하여 작업 다이어그램에서 소스, 대상 노드 및 변환 노드를 쉽게 추가하고 편집할 수 있습니다. 이때 Amazon Redshift를 Source(소스) 및 Target(대상)으로 선택합니다.


완료되면 Apache Spark 엔진용 Glue에서 Glue 작업을 실행할 수 있으며, 이 작업은 자동으로 최신 spark-redshift 커넥터를 사용합니다.
다음 Python 스크립트는 spark-redshift 커넥터를 사용하여 dynamicframe으로 Redshift에 읽고 쓰는 예시 작업을 보여줍니다.
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
print("================ DynamicFrame Read ===============")
url = "jdbc:redshift://<RedshiftEndpoint>:<Port>/dev"
read_options = {
"url": url,
"dbtable": dbtable,
"redshiftTmpDir": redshiftTmpDir,
"tempdir": redshiftTmpDir,
"aws_iam_role": aws_iam_role,
"autopushdown": "true",
"include_column_list": "false"
}
redshift_read = glueContext.create_dynamic_frame.from_options(
connection_type="redshift",
connection_options=read_options
)
print("================ DynamicFrame Write ===============")
write_options = {
"url": url,
"dbtable": dbtable,
"user": "awsuser",
"password": "Password1",
"redshiftTmpDir": redshiftTmpDir,
"tempdir": redshiftTmpDir,
"aws_iam_role": aws_iam_role,
"autopushdown": "true",
"DbUser": "awsuser"
}
print("================ dyf write result: check redshift table ===============")
redshift_write = glueContext.write_dynamic_frame.from_options(
frame=redshift_read,
connection_type="redshift",
connection_options=write_options
)작업 세부 정보를 설정할 때 이 통합에 Glue 4.0(스파크 3.3 Python 3 지원) 버전만 사용할 수 있습니다.


자세히 알아보려면 AWS 설명서의 Creating ETL jobs with AWS Glue Studio(AWS Glue Studio로 ETL 작업 생성) 및 Using connectors and connections with AWS Glue Studio(AWS Glue Studio로 커넥터 및 연결 사용)을 참조하세요.
최고의 성능 확보
Apache Spark용 Amazon Redshift 통합에서 Spark 커넥터는 조건자 및 쿼리 푸시다운을 자동으로 적용하여 성능을 최적화합니다. 이 통합으로 언로드에 사용되는 커넥터의 기본 Parquet 형식을 사용하면 성능을 향상시킬 수 있습니다.
다음 샘플 코드에서 볼 수 있듯이 Spark 커넥터는 지원되는 함수를 SQL 쿼리로 전환하고 Amazon Redshift에서 쿼리를 실행합니다.
import sqlContext.implicits._val
sample= sqlContext.read
.format("io.github.spark_redshift_community.spark.redshift")
.option("url",jdbcURL )
.option("tempdir", tempS3Dir)
.option("unload_s3_format", "PARQUET")
.option("dbtable", "event")
.load()
// Spark SQL을 통해 액세스할 수 있도록 이전에 만든 데이터 프레임에 대한 임시 뷰 생성
sales_df.createOrReplaceTempView("sales")
date_df.createOrReplaceTempView("date")
// Spark SQL API를 사용하여 지정된 날짜의 총 판매량 표시
spark.sql(
"""SELECT sum(qtysold)
| FROM sales, date
| WHERE sales.dateid = date.dateid
| AND caldate = '2008-01-05'""".stripMargin).show()Apache Spark용 Amazon Redshift 통합은 정렬, 집계, 제한, 조인 및 스칼라 함수와 같은 작업을 위한 푸시다운 기능을 추가하여 관련 데이터만 Redshift 데이터 웨어하우스에서 소비하는 Spark 애플리케이션으로 이동하므로 성능이 향상됩니다.
지금 이용 가능
Apache Spark를 위한 Amazon Redshift 통합은 이제 Amazon EMR 6.9, AWS Glue 4.0 및 Amazon Redshift를 지원하는 모든 리전에서 사용할 수 있습니다. 새로운 Spark 3.3.0 버전과 함께 EMR 6.9 및 Glue Studio 4.0에서 직접 이 기능을 사용할 수 있습니다.
사용해 보시고 피드백이 있으시면 Amazon Redshift용 AWS re:Post 또는 평소에 이용하는 AWS Support 연락처를 통해 알려주시기 바랍니다.
– Channy