


Application Tracing with NGINX and NGINX Plus



Using variables for application performance management
Variables are an important and sometimes overlooked aspect of NGINX configuration. With approximately 150 variables available, there are variables to enhance every part of your configuration. In this blog post we discuss how to use NGINX variables for application tracing and application performance management (APM), with a focus on uncovering performance bottlenecks in your application. This post applies to both the open source NGINX software and NGINX Plus. For brevity we’ll refer to NGINX Plus throughout except when there is a difference between the two products.
The Application Delivery Environment
In our sample application delivery environment, NGINX Plus is working as a reverse proxy for our application. The application itself is comprised of a web frontend behind which sit a number of microservices.

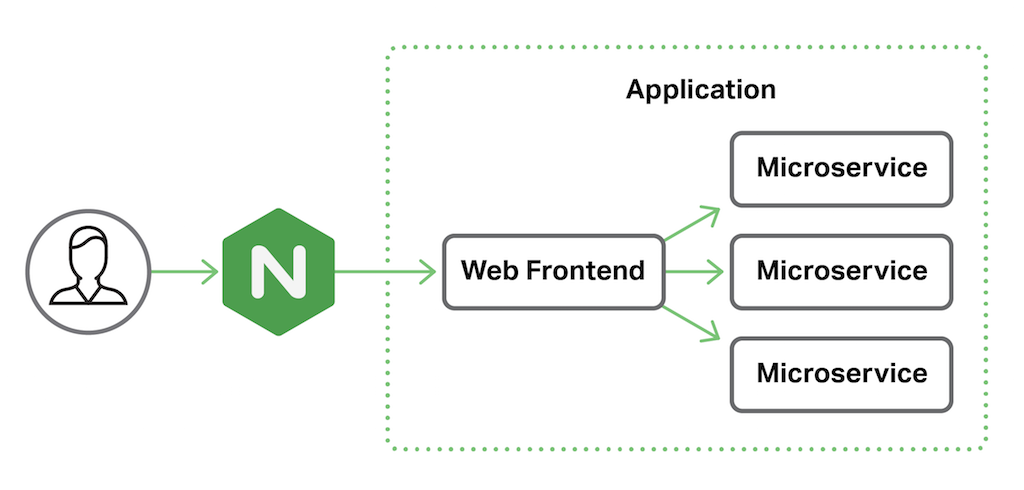
Tracing Requests End‑to‑End
NGINX Plus R10 (and NGINX 1.11.0) introduces the $request_id variable, which is a randomly generated string of 32 hexadecimal characters automatically assigned to each HTTP request as it arrives (for example, 444535f9378a3dfa1b8604bc9e05a303). This deceptively simple mechanism unlocks a powerful tool for tracing and troubleshooting. By configuring NGINX Plus and all backend services to pass the $request_id value, you can trace every request end‑to‑end. This sample config is for our frontend NGINX Plus server.
upstream app_server {
server 10.0.0.1:80;
}
server {
listen 80;
add_header X-Request-ID $request_id; # Return to client
location / {
proxy_pass http://app_server;
proxy_set_header X-Request-ID $request_id; # Pass to app server
}
}
To configure NGINX Plus for request tracing, we first define the network location of the application server in the upstream block. For simplicity we only show a single application server here, but we would normally use several, for high availability and load balancing purposes.
The server block defines how NGINX Plus handles incoming HTTP requests. The listen directive tells NGINX Plus to listen on port 80 – the default for HTTP traffic, but a production configuration normally uses use SSL/TLS to protect data in transit.
The add_header directive sends the $request_id value back to the client as a custom header in the response. This is useful for testing and also for client applications that generate their own logs, such as mobile apps, so that a client‑side error can be matched precisely to the server logs.
Finally, the location block applies to the entire application space (/) and the proxy_pass directive simply proxies all requests to the application server. The proxy_set_header directive modifies the proxied request by adding an HTTP header that is passed to the application. In this case we create a new header called X‑Request‑ID and assign to it the value of the $request_id variable. So our application receives the request ID that was generated by NGINX Plus.
Logging $request_id End‑to‑End
Our goal with application tracing is to identify performance bottlenecks in the request‑processing lifecycle as part of application performance management. We do this by logging significant events during processing so we can analyze them later for unexpected or unreasonable delays.
Configuring NGINX Plus
We start by configuring the frontend NGINX Plus server to include $request_id in a custom logging format, trace, which is used for the access_trace.log file.
log_format trace '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" "$http_user_agent" '
'"$http_x_forwarded_for" $request_id';
upstream app_server {
server 10.0.0.1;
}
server {
listen 80;
add_header X-Request-ID $request_id; # Return to client
location / {
proxy_pass http://app_server;
proxy_set_header X-Request-ID $request_id; # Pass to app server
access_log /var/log/nginx/access_trace.log trace; # Log $request_id
}
}
Configuring the Backend Application
Passing the Request ID to your application is all well and good, but does not actually help with application tracing unless the application does something with it. In this example we have a Python application managed by uWSGI. Let’s modify the application entry point to grab the Request ID as a logging variable.
from uwsgi import set_logvar
def main(environ, start_response):
set_logvar('requestid', environ['X_REQUEST_ID'])
Then we can modify the uWSGI configuration to include the Request ID in the standard log file.
log-format = %(addr) - %(user) [%(ltime)] "%(method) %(uri) %(proto)" %(status)
%(size) "%(referer)" "%(uagent)" %(requestid)With this configuration in place we are now producing log files which can be linked to a single request across numerous systems.
Log entry from NGINX:
172.17.0.1 - - [02/Aug/2016:14:26:33 +0000] "GET / HTTP/1.1" 200 90 "-" "-" "-" 5f222ae5938482c32a822dbf15e19f0fLog entry from application:
192.168.91.1 - - [02/Aug/2016:14:26:34 +0000] "GET / HTTP/1.0" 200 123 "-" "-" 5f222ae5938482c32a822dbf15e19f0fBy matching transactions against the Request ID fields, tools like Splunk and Kibana allow us to identify performance bottlenecks. For example, we can search for requests that took more than two seconds to complete. However, the default time resolution of one second in regular timestamps is insufficient for most real‑world analysis.
High‑Precision Timing
In order to accurately measure requests end‑to‑end we need timestamps with millisecond‑level precision. By including the $msec variable in log entries, we get millisecond resolution on the timestamp for each entry. Adding millisecond timestamps to our application log allows us to look for requests that took more than 200 milliseconds to complete rather than 2 seconds.
But even then we are not getting the full picture, because NGINX Plus writes the $msec timestamp only at the end of processing each request. Fortunately, there are several other NGINX Plus timing variables with millisecond precision that give us more insight into the processing itself:
$request_time– Full request time, starting when NGINX Plus reads the first byte from the client and ending when NGINX Plus sends the last byte of the response body$upstream_connect_time– Time spent establishing a connection with the upstream server$upstream_header_time– Time between establishing a connection to the upstream server and receiving the first byte of the response header$upstream_response_time– Time between establishing a connection to the upstream server and receiving the last byte of the response body
For detailed information about these timing variables, see Using NGINX Logging for Application Performance Monitoring.
Let’s extend our log_format directive to include all of these high‑precision timing variables in our trace log format.
log_format trace '$remote_addr - $remote_user [$time_local] "$request" $status '
'$body_bytes_sent "$http_referer" "$http_user_agent" '
'"$http_x_forwarded_for" $request_id $msec $request_time '
'$upstream_connect_time $upstream_header_time $upstream_response_time';Using our preferred log analysis tool, we can extract variable values and perform the following calculation to see how long NGINX Plus took to process the request before connecting to the application server:
NGINX Plus processing time = $request_time - $upstream_connect_time - $upstream_response_timeWe can also search for the highest values of $upstream_response_time to see if they are associated with particular URIs or upstream servers. And these can then be further checked against application log entries that have the same Request ID.
Conclusion
Utilizing the new $request_id variable and some or all of the millisecond‑precision variables can provide great insight into the performance bottlenecks in your application, improving application performance management without having to resort to heavyweight agents and plug‑ins.
Try out application tracing with NGINX Plus for yourself: start your free 30‑day trial today or contact us for a live demo.
The post Application Tracing with NGINX and NGINX Plus appeared first on NGINX.