


AWS Data Exchange 및 Amazon QuickSight를 사용한 AWS의 데이터 시각화

지금까지는 비즈니스에 대한 인사이트를 확보하는 데 유용한 올바른 서드 파티 데이터를 찾으려면 느리고 번거로운 프로세스를 거쳐야 했습니다. AWS Marketplace의 새로운 서비스인 AWS Data Exchange를 사용하면 이제 모든 업종의 데이터 제품을 검색하고 샘플링하고 구독할 수 있습니다. AWS Data Exchange의 카탈로그를 통해 AWS 고객은 데이터 원본에 액세스할 수 있습니다. 이러한 데이터 집합을 사용하여 분석 및 기계 학습(ML) 워크로드를 실험할 수 있습니다. AWS Data Exchange의 데이터를 Amazon QuickSight에 연결하여 주요 인사이트를 추출하고 시각화할 수 있습니다.
Amazon QuickSight는 조직의 모든 구성원에게 인사이트를 쉽게 제공할 수 있는 비즈니스 인텔리전스(BI) 서비스입니다. Amazon QuickSight를 사용하면 기계 학습 기반 인사이트를 포함하는 대화형 대시보드를 만들고 게시할 수 있습니다. 이 대시보드는 모든 디바이스에서 액세스할 수 있으며 애플리케이션, 포털 및 웹 사이트에 포함할 수 있습니다.
이 블로그 게시물에서는 AWS Data Exchange의 데이터 집합을 사용하여 Amazon QuickSight로 BI 인사이트를 구축하는 방법을 설명합니다. 이 게시물에서는 다음 두 가지에 중점을 둡니다.
- AWS Data Exchange에서 제공되는 데이터 집합을 사용하여 준비할 수 있는 시각적 요소 제시
- Amazon QuickSight를 사용하여 이러한 데이터 집합에 대한 의미 있는 인사이트를 확보하는 방법
AWS Data Exchange 데이터 집합을 구독하는 방법을 보여주는 단계별 안내서는 이 블로그 게시물 AWS Data Exchange – Find, Subscribe To, and Use Data Products를 참조하세요.
사전 조건
데이터 시각화를 위해서는 다음과 같은 AWS 서비스 및 사전 요구 사항이 필요합니다.
- 데이터 원본을 저장할 Amazon Simple Storage Service(Amazon S3) 객체 스토어
- 데이터베이스에 데이터를 로드할 필요 없이 데이터 집합을 크롤링하고 메타데이터를 준비하는 AWS Glue. 값비싼 데이터베이스를 실행하는 데 드는 비용이 절감됩니다. 그 대신에 Amazon S3 버킷에 저장된 원시 데이터 파일의 시각적 객체를 저장하고 실행할 수 있습니다.
- 수동 데이터 분석을 위해 Amazon QuickSight 데이터 집합을 쿼리하는 Amazon Athena
- 이해 관계자가 비즈니스를 위한 주요 동인을 파악하는 데 도움을 주는 Amazon QuickSight
데이터 준비
효과적인 데이터 시각화를 구현하려면 먼저 데이터를 준비해야 합니다.
데이터 구독 및 저장
- AWS Data Exchange 콘솔에서 NinthDecimal QSR Visitation 데이터 집합을 구독합니다. AWS Data Exchange 데이터 집합을 구독하는 방법은 이 단계별 안내서를 참조하세요.
- AWS Data Exchange 콘솔의 왼쪽 메뉴에서 [구독(Subscriptions)]으로 이동하여 데이터 집합을 선택한 다음, [개정 버전(Revision)]을 찾아 사용 가능한 최신 데이터 세트 버전을 복사합니다. 원하는 자산을 선택하고 [Amazon S3로 내보내기(Export to Amazon S3)]를 선택합니다. 사전 조건 섹션에서 데이터 저장을 위해 생성한 버킷을 선택합니다. [내보내기(Export)]를 선택합니다.
분석을 위한 데이터 준비 및 로드
- 새 크롤러를 생성합니다. AWS 관리 콘솔에서 AWS Glue 콘솔을 엽니다. 탐색 창에서 [크롤러(Crawler)]를 선택합니다. [크롤러 추가(Add crawler)]를 선택하고 [크롤러 추가(Add crawler)] 마법사의 지침을 따릅니다. [데이터 스토어 추가(Add a data store)] 페이지에서 S3 버킷을 데이터 원본으로 지정합니다.
- 크롤러에 대한 Identity and Access Management(IAM) 역할을 생성합니다. AWS Glue [크롤러 추가(Add crawler)] 마법사의 [IAM 역할 선택(Choose an IAM role)]에서 크롤러에 대한 IAM 역할을 생성합니다. 이 역할은 크롤러에 S3의 데이터 집합에 대한 프로그래밍 방식 액세스 권한을 부여하고 크롤러가 분석을 위한 메타데이터를 준비할 수 있도록 합니다.
- 크롤러를 실행합니다. [크롤러 추가(Add crawler)]에서 나머지 단계를 완료하고 [마침(finish)]을 선택합니다. 그러면 AWS Glue 크롤러 홈 페이지로 리디렉션됩니다. [지금 실행하시겠습니까?(Run it now?)]를 선택합니다.
- 데이터를 수동으로 확인합니다. AWS Glue 콘솔의 왼쪽 메뉴에서 [데이터베이스(Databases)]를 선택합니다. 데이터 집합을 수동으로 확인하려면 왼쪽 메뉴에서 [데이터베이스(Database)]로 이동하여 그 아래에 있는 [테이블(Tables)]을 선택합니다. 옆에 있는 확인란을 선택하고 [데이터 보기(View data)]를 선택합니다. 그러면 Amazon Athena 콘솔로 이동합니다.
- 데이터를 검증합니다. Amazon Athena 콘솔에서는 SQL 스타일의 일회성 쿼리를 실행하여 데이터 집합을 조작하고 검증할 수 있습니다. Athena를 사용하여 데이터 집합에 있는 특성 수를 수동으로 확인하고, null 또는 누락된 값을 필터링하고, 데이터 유형을 검증하고, 데이터 형식을 확인했습니다. 예를 들어 날짜 열이 DD-MM-YYYY 형식인지 아니면 YYYY-MM-DD 형식인지 확인할 수 있습니다. 이 작업을 수행하는 방법은 다음과 같습니다.
- 특성 수 확인: 왼쪽 사이드바의 드롭다운 메뉴에서 [데이터베이스(Database)]를 선택합니다. 열을 시각화하려면 [테이블 미리 보기(Preview Table)]를 클릭합니다.
- null 또는 누락된 값을 검증합니다.
- 예: SELECT * FROM “cubiq-sales-grocery”.”cubiq_sales_grocery_data” where col1 = null;
- 데이터 형식 확인: 단계에 따라 각 열 또는 특성의 데이터 유형을 확인합니다.
데이터 시각화 생성
- AWS 관리 콘솔에서 QuickSight로 이동합니다.
- QuickSight, S3 및 AWS Glue가 모두 동일한 리전을 사용하고 있는지 확인합니다. 이렇게 하려면 오른쪽 상단에서 [리전(Region)]을 선택합니다.
- 새 시각화를 만듭니다. QuickSight 콘솔 왼쪽 상단에서 [새 분석(New analysis)]을 선택한 다음 [새 데이터 집합(New dataset)]을 선택합니다.
- [데이터 집합 생성(Create a dataset)]의 콘솔에 표시된 데이터 원본 목록에서 데이터 원본으로 [Amazon Athena]를 선택합니다.
- 마법사의 지시에 따라 [데이터 원본 이름(Data source name)]을 입력한 다음 [연결(Connect)]을 클릭합니다. [테이블 선택(Choose your table)]에서 분석을 위해 데이터를 준비하고 로드하는 동안 Glue 크롤러를 통해 생성한 [데이터베이스(Database)]를 선택합니다. 마법사에서 [시각화(Visualize)]를 선택합니다.
- [시각화 유형(Visual types)]에서 원하는 시각화 유형을 선택합니다. 여기서는 막대 그래프, 산점도 및 선 그래프를 사용합니다.
- [필드 목록(Fields list)]에서 시각화할 필드를 선택합니다.
시각화 예제
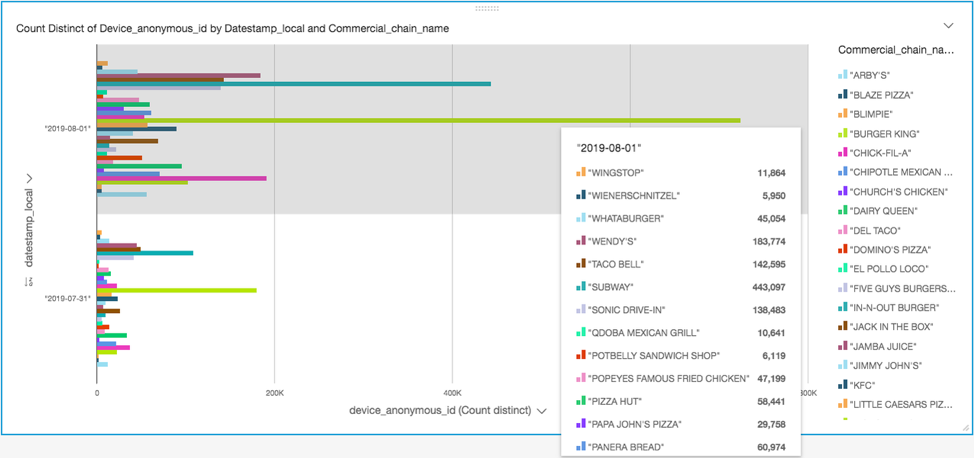
예제 1: 인기 있는 패스트푸드 체인 레스토랑은 어느 요일에 더 바쁩니까?
이전 단계를 이용하여 답변한 비즈니스 사용 사례입니다. 인기 있는 레스토랑 체인은 수요일과 목요일 중 어느 요일이 더 바쁠까요?
이 질문에 답하기 위해 인기 있는 레스토랑 체인의 그룹이 포함된 막대 차트를 만들어 9월 31일(수요일)의 데이터를 10월 1일(목요일)과 비교했습니다. 다음 막대 차트는 목요일이 더 바쁜 요일이었음을 보여줍니다.
이 시각화를 복제하려면 데이터 시각화 생성의 3단계에서 아래의 단계를 따릅니다.
- 메뉴 드롭다운에서 [시각화 복제(Duplicate visual)]를 선택합니다.
- [시각화 유형(Visual types)]에서 [가로 막대 차트(Horizontal bar chart)]를 선택합니다.
- [필드 목록(Fields list)]의 [X축(X axis)]에 대해 device_anonymous_id를 선택하고 [Y축(Y axis)]에 대해 datestamp_local을 선택합니다.
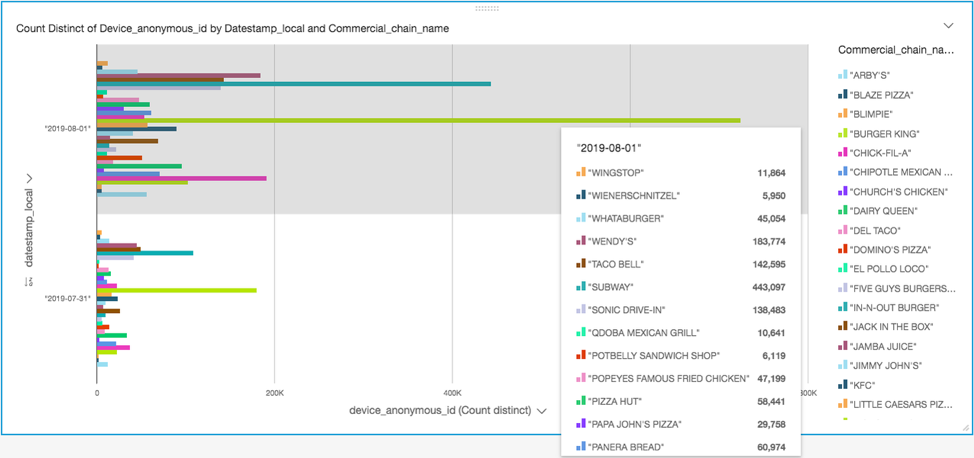
예제 2: 어느 인기 패스트 푸드 레스토랑 체인의 방문객 수가 가장 많습니까?
동일한 레스토랑 방문 데이터 집합을 사용하여 방문객 수가 가장 많은 커머셜 체인을 식별할 수 있습니다.
레스토랑 체인 이름을 그룹화하고 색상을 코딩하기 위해 산점도 시각화 요소를 만들었습니다. 이를 위해 X축의 [디바이스 익명 ID(Device anonymous id)] 필드와 Y축의 [날짜 스탬프(Datestamp)] 필드를 사용했습니다. 그러면 다음과 같은 시각화가 생성됩니다.
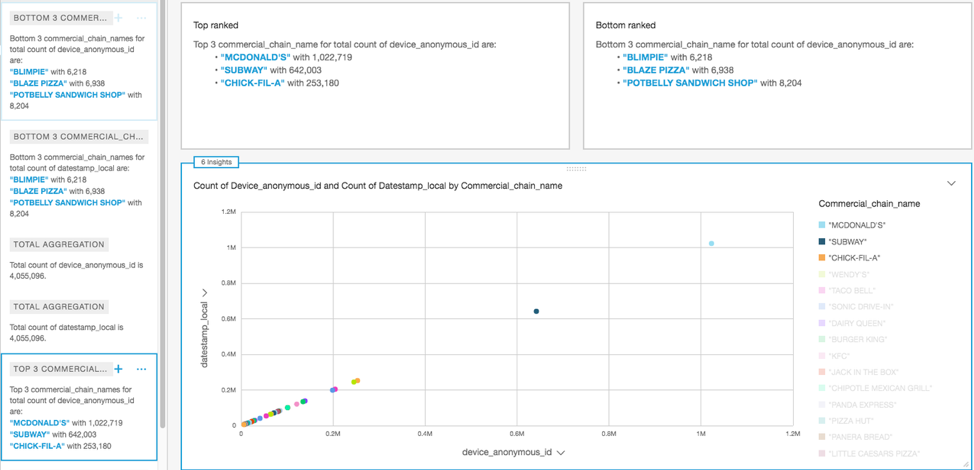

이 시각화를 복제하려면 데이터 시각화 생성의 3단계에서 다음과 같이 합니다.
- 메뉴 드롭다운에서 [시각화 복제(Duplicate visual)]를 선택합니다.
- [시각화 유형(Visual types)]에서 [산점도(Scatter graph)]를 선택합니다.
- [필드 목록(Fields list)]의 [X축(X axis)]에 대해 device_anonymous_id를 선택하고 [Y축(Y axis)]에 대해 datestamp_local을 선택합니다.
Tip: 자신만의 인사이트 구축
산점도 시각화의 왼쪽 상단에는 자동화된 인사이트가 제공된다는 점에 유의하십시오. QuickSight는 내장된 기계 학습 알고리즘을 기반으로 인사이트를 자동으로 준비합니다. 또한 자신만의 인사이트를 구축하도록 선택할 수도 있습니다. 이렇게 하려면 다음을 수행합니다.
- QuickSight의 상단 탐색 메뉴에서 [추가(Add)]를 선택합니다.
- 시각화 요소에 추가할 수 있는 각 인사이트에 대한 간략한 설명이 왼쪽에 표시됩니다. 추가할 인사이트 옆에 있는 더하기 기호(+)를 선택합니다.
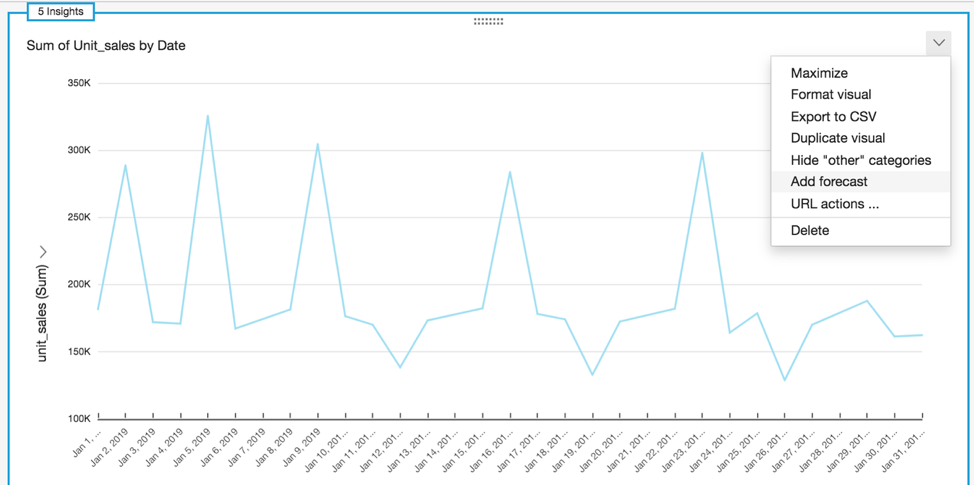
예제 3: 판매 이상치 찾기
영업 주기에서 흔히 볼 수 있는 시나리오는 일정 기간 동안 판매의 이상치를 식별하는 것입니다. 비즈니스, 영업, 마케팅 및 조달 부문의 이해 관계자는 향후 전략 계획 수립 시에 고려하기 위해 영업 주기의 과거 이상치를 분석합니다. 판매 이상치를 날짜별로 다음과 같이 시각화했습니다.
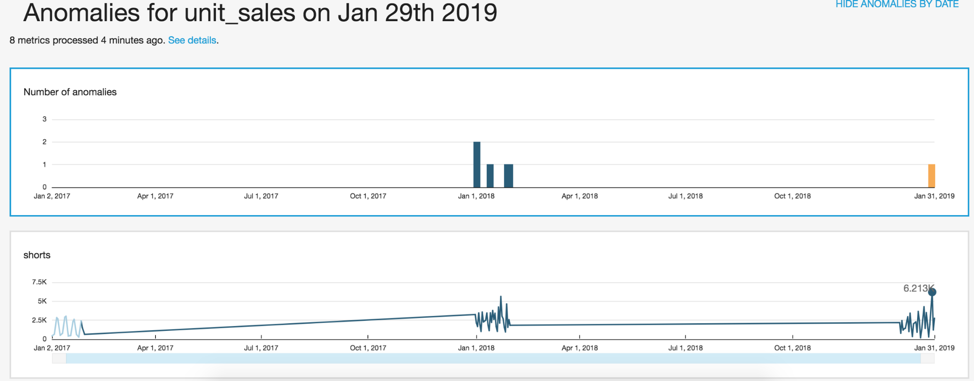

- 이 시각화를 준비하기 위해 먼저 시간 필드 웰에 차원이 하나 이상 있고 값 필드 웰에 측정값이 하나 이상 있고 범주 필드 웰에 차원이 하나 이상 있는 AWS Data Exchange 판매 데이터 집합을 찾았습니다. 이 데이터 집합을 구독했습니다.
- 그런 다음 나머지 단계에 따라 데이터 준비 및 데이터 시각화 생성 작업을 수행했습니다. 데이터 시각화 생성의 3c단계에서 다음을 수행합니다.
- QuickSight 콘솔의 [시각화 유형(Visual types)]에서 [인사이트(Insight)]를 선택합니다.
- [계산(Computation)] 드롭다운 메뉴에서 [인사이트 사용자 지정(Customize insight)], [이상치 감지(Anomaly detection)]를 차례로 선택합니다.
- [필드 목록(Fields list)]에서 [날짜(Date)], [판매 수량(Unit sales)] 및 [범주(Category)]를 선택한 후 [적용(Apply)]을 선택합니다.
- 시각화 요소에는 그래프 아래에 날짜 범위 선택 스크롤 막대가 있습니다. 이 막대를 드래그하여 날짜 범위를 조정합니다.
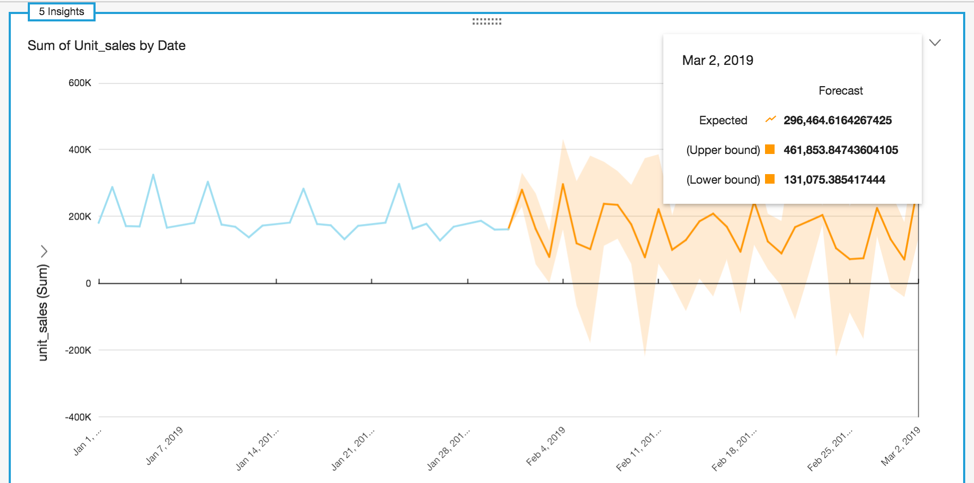
예제 4: 과거 데이터를 기반으로 한 예측
다음 스크린샷은 QuickSight 기계 학습 예측 기능을 사용하여 시각화한 향후 30일 동안의 예측 판매 수량을 보여 줍니다.

이 레스토랑 데이터 집합을 사용하여 과거 데이터에서 예측을 생성하려면 다음을 수행합니다.
- 데이터 시각화 생성의 3c단계에서 왼쪽 메뉴의 사용 가능한 [시각화 유형(Visual types)]에서 [선형 차트(Line chart)]를 선택합니다.
- [X축(X axis)]에 대해 날짜(Date) 필드를 선택하고 [Y축(Y axis)]에 대해 Unit_Sales 필드를 선택합니다. 이전 스크린샷에서 보듯이 시각화는 왼쪽 상단에 표시되는 ML insights를 자동으로 생성합니다.푸시 그룹(Push Groups)
- 오른쪽 상단의 화살표를 선택하여 드롭다운 메뉴를 엽니다. [예측 추가(Add forecast)]를 선택합니다. 이렇게 하면 과거 데이터를 기반으로 예측이 추가됩니다.

이 블로그 게시물에서는 AWS Data Exchange에서 제공되는 데이터 집합을 사용하여 Amazon QuickSight에서 시각화를 구축하는 방법을 살펴보았습니다. 비즈니스 질문에 답하는 시각화 요소를 만드는 방법을 보여 드렸습니다. 즉, 어느 요일이 더 바쁜지, 어느 레스토랑이 가장 손님이 많은지, 판매 이상치는 어디에서 나타나는지, 판매 예측은 어떻게 되는지 등을 파악하는 방법을 알아보았습니다.
AWS Data Exchange에 대한 자세한 내용은 여기를 참조하십시오. QuickSight에 대한 자세한 내용은 Amazon QuickSight를 참조하십시오.
– Pranabesh Mandal, AWS 솔루션스 아키텍트
– Mohsen Malik, AWS Data Exchange 글로벌 부문 리더
이 글은 AWS Marketplace 블로그 Data visualization in AWS using AWS Data Exchange and Amazon QuickSight의 한국어 번역입니다.
Source: AWS Data Exchange 및 Amazon QuickSight를 사용한 AWS의 데이터 시각화