


AWS DataSync, 추가 클라우드 스토리지 위치로 이전 기능 제공

AWS DataSync를 사용하면 AWS Storage 서비스와 주고받는 데이터 이동을 자동화하고 가속할 수 있습니다. 예를 들어 DataSync를 사용하여 데이터를 AWS로 마이그레이션하고, 비즈니스 연속성을 위해 데이터를 복제하고, 클라우드에서 분석 및 처리를 위해 데이터를 이동할 수 있습니다. DataSync를 사용하여 Amazon Simple Storage Service(S3), Amazon Elastic File System(Amazon EFS) 및 Amazon FSx를 포함한 AWS Storage 서비스와 데이터를 주고받을 수 있습니다. 또한 DataSync는 로깅, 모니터링 및 알림을 위해 Amazon CloudWatch 및 AWS CloudTrail과 통합됩니다.
오늘 DataSync에 AWS Storage 서비스와 Google Cloud Storage 또는 Microsoft Azure Files 간에 데이터를 마이그레이션하는 기능을 추가했습니다. 이러한 방식을 통해 데이터 처리 또는 스토리지 통합 작업을 간소화할 수 있습니다. 또한 Google Cloud Storage 또는 Microsoft Azure Files를 사용하는 고객, 공급업체 또는 파트너와 데이터를 가져오고 공유하고 교환해야 하는 경우에도 유용합니다. DataSync는 암호화 및 무결성 검증을 포함한 엔드 투 엔드 보안을 제공하여 데이터가 안전하고 도착하고 손상되지 않아 즉시 사용할 수 있도록 보장합니다.
실제로 어떻게 작동하는지 알아보겠습니다.
DataSync 에이전트 준비
먼저 Google Cloud Storage 또는 Azure Files에 있는 스토리지에서 읽거나 쓸 DataSync 에이전트가 필요합니다. Amazon Elastic Compute Cloud(Amazon EC2) 인스턴스에 에이전트를 배포합니다. 최신 DataSync Amazon Machine Image(AMI) ID는 AWS Systems Manager의 기능인 Parameter Store에 저장됩니다. AWS Command Line Interface(AWS CLI)를 사용하여 /aws/service/datasync/ami 파라미터의 값을 가져옵니다.
{
"Parameter": {
"Name": "/aws/service/datasync/ami",
"Type": "String",
"Value": "ami-0e244fe801cf5a510",
"Version": 54,
"LastModifiedDate": "2022-05-11T14:08:09.319000+01:00",
"ARN": "arn:aws:ssm:us-east-1::parameter/aws/service/datasync/ami",
"DataType": "text"
}
}EC2 콘솔을 사용하여 파라미터의 값(value) 속성에 지정된 AMI ID를 사용하여 EC2 인스턴스를 시작합니다. 네트워킹의 경우 퍼블릭 서브넷과 퍼블릭 IP 주소를 자동 할당하는 옵션을 사용합니다. EC2 인스턴스는 데이터 이동 작업의 소스와 대상 모두에 대한 네트워크 액세스가 필요합니다. 인스턴스에 대한 또 다른 요구 사항은 DataSync에서 HTTP 트래픽을 수신하여 에이전트를 활성화할 수 있어야 한다는 것입니다.
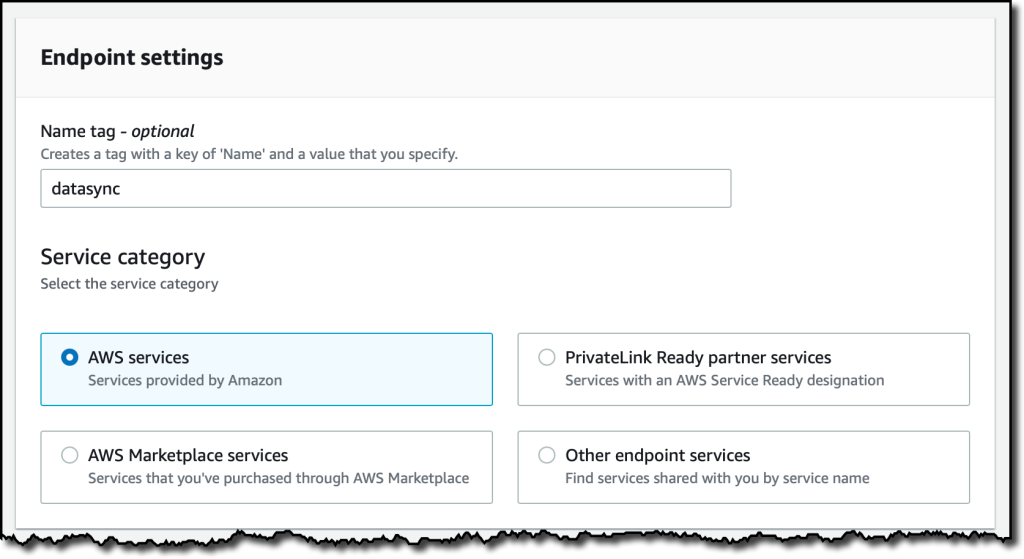
Amazon VPC 서비스를 기반으로 하는 Virtual Private Cloud(VPC) 에서 AWS DataSync를 사용하는 경우 VPC 엔드포인트를 사용하여 에이전트를 DataSync 서비스에 연결하는 것이 모범 사례입니다. VPC 콘솔(VPC console)의 탐색 창에서 엔드포인트(Endpoints)를 선택한 다음 엔드포인트 생성(Create endpoint)을 선택합니다. 엔드포인트의 이름을 입력하고 AWS 서비스(AWS services) 범주를 선택합니다.
서비스(Services) 섹션에서 DataSync를 찾습니다.

그런 다음 EC2 인스턴스를 시작한 곳과 동일한 VPC를 선택합니다.

교차 AZ 트래픽을 줄이기 위해 EC2 인스턴스에 사용되는 것과 동일한 서브넷을 선택합니다.

EC2 인스턴스에서 실행되는 DataSync 에이전트는 VPC 엔드포인트에 대한 네트워크 액세스가 필요합니다. 간단하게 하기 위해 두 가지 모두에 VPC의 기본 보안 그룹(default security group of the VPC)을 사용합니다. VPC 엔드포인트를 생성하면 몇 분 후에 사용할 준비가 끝납니다.

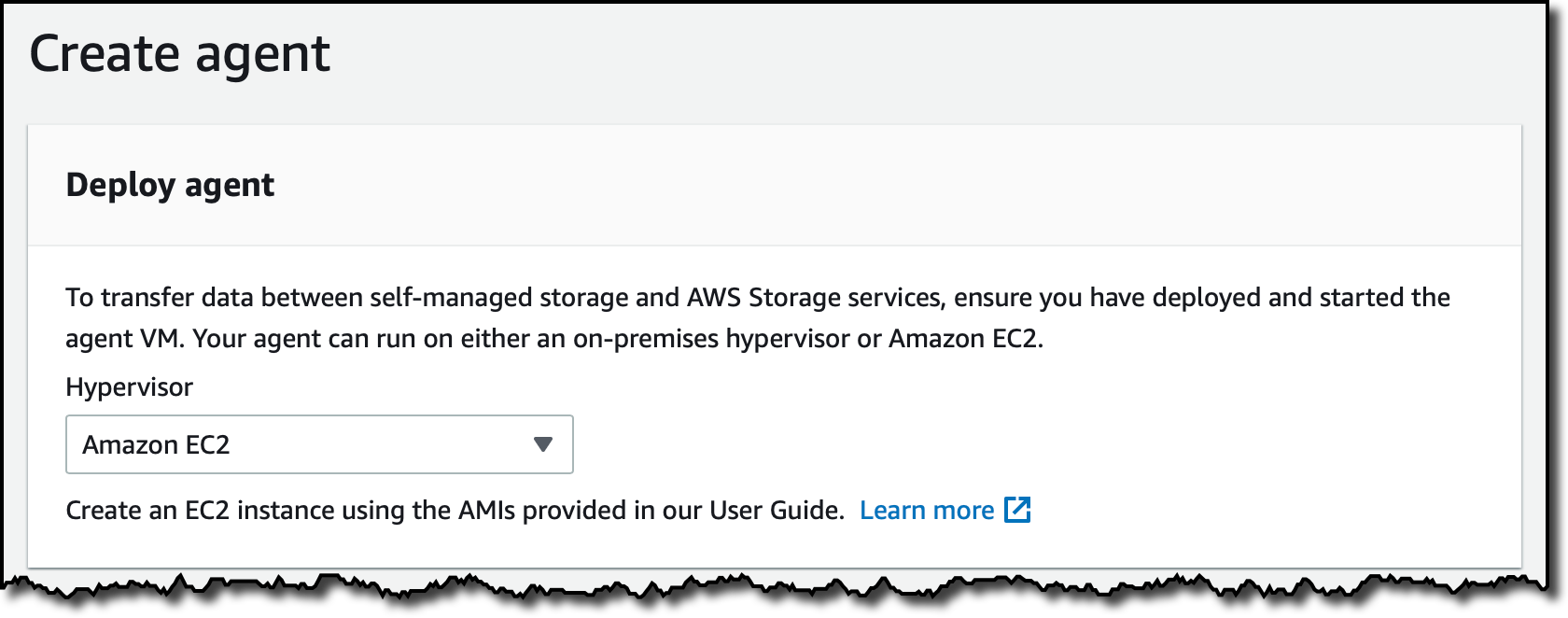
AWS DataSync 콘솔(AWS DataSync console)의 탐색 창에서 에이전트(Agents)를 선택한 다음 에이전트 생성(Create agent)을 선택합니다. 하이퍼바이저(Hypervisor)로 Amazon EC2를 선택합니다.
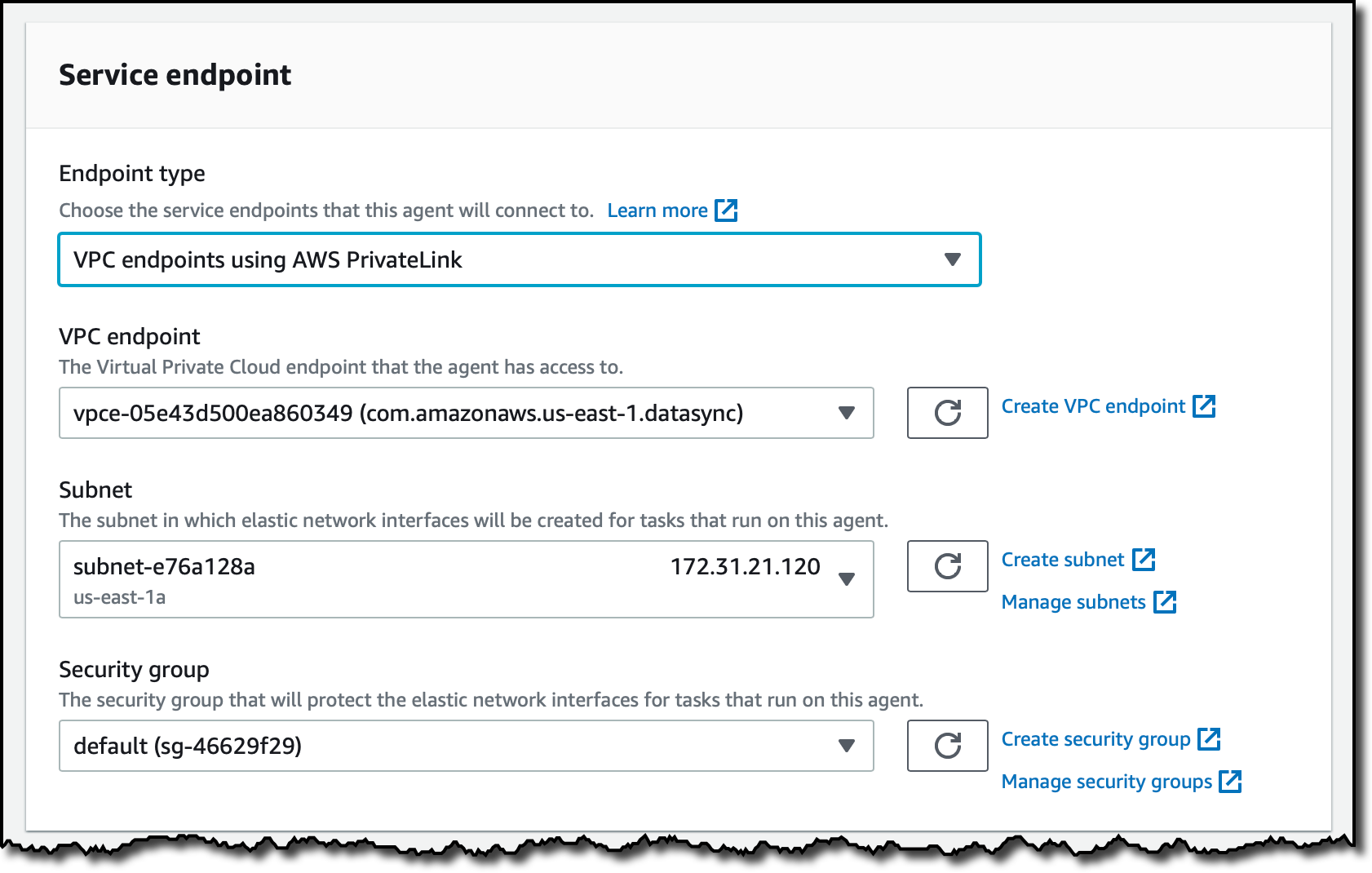
엔드포인트 유형(ndpoint type)으로 AWS PrivateLink를 사용하는 VPC 엔드포인트(VPC endpoints using AWS PrivateLink)를 선택합니다. 이전에 생성한 VPC 엔드포인트(VPC endpoint)와 VPC 엔드포인트에 사용한 것과 동일한 서브넷(Subnet) 및 보안 그룹(Security group)을 선택합니다.
자동으로 활성화 키 가져오기(Automatically get the activation key) 옵션을 선택하고 EC2 인스턴스의 퍼블릭 IP를 입력합니다. 그런 다음 키 가져오기(Get key)를 선택합니다.

DataSync 에이전트가 활성화되면 더 이상 HTTP 액세스가 필요하지 않으므로 EC2 인스턴스의 보안 그룹에서 이를 제거합니다. 이제 DataSync 에이전트가 활성화되었으므로 데이터를 이동하도록 작업 및 위치를 구성할 수 있습니다.
Google Cloud Storage에서 Amazon S3로 데이터 이동
Google Cloud Storage 버킷에 이미지가 몇 개 있는데 이러한 파일을 S3 버킷과 동기화하고 싶습니다. Google Cloud 콘솔에서 버킷의 설정을 엽니다. 여기서 Storage Object Viewer 권한을 가진 서비스 계정을 생성하고 보안 인증 정보(액세스 키 및 암호)를 기록하여 버킷에 프로그래밍 방식으로 액세스합니다.
AWS DataSync 콘솔로 돌아가서 작업(Tasks)을 선택한 다음 작업 생성(Create task)을 선택합니다.
작업의 소스를 구성하기 위해 위치를 생성합니다. 위치 유형(Location type)으로 객체 스토리지(Object storage)를 선택하고 방금 생성한 에이전트를 선택합니다. 서버(Server)의 경우 storage.googleapis.com을 사용합니다. 그런 다음 Google Cloud 버킷의 이름과 이미지가 저장된 폴더를 입력합니다.

인증을 위해 서비스 계정을 생성할 때 검색한 액세스 키와 암호를 입력합니다. 다음(Next)을 선택합니다.

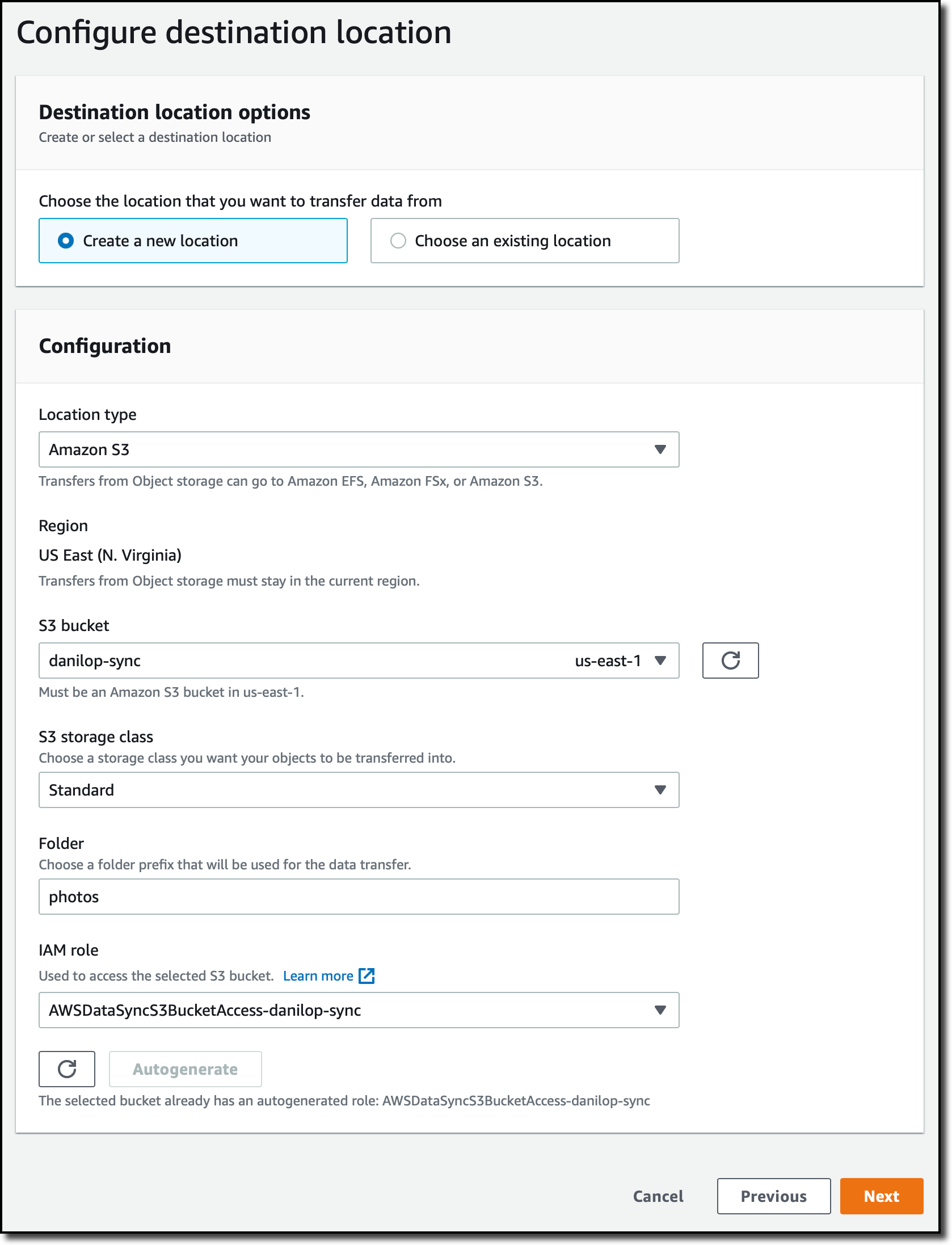
작업의 대상을 구성하기 위해 다른 위치를 생성합니다. 이번에는 위치 유형(Location Type)으로 Amazon S3를 선택하겠습니다. 대상 S3 버킷을 선택하고 버킷으로 전송된 파일의 접두사(prefix)로 사용할 폴더를 입력합니다. 자동 생성(Autogenerate) 버튼을 사용하여 S3 버킷에 액세스할 수 있는 DataSync 권한을 부여할 IAM 역할(IAM role)을 생성합니다.
다음 단계에서는 작업 설정을 구성합니다. 작업 이름을 입력합니다. 필요한 경우 DataSync가 전송된 데이터의 무결성을 확인하는 방법을 미세 조정하거나 작업에 대역폭을 할당할 수 있습니다.
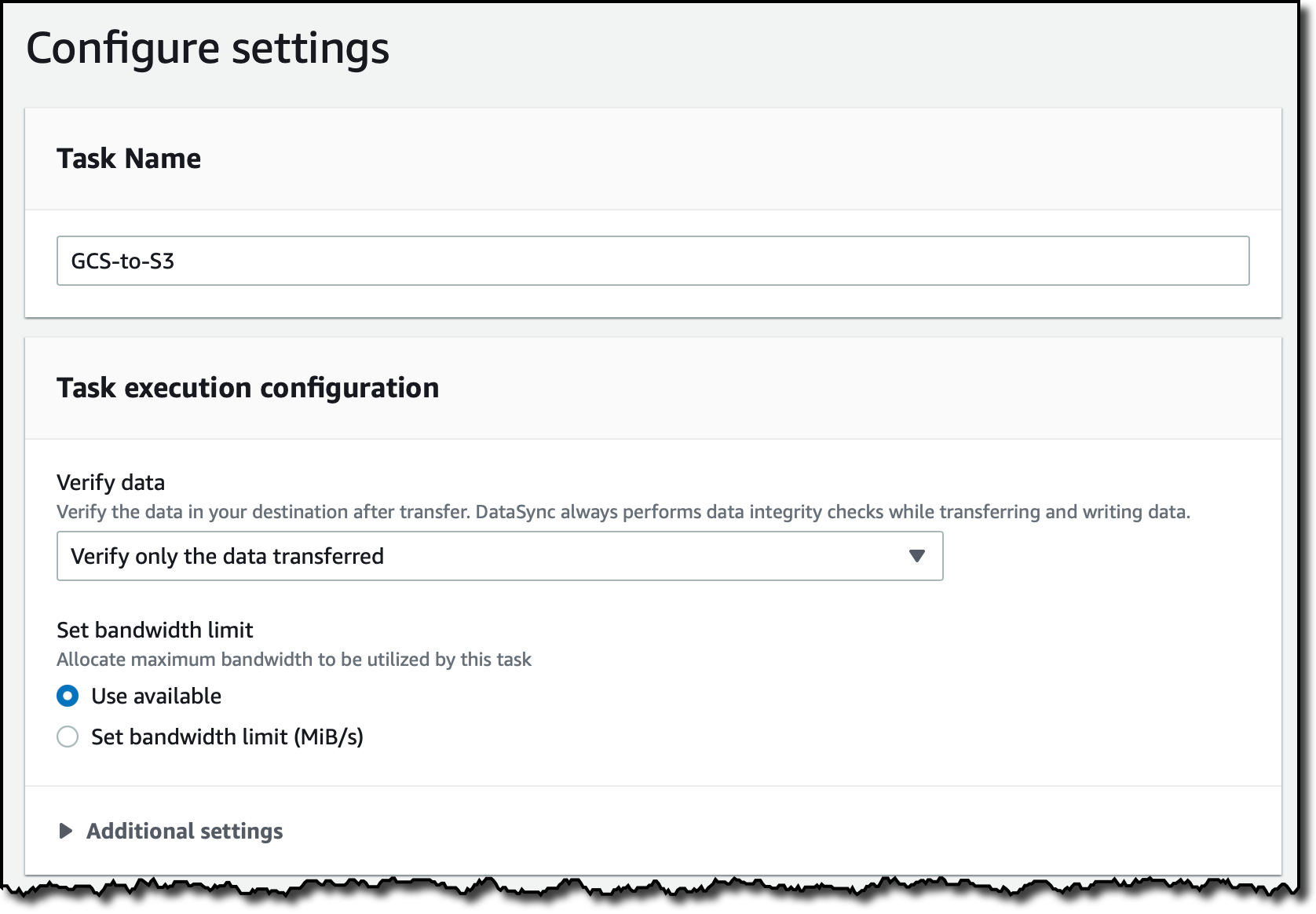
스캔할 데이터와 전송할 데이터를 선택할 수도 있습니다. 기본적으로 모든 소스 데이터가 스캔되고 변경된 데이터만 전송됩니다. 추가 설정(Additional settings)에서 현재 Google Cloud Storage에서 태그가 지원되지 않으므로 객체 태그 복사(Copy object tags)를 사용 중지합니다.

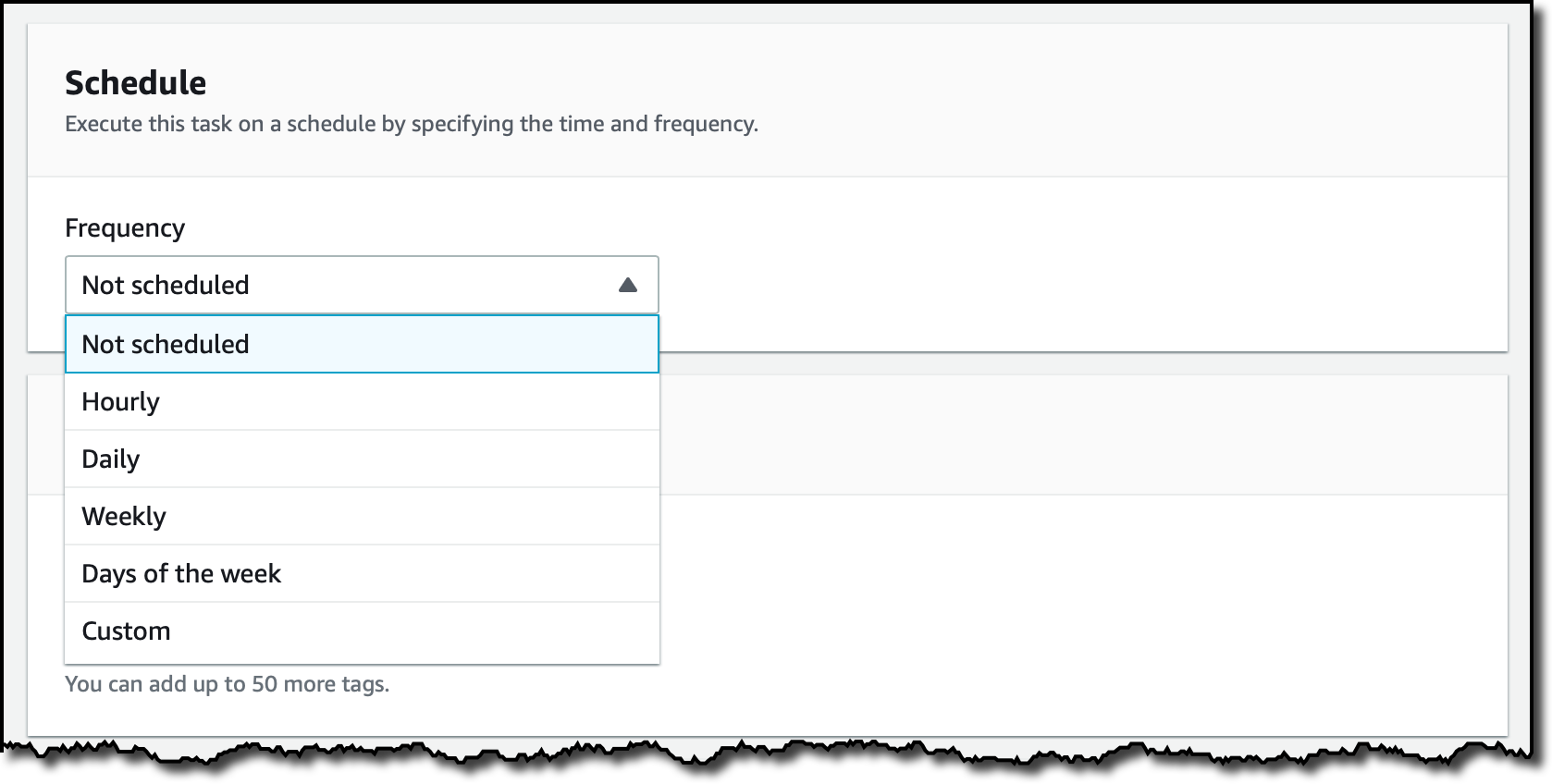
이 작업을 실행하는 데 사용할 일정을 선택할 수 있습니다. 지금은 예정되지 않음(Not scheduled) 상태로 두고 수동으로 시작하겠습니다.
로깅의 경우 자동 생성(Autogenerate) 버튼을 사용하여 DataSync에 대한 로그 그룹을 생성합니다. 다음(Next)을 선택합니다.

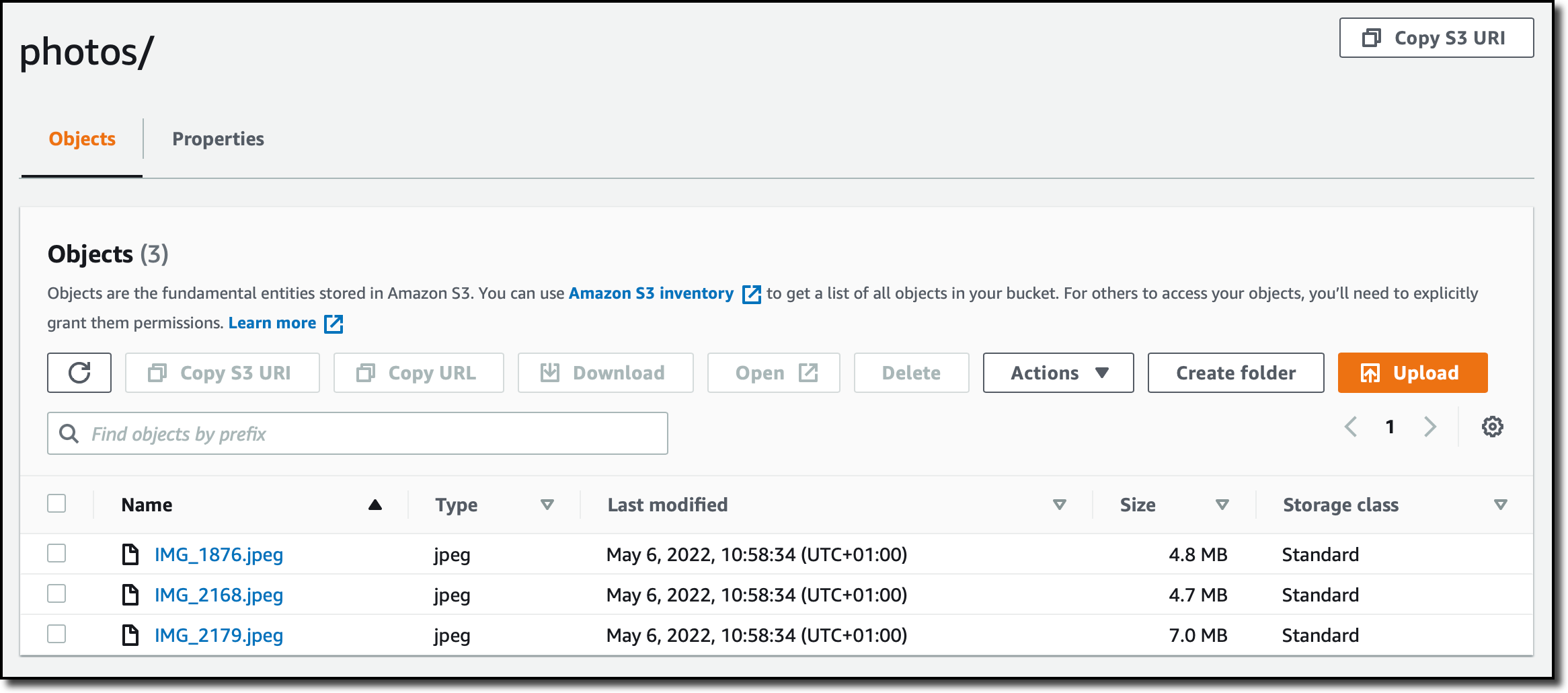
구성을 검토하고 작업을 생성합니다. 이제 콘솔에서 데이터 이동 작업을 시작합니다. 몇 분 후 파일이 S3 버킷과 동기화되고 S3 콘솔(S3 console)에서 파일에 액세스할 수 있습니다.
Azure Files에서 Amazon FSx for Windows File Server로 데이터 이동
찍은 사진이 많이 있고, Azure 파일 공유에 이미지도 몇 개 있습니다. 이러한 파일을 Amazon FSx for Windows 파일 시스템과 동기화하고 싶습니다. Azure 콘솔에서 파일 공유를 선택하고 연결(Connect) 버튼을 선택하여 네트워크를 통해 이 스토리지 계정에 액세스할 수 있는지 확인하는 PowerShell 스크립트를 생성합니다.
이 스크립트에서 DataSync 위치를 구성하는 데 필요한 정보를 가져옵니다.
- SMB 서버
- 공유 이름
- 사용자
- 암호
AWS DataSync 콘솔로 돌아가서 작업(Tasks)을 선택한 다음 작업 생성(Create task)을 선택합니다.
작업의 소스를 구성하기 위해 위치를 생성합니다. 위치 유형(Location Type) 및 이전에 생성한 에이전트로 Server Message Block(SMB)을 선택합니다. 그런 다음 스크립트에서 찾은 정보를 사용하여 인증에 사용할 SMB 서버(SMB Server) 주소, 공유 이름(Share name) 및 사용자(User)/암호(Password)를 입력합니다.
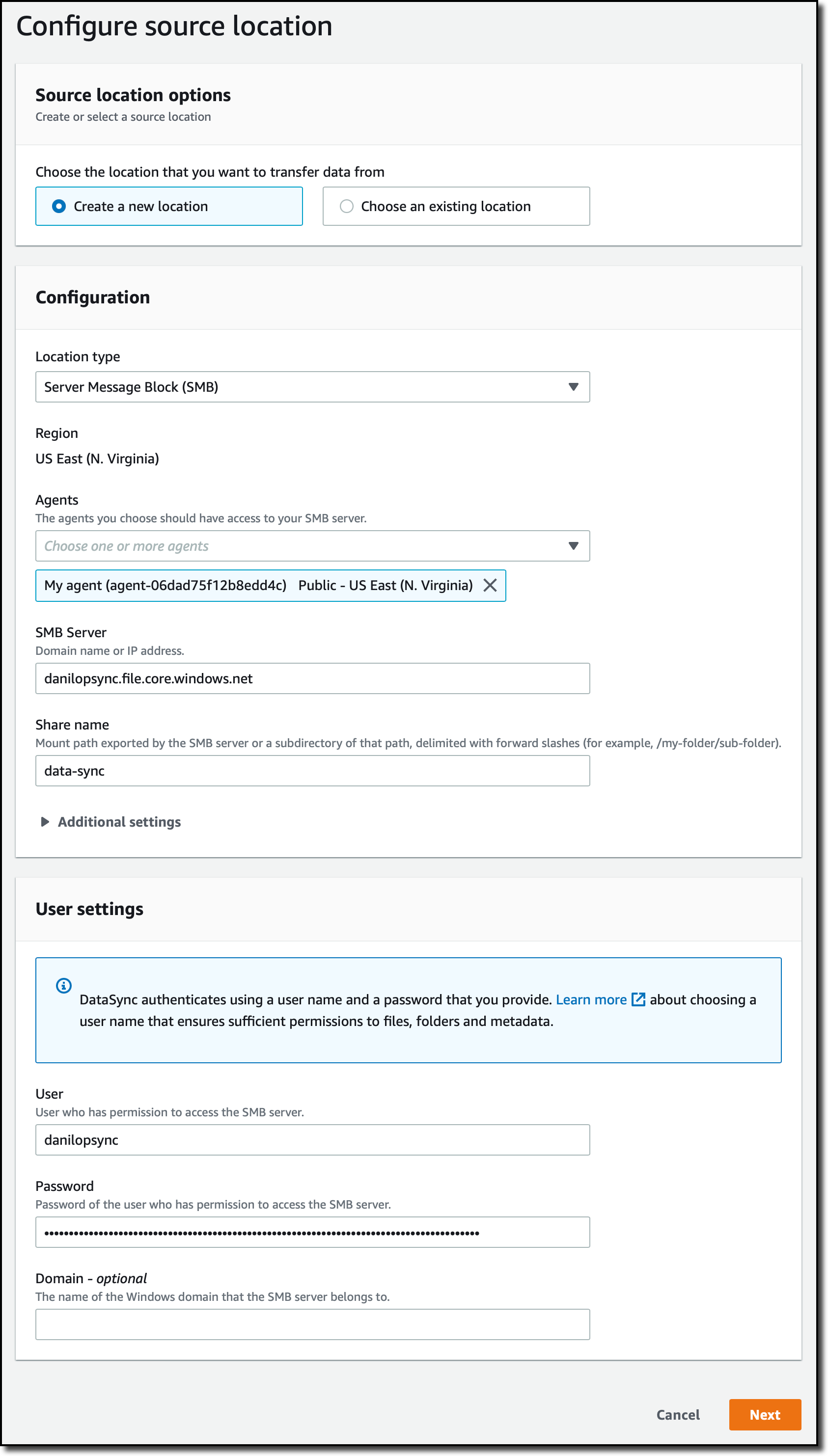
작업의 대상을 구성하기 위해 위치를 다시 생성합니다. 이번에는 위치 유형(Location type)으로 Amazon FSx를 선택합니다. 이전에 만든 FSx for Windows 파일 시스템을 선택하고 기본 공유 이름을 사용합니다. 기본 보안 그룹(default security group)을 사용하여 파일 시스템에 연결합니다. FSx for Windows File Server와 함께 AWS Directory Service for Microsoft Active Directory를 사용하고 있기 때문에 AWS Delegated FSx Administrators 및 도메인 관리자(Domain Admins) 그룹의 사용자 구성원의 보안 인증 정보를 사용합니다. 자세한 내용은 설명서의 FSx for Windows File Server용 위치 생성(Creating a location for FSx for Windows File Server)을 참조하세요.

다음 단계에서는 작업의 이름을 입력하고 다른 모든 옵션은 이전 작업과 동일한 방식으로 기본값으로 둡니다.
구성을 검토하고 작업을 생성합니다. 이제 콘솔에서 데이터 이동 작업을 시작합니다. 몇 분 후 파일이 FSx for Windows 파일 시스템 공유와 동기화됩니다. Windows EC2 인스턴스와 함께 파일 시스템 공유를 탑재하고 이미지가 거기에 있는지 확인합니다.

작업을 생성할 때 기존 위치를 재사용할 수 있습니다. 예를 들어 Azure Files의 파일을 S3 버킷으로 동기화하려는 경우 이 게시물에 대해 생성한 두 개의 해당 위치를 빠르게 선택할 수 있습니다.
가용성 및 요금
AWS DataSync 콘솔, AWS Command Line Interface(AWS CLI) 또는 AWS SDK를 사용하여 데이터를 이동하여 AWS 스토리지와 Google Cloud Storage 버킷 또는 Azure Files 파일 시스템 간에 데이터를 이동하는 작업을 생성할 수 있습니다. 작업이 실행되는 동안 DataSync 콘솔에서 또는 CloudWatch를 사용하여 진행 상황을 모니터링할 수 있습니다.
이러한 새로운 기능으로 DataSync 가격이 변경되지는 않습니다. Google Cloud 또는 Microsoft Azure와의 데이터 이동에는 현재 DataSync에서 지원하는 다른 모든 데이터 소스와 동일한 요금이 부과됩니다.
Google Cloud 또는 Microsoft Azure의 데이터 전송 요금이 부과될 수 있습니다. DataSync는 에이전트와 AWS 간에 복사할 때 전송 중인 데이터를 압축하기 때문에 Google Cloud 또는 Microsoft Azure 환경에 DataSync 에이전트를 배포하여 송신 요금을 줄일 수 있습니다.
DataSync를 사용하여 AWS에서 Google Cloud 또는 Microsoft Azure로 데이터를 이동하는 경우 EC2에서 인터넷으로의 데이터 전송에 대한 요금이 부과됩니다. 자세한 내용은 Amazon EC2 요금을 참조하세요.
AWS DataSync를 사용하여 데이터를 이동하는 방식을 자동화하고 가속할 수 있습니다.
— Danilo
Source: AWS DataSync, 추가 클라우드 스토리지 위치로 이전 기능 제공