


AWS Entity Resolution 정식 출시 – 앱 및 데이터 스토어 관련 레코드 매칭 워크플로 서비스


기업이 성장하면 고객, 비즈니스 또는 제품에 대한 정보가 포함된 레코드는 애플리케이션, 채널 및 데이터 스토어 전반에서 갈수록 세분화되고 사일로화되는 경향이 있습니다. 정보는 다양한 방식으로 수집되기 때문에 도로명 주소(‘5번가’ 및 ‘5가’)와 같이 서로 다르지만 의미상 동일한 데이터가 발생하는 문제도 있습니다. 따라서 관련 레코드를 서로 연결하여 통합된 보기를 만들고 더 나은 인사이트를 도출하기가 쉽지 않습니다.
예를 들어, 기업은 광고 캠페인을 운영하여 개인화된 메시징을 통해 여러 애플리케이션 및 채널에서 소비자에게 다가가고자 합니다. 기업은 불완전하거나 서로 상충되는 정보가 포함된 여러 이질적인 데이터 레코드를 처리해야 하는 경우가 많기 때문에 매칭 프로세스가 어려워집니다.
소매 업계에서 기업은 공급망과 매장 전반에서 재고 관리 단위(SKU), 범용 제품 코드(UPC), 전용 코드 등 이질적인 여러 제품 코드를 사용하는 제품을 매칭해야 합니다. 따라서 정보를 종합적으로 신속하게 분석할 수 없습니다.
이 문제를 해결하는 방법 하나는 여러 데이터베이스와 상호 작용하는 복잡한 SQL 쿼리와 같은 맞춤형 데이터 해결 솔루션을 구축하거나, 레코드 매칭을 수행하도록 기계 학습(ML) 모델을 훈련하는 것입니다. 하지만 이러한 솔루션은 구축하는 데 몇 달이 걸리고 개발 리소스가 필요하며 유지 관리 비용이 많이 듭니다.
이 문제를 해결해줄 솔루션으로서, 오늘 저희는 여러 애플리케이션, 채널 및 데이터 스토어에 저장된 관련 레코드를 서로 매칭하고 연결하는 데 유용한 ML 기반 서비스, AWS Entity Resolution을 소개합니다. 유연하고 확장 가능하며 기존 애플리케이션에 원활하게 연결되는 엔터티 해결 워크플로를 몇 분 만에 구성할 수 있습니다.

AWS Entity Resolution은 규칙 기반 매칭 및 기계 학습 모델과 같은 고급 매칭 기술을 제공하여, 관련 고객 정보, 제품 코드 또는 비즈니스 데이터 코드를 정확하게 연결하는 데 도움을 줍니다. 예를 들어 AWS Entity Resolution을 사용하면 최근 이벤트(예: 광고 클릭, 장바구니 방치, 구매)를 고유한 엔터티 ID에 연결하여 고객 상호 작용에 대한 통합 보기를 생성하거나, 매장 전반에서 서로 다른 코드(예: SKU 또는 UPC)를 사용하는 제품을 보다 효과적으로 추적할 수 있습니다.
AWS Entity Resolution을 사용하면 레코드가 상주하는 위치에서 레코드를 읽기 때문에, 데이터 이동을 최소화하면서 매칭 정확도를 높이고 데이터 보안을 강화할 수 있습니다. 이제 실제 작동 방식을 살펴보겠습니다.
AWS Entity Resolution 시작하기
분석 플랫폼의 일부로서, 백만 명의 가상 고객이 수록된 쉼표로 구분된 값(CSV) 파일이 Amazon Simple Storage Service(S3) 버킷에 저장되어 있습니다. 이들 고객에 대한 정보는 로열티 프로그램에서 가져온 것이지만, 다양한 채널(온라인, 매장, 우편)을 통해 신청한 경우에는 동일한 고객과 관련한 레코드가 여러 개 존재할 수 있습니다.
CSV 파일의 데이터 형식은 다음과 같습니다.
이 예에서는 AWS Glue 크롤러를 사용하여 파일의 내용을 자동으로 판단하고, 분석 작업에 사용할 수 있도록 데이터 카탈로그의 메타데이터 테이블이 계속 업데이트되게 합니다. 이제 AWS Entity Resolution에서 동일한 설정을 사용할 수 있습니다.
AWS Entity Resolution 콘솔에서 Get Started(시작하기)를 선택하여 매칭 워크플로를 설정하는 방법을 살펴봅니다.

매칭 워크플로를 생성하려면 먼저 스키마 매핑을 사용하여 데이터를 정의해야 합니다.

Create schema mapping(스키마 매핑 생성)을 선택하고 이름과 설명을 입력한 다음 AWS Glue에서 스키마를 가져오는 옵션을 선택합니다. 단계별 흐름이나 JSON 편집기를 사용하여 사용자 지정 스키마를 정의할 수도 있습니다.
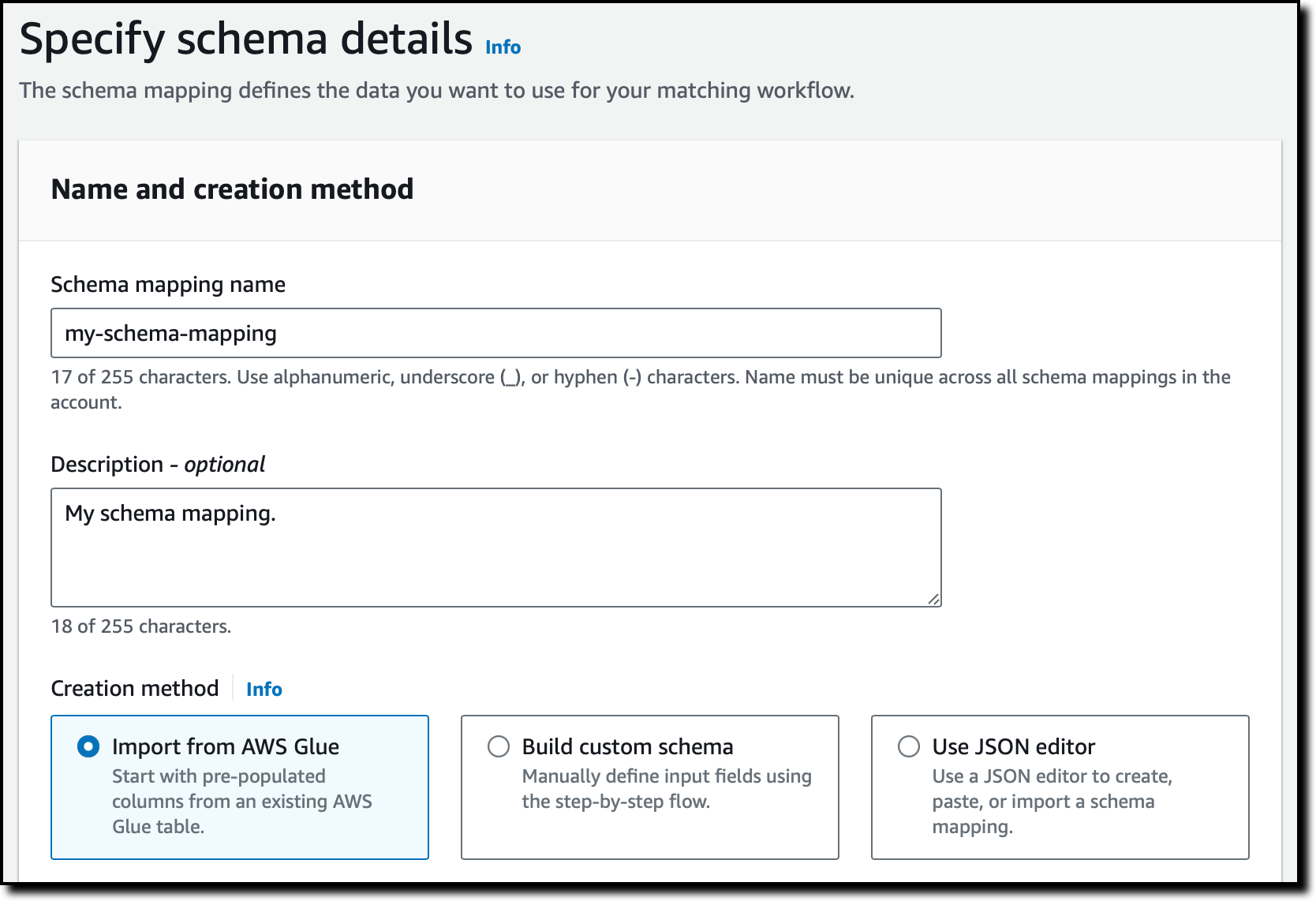
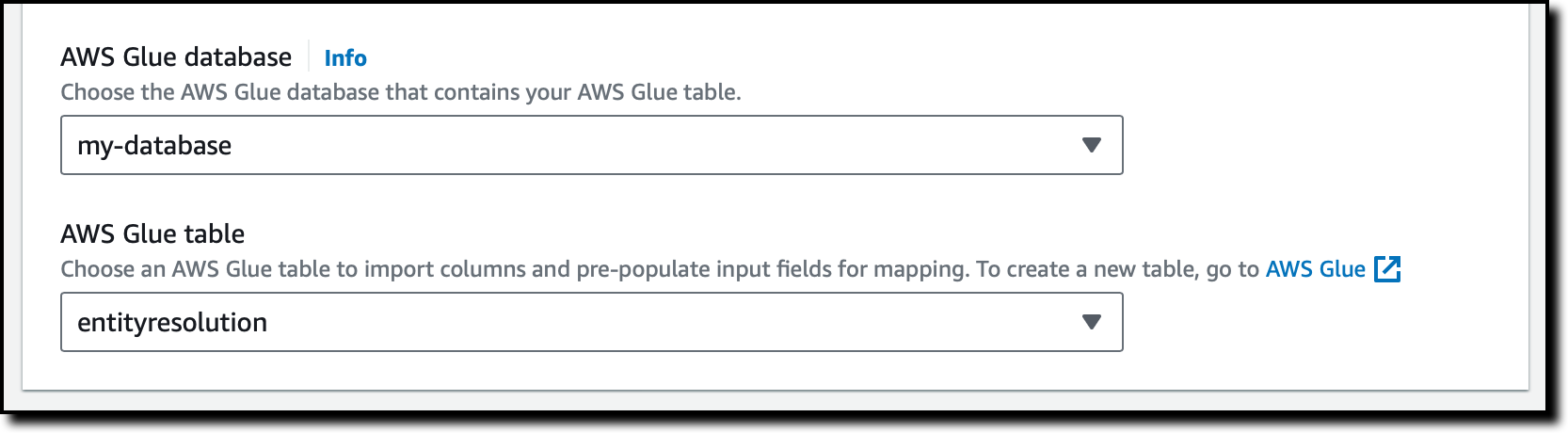
두 드롭다운에서 AWS Glue 데이터베이스와 테이블을 선택하여, 열을 가져오고 입력 필드를 미리 채웁니다.
드롭다운에서 Unique ID(고유 ID)를 선택합니다. 고유 ID는 데이터의 각 행을 명시적으로 참조할 수 있는 열입니다. 이 예의 경우 CSV 파일의 loyalty_id입니다.

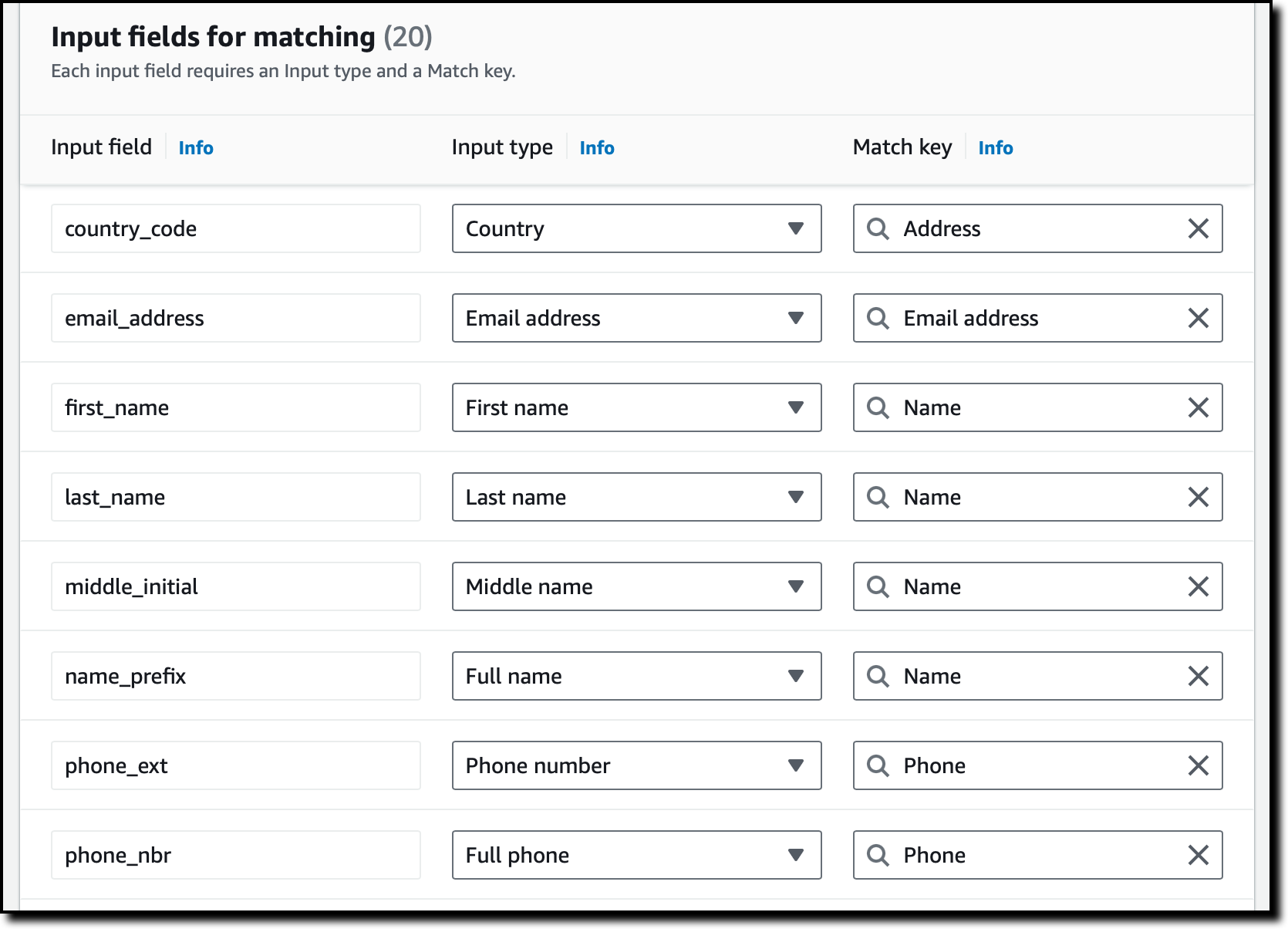
매칭에 사용할 입력 필드를 선택합니다. 이 경우 동일한 고객과 관련한 레코드가 여러 개 있는지 확인하는 데 사용 가능한 열을 드롭다운에서 선택합니다. 매칭에는 필요하지 않지만 출력 파일에 필요한 열이 있다면, 선택적으로 패스스루 필드로 추가할 수 있습니다. Next(다음)를 선택합니다.

입력 필드를 입력 유형과 매칭 키에 매핑합니다. 그러면 AWS Entity Resolution이 이들 필드를 사용하여 유사한 레코드를 매칭하는 방법을 알게 됩니다. 계속하려면 Next(다음)를 선택합니다.
이제, 그룹화를 사용하여 비교할 데이터를 더 효과적으로 정리할 수 있습니다. 예를 들어 First name(이름), Middle name(중간 이름) 및 Last name(성) 입력 필드를 그룹화하여 Full name(전체 이름)으로서 비교할 수 있습니다.

Address(주소) 필드의 그룹도 만듭니다.

Next(다음)를 선택하고 모든 구성을 검토합니다. 그런 다음 Create schema mapping(스키마 매핑 생성)을 선택합니다.
스키마 매핑을 만들었으니 이제 탐색 창에서 Matching workflows(매칭 워크플로)를 선택한 다음 Create matching workflow(매칭 워크플로 생성)를 선택합니다.

이름 및 설명을 입력합니다. 그런 다음 입력 데이터를 구성하기 위해 AWS Glue 데이터베이스 및 테이블과 스키마 매핑을 선택합니다.

서비스에 데이터에 대한 액세스 권한을 부여하기 위해, 이전에 구성한 서비스 역할을 선택합니다. 이 서비스 역할은 입력 및 출력 S3 버킷과 AWS Glue 데이터베이스 및 테이블에 대한 액세스 권한을 제공합니다. 입력 또는 출력 버킷이 암호화된 경우, 이 서비스 역할은 데이터를 암호화하고 복호화하는 데 필요한 AWS Key Management Service(AWS KMS) 키에 대한 액세스 권한도 부여할 수 있습니다. Next(다음)를 선택합니다.

규칙 기반 또는 ML 기반 매칭 방법을 사용할 수 있습니다. 방법에 따라 수동 또는 자동 처리 케이던스를 사용하여 매칭 워크플로 작업을 실행할 수 있습니다. 지금은 Processing cadence(처리 케이던스)에서 Machine learning matching(기계 학습 매칭)과 Manual(수동)을 선택하고 Next(다음)를 선택합니다.

S3 버킷을 출력 대상으로 구성합니다. Data format(데이터 형식)에서 Normalized data(정규화된 데이터)를 선택하여 특수 문자와 불필요한 공백을 제거하고 데이터를 소문자로 서식 지정합니다.

기본 Encryption(암호화) 설정을 사용합니다. Data output(데이터 출력)의 경우, 모든 입력 필드가 포함되도록 기본값을 사용합니다. 보안을 위해 필드를 숨겨서 마스킹하려는 출력 또는 해시 필드에서 제외할 수 있습니다. Next(다음)를 선택합니다.
모든 설정을 검토하고 Create and run(생성 및 실행)을 선택하여 매칭 워크플로 생성을 완료하고 처음으로 작업을 실행합니다.
몇 분이 지나면 작업이 완료됩니다. 이 분석 결과에 따르면 100만 개의 레코드 중 고유 고객은 83만 5,000명에 불과합니다. View output in Amazon S3(Amazon S3에서 출력 보기)를 선택하여 출력 파일을 다운로드합니다.

출력 파일의 각 레코드에는 원래의 고유 ID(이 예의 경우 loyalty_id)와 새로 할당된 MatchID가 있습니다. 동일한 고객과 관련된 매칭 레코드는 동일한 MatchID를 갖습니다. ConfidenceLevel 필드는 기계 학습 매칭에서 해당 레코드가 실제로 서로 일치할 확률인 신뢰 수준을 나타냅니다.
이제 이 정보를 사용하여 로열티 프로그램에 가입한 고객을 더 잘 이해할 수 있습니다.
가용성 및 요금
AWS Entity Resolution은 현재 미국 동부(오하이오, 버지니아 북부), 미국 서부(오레곤), 아시아 태평양(서울, 싱가포르, 시드니, 도쿄), 유럽(프랑크푸르트, 아일랜드, 런던) AWS 리전에서 정식 버전으로 사용할 수 있습니다.
AWS Entity Resolution의 경우 워크플로에서 처리한 소스 레코드의 수를 기준으로 사용한 만큼만 요금을 지불합니다. 기계 학습이나 규칙 기반 레코드 매칭과 같은 매칭 방법에 따라서는 요금이 달라지지 않습니다. 자세한 내용은 AWS Entity Resolution 요금을 참조하세요.
AWS Entity Resolution을 사용하면 데이터가 어떻게 연관되어 있는지 보다 심층적으로 이해할 수 있습니다. 이를 통해 레코드에 대한 통합된 보기를 기반으로 새로운 인사이트를 제공하고, 의사 결정을 보완하며, 고객 경험을 개선할 수 있습니다.
– Danilo
추신: AWS는 더 나은 고객 경험을 제공하기 위해 콘텐츠 개선에 초점을 맞추고 있으며, 이를 위해서는 여러분의 피드백이 필요합니다. 간단한 설문조사를 통해 AWS 블로그에 대한 경험과 관련된 인사이트를 공유해 주세요. 이 설문조사는 외부 기업에서 주최하므로 링크가 AWS 웹사이트로 연결되지 않습니다. AWS는 AWS 개인정보 처리방침에 설명한 대로 사용자 정보를 처리합니다.
Source: AWS Entity Resolution 정식 출시 – 앱 및 데이터 스토어 관련 레코드 매칭 워크플로 서비스