



Coursera, Amazon SageMaker Canvas 기반 No-Code 기계 학습 실습 교육 과정 개설


인공 지능은 우리 주변에 있습니다. AI는 특정 이메일을 스팸 폴더로 보냅니다. 자동 수정 기능을 제공하므로 문자를 보낼 때 오타를 수정하는 데 유용합니다. 이제 이것을 비즈니스 문제 해결에 사용할 수 있습니다.
비즈니스에서 데이터 기반 통찰력은 가치가 점점 더 높아지고 있습니다. 이러한 인사이트는 종종 AI의 하위 집합이자 복잡한 AI 시스템의 기반인 기계 학습(ML)을 통해 발견됩니다. 그리고 ML 기술은 이미 먼 길을 왔습니다. 오늘날에는 데이터 과학자나 컴퓨터 엔지니어가 아니어도 인사이트를 얻을 수 있습니다. Amazon SageMaker Canvas처럼 코딩이 필요 없는 ML 도구를 사용하면 이제 한 줄의 코드도 작성하지 않고도 ML을 사용해 효과적인 비즈니스 성과를 달성할 수 있습니다. 패턴, 추세 및 향후 어떤 일이 일어날 지 더 잘 이해할 수 있습니다. 즉 더 나은 비즈니스 결정을 내린다는 의미입니다!
오늘 AWS와 Coursera가 AWS에서 No-Code ML을 사용한 실무 의사 결정 실습 과정을 새로 시작합니다. 이 5시간 교육 과정은 AI/ML을 이해하기 쉽게 설명하고 스프레드시트를 가진 사람이라면 누구나 실제 비즈니스 문제를 해결할 수 있는 능력을 갖추도록 고안되었습니다.

과정 하이라이트
세 번의 강의를 통해 ML을 사용하여 비즈니스 문제를 해결하는 방법, 코드 없이 ML 모델을 구축하고 이해하는 방법, ML을 사용하여 가치를 추출하여 더 나은 의사 결정을 내리는 방법을 배우게 됩니다. 각 강의에서는 코딩이 필요 없는 시각적 ML 도구인 Amazon SageMaker Canvas를 사용하여 실제 비즈니스 시나리오 및 실습을 안내합니다.
강의 1 – ML을 사용하여 비즈니스 문제를 해결하는 방법
첫 번째 강의에서는 데이터 과학을 몰라도 ML을 사용하여 비즈니스 문제를 해결하는 방법을 배웁니다. 분석의 4단계를 설명하고 AI/ML의 고급 개념에 대해 논의할 수 있습니다.
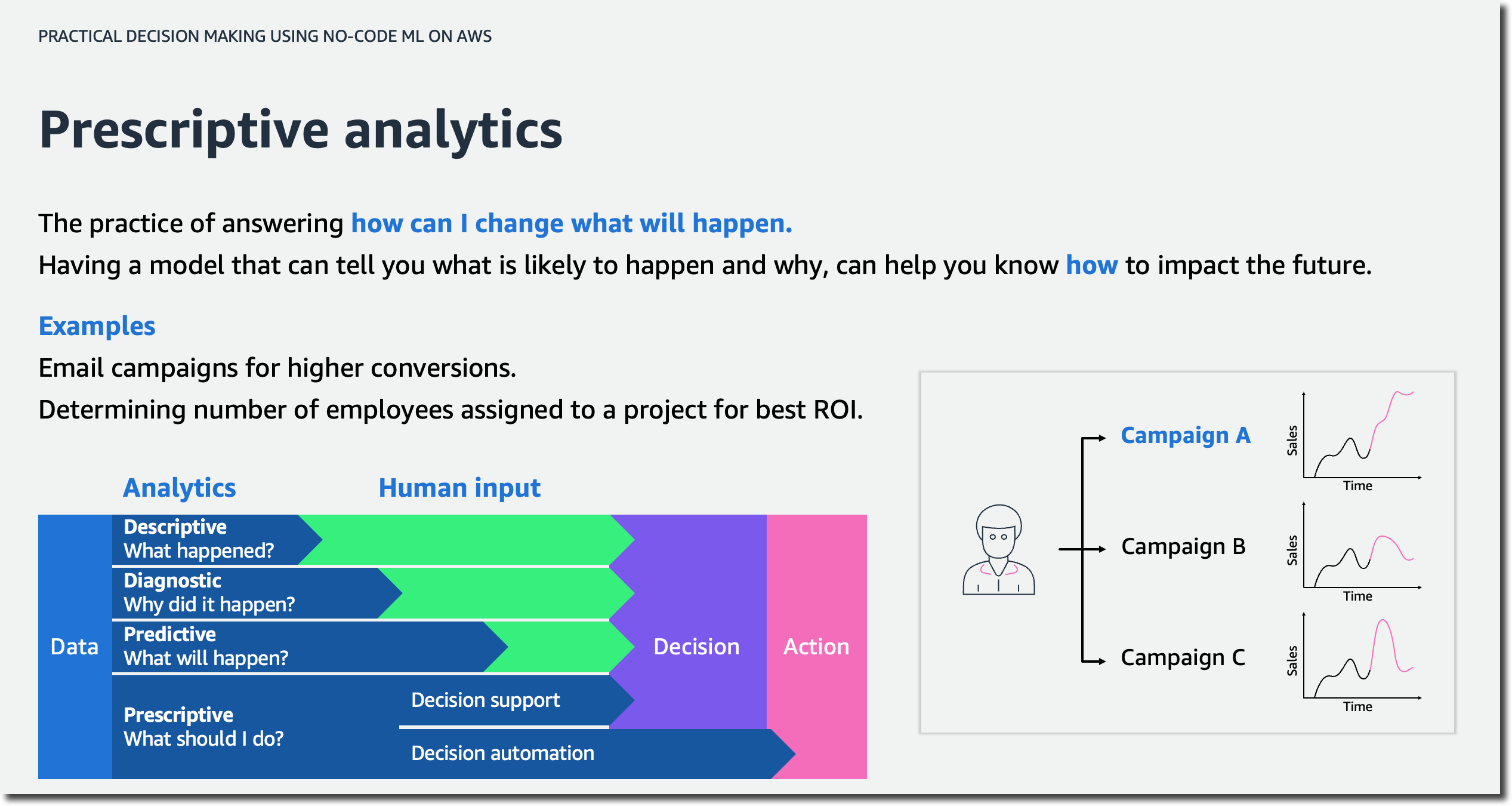
또한 이 강의에서는 자동화된 기계 학습(AutoML)에 대해 알아보고 AutoML을 사용하여 일반적인 비즈니스 사용 사례를 기반으로 인사이트를 생성하는 방법을 소개합니다. 그런 다음 가장 일반적인 기계 학습 문제 유형에 대한 비즈니스 질문 작성을 연습합니다.
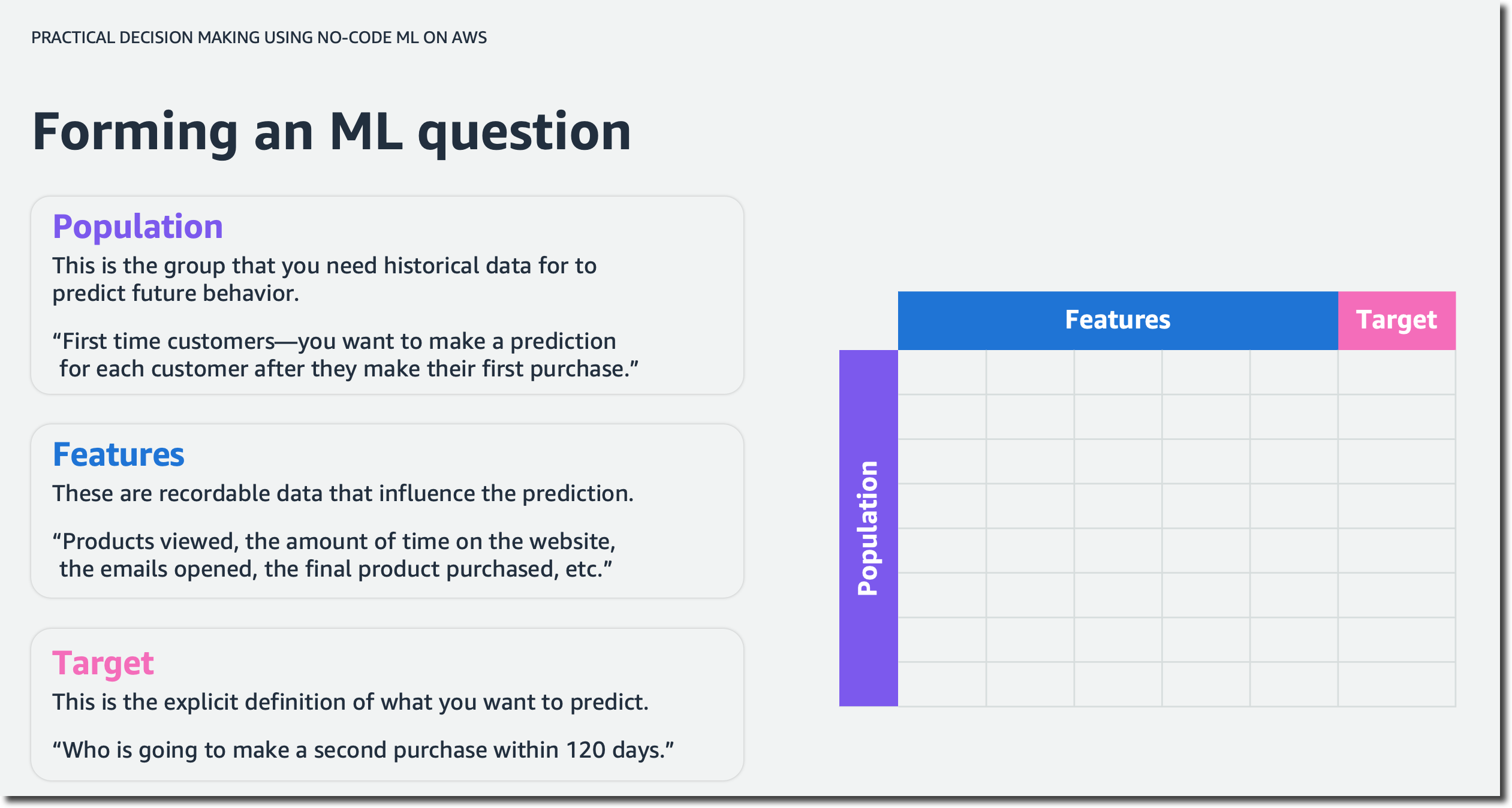
예를 들어 여러분이 한 티켓팅 기업의 비즈니스 분석가라고 가정해 봅시다. 여러분은 콘서트, 스포츠 이벤트 등 대규모 장소의 티켓 판매를 관리합니다. 현금 흐름을 예측하고 싶다고 가정해 봅시다. ML을 통해 해결해야 할 질문은 “티켓 판매를 어떻게 더 잘 예측할 수 있을까요?”입니다. 다음은 시계열 예측의 예입니다. 또한 과정 전반에 걸쳐 수치 및 범주 ML 문제를 살펴봅니다. “고객의 연간 수익은 얼마나 될까요?”와 “이 고객이 향후 3개월 내에 다른 티켓을 구매하게 되나요?” 같은 비즈니스 질문에 답하는 데 도움을 줄 것입니다.
다음으로 기계 학습에 대해 질문하는 반복적인 프로세스에 대해 알아보고 질문을 좀 더 명확히 표현하고 가장 가치가 높은 문제를 골라서 해결할 방법을 살펴봅니다.

첫 번째 강의에서는 예측 및 비예측 비즈니스 문제 전반에서 시간이 데이터에 어떤 영향을 미치는지, 그리고 각 ML 문제 유형에 맞게 데이터를 설정하는 방법을 심층적으로 분석하여 마무리합니다.
강의 2 – 코드 없이 ML 모델 구축 및 이해
두 번째 강의에서는 Amazon SageMaker Canvas를 사용하여 코드 없이 ML 모델을 구축하고 이해하는 방법을 배웁니다. 이동통신 서비스 기업에서 종합적으로 생성한 데이터를 사용한 고객 이탈 예제를 집중적으로 살펴보겠습니다. 문제는 “다음 달에 서비스를 취소할 가능성이 가장 높은 고객은 누구입니까?” 입니다.
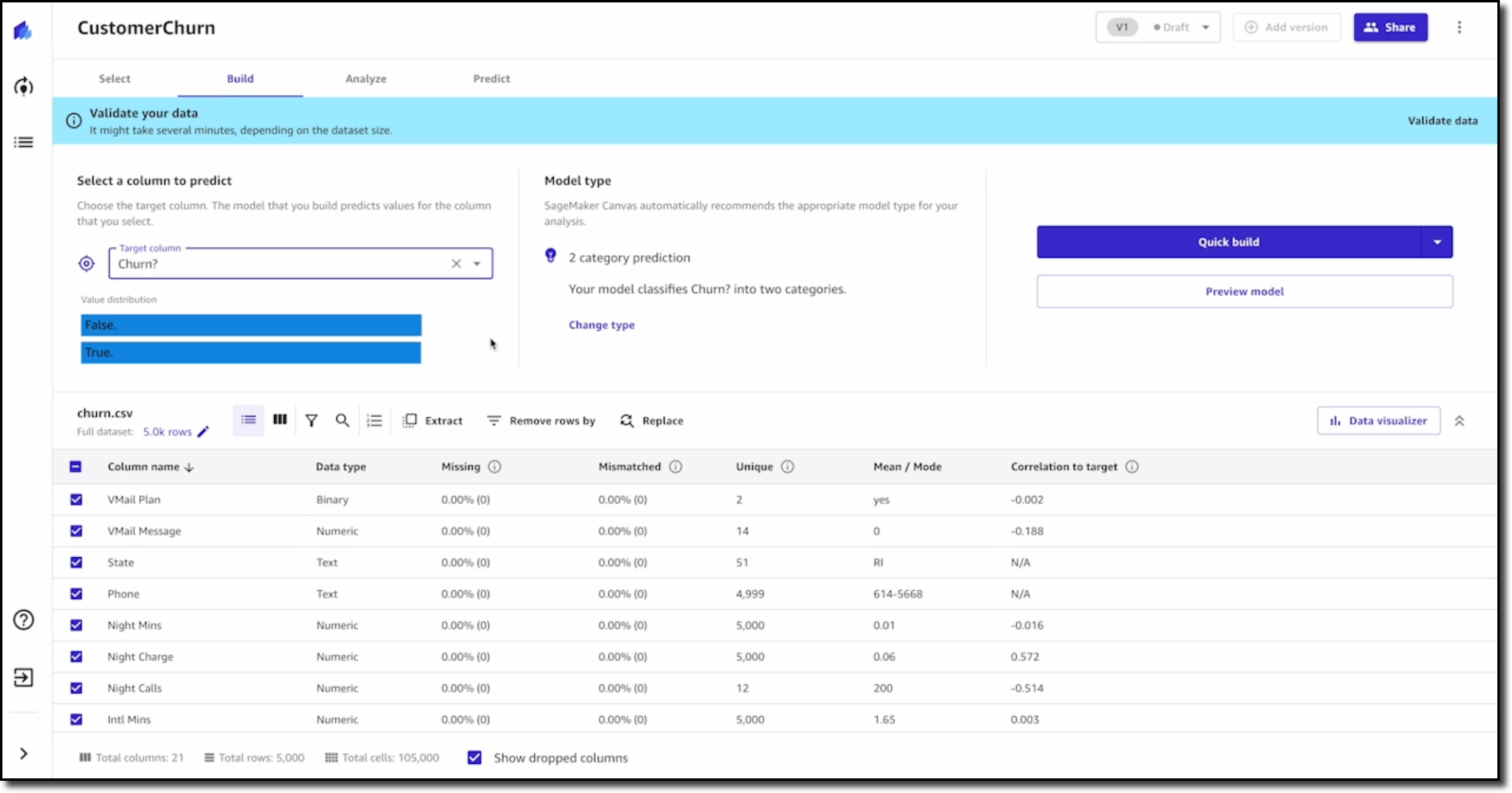
데이터를 가져오는 방법을 배우고 탐색을 시작합니다. 이 단원에서는 올바른 구성을 선택하고, 대상 열을 선택하고, ML에 사용할 데이터를 준비하는 방법을 설명합니다.
SageMaker Canvas는 또한 최근에 스캐터 차트, 막대 차트 및 박스 플롯을 비롯한 탐색적 데이터 분석(EDA)을 위한 새로운 시각화를 도입했습니다. 이러한 시각화는 데이터 집합의 특징 간의 관계를 분석하고 데이터를 더 잘 이해하는 데 도움이 됩니다.
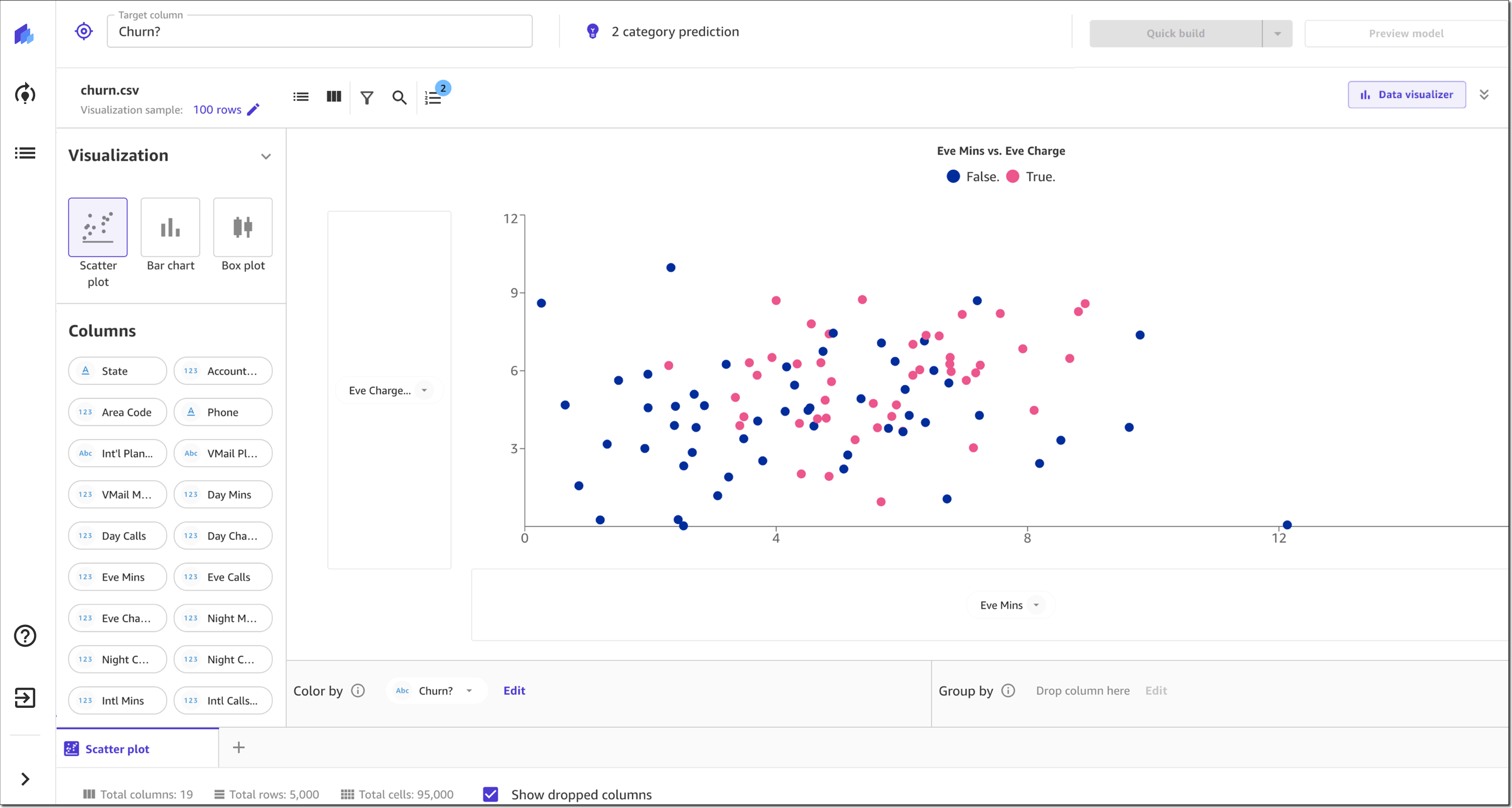
최종 데이터 검증 후 모델을 미리 볼 수 있습니다. 이를 통해 모델의 정확도와 평균적으로 모델 예측에 가장 큰 상대적 영향을 미치는 특징 또는 열이 무엇인지 즉시 알 수 있습니다. 데이터 준비 및 검증이 끝나면 계속해서 모델을 구축할 수 있습니다.
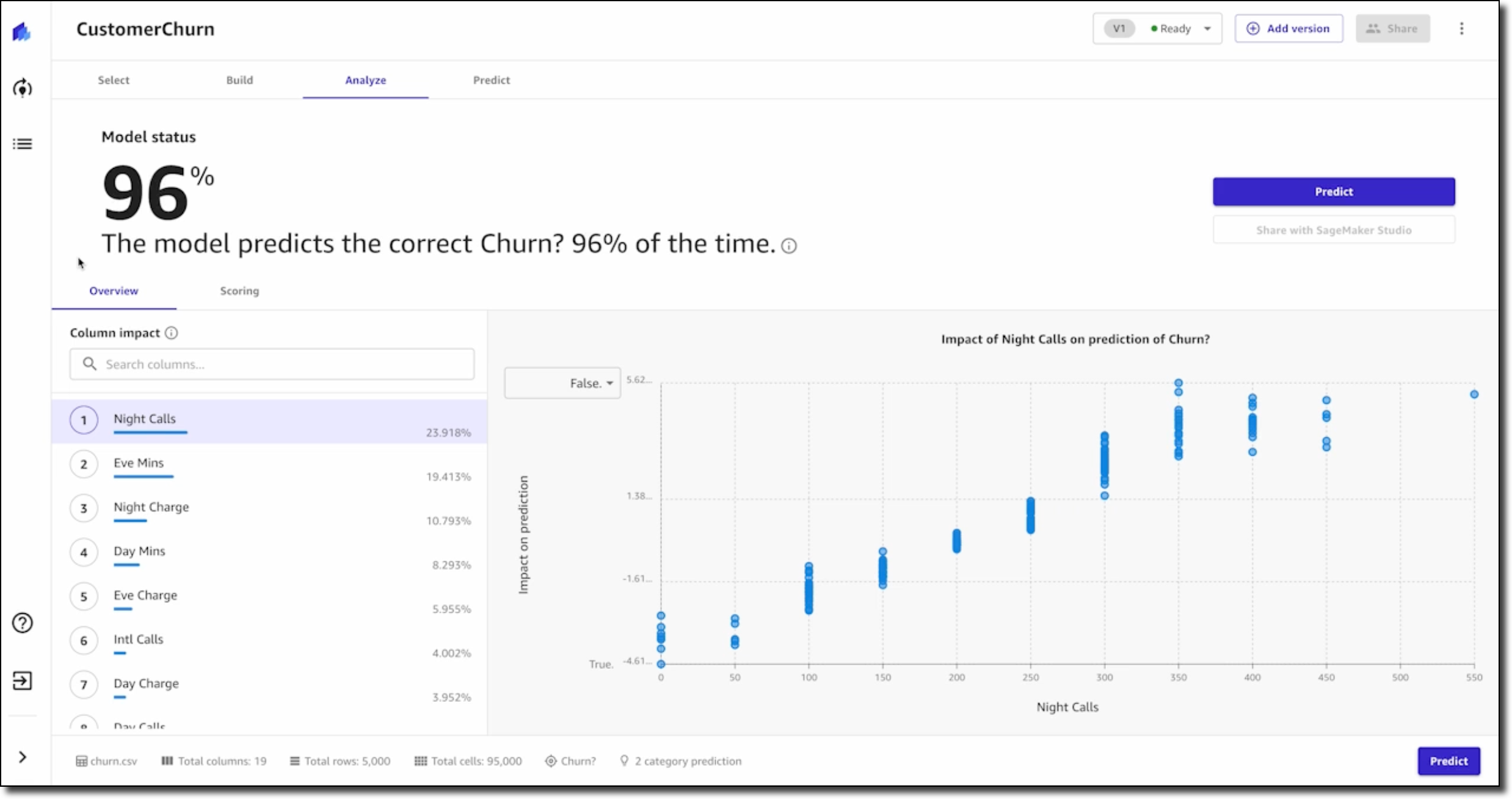
다음으로 모델의 성능을 평가하는 방법을 배웁니다. 학습 데이터와 테스트 데이터 분할의 차이점과 이를 사용하여 모델의 정확도 점수를 도출하는 방법을 설명할 수 있습니다. 또한 이 단원에서는 추가 성능 지표에 대해 알아보고 도메인 지식을 적용하여 모델이 제대로 작동하는지 판단하는 방법에 대해서도 설명합니다. 성과 지표를 평가하는 방법을 이해하면 더 나은 비즈니스 결정을 내릴 수 있는 기반을 갖게 됩니다.
두 번째 단원에서는 주의해야 할 몇 가지 일반적인 문제점을 마무리하고 모델을 반복하여 성능을 지속적으로 개선하는 방법을 보여줍니다. 기억과 일반화로 인한 데이터 유출의 개념과, 피해야 할 추가 모델 결함을 설명할 수 있습니다. 또한 모델 성능을 지속적으로 개선하기 위한 질문, 포함된 기능 및 샘플 크기를 반복하는 방법을 배우게 됩니다.
강의 3 – ML에서 값 추출
세 번째 강의에서는 ML에서 가치를 추출하여 보다 나은 결정을 내리는 방법을 배웁니다. 스프레드시트의 한 행에 대한 예측(단일 예측이라고 함)과 전체 스프레드시트의 예측(배치 예측이라고 함)을 포함하는 예측을 생성하고 읽을 수 있습니다. 무엇이 예측에 영향을 미치는지 이해하고 다양한 시나리오를 플레이할 수 있습니다.
다음으로 다른 사람들과 통찰력 및 예측을 공유하는 방법을 배웁니다. 기능 중요도 차트나 점수 부여 다이어그램 등의 제품을 시각적으로 표현하고, 프레젠테이션이나 비즈니스 보고서를 통해 통찰력을 공유하는 방법을 배우게 됩니다.
세 번째 강의에서는 데이터 과학 팀 또는 기계 학습 전문 지식을 갖춘 팀원과 협업하는 방법을 마무리합니다. SageMaker Canvas를 사용하여 모델을 구축할 때 빠른 구축 또는 표준 구축을 선택할 수 있습니다. 빠른 구축은 일반적으로 2~15분이 소요되며 입력 데이터 세트를 최대 50,000행으로 제한합니다. 표준 구축은 보통 2~4시간이 소요되며 일반적으로 정확도가 더 높습니다. SageMaker 캔버스를 사용하면 표준 구축 모델을 쉽게 공유할 수 있습니다. 이 과정에서 모델의 숨겨진 복잡성을 코드 수준까지 드러낼 수 있습니다.
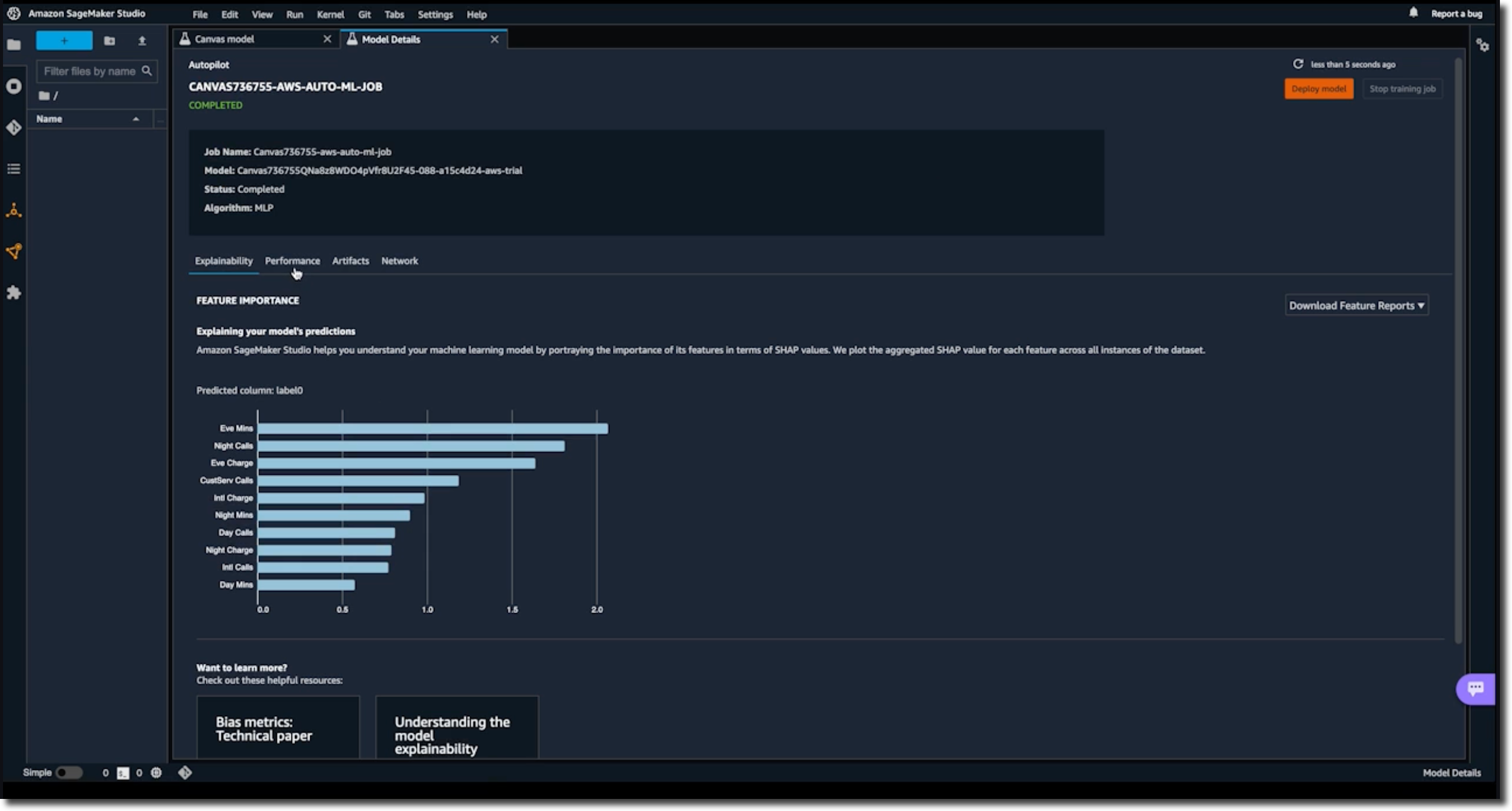
학습된 모델을 연 다음 공유 버튼을 클릭할 수 있습니다. 이렇게 하면 데이터 과학 팀에서 사용하는 통합 개발 환경인 SageMaker Studio에서 열 수 있는 링크가 만들어집니다.

SageMaker Studio에서는 입력 데이터 세트에 대한 변환과 모델 객체와 같은 채점 및 아티팩트에 대한 자세한 정보를 볼 수 있습니다. 데이터 탐색 및 특성 추출을 위한 Python 노트북도 볼 수 있습니다.
실습 연습
이 과정은 학습을 실습으로 옮길 수 있는 7개의 실습을 포함합니다. SageMaker Canvas와 함께 코드 없는 ML을 사용하여 공개적으로 사용 가능한 데이터 세트를 기반으로 실제 문제를 해결할 수 있습니다.
연구소는 소매, 금융 서비스, 제조, 의료, 생명 과학, 운송 및 물류를 비롯한 산업 전반의 다양한 비즈니스 문제에 중점을 둡니다.
고객 이탈 예측, 주택 가격 예측, 판매 예측, 대출 예측, 당뇨병 환자 재입원 예측, 기계 고장 예측 및 공급망 배송 정시 예측 작업을 수행할 수 있습니다.
지금 등록하세요
AWS에서 No-Code ML을 사용한 실무 의사 결정은 비즈니스 분석가와 비코드 ML을 사용하여 실제 비즈니스 문제를 해결하는 방법을 배우려는 모든 사람을 위한 5시간 과정입니다.
오늘 Coursera에서 AWS 기반 노코드 ML을 사용한 실용적인 의사 결정에 등록하세요!
— Antje
Source: Coursera, Amazon SageMaker Canvas 기반 No-Code 기계 학습 실습 교육 과정 개설