


EMR Notebooks를 사용하여 실행 중인 클러스터에 Python 라이브러리 설치
EMR Notebooks를 소개했습니다.이 게시물에서는 EMR Notebooks를 사용하여 실행 중인 클러스터에서 직접 노트북 범위 라이브러리를 설치하는 방법을 알아봅니다. 이 기능이 도입되기 전에는 부트스트랩 작업에 의존하거나 사용자 지정 AMI를 사용하여 클러스터를 프로비저닝할 때 EMR AMI로 사전에 패키징되지 않은 추가 라이브러리를 설치해야 했습니다. 이 게시물에서는 EMR Notebooks 안에서 미리 설치된 Python 라이브러리를 로컬에서 사용하여 결과를 분석하고 플롯을 작성하는 방법도 설명합니다. 이 기능은 데이터 세트를 분석하고 시각화해야 하지만 PyPI 리포지토리에 액세스할 수 없는 시나리오에서 유용합니다.
EMR Notebooks로 노트북 범위 라이브러리를 사용할 때의 이점
노트북 범위 라이브러리는 다음과 같은 이점을 제공합니다.
- 런타임 설치 – PyPI 리포지토리에서 즐겨찾는 Python 라이브러리를 가져와서 필요할 때 바로 원격 클러스터에 설치할 수 있습니다. 이러한 라이브러리는 Spark 런타임 환경에서 즉시 사용할 수 있습니다. 노트북 세션을 다시 시작하거나 클러스터를 다시 생성하지 않아도 됩니다.
- 종속성 분리 – EMR Notebooks를 사용하여 설치하는 라이브러리는 노트북 세션에만 적용되며 부트스트래핑된 클러스터 라이브러리 또는 다른 노트북 세션에서 설치된 라이브러리에 영향을 주지 않습니다. 이러한 노트북 범위 라이브러리는 부트스트래핑된 라이브러리보다 우선합니다. 여러 노트북 사용자가 원하는 버전의 라이브러리를 가져올 수 있으며 동일한 클러스터에서 종속성 충돌 없이 사용할 수 있습니다.
- 이동식 라이브러리 환경 – 라이브러리 패키지 설치는 노트북 파일로부터 수행됩니다. 따라서 노트북을 다른 클러스터로 전환한 경우 노트북 코드를 다시 실행하여 라이브러리 환경을 다시 생성할 수 있습니다. 노트북 세션이 끝나면 EMR Notebooks를 통해 설치한 라이브러리가 호스팅 EMR 클러스터에서 자동으로 제거됩니다.
사전 조건
EMR Notebooks의 이 기능을 사용하려면 EMR 릴리스 5.26.0 이상을 실행하는 클러스터에 노트북을 연결해야 합니다. 클러스터에서는 라이브러리를 가져오려는 퍼블릭 또는 프라이빗 PyPI 리포지토리에 액세스할 수 있어야 합니다. 자세한 내용은 노트북 생성을 참조하십시오.
VPC 내부 클러스터에서 외부 리포지토리에 연결할 수 있도록 VPC 네트워킹을 구성하는 방법은 다양합니다. 자세한 내용은 Amazon VPC 사용 설명서에서 시나리오 및 예제를 참조하십시오.
노트북 범위 라이브러리 사용
이 게시물에서는 공개적으로 사용 가능한 Amazon 고객의 도서 후기 데이터 세트를 분석함으로써 EMR Notebooks의 노트북 범위 라이브러리 기능을 설명합니다. 자세한 내용은 Registry of Open Data for AWS 사이트의 Amazon Customer Reviews Dataset를 참조하십시오.
노트북을 열고 커널이 PySpark로 설정되었는지 확인합니다. 노트북 셀에서 다음 명령을 실행합니다.
다음 출력이 반환됩니다.
다음 명령을 실행하여 현재 노트북 세션 구성을 확인할 수 있습니다.
다음 출력이 반환됩니다.


노트북 세션은 기본적으로 Python 3을 사용하도록 구성됩니다(spark.pyspark.python 사용). Python 2를 사용하려는 경우 노트북 셀에서 다음 명령을 실행하여 노트북 세션을 다시 구성하십시오.
다음과 같은 결과를 확인할 수 있습니다.
![]()

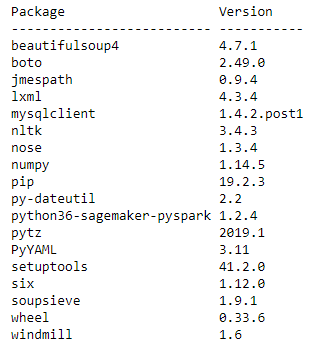
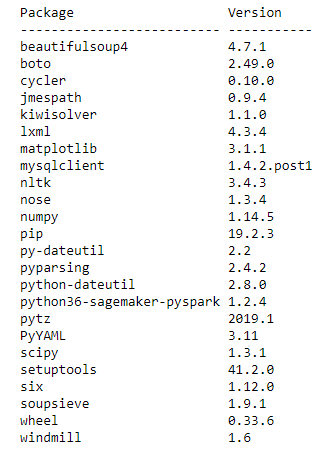
분석을 시작하기 전에 클러스터에서 이미 사용할 수 있는 라이브러리를 확인합니다. 클러스터의 모든 Python 라이브러리를 나열하는 list_packages() PySpark API를 사용하여 이 작업을 수행할 수 있습니다. 다음 코드를 실행합니다.
클러스터의 사용 가능한 모든 Python 3 호환 패키지를 보여주는 다음과 같은 출력를 확인할 수 있습니다.

다음 코드를 사용하여 Amazon 고객의 도서 후기 데이터를 Spark DataFrame으로 로드합니다.
이제 데이터를 탐색할 준비가 되었습니다. 다음 코드를 사용하여 데이터 세트에서 사용 가능한 스키마와 열의 수를 확인합니다.
다음 출력이 반환됩니다.


이 데이터 세트에는 총 15개의 열이 있습니다. 다음 코드를 실행하여 데이터 세트의 총 행 수를 확인할 수도 있습니다.
다음 출력이 반환됩니다.
![]()

다음 코드를 사용하여 전체 도서의 수를 확인합니다.
다음 출력이 반환됩니다.
![]()

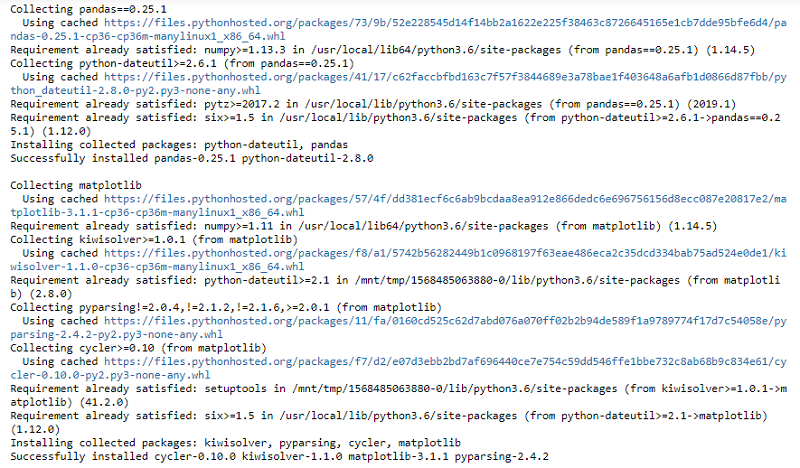
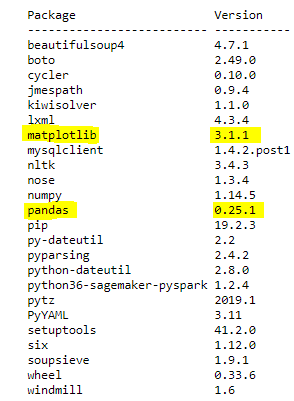
연간 도서 후기 수를 분석하고 고객 평점의 분포를 분석할 수도 있습니다. 이 작업을 수행하려면 퍼블릭 PyPI 리포지토리에서 Pandas 라이브러리 0.25.1 버전과 최신 Matplotlib 라이브러리를 가져옵니다. install_pypi_package API를 사용하여 노트북에 연결된 클러스터에 라이브러리를 설치합니다. 다음 코드를 참조하십시오.
다음 출력이 반환됩니다.

install_pypi_package PySpark API는 라이브러리와 연관된 모든 종속성을 설치합니다. 기본적으로 현재 사용 중인 Python 버전과 호환되는 라이브러리의 최신 버전이 설치됩니다. 앞서 Pandas 예제에서 특정 라이브러리 버전을 지정하여 설치하는 방법도 확인하였습니다.
다음 코드를 실행하여 가져온 패키지가 성공적으로 설치 되었는지 확인합니다.
다음 출력이 반환됩니다.

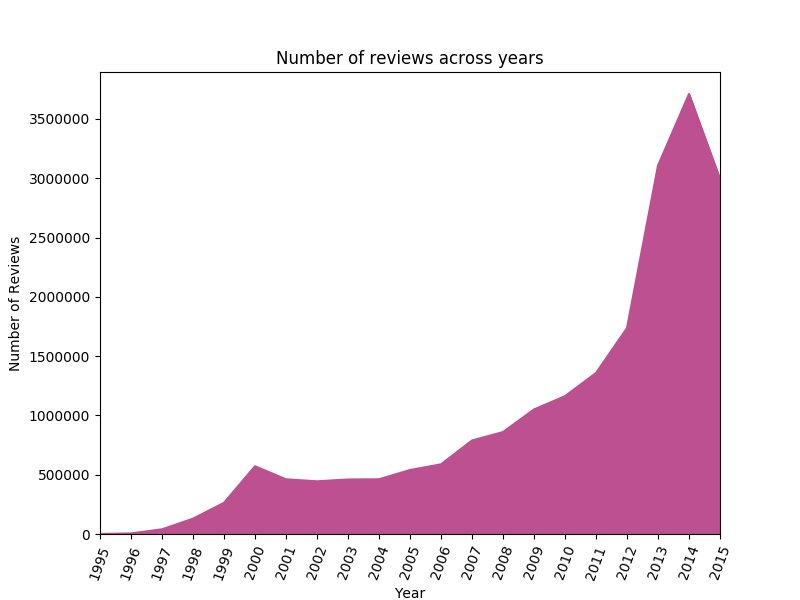
수 년간 작성된 후기 수의 추세를 분석할 수도 있습니다. ‘toPandas()’를 사용하여 Spark 데이터 프레임을 Pandas 데이터 프레임으로 변환한 다음 Matplotlib로 시각화 할 수 있습니다. 다음 코드를 참조하십시오.
위의 명령은 연결된 EMR 클러스터에 플롯을 렌더링합니다. 노트북 안에서 플롯을 시각화하려면 %matplot 매직을 사용합니다. 다음 코드를 참조하십시오.
다음 그래프는 고객이 제공한 후기 수가 1995년부터 2015까지 폭발적으로 증가했음을 보여줍니다. 2001년, 2002년 및 2015년은 이례적으로, 이전 연도보다 후기 수가 감소했습니다.

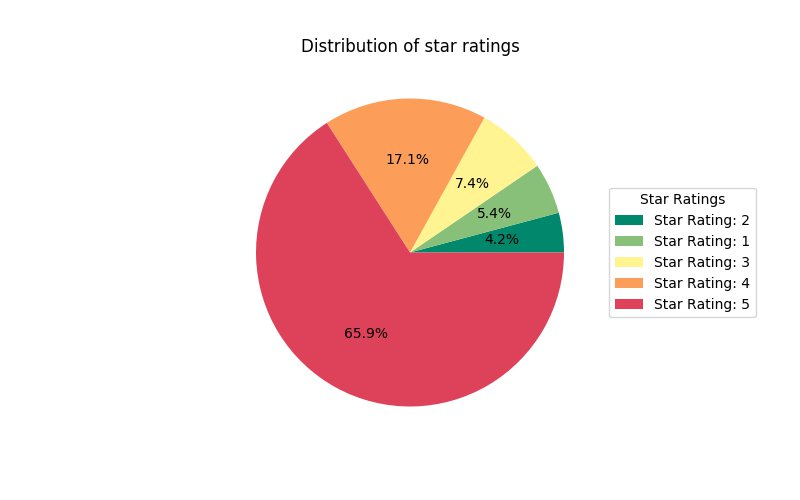
별 평점의 분포를 분석하고 원형 차트를 사용하여 시각화할 수 있습니다. 다음 코드를 참조하십시오.
%matplot 매직을 사용하여 원형 차트를 인쇄하고 다음 코드를 사용하여 노트북에서 시각화할 수 있습니다.
다음 원형 차트는 사용자의 80%가 4점 이상의 평점을 주었음을 보여줍니다. 약 10%의 사용자는 도서에 2점 이하의 평점을 제공했습니다. 일반적으로 고객은 Amazon에서 구매한 도서에 만족함을 알 수 있습니다.

마지막으로, ‘uninstall_package’ Pyspark API를 사용하여 install_package API를 사용하여 설치한 Pandas 라이브러리를 제거합니다. 앞서 EMR Notebooks를 사용하여 설치한 라이브러리의 다른 버전을 사용하려는 시나리오에서 유용합니다. 다음 코드를 참조하십시오.
다음 출력이 반환됩니다.


다음 코드를 실행합니다.
다음 출력이 반환됩니다.

노트북을 종료하면 install_pypi_package API를 사용하여 클러스터에 설치한 Pandas 및 Matplot 라이브러리가 가비지가 되고 클러스터 외부로 수거됩니다.
EMR Notebooks에서 로컬 Python 라이브러리 사용
지금까지 설명한 노트북 범위 라이브러리를 사용하려면 EMR 클러스터에서 PyPI 리포지토리에 액세스할 수 있어야 합니다. EMR 클러스터를 리포지토리에 연결할 수 없는 경우 EMR Notebooks로 사전 패키징된 Python 라이브러리를 사용하여 노트북 안에서 로컬로 결과를 분석하고 시각화할 수 있습니다. 노트북 범위 라이브러리와 달리 이러한 로컬 라이브러리는 Python 커널에만 제공되며 클러스터의 Spark 환경에는 제공되지 않습니다. 이러한 로컬 라이브러리를 사용하려면 클러스터의 Spark 드라이버에서 노트북으로 결과를 내보내고 노트북 매직을 사용하여 로컬로 결과의 플롯을 작성합니다. 클러스터가 아니라 노트북을 사용하여 플롯을 분석하고 렌더링하는 것이므로 노트북으로 내보내는 데이터 세트는 크기가 작아야 합니다(100MB 미만 권장).
로컬 라이브러리 목록을 보려면 노트북 셀에서 다음 명령을 실행합니다.
노트북에서 사용 가능한 모든 라이브러리 목록이 반환됩니다. 이 목록은 꽤 길기 때문에 이 게시물에 포함하지 않겠습니다.
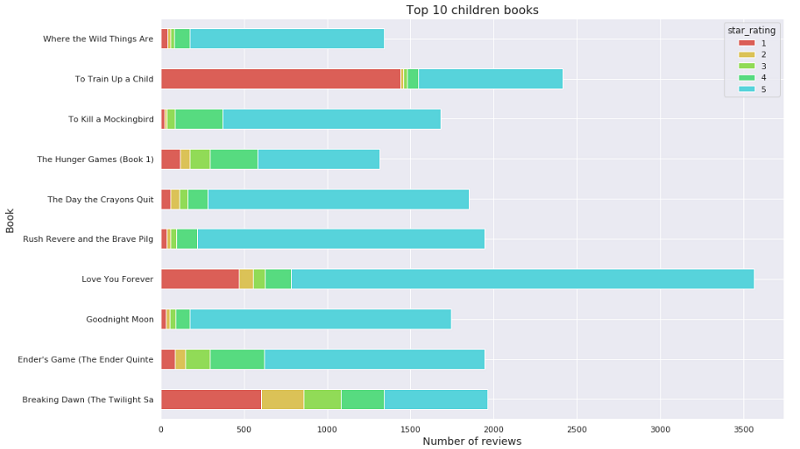
이 분석에서는 도서 후기 데이터 세트에서 상위 10개의 아동용 도서를 찾고 이러한 아동용 도서에 대한 별 평점 분포를 분석합니다.
고객이 작성한 후기에서 다음 코드를 사용하여 아동용 도서를 식별할 수 있습니다.
다음 코드를 사용하여 고객 후기 수를 기준으로 상위 10개의 아동용 도서에 대한 플롯을 작성합니다.
다음 출력이 반환됩니다.


다음 코드를 사용하여 해당 도서들에 대한 고객 평점 분포를 분석합니다.
다음 출력이 반환됩니다.


이 결과에 대한 플롯을 노트북 안에서 로컬로 작성하려면 Spark 드라이버의 데이터를 내보내고 로컬 노트북에서 Pandas DataFrame으로 캐싱합니다. 이 작업을 수행하려면, 우선 다음 코드를 사용하여 임시 테이블을 등록합니다.
로컬 SQL 매직을 사용하여 다음 코드로 이 테이블에서 데이터를 추출합니다.
이러한 매직 명령에 대한 자세한 내용은 GitHub 리포지토리를 참조하십시오.
코드를 실행하면 결과에 대한 플롯을 대화형으로 작성할 수 있는 사용자 인터페이스가 반환됩니다. 다음 원형 차트는 평점의 분포를 보여줍니다.
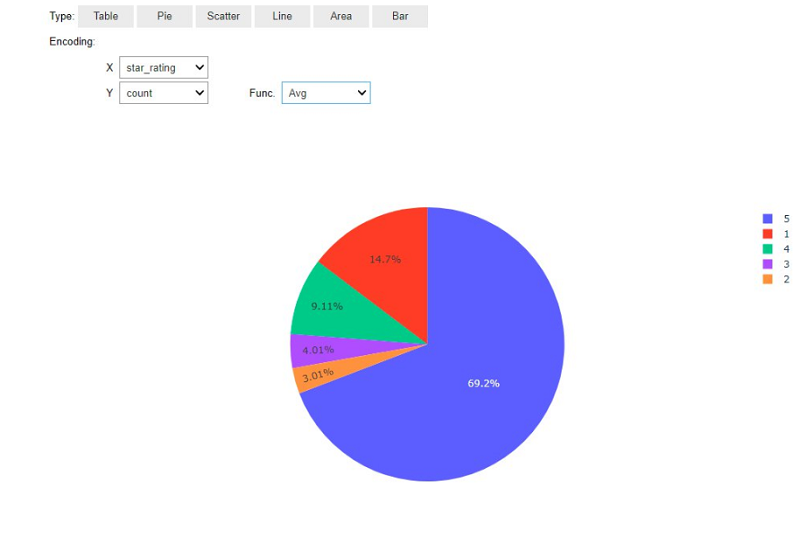

EMR Notebooks에서 제공되는 로컬 Matplot 및 seaborn 라이브러리를 사용하여 보다 복잡한 차트를 그릴 수도 있습니다. 다음 코드를 참조하십시오.
다음 출력이 반환됩니다.

요약
이 게시물에서는 EMR Notebooks의 노트북 범위 라이브러리 기능을 사용하여 자주 사용하는 Python 라이브러리를 실시간으로 EMR 클러스터로 가져와서 설치하고, 해당 라이브러리를 사용하여 데이터 분석을 개선하고 풍부한 그래픽 플롯으로 결과를 시각화하는 방법을 살펴봤습니다. 또한 사전 패키징된 로컬 Python 라이브러리를 EMR Notebooks에서 사용하여 결과를 분석하고 플롯을 작성하는 방법도 알아 보았습니다.
작성자 소개

