



HTTP/2 Theory and Practice in NGINX Stable, Part 1


td {
padding-right: 10px;
}

Table of Contents
Good morning ladies and gentlemen. My name is Nathan. I work at a startup called StackPath. We are currently in a closed beta and will be exiting that within the next couple weeks and we will have our first major public product out at that point. I am what they call an aqui-hire.
I was originally with a company called MaxCDN which was purchased, and so that’s where the bulk of this particular talk comes from, is our experience at MaxCDN deploying HTTP/2 at a global scale and across, oh, I don’t know, 20-odd pops throughout the world and several hundred servers.
Before I get started on this, I’m going to take a moment to share. I want to publicly thank Valentin for his wonderful talk on HP2 yesterday especially because it was on the negatives and the downsides of HP2 which, you know, ordinarily at a conference like this, you’re not allowed to have a negative talk. Everything has to be upbeat. Everything has to be positive. People who do very negative talks tend not to get invited back unless, of course, you’re the conference sponsor.
So the really good thing about this is that it convinced me to stay up until 2 o’clock rewriting about one third of this presentation because he led an elephant into the room and I have to address it. I can’t just let it sit because, frankly, a lot of what he says is very, very valid and a lot of this echoes what it is that we saw when we went to go ahead and deploy the thing.
So the background – one last little story before I get started, which is that when I was first asked to give this talk, I had some guys from the sales and marketing team come over and they kept saying “Oh, this is going to be great,” “It’s gonna be fantastic.” I said well, you know, we have this company priority which is selling the company out to StackPath going on. I don’t really have time.
And they said “Fine, fine, fine, we’ll do it with you.” So we sat down and talked to what were the problems with this, and a comment that kept coming back after doing a lot of benchmarking, after doing a lot of testing with this is, well, a lot of this is buzzword compliance, so it’s sort of being done because customers are asking for it, so we have to do it.
But does it really get us anything? Does it really do anything for us? And the guy said “This is great, we’ll pitch this in.” And I thought this was a wonderful solution to my problem because I’m not allowed to do a negative talk. This is a negative talk. It’s absolutely going to get denied and this gets me out of the whole problem in the first place. Unfortunately, it was accepted.
I was, you know, quite surprised why, but thanks to Valentin’s talk, now I know why it was accepted is because it has to bookend his earlier talk, because we have to show the entire range of the experiences here, and that’s fine, that’s fair, that actually works out.
So, unfortunately, my co-presenters bailed on me about –oh, I don’t know –a month or 6 weeks or so ago, and so I had at the last minute sent into this conference: I’m sorry, I have to cancel. I can’t do this because my co-presenters are no longer here.
And they said “Are you sure? Is this non-negotiable?” And I said well, you know, if I can meet my deadlines, get my stuff done, I will be very happy to do the talk. And so I was lucky. I was able to do that and here I am. But that wound up changing the topic to something positive, right, or at least not negative, which is why the title on the screen says Theory and Practice in NGINX Stable.
So what I’m going to try to do right now is, I’m going to – I know the time clock is ticking – I’m going to try to hustle through a lot of the technical slides. I’m going to try to get to the – leave as much time as possible, especially for the QA section, and I’m going to end this with trying to address a lot of the criticisms of HTTP/2 because, frankly, a lot of them are absolutely very valid, but it still has a use case, it still does have a place where it actually delivers value, where it delivers functionality, where it actually does something.
I will temper that by saying that when we deployed this globally at Little MaxCDN for our dedicated SSL customers, you get – you basically lease your own IP when you do it over a dedicated cert, and so we deliberately set it so that you can either choose to enable or you can choose to disable H2 support, assuming that you have your own dedicated IP.
And that was done for positive reasons. We want the end user to be able to make a choice, make their own decision whether to enable it or not.
3:56 What Is HTTP/2?

So all that out of the way, let’s go ahead and get started – technical slides – again, I’m going to try to politic, I’m going to try to hustle through these, so if I skip this and you want to come back to it in the Q&A, that’s fine, that’s not a problem, we’ll do it at that point.
So RFC 7540 was ratified and what wound up happening is, you know, it’s a new HTTP protocol. It does basically the same underlying concept. What it’s supposed to do is the same thing as the previous protocols which is: they’ll allow the transport of HTTP object so you can do requests, you can do responses.
4:24 What Was SPDY?

And what it was built on was technology from – called Speedy. In fact, if you go to – there’s a lovely backup on GitHub where it explicitly says that, you know, after a call for proposals in the selection process, Speedy 2 is chosen as the basis for H2 and that’s why, you know, it’s a binary protocol.
It supports all this other stuff that Speedy did, and it looks really, really similar, and it was built off of that, so – Speedy was an earlier Google to find protocol from a couple years ago which was designed again to help assist the delivery of content and to help pages load a little bit faster delivered from the server, but it doesn’t necessarily help other parts of the stack.
5:05 HTTP/2 Sample Object

So we’re here to do HTTP objects. “Great. What’s an HTTP object?” Well, you know, it looks like standard, any object and under H2, the same as they are under H1. You have the same methods, you have the same request URIs, the same headers, the same codings. It looks the same.
5:25 Proxying Under HTTP/2: GET Method
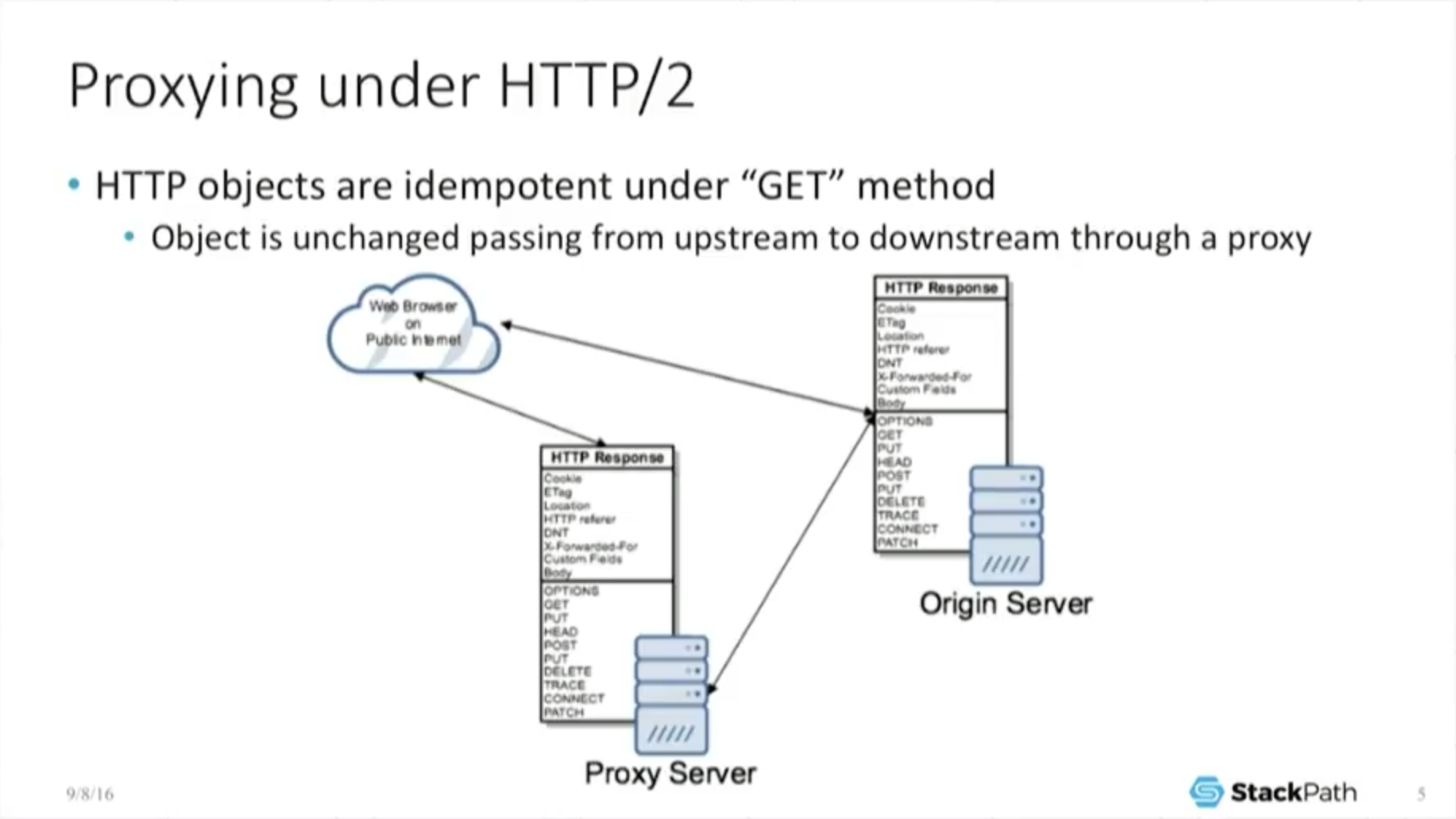
And that’s good because that’s ultimately how we GET in our operation. So it has to interoperate with the rest of the Web. It cannot break the lab. It’s worthless as a protocol if it does. So if you look at this from a proxy perspective, I’m a cache. I care very deeply about proxying.
What this means is because the HTTP objects are the same, the spec for HTTP forces the object to be idempotent under the GET method which is a very, very fancy way of saying it is not allowed to change. So if I am out there on the public Internet and I am a web browser, if I make a call directly to an origin, I do a GET request for an object. Great, I get the object no problem.
But if I go through a proxy server, it’s idempotent under the GET method, so the proxy server turns around, does its own GET back to the origin, takes that object and returns it back to the end user.
And because it was not allowed to change under the GET method, the object is exactly the same. So the end user doesn’t care where he got it from because he’s always getting the exact same object. And this is as true under H2, as it is under H1, which is great for me. It allows my business to still exist.
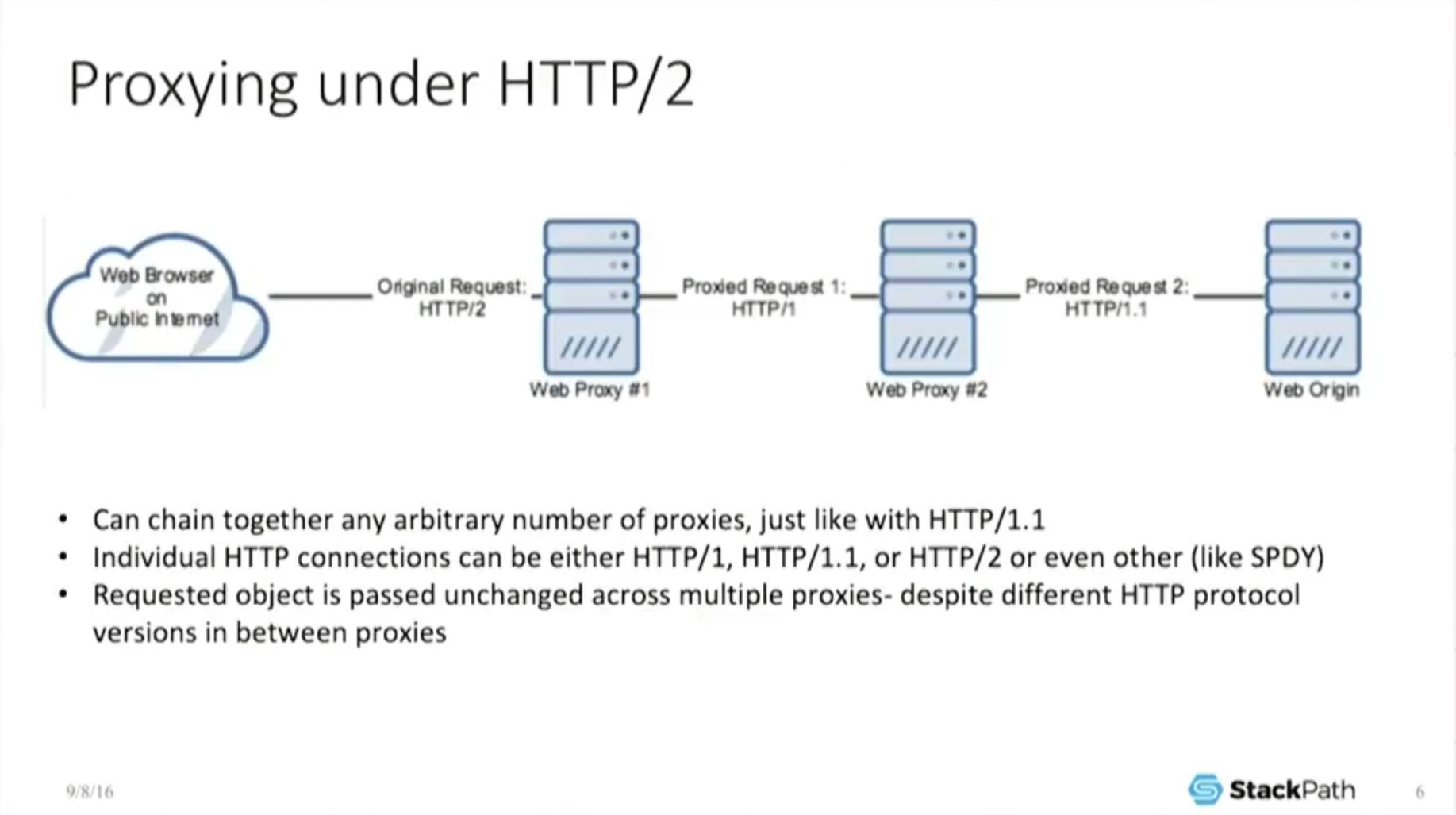
But it gets a little bit more fun than that because I can chain together an arbitrary number of proxies so I can bounce this object. Because it’s idempotent under every single one of those, it’s always the same.
The end user never sees a different object, he gets the exact same thing back. So this is great. I can change stuff together. The moment I can change stuff together, I can now interoperate with previous versions of the protocol because each connection can negotiate to a different protocol, and because the object is the same under either protocol, I don’t care. I get back the exact same object. So I can interoperate.
7:06 Proxying Under HTTP/2: Load Balancing
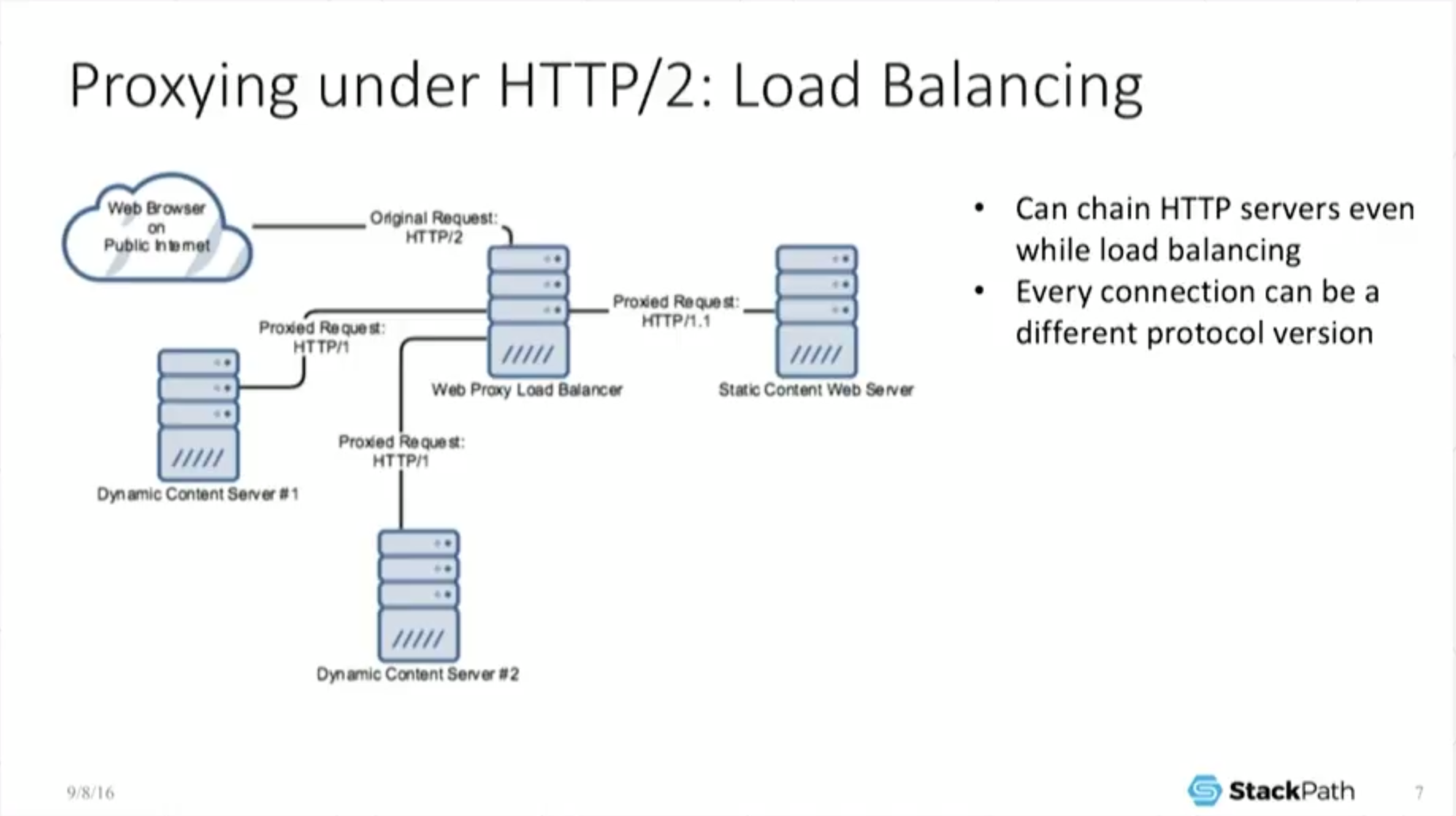
Now, I can interoperate under load balancing which is a very standard technology that everyone has been talking about at this conference.
And here’s an example where you are using – the web browser talks H2 out to the load balancer, but then the load balancer, and internally, may be talking H1 to, you know, some dynamic content servers that may be doing a persistent 1.1 connection out to some static content server, and this is okay.
We’re getting back the object. Everything is getting put together. We look and work the same no matter which protocol we’re under from a practical perspective, from the web browser’s perspective.
7:39 Key Features: Binary Protocol

So why do it? What are the benefits that we’re actually getting out of this? Well, it – we’ve changed now from an ASCII text-based protocol, one where you can just tell that into the port, to a simple ASCII, yet you can replicate the headers by hand, get back the expected result, and everything just magically works.
That’s no longer the case because it’s a binary protocol. So my little stupid example is: I use Curl with H2 support to make a call just plain to Netcat, right? Just see, okay, what’s it doing?
And you can see, well, it’s got all this weird stuff going on because – got all these weird binary frames trying to pass in and all this other stuff under the hood that it’s trying to do, and of course, see, it’s no longer quite as easy.
On the other hand, because it’s a binary protocol, we can do some fun things, like do interleave requests. We can set request priority. And so we can actually start playing a lot of games that you can’t do under H1, in particular: the Head-Of-Line blocking.
8:32 Key Features: No Head-of-Line Blocking

And this was a very nice point that Valentin brought up the other day, which is that while your process can still block, but you can still go through Head-Of-Line blocking. But within the process itself, you don’t GET within the protocol down at that layer – there is no Head-Of-Line blocking, and that very, very simple example here – H1.1 GET object – has to respond.
Then I can do the next one object response. So it’s a FIFO queue. And you don’t have that anymore in the H2. Well, I can actually do multiple GETs at the same time. While something is streaming down, I can issue another GET and start retrieving that at the same time over the same connection because it’s multiplex and interleaved. So it does do some fun stuff.
9:09 Key Features: Only One Connection
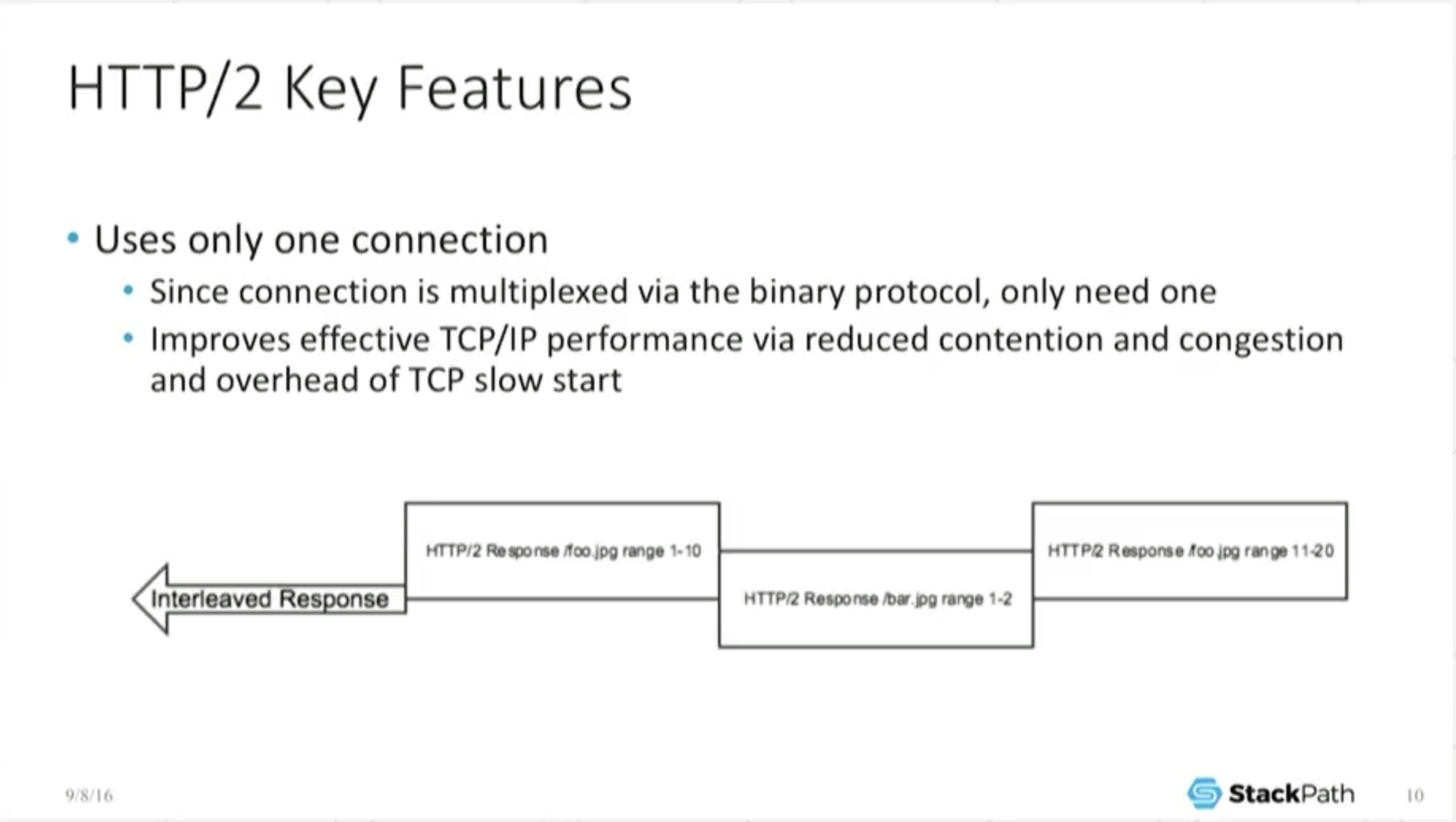
Because we have this interleave connection, all of a sudden we no longer need a flurry of connections to do something. If I have 5 calls, you know, whatever, I only need one connection to do this. And for most end users, they don’t necessarily care about this.
And you have to get diving into some level of TCP optimization before it starts to make sense, in particular, discussion about the congestion windows and the peril of TCP. So, sorry, I have an appendix slide about it.
I’m not going to talk too much about it because I could waste a ton of time on it, but the long and short of it is: TCP slow start means that when you start a connection, you only want to send a little bit of data out, and that the longer the connection is and the better and cleaner it tests your connection, the better and cleaner it is, the bigger that window ramps up and the more information you can keep in flight; which means an existing, already open connection with a huge congestion window can handle a huge amount of information on the exact same line.
But if you have a brand new connection and you’re stuck going through slow start, you can – you’re sipping data through a straw.
10:11 Key Features: Server Push
So in addition to all the sort of interleaving and the like, we have some other fun C stuff that we can do which is server push. And as, again, I’m a content provider C, I’m a cache, I love server push because what I can do now is: if I have a request come in for an object on the back and I’ve done the appropriate data crunching, I know that people who have downloaded Foo also want to download Bar.
Well, I don’t have to wait for the request for Bar, I can actually push that at the exact same time as I’m downloading Foo. So now the browser receives two files, even though he only asked for one, and if I’m remotely clever in the back and I figured out what that is – a lot of the current push implementations sort of pre-assume that you know exactly what you’re doing and that you can pre-define this in your configuration, and it’s not very dynamic.
This is going to change in the future as this becomes a little bit more evolved, and this is one of the places where a lot of the providers are going to start differentiating themselves and offering a greater level of value. Fine.
11:04 Key Features, Header Compression

What else does it do? Well it also does header compression. Anyone who’s familiar with HV objects – there’s a lot of perils to using custom headers and shoveling huge amounts of data into the header section because under H1, that’s uncompressed data, so all you’ve done is increase the amount of bandwidth required to download.
And for what is basically metadata and if you can hide that or encode it in some cleaner way or some easier way, so much the better. Well, that largely goes away under H2. Sure, it can still be a bottleneck, but because they’re now compressed, you can actually start shoveling more stuff in there and not have to worry as much as you did under the previous world.
So this should actually start changing the way you can start thinking about a lot of application development because now you can start making decisions on whatever it is (custom data? metadata?) you’ve chosen to shovel into the headers, because you no longer pay such a huge penalty shipping them around.
So again, as a cache, am I happy about this? No, because I built for bandwidth. Why would I want this?
The post HTTP/2 Theory and Practice in NGINX Stable, Part 1 appeared first on NGINX.