



NGINX and Zookeeper, Dynamic Load Balancing and Deployments



This post is adapted from a webinar hosted at nginx.conf from September 22-24, 2015 by Derek DeJonghe.
Table of Contents
Introduction
Introduction; Who am I?; Topics; The Actors; Goals
Cloud and DevOps Concepts
Cloud and DevOps Concepts; Microservices; Microservice Complexity; Deploying with More Services; Continuous Deployment; Blue-Green; Blue-Green Deployment; Blue-Green Deployment with NGINX; AutoScaling; Autoscaling Example; Elastic Load Balancer; Why NGINX?
ZooKeeper and NGINX
Service Discovery; ZooKeeper; Znode Example; How They Work; Node Client; NGINX Client; The Upstream Pools; Application x Version; Pseudocode for Upstream Pools; Result; Requests; Requests Example; Request to Upstream; Request Pseudocode
Outcomes
The Deploys; Deploys; Deploy Example; The Outcome; Before Implementation; After Implementation; Impact; Questions
0:00 Introduction

Welcome, thank you guys for joining me today at NGINX.conf. I’m here to talk about dynamic load balancing and deployments with NGINX and Zookeeper. I’m here to tell you why you should invest in your traffic controller and talk about the heart of the systems that I build in my everyday work life.
0:41 Who am I?

First of all, who am I? My name is Derek DeJonghe; I’m a cloud solutions architect and NGINX enthusiast – so much so that my advocacy has made NGINX our default go-to for web surfing and proxy in my organization.
I’m certified by Amazon Web Services, and I work for a company called Right Brain Networks. We are an advanced consulting partner and managed service provider for AWS and Azure. We help companies migrate into AWS to revolutionize their workflow by bringing in CI/CD and infrastructure as code, as in infrastructure management and configuration management.
We typically deal with SAS systems, services that are provided to the world, etc. I’m also in embedded consulting roles of larger organizations, as well as running lots of systems for smaller organizations.
2:05 Topics

So today, we’re going to have a few topics. We’re gonna briefly cover some reasons why we’re doing things like this; we’re going to talk about who our actors are and what our goals are. We’re going to cover some basic cloud concepts and DevOps.
We’re going to talk about what I mean when I talk about dynamic load balancing. We’re gonna explain some of the obstacles around microservices and autoscaling distributed architecture.
I’ll detail some of the processes around releasing code and what that means in dynamic infrastructure and how NGINX and service discovery can be utilized to impact these solutions.
3:03 The Actors

So who are my actors? Actors are your end user. So what do our users want? They want zero downtime; they don’t want to have to wait for maintenance mode for new features or bug fixes, and they certainly don’t want malformed requests.
Our other actors are the teams that are developing the software. They want to spend less time deploying. They want less effort for deploying. They want to spend their time doing what they do best and that’s developing and moving forward with the product.
3:57 Goals

So what are our goals here? We want to automate live index and code deployments. We want to update things more often. We want to eliminate the need for lengthy deployments and the resources around those deployments.
Have you guys ever seen it war room setup stacked to the brim with snacks and people sitting there for 36 hours straight? We need to get away from that.
We want to eliminate the need for overcapacity of data centers. We want zero service disruption. We want to make sure that every request is sent to the right application server and the right version. We also want dynamic load balancing because in my world, everything is built in the cloud; this is a problem that I have to solve day in and day out.
5:06 Cloud & DevOps Concepts

Let’s cover a couple cloud and DevOps concepts.
5:18 Microservices

With the drive to the cloud, a lot of companies are decoupling their monolithic application servers and going with microservices. This concept makes many different distributed services that all work together to provide your service or product.
Microservices allow you to scale on a very granular level, which saves on cost and allows developers to get their work done more cleanly and push it out more efficiently. Cloud and microservices go together like engineers and coffee. An engineer might not actually need their coffee, but they work a little better with it; it’s the same idea with cloud and microservices.
Being able to scale at that granular level, just saying, “Okay, we’re getting a lot of authentication requests; we need to scale up just one portion of the application rather than some work around the back-end that might not be under such load.”
6:44 Microservice Complexity
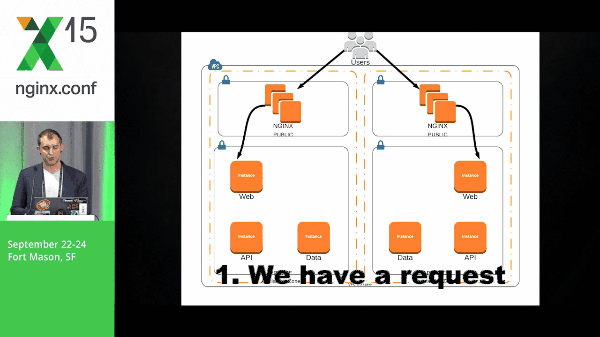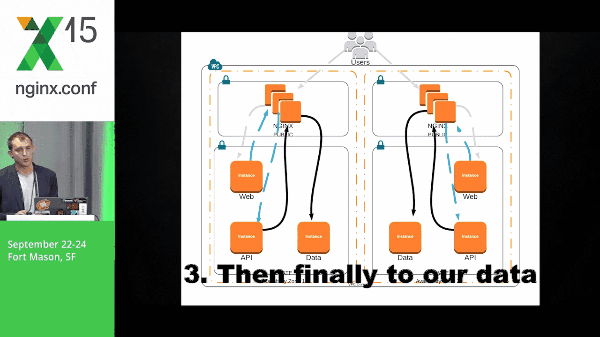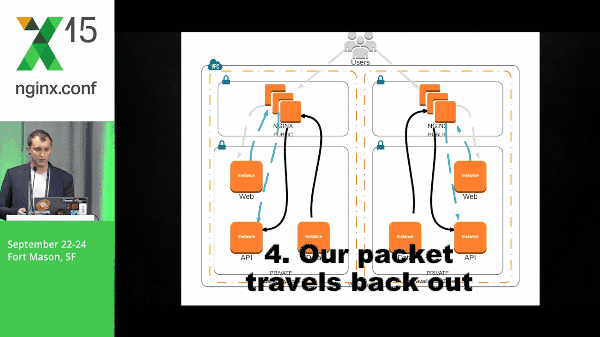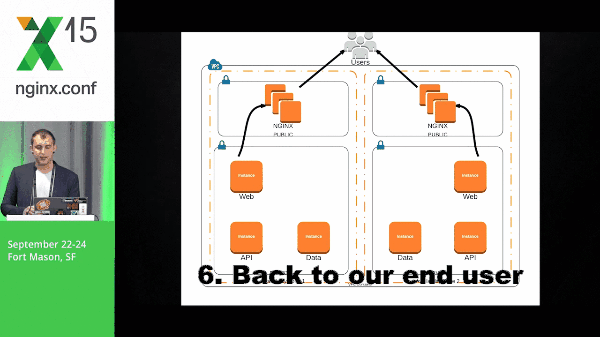
Microservices definitely causes a little bit of complexity when you’re deploying and in your environment as a whole. So let’s take a look at a pretty simple architecture and what it might look like for a packet to run through this. We have a request that hits our web layer, back to NGINX, goes to our API layer, and then finally to our data.
It’s important to note that the data that I’m talking about in this particular example are Solr shards: they’re immutable, they’re static data, and we’ve got multiple shards.
With that, our packet travels back out through the stack, back to the end user.
7:20 Deploying with More Services

You can see how much more complicated this can get if we had another service, or 10 services. Deploying to these is going to be a little bit more complex when you want to offer that zero downtime, high availability.
7:35 Continuous Deployment

Continuous delivery is a completely automated system. It allows you to spend less time doing release work, increases your productivity, and insures more reliable releases. It decreases your time to market for things like: new features, blogs, etc. That improves your product quality.
It increases your customer satisfaction because you’re smashing those bugs and releasing those new features faster. You don’t have to wait for deploy time where we have to put up that war room and there’s tons of people. It gives you more time to focus on what really matters – moving forward with your product.
8:34 Blue-Green

So another concept of this continual deployment, zero downtime, etc., is the blue-green deployment. It’s one of the most sought-after deployment styles of today. This deployment style allows you to seamlessly direct traffic to a new version of the application code running on separate sets of infrastructure.
The fulcrum of these deployments is the traffic router, whether it be DNS or something like a proxy with NGINX. These deployments offer zero down time and the ability to switch back to the older version if things go wrong. This lowers the the stress of the engineering team and increases your, again, customer satisfaction. You have zero downtime, and that’s exactly what we’re looking for.
9:33 Blue-Green Deployment
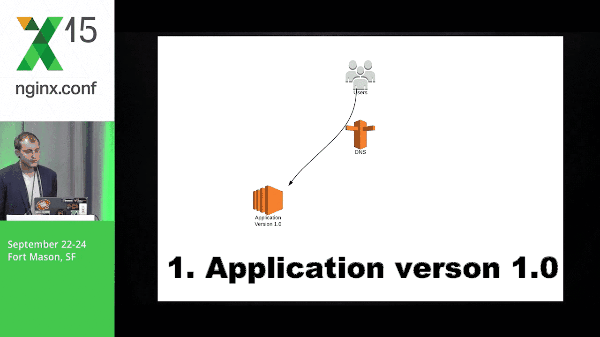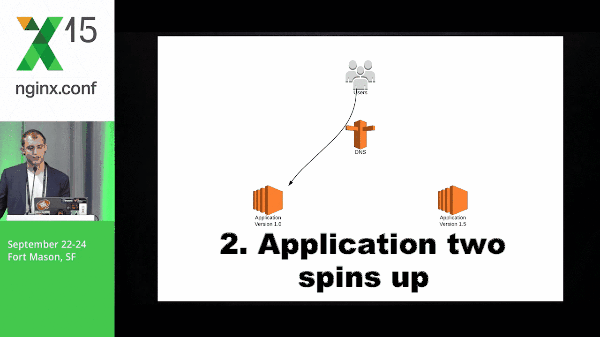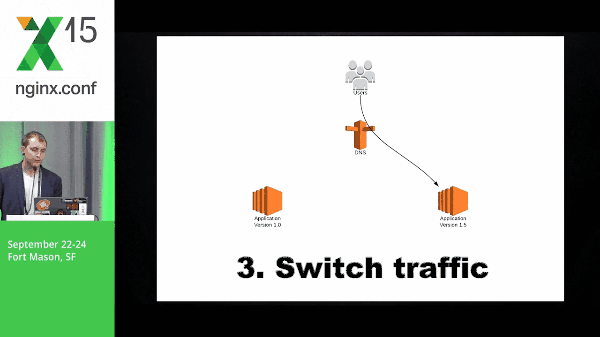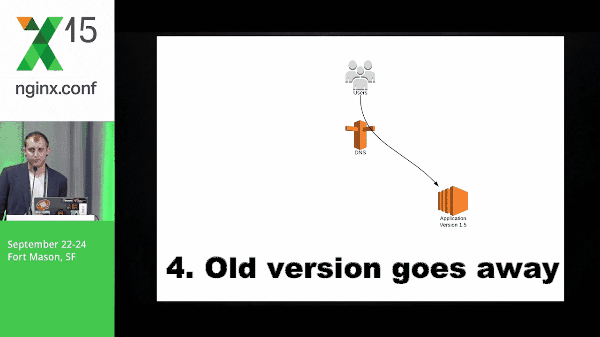
So this is a quick diagram of what blue-green might look like. You have application version 1.0, application 2 spins up, you switch traffic, and the old version goes away.
9:47 Blue-Green Deployment with NGINX
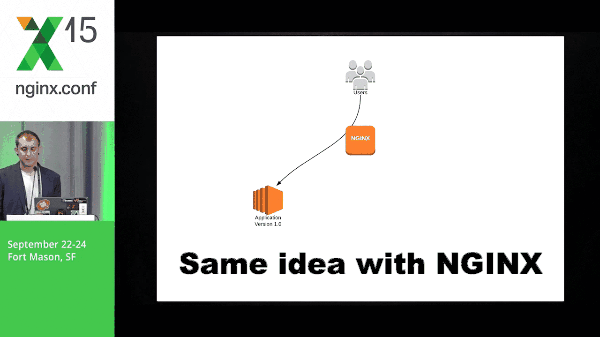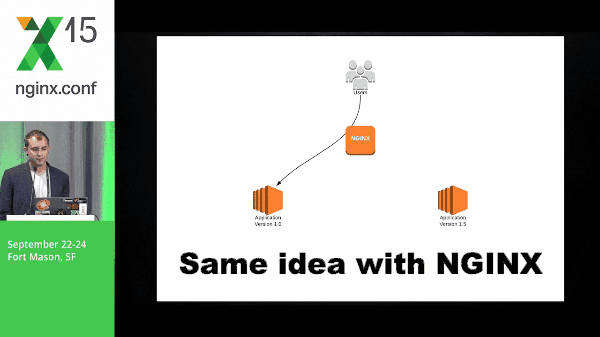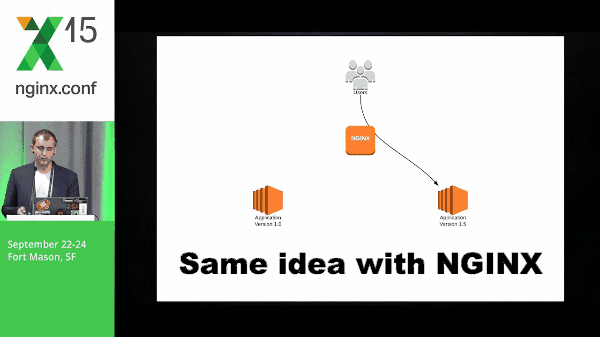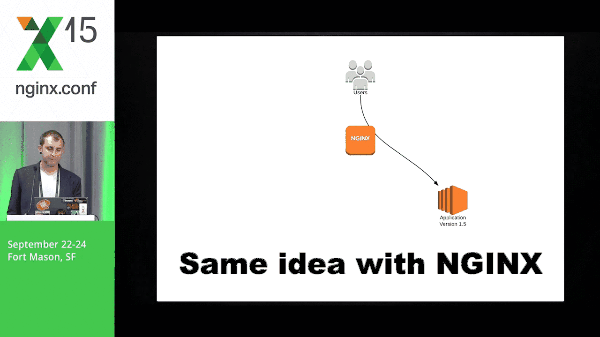
Same idea with NGINX, but the idea here is that NGINX is able to do this a lot more cleanly than DNS because we don’t have to wait for things like TTL; there’s a lot of inconsistency around that. You don’t know exactly when things are going to switch, what application servers are going to switch, at what time, etc. So this is why doing it with NGINX is the preferred way for me.
10:13 AutoScaling

We’ll just cover AutoScaling briefly because it does present a lot of problems. So some of these obstacles when you’re scaling horizontally to increase your performance under load, you’re gonna have very dynamic back-end infrastructure; your deployment has to change. It’s not SSHing into boxes and swapping out code, or just get polling anymore; things are vastly different.
Being able to load balance is one of the problems that we’ve been trying to tackle. This means when we have servers spin up, we want to make sure that they get put into the back-end pool. We want to make sure that if they die or scale down, they’re removed from the back-end. With products like the dynamic elastic balancer or NGINX Plus, that’s solved for us.
11:24 Autoscaling Example
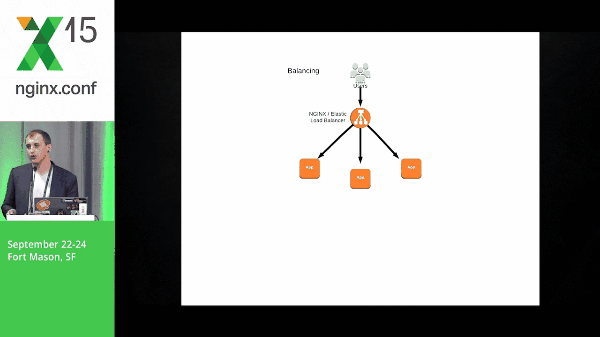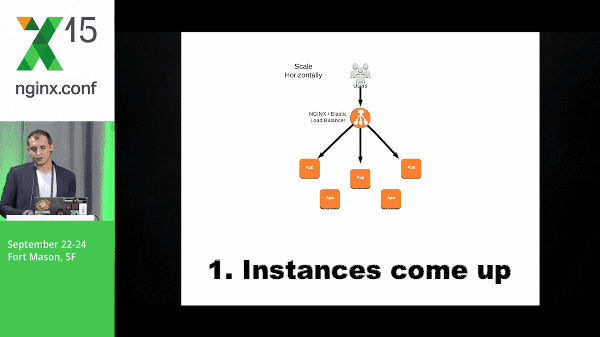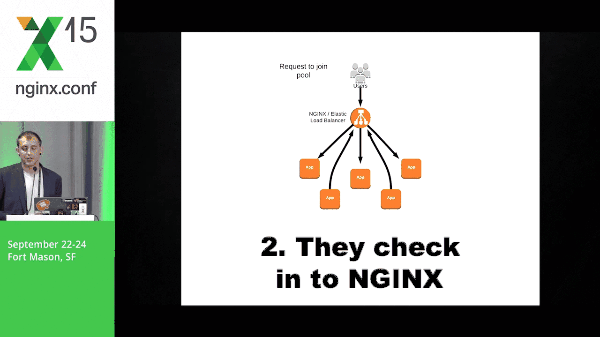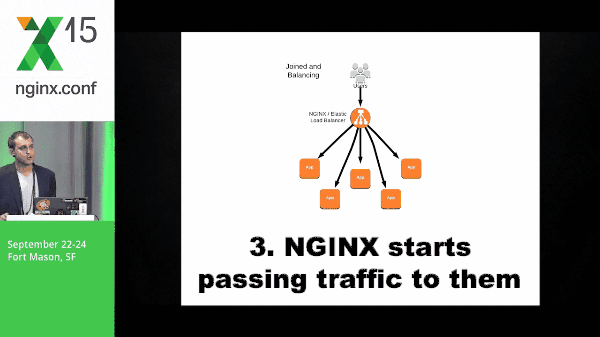
Instances come up, they check in to NGINX, and NGINX starts passing traffic to them.
11:33 Elastic Load Balancer

So why NGINX? Let’s talk about why not the Elastic Load Balancer real quick. This Elastic Load Balancer offers a lot of great things like dynamic load balancing where your instance comes up, it checks in, and it starts getting passed traffic. That solves a lot of problems for a lot of teams. It’s a really great product and it does what it does very well; however, we have some problems here.
It only has a single back-end pool, no context switching, and one of the biggest pains is that once an instance registers, it has a minimum of four seconds before being passed traffic; this is because of the health check. It has to pass two health checks and the interval must be two seconds or more.
That’s a huge issue when trying to use an Elastic Load Balancer for dynamically switching out versions unless you’re doing something like DNS to point to a different load balancer, which again we come back to the issue of TTL issues and DNS caching.
The need for a more sophisticated deployment and traffic router is greatly increased by the use of microservices because we want to be able to do the context switching and dynamic load balancing, and we need to be able to do deployments.
13:22 Why NGINX?

For me, NGINX is this perfect Venn diagram with equal parts rocket ship and bicycle, it has high speed and low resource footprint, it’s scalable, and it’s highly configurable. Also, the Lua aspect of this allows us to do so much header manipulation that we can do whatever we need to.
The other part is this seamless reload; this is this is a feature that a lot of other proxies are missing. NGINX is able to do decision-making, context switching, routing these requests to exactly where they need to go seamlessly.
14:19 Service Discovery

Let’s move on to the interesting stuff. How does service discovery fit into this?
14:28 ZooKeeper

Now I’m going to be talking about ZooKeeper, and a lot of people here probably asking, “Why not Console?” The answer is that I’m a consultant. I get put into larger organizations and I don’t always good to make all the technology decisions. In this particular case the team was moving toward SolrCloud and wanted to implement ZooKeeper so that they were ready for that.
ZooKeeper is a centralized configuration store. This is where you might store all of your metadata about a server, all these roles, all of its data models that it’s running, things to that effect. ZooKeeper clusters and scales really nicely. it’s a publish/subscribe system; that means that we’re not only able to push to get to it and pull data out of it, but you’re able to subscribe to different events within the system and you register callbacks to be had when an event takes place or data is presented.
All the services in the environment are always connected to the ZooKeeper. If a node falls off the face of the earth, their connections dropped that, and that node is no longer in connection to the ZooKeeper. So with that, what I’m talking about here is the socket between the two, so things are really fast. There’s not a connection being opened and closed, we’re always connected.
Znodes are what the data is actually called; it’s a blob of any data limited to one megabyte. The znodes are stored in a very Unix-like directory structure, which is pretty comfortable for most people. You have a child and parent nodes which can both hold data.
17:12 Znode Example

Let’s take a look at a znode example. Let’s go ahead and get the route, we have a few easy notes here (API, web, NGINX), so let’s take a look at what NGINX is holding for us. I listed out a unique identifier, so these are all my NGINX nodes that are currently running connected to the system. Let’s go ahead and ask for the data within one of those nodes. Here we’ll see things like IP, release version, things to that effect.
17:57 How They Work

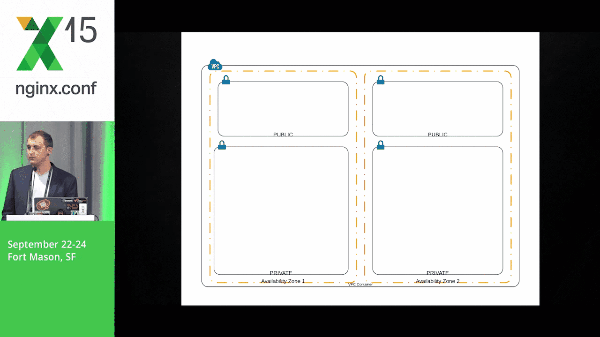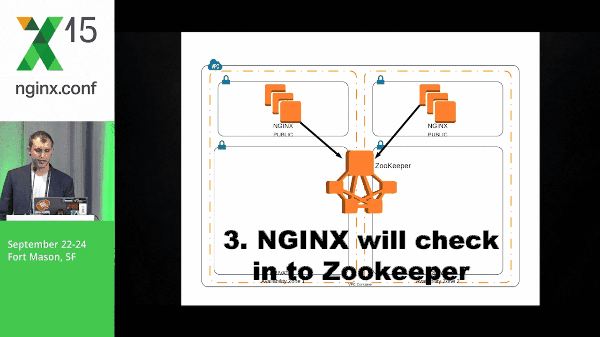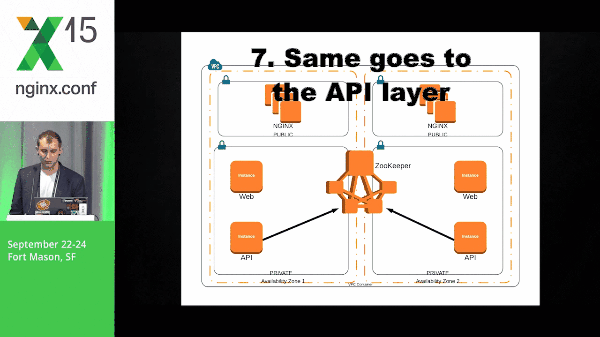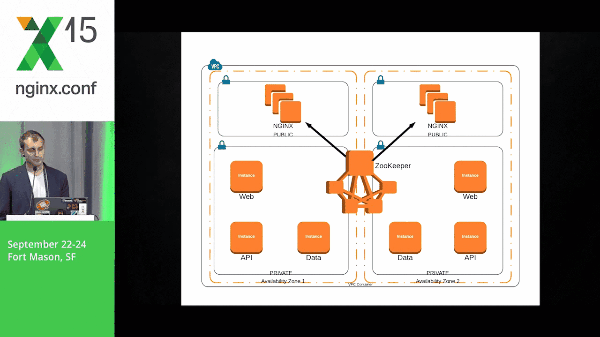
So how do these systems work together? So, here we’re going to stand up ZooKeeper, we’re going to build our NGINX boxes, and NGINX will check in with ZooKeeper. We’ve got our web layer which, again, check in to ZooKeeper.
However, here, the NGINX box has a subscribe to the web layer znodes. So, this event is pushed out to the NGINX boxes. The NGINX client will know what to do with that information and template its configuration accordingly. The same goes for the API layer and the data layer.
18:53 Node Client

Let’s talk about this Node client. What are we doing here? We’re grabbing data; anything I can find about myself, we’re doing self-discovery. We’re going ahead and putting that into a znode structure that’s based on: the environment it’s running in, the role of the application, and then finally a unique identifier.
These can be built in very modular ways. For instance, most of the Node clients were very common; all they need to do is just dump data into the system so that NGINX could find it and act accordingly. The information we put in here is actually pretty important. We want to be able to know exactly what the IP is and definitely the release. This is going to build as we get further into exactly what’s happening with the deployment.
You can really put anything pertinent into it, the things you might find in environment variables. Given that discovery, the node will be able to construct the znode path in a meaningful way and with that, we’ll have something that looks something like this. We have what we call ephemeral nodes inside of this structure, meaning that if the connection is never severed between the node and the ZooKeeper, that node will then disappear.
This means that we don’t have to clean up after ourselves, it’s done for us, and if there’s ever a blip in connectivity, then we’re no longer routing traffic to that host. I decided to store my my configuration data in JSON format because it’s independent of languages. I was using an orchestrator written in Ruby and all my notes were in Python, so it was a very common language to be able to communicate across.
20:58 NGINX Client

The NGINX client provides all of your functionality and decision-making. The NGINX client might do the same things that the node client will by putting its data into ZooKeeper and setting up the structure; however, one thing that’s gonna do differently is that it’s gonna subscribe to different nodes and different parent nodes in the ZooKeeper directors.
This client would also ask questions, getting information about the different services in the environment so that it’s able to temper its configuration and make changes accordingly.
This is done via templating and configuration files. My NGINX client included the templates for these different configuration files, things like templates of pools, variable changes, mappings, and even being able to produce full servers.
So I talked about my data example being Solr. Now, running a Solr cluster, you might have two nodes, you might have ten nodes, your dev environment might have ten nodes, and your prod environment might have 200.
Setting up the NGINX rules for those is boring, nobody wants to do that. So, with this we’re able to dynamically find out how many shards there are and template out all of the servers so that we’re able to not have to type all that out and it just dynamically generates all of the services.
The NGINX client might want to know things about health for all those boxes, if something’s not acting appropriately or serving requests appropriately. They can do health checks on the local node, put that into ZooKeeper and say, “Hey I’m healthy, pass me traffic,” or, “We’re getting 500s over here, don’t send me more traffic, we need to figure this stuff out.”
It also wants to know when things register to the system and when things disappear from the system. That gives us the ability to template out those pools very efficiently. You can also do things like load. If you have an API that takes large data sets, small data sets, and one’s really cranking away at things, you can say, “This server is under a lot of load. Let’s send less requests to this and point it somewhere else.”
The NGINX will register call-backs around all these different parent or child nodes that they’re subscribed to, and that callback is going to work appropriately to reconfigure its configuration. This is our dynamic load balancing
24:05 The Upstream Pools

So let’s talk about the upstream pools.
24:08 Application x Version

So the pools are created dynamically based on the znodes in the environment. Instances are pooled by application and versions. That’s something that’s a little bit different, I would say. We’re not really load balancing over the service or number of servers, but really what we’re doing is we’re load balancing over the version and the application. All the upstream services must pass health checks, etc.
24:43 Pseudocode for Upstream Pools

So here’s a little bit of pseudocode. I’m templating this out, very very simple. You can also put the port in there; you can see how this might drop into something like a containerized environment.
24:55 Result

It will end up with something like this.
24:59 Requests

What happens when a request comes into our system?
25:09 Requests Example
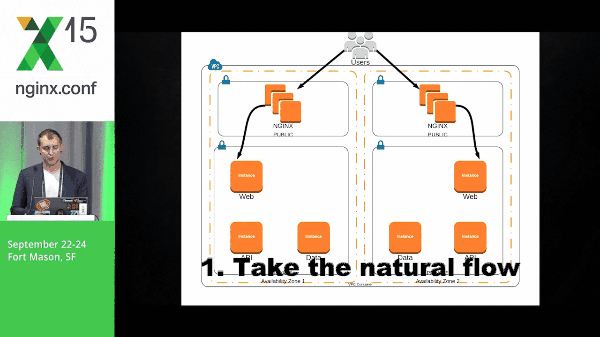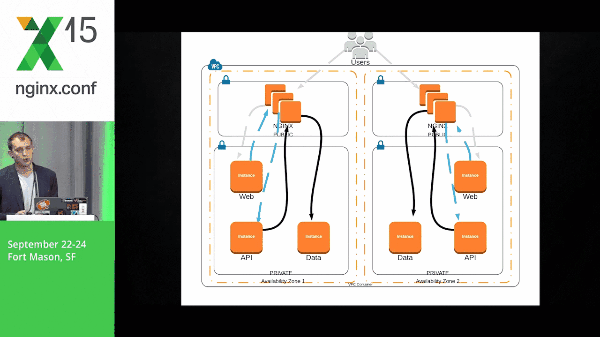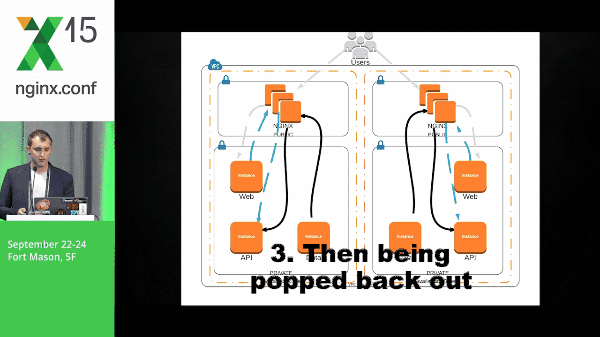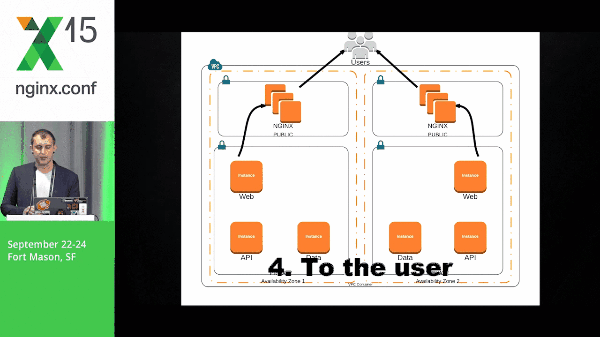
It’s going to take that natural flow, moving through the application stack, and then being popped back out to the user.
25:21 Request to Upstream

Here we’re doing context switching on the hostname I was provided. Okay, we’re going to go to this particular application. Also, we’re going to take a look at the request and what version it’s bound for. The version header is mapped to the application pool by different versions of this application that we’re load balancing over, and we’re going to route that traffic properly.
26:13 Request Pseudocode

So here’s a map of what the request version might be for a particular request and direct it to a pool so that we’re able to proxy this request to a particular pool based on, not only the application, but the version as well.
26:36 The Deploys


So this is the meat of it; how our deploys really work.
26:55 Deploys

A new server is built, health checks are passed, NGINX templates the pools, then orchestration might change the NGINX version by making an alteration to the NGINX node. The NGINX client is actually watching its own znode for changes so that an outside force can actually change its version.
At that point, NGINX will go ahead and retemplate its configuration saying that, “My current release version is 1.2.4, where the previous version might be 1.2.3.” This is actually pretty important because of how the request actually gets tagged. The request is tagged if it doesn’t have a version within the system; that request will flow through the different services tagged with a particular release.
As the client notices a change to the NGINX release version, it goes ahead and retains its configuration and directs traffic to the newest version for any new request.
Now, what happens when you have a request that’s in mid-flight between all these different microservices? You just switched versions on it. That seamless switch for the blue-green is great in theory, but if you have a coupled service that is expecting a reply a certain way and you switch its version, it’s going to get a different reply and you’re going to have a malformed request. That’s the issue we’re trying to solve.
28:48 Deploy Example

The idea here is that if we were to build services in the middle of a microservice request, it might end up going to the wrong node. We don’t want that to happen. So, if we switch versions, even though NGINX is on a newer version, we’re able to direct the request to the 1.2 version appropriately.
29:42 The Outcome


The outcome here is that we’re highly available, we don’t have any maintenance windows, we have zero downtime, zero malformed requests, we update our data and our code more frequently, faster, and of course with less headaches.
30:07 Before Implementation

Effectively turning deploys from something like this…
30:16 After Implementation

…into something like this.
30:23 Impact

The impact is higher customer satisfaction, higher engineer satisfaction, higher productivity, and a better product.
30:35 Questions

Thank you, my name again is Derek DeJonghe, I work for Right Brain Networks. I suppose I have a few minutes here for questions:
- Reloading – No, there’s an external process that’s continually running. It’s a daemon that keeps an eye on all these things, it’ll reload.
- Open sourcing – Not at the moment. It was built for the company. the idea is mine, but it’s their code.
- Library usage – The Python library for ZooKeeper is called Kazoo. It’s actually has a nice retry mechanism that let you take the appropriate steps to reconnect if if there is a separate connection or timeout.
- ZooKeeper communication – Yeah absolutely, if it can’t talk to ZooKeeper, it’s not gonna re-template it’s configuration.
- Load balancing – If you’re running microservices, you might have upwards of thirty different services in your environment for your product offering or service, and to be able to do that with the ELBs, you’re gonna need to run thirty ELBs. That’s a huge waste of cost, it’s harder to work with and work around. The idea would be to replace all those multiple ELBs with a system that is dynamic, and does context switching over multiple pools, different application services, and versions.
- Health checks – So that is through the publish and subscribe system. This is an idea where you can tell ZooKeeper, “I want to get updates about any event to any of these Znodes.” That actually sends a message back to the client, and the client has a callback function that runs and does that. So it’s a small client the runs on each node. The node client is there on each node, it doesn’t matter what services it is, it’s just sitting there at any interval you want. it’ll just check It’s health, make sure things are running appropriately, send information back if things change. When something does change, ZooKeeper will notify the client on all of the NGINX boxes.
- Tools – So what I would say to that question is that: Puppet, Chef, and Saltstack is our go-to. Those are used to set things up. They’re used to configure the NGINX box and set up the client, and they’re used to setup the NGINX nodes and cluster them, things to the effect. If you were to run something like this with Chef or Puppet, my feeling is that it might be a little bit slower and might need a little bit more engineering work to do that discovery and figure out what’s going on and route things appropriately. it’s definitely doable, absolutely doable, but with service discovery the pub sub is really what makes things fast and reliable. I know Chef is moving towards a push-pull model, Salt’s already there, I’m not entirely sure about Puppet, but having that subscribe is really what makes this a big difference.
- ZooKeeper clusters – You can connect any number of them and they all have the same information. They all have chatter between them and they’re just in a cluster together. I think there is a little bit of work to be done around actually having scaling ZooKeeper. With regards to the clustering itself – Netflix has an open source product that does it for you I think it’s called exhibitor.
Thank you guys for coming and listening to me talk.
The post NGINX and Zookeeper, Dynamic Load Balancing and Deployments appeared first on NGINX.
Source: NGINX and Zookeeper, Dynamic Load Balancing and Deployments