


Oracle의 사용자 정의 타입(user-defined types)을 PostgreSQL로 변환하기

기존 상용 데이터베이스에서 오픈 소스로 마이그레이션은 평가(Assessment)로부터, 데이터 변환, 유효성 검사 및 컷 오버까지 여러 단계의 프로세스가 있습니다. 특히, 이기종 데이터베이스 마이그레이션의 가장 주요 항목 중 하나가 바로 데이터 타입의 변환입니다.
이 글에서는 Oracle 데이터베이스에서 Amazon Aurora PostgreSQL 또는 Amazon RDS for PostgreSQL로 사용자 정의 타입(UDT, User-defined types)을 마이그레이션하는 단계별 접근 방식을 알아보려 합니다. 또한 PostgreSQL에서 UDT를 사용하여 테이블에 액세스하기 위해 SQL 쿼리에서 사용하는 사용자 지정 연산자(Custom Operator)에 대한 개요도 설명합니다.
1. 사용자 정의 타입(UDT) 변환 과정 개요
Oracle에서 사용하는 UDT를 Aurora PostgreSQL 또는 Amazon RDS PostgreSQL로 마이그레이션하는 것은 UDT 멤버 함수를 사용해야 됨으로 간단하지는 않습니다. Oracle 및 PostgreSQL에 정의 된 UDT는 구조화 된 비즈니스 데이터를 자연스러운 형태로 저장하고 객체 지향 프로그래밍 기술을 사용하여 애플리케이션과 효율적으로 작동합니다. Oracle의 UDT는 관계형 모델 내에서 해당 데이터에 대해 작동하는 데이터 구조와 메서드를 모두 가질 수 있습니다. 유사하지만 멤버 함수를 사용하여 Oracle 및 PostgreSQL에서 UDT를 구현하는 방법은 미묘한 차이가 있습니다.
Oracle의 UDT을사용하는 테이블을 PostgreSQL로 마이그레이션하는 데는 다음 단계로 진행됩니다:
- UDT 변환 – AWS Schema Conversion Tool (AWS SCT)을 사용하여 기존 데이터베이스 스키마를 원본 데이터베이스 엔진에서 다른 데이터베이스 엔진으로 변환 할 수 있습니다. PostgreSQL과 달리 Oracle의 사용자 정의 타입을 사용하면 PL / SQL 기반 멤버 함수가 UDT의 일부가 될 수 있습니다. PostgreSQL은 UDT에서 멤버 함수를 지원하지 않기 때문에 UDT 변환 중에 별도로 처리해야합니다.
- UDT을 사용하는 테이블에서 데이터 마이그레이션 – AWS Database Migration Service (AWS DMS)는 Oracle 데이터베이스에서 Aurora PostgreSQL 및 Amazon RDS PostgreSQL로 데이터를 마이그레이션하는 데 도움이됩니다. 현재 AWS DMS는 UDT를 지원하지 않습니다. 이 게시물은 오픈 소스 도구 Ora2pg를 사용하여 UDT가있는 테이블을 Oracle에서 PostgreSQL로 마이그레이션하는 방법을 설명합니다.
준비하셔야 할 부분
시작하기 전에 다음 필수 구성 요소가 있어야합니다:
- 로컬 데스크탑 또는 Amazon Elastic Compute Cloud (Amazon EC2) 인스턴스에 설치된 AWS SCT가 필요합니다. AWS SCT 설치, 확인 및 최신 버전 업데이트에 대한 내용은 각 링크를 참조하십시오.
- EC2 인스턴스에 Ora2pg가 설치 및 설정되어 있어야 합니다. 관련 자료는 Ora2pg 설치 안내서를 참조하십시오. Ora2pg는 GPLv3 라이선스를 통해 배포되는 오픈 소스 도구입니다.
- Ora2pg 및 AWS SCT에 사용되는 EC2 인스턴스는 Oracle 소스 및 PostgreSQL 대상 데이터베이스에 연결할 수 있어야 됩니다.
데이터 세트
이 글에서는 스포츠 이벤트 티켓 관리 시스템의 샘플 데이터 세트를 사용합니다. 이 사용 사례의 경우 이벤트 위치 좌석 세부 정보가 포함 된 DIM_SPORT_LOCATION_SEATS 테이블이 UDT로 location_t를 포함하도록 수정되었습니다. location_t에는 스포츠 이벤트 위치 및 좌석 수에 대한 정보가 포함 되어 있습니다.
Oracle UDT location_t
UDT location_t에는 위치의 현재 좌석 수를 스포츠 이벤트의 예상 점유율과 비교하는 인수 기반 멤버 함수를 포함하여 스포츠 이벤트 위치 세부 정보를 설명하는 속성이 있습니다. 이 함수는 이벤트에 대한 예상 점유율을 인수로 취하고 이벤트 위치의 현재 좌석 수용 능력과 비교합니다. 스포츠 이벤트 위치에 이벤트를위한 충분한 좌석이 있으면 t를 반환하고 그렇지 않으면 f를 반환합니다. 다음 코드를 참조하십시오:
create or replace type location_t as object (
LOCATION_NAME VARCHAR2 (60 ) ,
LOCATION_CITY VARCHAR2 (60 ),
LOCATION_SEATING_CAPACITY NUMBER (7) ,
LOCATION_LEVELS NUMBER (1) ,
LOCATION_SECTIONS NUMBER (4) ,
MEMBER FUNCTION COMPARE_SEATING_CAPACITY(capacity in number) RETURN VARCHAR2
);
/
create or replace type body location_t is
MEMBER FUNCTION COMPARE_SEATING_CAPACITY(capacity in number) RETURN VARCHAR2 is
seat_capacity_1 number ;
seat_capacity_2 number ;
begin
if ( LOCATION_SEATING_CAPACITY is null ) then
seat_capacity_1 := 0;
else
seat_capacity_1 := LOCATION_SEATING_CAPACITY;
end if;
if ( capacity is null ) then
seat_capacity_2 := 0;
else
seat_capacity_2 := capacity;
end if;
if seat_capacity_1 >= seat_capacity_2 then
return 't';
else
return 'f';
end if;
end COMPARE_SEATING_CAPACITY;
end;
/Oracle 테이블 DIM_SPORT_LOCATION_SEATS
아래 코드는 Oracle에서 UDT인 location_t 를 포함하는 DIM_SPORT_LOCATION_SEATS 테이블의 DDL 입니다:
CREATE TABLE DIM_SPORT_LOCATION_SEATS
(
SPORT_LOCATION_SEAT_ID NUMBER NOT NULL ,
SPORT_LOCATION_ID NUMBER (3) NOT NULL ,
LOCATION location_t,
SEAT_LEVEL NUMBER (1) NOT NULL ,
SEAT_SECTION VARCHAR2 (15) NOT NULL ,
SEAT_ROW VARCHAR2 (10 BYTE) NOT NULL ,
SEAT_NO VARCHAR2 (10 BYTE) NOT NULL ,
SEAT_TYPE VARCHAR2 (15 BYTE) ,
SEAT_TYPE_DESCRIPTION VARCHAR2 (120 BYTE) ,
RELATIVE_QUANTITY NUMBER (2)
) ;2. UDT 데이터 변환하기
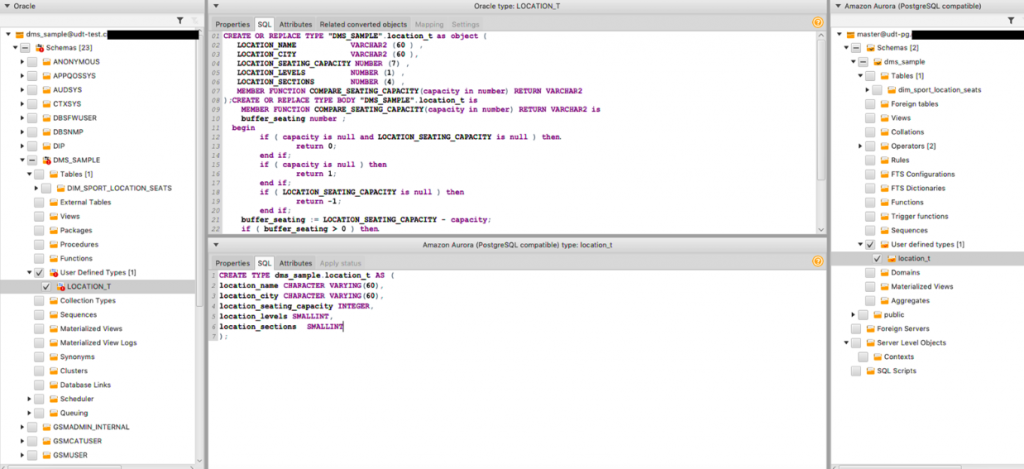
Oracle에서 PostgreSQL로 location_t 및 테이블 DIM_SPORT_LOCATION_SEATS의 DDL 변환부터 시작하겠습니다.
AWS SCT를 사용하여 기존 데이터베이스 스키마를 Oracle에서 PostgreSQL로 변환 할 수 있습니다. 대상 PostgreSQL 데이터베이스는 UDT에서 멤버 함수를 지원하지 않기 때문에 AWS SCT는 UDT를 Oracle에서 PostgreSQL로 변환하는 동안 멤버 함수를 무시합니다. PostgreSQL에서는 Oracle UDT가 멤버 함수에서 수행하는 것과 유사한 기능을 갖도록 연산자를 사용하여 PL/pgSQL에서 함수를 만들 수 있습니다.
이 샘플 데이터 세트의 경우 AWS SCT를 사용하여 location_t를 PostgreSQL로 변환 할 수 있습니다. AWS SCT는 location_t에 대한 멤버 함수의 DDL을 Oracle에서 PostgreSQL로 변환하지 않습니다.
다음 이미지는 SQL 코드를 보여줍니다.

PostgreSQL UDT location_t
AWS SCT는 스키마 매핑 규칙을 기반으로 Postgres 최적화를 위해 LOCATION_LEVELS 및 LOCATION_SECTIONS를 location_t UDT에서 SMALLINT로 변환합니다. 다음 코드를 참조하십시오:
create TYPE location_t as (
LOCATION_NAME CHARACTER VARYING(60) ,
LOCATION_CITY CHARACTER VARYING(60) ,
LOCATION_SEATING_CAPACITY INTEGER ,
LOCATION_LEVELS SMALLINT ,
LOCATION_SECTIONS SMALLINT
);스키마 매핑에 대한 자세한 내용은 AWS SCT에서 매핑 규칙 생성을 참조하십시오.
PostgreSQL은 UDT에서 멤버 함수를 지원하지 않기 때문에 AWS SCT는 DDL을 Oracle에서 PostgreSQL로 변환하는 동안 이를 무시합니다. PL/pgSQL 함수를 별도로 작성해야합니다. 별도의 엔터티를 작성하려면 멤버 함수에 UDT 개체 매개 변수를 추가해야 할 수 있습니다. 사용 사례에서 compare_seating_capacity 멤버 함수는 별도의 PL/pgSQL 함수로 다시 작성됩니다. PostgreSQL은 true 또는 false에 대해 bool 데이터 유형을 제공하기 때문에이 함수의 반환 데이터 유형은 varchar2 (Oracle) 대신 bool입니다. 다음 코드를 참조하십시오:
CREATE or REPLACE FUNCTION COMPARE_SEATING_CAPACITY (event_loc_1 location_t,event_loc_2 integer) RETURNS bool AS
$$
declare
seat_capacity_1 integer;
seat_capacity_2 integer ;
begin
if ( event_loc_1.LOCATION_SEATING_CAPACITY is null ) then
seat_capacity_1 = 0 ;
else
seat_capacity_1 = event_loc_1.LOCATION_SEATING_CAPACITY;
end if;
if ( event_loc_2 is null ) then
seat_capacity_2 = 0 ;
else
seat_capacity_2 = event_loc_2 ;
end if;
if seat_capacity_1 >= seat_capacity_2 then
return true;
else
return false;
end if;
end;
$$ LANGUAGE plpgsql;UDT 변환이 완료되어 PostgreSQL에서 PL/pgSQL 함수와 UDT가 생성됩니다. 이제 다음 스크린 샷과 같이 AWS SCT를 사용하여 PostgreSQL 대상 데이터베이스에서이 UDT를 사용하여 테이블에 대한 DDL을 생성 할 수 있습니다.


다음에는 Oracle의 UDT가 포함 된 테이블에서 Oracle에서 PostgreSQL로 데이터를 마이그레이션하는 방법에 대해 알아 봅니다.
3. UDT가 포함된 테이블의 데이터 마이그레이션하기
여기서는 오픈 소스 툴인 Ora2pg를 사용하여 Oracle에서 PostgreSQL로 UDT가 존재하는 DIM_SPORT_LOCATION_SEATS 테이블의 전체 로드를 수행합니다. EC2 인스턴스에 Ora2pg를 설치하고 설정하려면 Ora2pg 설치 안내서를 참조하십시오.
Ora2pg를 설치 한 후 Oracle 소스 및 PostgreSQL 대상 데이터베이스와의 연결을 테스트 할 수 있습니다.
Oracle 연결을 테스트하려면 다음 코드를 참조하십시오:
$ cd $ORACLE_HOME/network/admin
$ echo "oratest=(DESCRIPTION =(ADDRESS = (PROTOCOL = TCP)(HOST = oratest.xxxxxxx.us-west-2.rds.amazonaws.com )(PORT =1526))(CONNECT_DATA =(SERVER = DEDICATED) (SERVICE_NAME = UDTTEST)))" >> tnsnames.ora
-bash-4.2$ sqlplus username/password@oratest
SQL*Plus: Release 11.2.0.4.0 Production on Fri Aug 7 05:05:35 2020
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Connected to:
Oracle Database 12c Enterprise Edition Release 12.2.0.1.0 - 64bit Production
SQL>Amazon Aurora for PostgreSQL 연결을 테스트하려면 다음 코드를 참조하십시오:
$ psql -h pgtest.xxxxxxxx.us-west-2.rds.amazonaws.com -p 5436 -d postgres master
Password for user master:
psql (9.2.24, server 11.6)
WARNING: psql version 9.2, server version 11.0.
Some psql features might not work.
SSL connection (cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256)
Type "help" for help.
postgres=>Ora2pg로 Oracle에서 PostgreSQL로 데이터를 마이그레이션하기 위해서 구성 파일을 사용합니다. 다음은 이 샘플 데이터 세트에 사용되는 구성 파일입니다. Ora2pg에는 다양한 객체 유형을 복사하고 내보낼 수있는 많은 옵션이 있습니다. 이 예에서는 COPY를 사용하여 UDT를 사용하는 테이블을 마이그레이션합니다:
$ cat ora2pg_for_copy.conf
ORACLE_HOME /usr/lib/oracle/11.2/client64
ORACLE_DSN dbi:Oracle:sid=oratest
ORACLE_USER master
ORACLE_PWD xxxxxxx
DEBUG 1
EXPORT_SCHEMA 1
SCHEMA dms_sample
CREATE_SCHEMA 0
COMPILE_SCHEMA 0
PG_SCHEMA
TYPE COPY
PG_DSN dbi:Pg:dbname=postgres;host=pgtest.xxxxxxxxx.us-west-2.rds.amazonaws.com;port=5436
PG_USER master
PG_PWD xxxxxxxx
ALLOW DIM_SPORT_LOCATION_SEATS
BZIP2
DATA_LIMIT 400
BLOB_LIMIT 100
LONGREADLEN6285312
LOG_ON_ERROR
PARALLEL_TABLES 1
DROP_INDEXES 1
WITH_OID 1
FILE_PER_TABLE구성 파일에는 다음과 같은 주목할만한 설정이 있습니다:
- SCHEMA – 데이터 마이그레이션할 스키마 리스트 집합.
- ALLOW – 마이그레이션 할 개체 목록을 제공합니다. 개체 이름은 공백 또는 쉼표로 구분할 수 있습니다.
DIM_*와 같은 정규식을 사용하여dms_sample스키마에DIM_로 시작하는 모든 개체를 포함 할 수도 있습니다. - DROP_INDEXES – 데이터로드 전에 인덱스를 삭제하고 데이터 마이그레이션 후 대상 데이터베이스에서 인덱스를 다시 생성하여 데이터 마이그레이션 성능을 향상시킵니다.
- TYPE – 데이터 마이그레이션을위한 내보내기 유형을 제공합니다. 우리의 사례에서는
COPY문을 사용하여 데이터를 대상 테이블로 마이그레이션합니다. 이 매개 변수는 단일 값만 가질 수 있습니다.
Oracle에서 PostgreSQL로 데이터를 마이그레이션하기 위해 Ora2pg에서 사용 가능한 옵션에 대한 자세한 내용은 Ora2pg 설명서를 참조하십시오.
다음 코드에서는 이전에 생성 된 구성 파일을 사용하여 DIM_SPORT_LOCATION_SEATS 테이블을 Oracle에서 PostgreSQL로 마이그레이션합니다:
$ ora2pg -c ora2pg_for_copy.conf -d
Ora2Pg version: 18.1
Trying to connect to database: dbi:Oracle:sid=oratest
Isolation level: SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
Retrieving table information...
[1] Scanning table DIM_SPORT_LOCATION_SEATS (2 rows)...
Trying to connect to database: dbi:Oracle:sid=oratest
Isolation level: SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
Retrieving partitions information...
Dropping indexes of table DIM_SPORT_LOCATION_SEATS...
Looking how to retrieve data from DIM_SPORT_LOCATION_SEATS...
Data type LOCATION_T is not native, searching on custom types.
Found Type: LOCATION_T
Looking inside custom type LOCATION_T to extract values...
Fetching all data from DIM_SPORT_LOCATION_SEATS tuples...
Dumping data from table DIM_SPORT_LOCATION_SEATS into PostgreSQL...
Setting client_encoding to UTF8...
Disabling synchronous commit when writing to PostgreSQL...
DEBUG: Formatting bulk of 400 data for PostgreSQL.
DEBUG: Creating output for 400 tuples
DEBUG: Sending COPY bulk output directly to PostgreSQL backend
Extracted records from table DIM_SPORT_LOCATION_SEATS: total_records = 2 (avg: 2 recs/sec)
[========================>] 2/2 total rows (100.0%) - (1 sec., avg: 2 recs/sec).
Restoring indexes of table DIM_SPORT_LOCATION_SEATS...
Restarting sequences이제 UDT가 있는 DIM_SPORT_LOCATION_SEATS 테이블의 데이터가 PostgreSQL로 마이그레이션됩니다. PostgreSQL에서 search_path를 설정하면 dms_sample을 스키마 이름으로 명시하지 않고도 데이터베이스 세션의 SQL 문에서 참조 된 개체를 검색하는 스키마가 될 수 있습니다. 다음 코드를 참조하십시오:
postgres=> set search_path=dms_sample;
SET
postgres=> select sport_location_seat_id,location,seat_level,seat_section,seat_row,seat_no from DIM_SPORT_LOCATION_SEATS;
sport_location_seat_id | location | seat_level | seat_section | seat_row | seat_no
------------------------+----------------------------+------------+--------------+----------+---------
1 | (Germany,Munich,75024,2,3) | 3 | S | 2 | S-8
1 | (Germany,Berlin,74475,2,3) | 3 | S | 2 | S-8
(2 rows)4. PostgreSQL에서 UDT 쿼리하기
DIM_SPORT_LOCATION_SEATS 테이블의 DDL과 데이터가 모두 PostgreSQL로 마이그레이션 되었으므로 새로 생성 된 PL/pgSQL 함수를 사용하여 UDT를 쿼리 할 수 있습니다.
UDT 멤버 함수를 Oracle에서 쿼리하기
다음 코드는 독일의 경기장에 75,000 명 이상의 좌석이 있는지 확인하기위한 SQL 쿼리의 예입니다. 데이터 세트는 베를린과 뮌헨에있는 경기장의 좌석 수 정보를 제공합니다:
SQL> select t.location.LOCATION_CITY CITY,t.LOCATION.COMPARE_SEATING_CAPACITY(75000) SEATS_AVAILABLE from DIM_SPORT_LOCATION_SEATS t where t.location.LOCATION_NAME='Germany';
CITY SEATS_AVAILABLE
--------------------------------- ----------------
Munich t
Berlin fSQL 쿼리의 결과는 뮌헨의 경기장에 충분한 좌석 공간이 있음을 보여줍니다. 하지만 베를린의 이벤트 장소에는 75,000 명의 스포츠 이벤트를 주최하기에 충분한 좌석이 없습니다.
PL/pgSQL 함수로 PG 쿼리하기
다음 코드는 PL/pgSQL 함수 COMPARE_SEATING_CAPACITY를 사용하여 동일한 결과를 표시하는 PostgreSQL에서 재 작성된 쿼리입니다.
postgres=> select (location).LOCATION_CITY,COMPARE_SEATING_CAPACITY(location,75000) from DIM_SPORT_LOCATION_SEATS where (location).LOCATION_NAME='Germany';
location_city | compare_seating_capacity
---------------+--------------------------
Munich | t
Berlin | f
(2 rows)연산자 사용하기
PostgreSQL 연산자를 사용하여 이전 쿼리를 단순화 할 수도 있습니다. 모든 연산자는 기본 함수에 대한 호출입니다. PostgreSQL은 시스템 타입에 대한 많은 내장된 연산자를 제공합니다. 예를 들어, integer = operator에는 두 정수에 대해 int4eq (int, int)와 같은 기본 함수가 있습니다.
연산자 이름 또는 기본 함수를 사용하여 내장 연산자를 호출 할 수 있습니다. 다음 쿼리는 = 연산자와 내장 함수 int4eq를 사용하여 두 수준으로 만 스포츠 위치 ID를 가져옵니다:
postgres=> select sport_location_id,(location).location_levels from DIM_SPORT_LOCATION_SEATS where (location).location_levels = 2;
sport_location_id | location_levels
-------------------+-----------------
2 | 2
3 | 2
(2 rows)
postgres=> select sport_location_id,(location).location_levels from DIM_SPORT_LOCATION_SEATS where int4eq((location).location_levels,2);
sport_location_id | location_levels
-------------------+-----------------
2 | 2
3 | 2
(2 rows)연산자를 사용하여 75,000 명 이상의 좌석을 보유한 독일의 경기장을 찾는 SQL 쿼리를 단순화 할 수 있습니다. 다음 코드에 표시된대로 연산자> =는 UDT location_t를 왼쪽 인수로, integer를 오른쪽 인수로 사용하여 compare_seating_capacity 함수를 호출합니다.
COMMUTATOR 절이 제공된 경우 정의된 연산자의 교환자 인 연산자로 지정합니다. 연산자 X는 a와 b의 가능한 모든 입력 값에 대해 (a X b)가 (b Y a)와 같으면 연산자 Y의 교환자입니다. 이 경우 <=는 연산자 > =에 대한 교환자 역할을합니다. 인덱스 및 조인 절에 사용되는 연산자에 대한 교환자 정보를 제공하는 것이 중요합니다. 이렇게하면 쿼리 최적화 프로그램이 다른 계획 타입에 대해 이러한 절을 뒤집을 수 있기 때문입니다.
CREATE OPERATOR >= (
LEFTARG = location_t,
RIGHTARG = integer,
PROCEDURE = COMPARE_SEATING_CAPACITY,
COMMUTATOR = <=
);연산자가 있는 다음 PostgreSQL 쿼리는 UDT 멤버 함수가 있는 Oracle 쿼리와 동일한 결과를 보여줍니다:
postgres=> select (location).LOCATION_CITY CITY,(location).LOCATION_SEATING_CAPACITY >=75000 from DIM_SPORT_LOCATION_SEATS where (location).LOCATION_NAME='Germany';
city | ?column?
--------+----------
Munich | t
Berlin | f
(2 rows)다른 비교 연산자와 마찬가지로 UDT location_t와 함께 where 절에서 > = 연산자를 사용할 수도 있습니다. 앞서 정의한 사용자 정의 연산자 >=의 도움으로 SQL 쿼리는 location_t 데이터 유형을 왼쪽 인수로, 정수를 오른쪽 인수로 사용합니다. 다음 SQL 쿼리는 좌석 수용 인원이 75,000 명 이상인 독일의 도시를 반환합니다.
postgres=> select (location).LOCATION_CITY from DIM_SPORT_LOCATION_SEATS where (location).LOCATION_NAME='Germany' and location >=75000;
location_city
---------------
Munich
(1 row)마무리
이 글에서는 멤버 함수가 있는 UDT를 Oracle에서 PostgreSQL로 변환하고 마이그레이션하는 솔루션과 PostgreSQL에서 UDT를 사용하여 쿼리에서 연산자를 사용하는 방법을 살펴보았습니다. Oracle 워크로드를 PostgreSQL 또는 Aurora PostgreSQL 용 Amazon RDS로 이동하는 방법에 대한 자세한 내용은 Oracle Database 11g / 12c에서 PostgreSQL 호환성이있는 Amazon Aurora로 (9.6.x) 마이그레이션 플레이 북을 참조하세요.
– Manuj Malik, AWS Senior Data Lab Solutions Architect
– Devika Singh, AWS Solutions Architect
이 글은 AWS Database Blog의 Migrating user-defined types from Oracle to PostgreSQL 한국어 번역본으로 강민석 AWS 솔루션스 아키텍트가 번역 및 검토해 주셨습니다.
Source: Oracle의 사용자 정의 타입(user-defined types)을 PostgreSQL로 변환하기