


spark-submit를 사용하여 사용자 애플리케이션 제출
Francisco Oliveira는 AWS Professional Services의 컨설턴트입니다.
빅 데이터로의 전환을 시작하는 고객은 종종 사용자 애플리케이션을 Amazon EMR에서 실행되는 Spark에 제출하는 방법에 대한 지침을 요청합니다. 예를 들어, 고객은 애플리케이션에 사용할 수 있는 메모리 및 계산 리소스의 크기를 조정하는 방법이나 사용 사례에 가장 적합한 리소스 할당 모델에 대한 지침에 대해 문의합니다.
이 게시물에서는 EMR에서 실행 중인 Spark에 제출된 애플리케이션에서 사용할 수 있는 메모리 및 계산 리소스를 제어하기 위해 spark-submit 플래그를 설정하는 방법을 알아보도록 하겠습니다. 어떤 경우에 maximizeResourceAllocation 구성 옵션과 실행자의 동적 할당을 사용하는지 설명합니다.
Spark 실행 모델
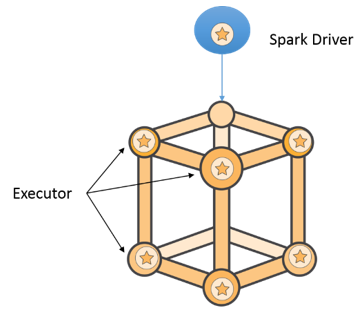
크게 봤을 때, 각 애플리케이션에는 클러스터의 여러 노드에서 실행되는 실행자 간에 태스크 형식의 작업을 배포하는 드라이버 프로그램이 있습니다.


드라이버는 데이터 세트에 적용되는 변환 및 작업을 정의하는 애플리케이션 코드입니다. 드라이버는 그 내부에서 SparkContext 클래스의 개체를 인스턴스화합니다. 이 개체를 사용하면 드라이버가 클러스터에 대한 연결을 얻고 리소스를 요청하며 애플리케이션이 해야할 일을 작업으로 분할하고 실행자에서 작업을 예약하고 시작할 수 있습니다.
실행자는 드라이버에서 보낸 태스크를 수행할 뿐만 아니라 로컬에 데이터를 저장합니다. 실행자가 생성되거나 삭제되면(아래 “실행자의 동적 할당 사용” 섹션 참조) 드라이버에 등록 및 등록 취소됩니다. 드라이버와 실행자는 직접 통신합니다.
애플리케이션을 실행하기 위해 드라이버는 작업 중에서 수행할 작업을 구성합니다. 각 작업은 단계로 분할되고 각 단계는 병렬로 실행되는 일련의 독립적인 태스크로 구성됩니다. 태스크는 Spark에서 가장 작은 작업 단위이며 각각 다른 파티션에서 동일한 코드를 실행합니다.
Spark 프로그래밍 모델
Spark의 중요한 추상화는 탄력적인 분산 데이터셋(RDD)입니다. 이 추상화는 인-메모리 계산을 수행하기 위한 핵심입니다. RDD는 클러스터의 노드에 분산된 읽기 전용 및 불변성 데이터 파티션의 집합입니다. Spark의 파티션을 통해 데이터의 하위 집합을 병렬로 실행할 수 있습니다. Spark 애플리케이션은 RDD를 생성하고 작업을 RDD에 적용합니다. Spark는 RDD 파티션을 자동으로 구성하지만 파티션 개수를 직접 설정할 수도 있습니다.
RDD는 변환과 작업이라는 두 가지 유형의 작업을 지원합니다. 변환은 새로운 RDD를 생성하는 작업이며, 작업은 데이터셋에서 변환을 실행한 후 외부 스토리지에 데이터를 쓰거나 드라이버에 값을 반환하는 작업입니다. 일반적으로 변환에는 키별로 필터링, 정렬 및 그룹화가 포함됩니다. 일반적인 작업에는 작업 결과를 수집하여 운전자에게 전송하거나, RDD의 저장 또는 RDD 요소 수를 계산하는 작업이 포함됩니다.
spark-submit
클러스터에서 애플리케이션을 실행하는 일반적인 방법은 spark-submit 스크립트를 사용하는 것입니다. 이 스크립트는 애플리케이션에서 사용하는 리소스를 제어할 수 있는 여러 플래그를 제공합니다.
spark-submit 플래그를 설정하는 것은 드라이버에서 인스턴스화된 SparkContext 개체에 구성을 동적으로 제공하는 방법 중 하나입니다. 클러스터를 생성할 때 EMR 구성 옵션을 사용하여 conf/spark-defaults.conf 파일에 저장하고 설정값을 spark-submit에서 읽는 것도 가능합니다. 권장하지는 않지만 애플리케이션에 하드코딩하는 방법도 있습니다. conf/spark-defaults.conf를 수정하는 것에 대한 대안으로 -conf prop=value 플래그를 사용할 수 있습니다. spark-submit 플래그와 spark-defaults.conf 파일 및 -conf. 플래그에 사용할 속성 이름을 모두 소개합니다.
EMR에서 실행되는 Spark 애플리케이션
EMR에서 실행 중인 Spark에 제출된 모든 애플리케이션은 YARN에서 실행되며 각 Spark 실행자는 YARN 컨테이너로 동작합니다. YARN에서 실행 중인 경우, 드라이버는 클러스터(클러스터 모드)에 있는 하나의 YARN 컨테이너에서 실행되거나 spark-submit 프로세스(클라이언트 모드) 내에서 로컬로 실행될 수 있습니다.
클러스터 모드에서 실행되는 경우 드라이버는 YARN 컨테이너 요청을 애플리케이션에 필요한 리소스에 해당하는 YARN ResourceManager로 제출하는 구성 요소인 ApplicationMaster에서 실행됩니다. 다음은 이러한 애플리케이션 제출 과정을 간략하게 도식화한 것입니다.


클라이언트 모드에서 실행되는 경우 드라이버는 ApplicationMaster가 아니라 애플리케이션을 제출하는 데 사용되는 시스템의 spark-submit 스크립트 프로세스 내에서 실행됩니다.


드라이버 위치 설정
spark-submit에서는 -deploy-mode 플래그를 사용하여 드라이버 위치를 지정할 수 있습니다.
디버깅할 때 애플리케이션의 출력을 빨리 확인하려면 클라이언트 모드로 애플리케이션을 제출하는 것이 좋습니다. 운영 환경에서 사용하는 애플리케이션의 경우에는 애플리케이션을 클러스터 모드로 실행하는 것이 좋습니다. 이 모드 플래그는 애플리케이션을 실행하는 동안 드라이버를 항상 사용할 수 있도록 보장합니다. 하지만 클라이언트 모드를 사용하는 경우 EMR 클러스터 외부에서(예: 로컬, 노트북에서) 애플리케이션을 제출할 경우 드라이버가 EMR 클러스터 외부에서 실행되고 있어서 드라이버-실행자 통신에 대한 지연 시간이 더 길어질 수 있음을 고려해야 합니다.
드라이버 리소스 설정
드라이버 크기는 드라이버가 수행하는 계산과 실행자로부터 수집하는 데이터의 양에 따라 달라집니다. 클러스터 모드에서 드라이버를 실행할 때 spark-submit은 드라이버 코어 수(–driver-cores)와 드라이버에서 사용하는 메모리(–driver-memory)를 제어하는 옵션을 제공합니다. 클라이언트 모드에서 드라이버 메모리의 기본값은 1024MB이고 코어 하나입니다.
코어 수 및 실행자 수 설정
선택한 실행자 코어 수 (–executor-cores 또는 spark.executor.cores)는 각 실행자가 병렬로 실행할 수 있는 작업 수를 정의합니다. 가장 좋은 방법은 OS용 코어를 한 개 남겨두고, 실행자당 약 4-5개의 코어를 지정하는 것입니다. 요청된 코어 수는 구성 속성 yarn.nodmanager.resource.cpu-vcores에 의해 제한됩니다. 이 구성 속성은 한 노드에서 실행되는 모든 YARN 컨테이너에서 사용할 수 있는 코어 수를 제어하며 yarn-site.xml 파일에 설정됩니다.
노드당 실행자 수는 다음 공식을 사용하여 계산할 수 있습니다.
노드당 실행자 수 = 노드의 코어 수 – 1(OS용)/실행자당 작업 수
Spark 작업에 대한 실행자 (-num-executors 또는 spark.instance)의 총 수는 다음과 같습니다.
총 실행자 수 = 노드당 실행자 수 * 인스턴스 수 -1
각 실행자의 메모리 설정
각 실행자 컨테이너의 메모리 공간은 크게 Spark 실행자 메모리와 메모리 오버헤드의 두 가지 영역으로 구분됩니다.


실행자 컨테이너에 할당할 수 있는 최대 메모리는 yarn-site.xml 파일의 yarn.nodmanager.resource.memory-mb 속성에 의해 결정됩니다. 실행자 메모리(–executor-memory 또는 spark.executor.memory)는 각 실행자 프로세스가 사용할 수 있는 메모리 양을 정의합니다. 메모리 오버헤드(spark.yarn.executor.memoryOverHead)는 오프히트 메모리이며 실행자 메모리에 자동으로 추가됩니다. 기본값은 executorMemory * 0.10입니다.
실행자 메모리는 저장 및 실행을 위해 힙 영역을 통합합니다. 이 두 영역은 사용량이 초과되면 서로 공간을 빌릴 수 있습니다. 관련 속성은 spark.memory.fraction 및 spark.memory.storageFraction입니다. 자세한 내용은 Spark 1.6의 통합 메모리 관리 백서를 참조하십시오.
각 실행자의 메모리는 다음 공식을 사용하여 계산할 수 있습니다.
각 실행자의 메모리 = 노드의 최대 컨테이너 크기/노드당 실행자 수
간단한 예
지금까지 설명한 플래그를 설정하는 방법을 알아보기 위해 다음과 같이 워드카운트 예제 애플리케이션을 제출하고 그 실행 결과를 그래픽 형태로 볼 수 있도록 Spark 기록 서버를 사용해보겠습니다.
먼저 작성한 word count 샘플 애플리케이션을 기존 클러스터에 EMR 단계로 제출합니다. 해당 코드는 다음과 같습니다.
from __future__ import print_function
from pyspark import SparkContext
import sys
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: wordcount ", file=sys.stderr)
exit(-1)
sc = SparkContext(appName="WordCount")
text_file = sc.textFile(sys.argv[1])
counts = text_file.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile(sys.argv[2])
sc.stop()
클러스터에는 6개의 m3.2xlarge 인스턴스와 마스터 인스턴스 하나가 있습니다. 각 인스턴스는 vCPU 8개와 30GB 메모리로 구성됩니다. 이 인스턴스 유형에 대한 yarn.nodemanager.resource.memory-mb의 기본값은 23GB입니다.
앞서 살펴본 공식에 따라 다음과 같이 spark-submit 명령을 실행합니다.
spark-submit --deploy-mode cluster --master yarn --num-executors 5 --executor-cores 5 --executor-memory 20g –conf spark.yarn.submit.waitAppCompletion=false wordcount.py s3://inputbucket/input.txt s3://outputbucket/
다음 명령을 사용하여 애플리케이션을 EMR 단계로 제출합니다.
aws emr add-steps --cluster-id j-xxxxx --steps Type=spark,Name=SparkWordCountApp,Args=[--deploy-mode,cluster,--master,yarn,--conf,spark.yarn.submit.waitAppCompletion=false,--num-executors,5,--executor-cores,5,--executor-memory,20g,s3://codelocation/wordcount.py,s3://inputbucket/input.txt,s3://outputbucket/],ActionOnFailure=CONTINUE
위에서 단계 정의를 사용하여 spark.yarn.submit.waitAppCompletion 속성도 설정한 것을 확인할 수 있습니다. 이 속성을 false로 설정하면 클라이언트는 애플리케이션을 제출하고 애플리케이션이 완료될 때까지 기다리지 않고 종료합니다. 이 설정을 사용하면 클러스터에서 동시에 실행할 여러 애플리케이션을 제출할 수 있는데 클러스터 모드에서만 사용할 수 있습니다.
샘플 애플리케이션이 Amazon S3에 직접 기록하고 드라이버가 실행자로부터 데이터를 수신하지는 않기 때문에 –driver-memory 및 –driver-cores에 대한 기본값을 사용합니다.
실행자의 동적 할당 활성화
YARN의 Spark는 실행자 수를 동적으로 스케일업 및 스케일다운할 수 있습니다. 이 기능은 유휴 실행기는 해제하고 애플리케이션이 요청 시 추가 실행자를 요청할 수 있으므로 여러 애플리케이션이 동시에 처리되는 경우에 유용합니다.
이 기능을 사용하려면 EMR 설명서의 단계를 참조하시기 바랍니다.
Spark는 다음과 같은 특성을 통해 동적 할당 메커니즘에 대한 세부적인 제어를 제공합니다.
- 초기 실행자 수(spark.dynamicAllocation.initalExecutors)
- 애플리케이션에서 사용할 최소 실행자 수(spark.dynamicAllocation.minExecutors)
- 요청할 수 있는 최대 실행자(spark.dynamicAllocation.maxExecutors)
- 유휴 실행자를 제거할 시점(sparkdynamicAllocation.executorIdleTime)
- 대기 중인 작업을 처리하기 위해 실행자를 요청하는 시점(spark.dynamicAllocation.schedulerBacklogTimeout and spark.dynamicAllocation.sustainedSchedulerBacklogTimeout)
최대 리소스 할당으로 실행자 자동 구성하기
EMR은 전체 클러스터의 리소스 사용을 최대화하기 위해 위의 속성을 자동으로 구성하는 옵션을 제공합니다. 이 구성 옵션은 클러스터에서 한 번에 하나의 애플리케이션만 처리하는 경우에 유용합니다. 여러 애플리케이션을 동시에 실행해야 하는 경우에는 이 애플리케이션의 사용을 피해야 합니다.
이 구성 옵션을 사용하려면 EMR 문서의 단계를 참조하시기 바랍니다.
EMR은 클러스터 생성 중에 이 구성 옵션을 설정하여 spark-defaults.conf 파일을 다음과 같이 실행자의 계산 및 메모리 리소스의 제어 속성을 자동으로 업데이트합니다.
- spark.executor.memory = (yarn.scheduler.maximum-allocation-mb – 1g) -spark.yarn.executor.memoryOverhead
- spark.executor.instance = [이 값은 초기 코어 노드 수와 클러스터의 작업 노드 수로 설정됩니다.]
- spark.executor.cores = yarn.nodemanager.resource.cpu-vcores
- spark.default.parallelism = spark.executor.instances * spark.executor.cores
병렬 처리의 그래픽 뷰
EMR 콘솔에서 Spark 기록 서버 UI에 액세스할 수 있습니다. 애플리케이션의 성능과 동작에 대한 유용한 정보를 제공합니다. 예약된 단계 및 태스크 목록을 확인하고, 실행자에 대한 정보를 검색하고, 메모리 사용량 요약을 가져오며, SparkContext 개체에 제출된 구성을 검색할 수 있습니다. 이 게시물의 목적을 위해 앞서 예에서 사용된 spark-submit 스크립트에 설정된 플래그가 그래픽 도구에 어떻게 적용되는지 알아보도록 하겠습니다.
Spark 기록 서버에 액세스하려면 SOCKS 프록시를 활성화하고 Connections에서 Spark History Server를 선택합니다.


완료된 애플리케이션의 경우 사용 가능한 유일한 항목을 선택하고 아래와 같이 이벤트 시간 표시줄을 확장합니다. Spark는 -num-executers 플래그의 정의에서 요청한 대로 5개의 실행자를 추가했습니다.


다음으로, 단계 세부 정보로 이동하면 실행자당 병렬로 실행되는 태스크 수를 볼 수 있습니다. 이 값은 –executor-cores 플래그의 값과 동일합니다.


요약
이 게시물에서는 spark-submit 플래그를 사용하여 애플리케이션을 클러스터에 제출하는 방법을 배웠습니다. 특히 드라이버 실행 위치를 제어하고 드라이버와 실행자에 할당된 리소스 및 실행자 수를 설정하는 방법을 배웠습니다. 또한 어떤 경우에 maximizeResourceAllocation 구성 옵션과 실행자의 동적 할당을 사용해야 하는지도 배웠습니다.
질문이나 제안이 있으면 의견을 남겨주시기 바랍니다.
—————————-
관련 정보:
Amazon EMR에서 S3 기반 노트북과 Spark를 사용하여 외부 Zeppelin 인스턴스 실행


빅 데이터 또는 스트리밍 데이터에 대해 자세히 알고 싶습니까? 빅 데이터 및 스트리밍 데이터 교육 페이지를 참조하십시오.
Source: spark-submit를 사용하여 사용자 애플리케이션 제출