고성능 모델 훈련용 Amazon EC2 Trn1 인스턴스 정식 출시
딥 러닝(DL) 모델은 지난 몇 년 동안 규모와 복잡성이 증가하면서 훈련 시간이 며칠에서 몇 주로 늘어났습니다. GPT-3 규모의 대형 언어 모델을 훈련하는 데 몇 개월이 걸리므로 훈련 비용이 기하급수적으로 증가할 수 있습니다. 모델 훈련 시간을 단축하고 기계 학습(ML) 실무자가 빠르게 반복할 수 있도록 AWS는 칩, 서버 및 데이터 센터 연결 전반을 혁신해왔습니다.
AWS re:Invent 2021에서 AWS Trainium 칩으로 구동되는 Amazon EC2 Trn1 인스턴스의 미리 보기를 발표한 바 있습니다. AWS Trainium은 고성능 딥 러닝 훈련에 최적화되어 있으며, AWS Inferentia에 이어 AWS에서 개발한 2세대 ML 칩입니다.
오늘 Amazon EC2 Trn1 인스턴스를 정식 출시한다는 소식을 발표하게 되어 기쁩니다! 이러한 인스턴스는 자연어 처리, 이미지 인식 등과 같은 광범위한 애플리케이션에서 복잡한 DL 모델을 대규모로 분산하여 훈련하는 데 매우 적합합니다.
Amazon EC2 P4d 인스턴스와 비교하면, Trn1 인스턴스는 BF16 데이터 형식의 경우 1.4배의 teraFLOP, TF32 데이터 형식의 경우 2.5배의 teraFLOP, FP32 데이터 형식의 경우 5배의 teraFLOP을 제공하고 노드 간 네트워크 대역폭이 4배로 증가했으며 최대 50%의 훈련 비용 절감 효과가 있습니다. Trn1 인스턴스는 복잡한 딥 러닝 모델을 빠르게 훈련하기 위한 강력한 슈퍼컴퓨터 역할을 하는 EC2 UltraCluster에 배포할 수 있습니다. EC2 UltraCluster에 대한 자세한 내용은 이 블로그 게시물 후반부에서 공유하겠습니다.
새로운 Trn1 인스턴스 주요 특징
Trn1 인스턴스는 현재 두 가지 크기로 제공되며 최대 16개의 AWS Trainium 칩 및 128개의 vCPU로 구동됩니다. 이들은 분산 훈련에 널리 사용되는 전략인 효율적인 데이터 및 모델 병렬 처리를 지원하는 고성능 네트워킹 및 스토리지를 제공합니다.
Trn1 인스턴스는 최대 512GB의 고대역폭 메모리, 최대 3.4petaFLOP의 TF32/FP16/BF16 컴퓨팅 파워, 칩 간 초고속 NeuronLink 상호 연결을 제공합니다. NeuronLink는 여러 Trainium 칩 간에 워크로드를 확장할 때 통신 병목 현상을 방지하는 데 도움이 됩니다.
또한 Trn1 인스턴스는 처리량이 많은 네트워크 통신을 위해 최대 800Gbps의 Elastic Fabric Adapter(EFA) 네트워크 대역폭을 지원하는 최초의 EC2 인스턴스입니다. 이 2세대 EFA는 이전 세대보다 짧은 지연 시간과 최대 2배의 네트워크 대역폭을 제공합니다. 또한 Trn1 인스턴스는 대용량 데이터 세트에 초고속으로 액세스할 수 있도록 최대 8TB의 로컬 NVMe SSD 스토리지와 함께 제공됩니다.
다음 표에는 Trn1 인스턴스의 크기 및 사양이 자세히 나와 있습니다.
| 인스턴스 이름 |
vCPU | AWS Trainium 칩 | 액셀러레이터 메모리 | NeuronLink | 인스턴스 메모리 | 인스턴스 네트워킹 | 로컬 인스턴스 스토리지 |
| trn1.2xlarge | 8 | 1 | 32GB | N/A | 32GB | 최대 12.5Gbps | 1x 500GB NVMe |
| trn1.32xlarge | 128 | 16 | 512GB | 지원됨 | 512GB | 800Gbps | 4x 2TB NVMe |
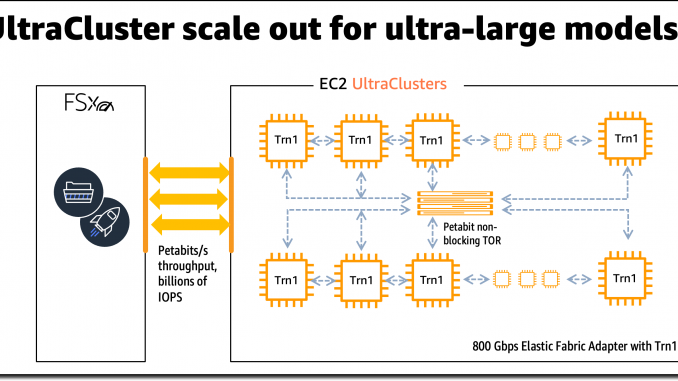
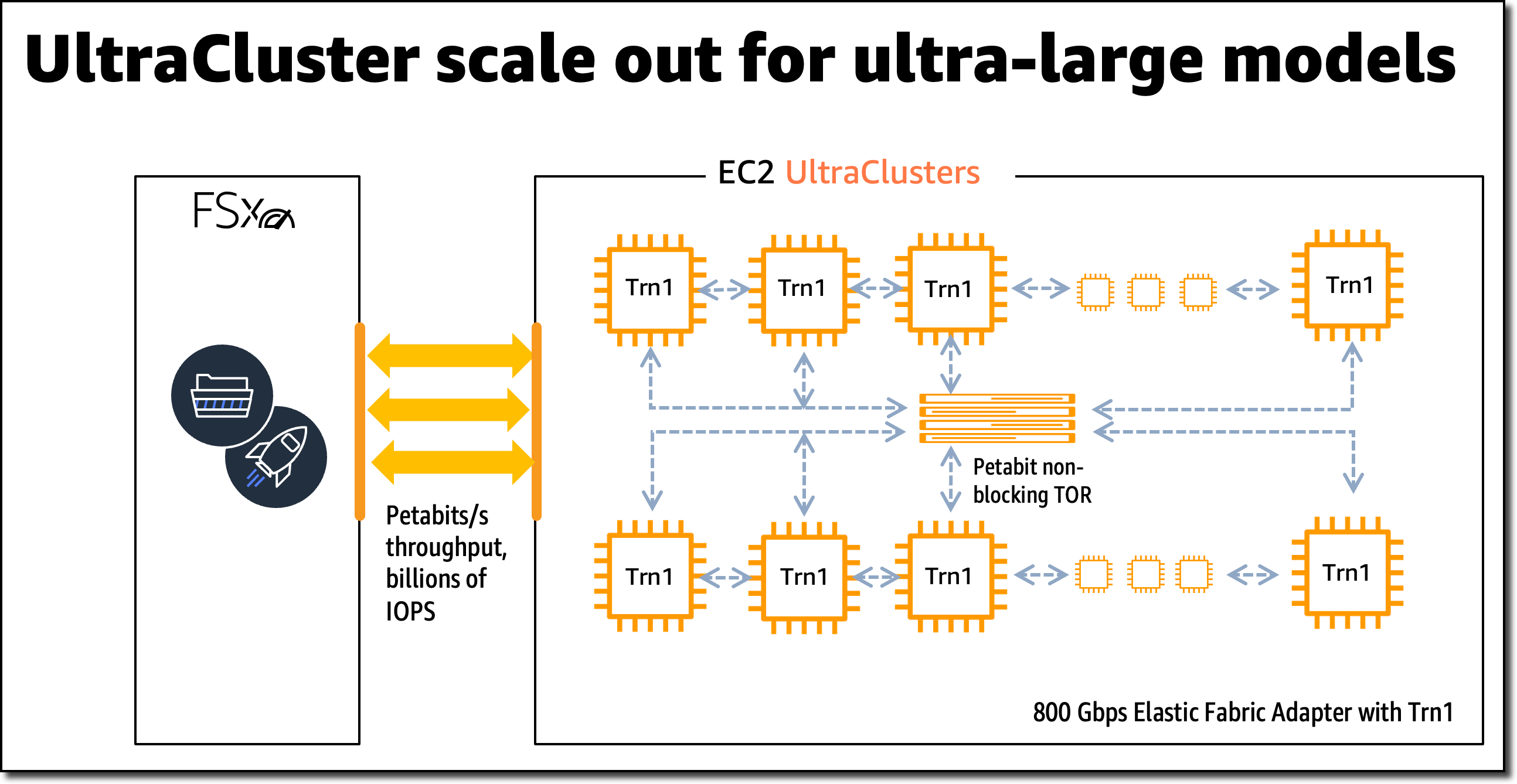
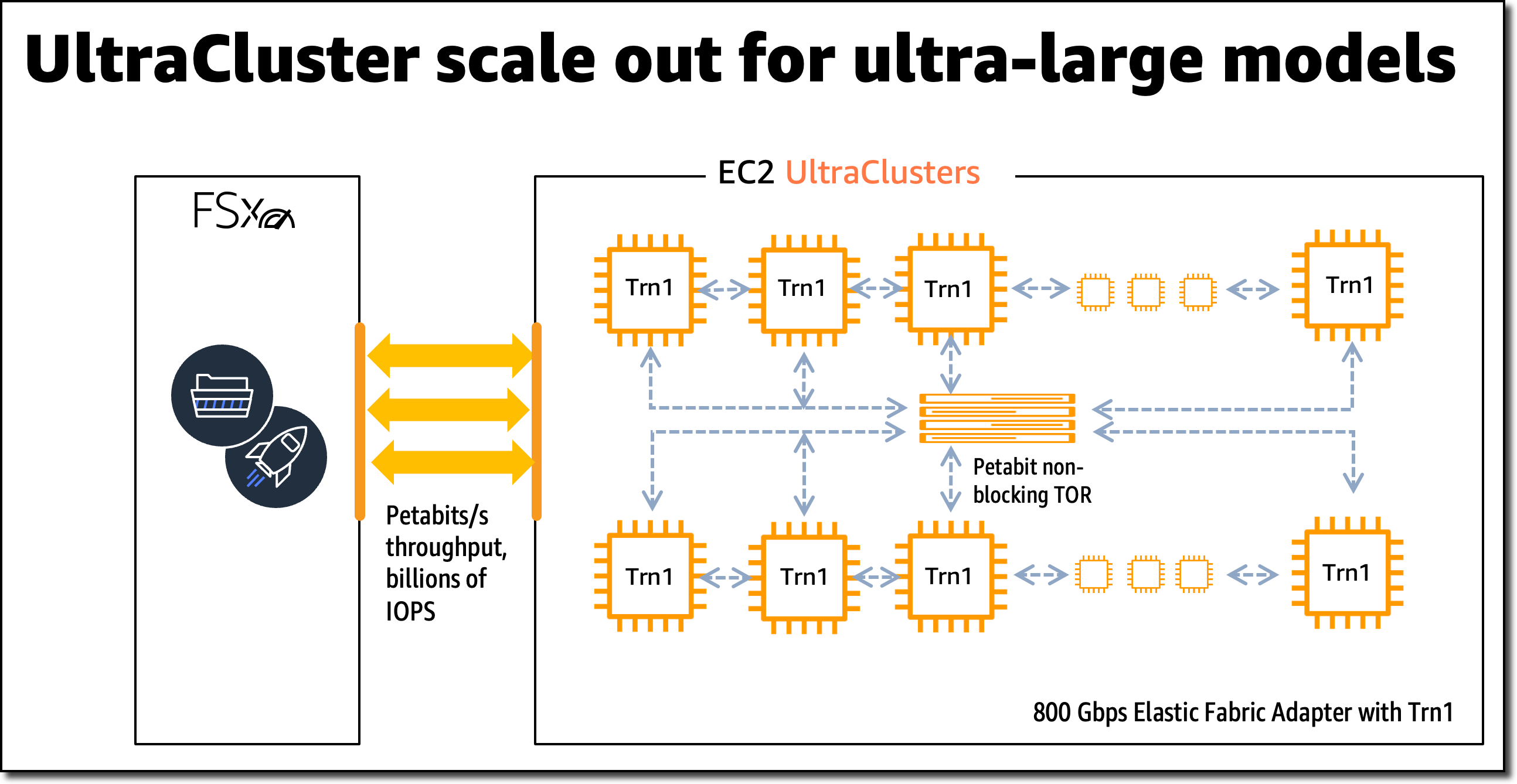
Trn1 EC2 UltraCluster
대규모 모델 훈련의 경우 Trn1 인스턴스는 Amazon FSx for Lustre 고성능 스토리지와 통합되고 EC2 UltraCluster에 배포됩니다. EC2 UltraCluster는 비차단 페타비트 규모 네트워크와 상호 연결된 하이퍼스케일 클러스터입니다. 이를 통해 슈퍼컴퓨터에 온디맨드로 액세스하여 크고 복잡한 모델의 모델 훈련 시간을 몇 개월에서 몇 주 또는 며칠로 단축할 수 있습니다.
AWS Trainium 혁신
AWS Trainium 칩에는 딥 러닝 알고리즘용으로 특별히 구축된 특정 스칼라, 벡터 및 텐서 엔진이 포함되어 있습니다. 그러므로 다른 아키텍처에 비해 칩 사용률이 높아져 성능이 향상됩니다.
다음은 추가적인 하드웨어 혁신에 대한 간략한 요약입니다.
- 데이터 형식: AWS Trainium은 FP32, TF32, BF16, FP16, UINT8 등 다양한 데이터 형식을 지원하므로 워크로드에 가장 적합한 데이터 형식을 선택할 수 있습니다. 또한 새로운 구성 가능한 FP8(cFP8) 데이터 형식을 지원하는데, 이 형식은 모델의 메모리 공간과 I/O 요구 사항을 줄여 주므로 대형 모델에 특히 적합합니다.
- 하드웨어 최적화 확률적 반올림: 확률적 반올림은 FP32 데이터 형식에서 BF16 데이터 형식으로 자동 캐스팅을 활성화하면 FP32 수준에 가까운 정확도와 더 빠른 BF16 수준의 성능을 제공합니다. 확률적 반올림은 부동 소수점 숫자를 반올림하는 다른 방식으로, 일반적으로 사용되는 오사오입 반올림에 비해 머신 러닝 워크로드에 더 적합합니다. 확률적 반올림을 사용하도록 환경 변수
NEURON_RT_STOCHASTIC_ROUNDING_EN=1을 설정하면 모델을 최대 30% 더 빠르게 훈련할 수 있습니다. - 사용자 지정 연산자, 동적 텐서 셰이프: AWS Trainium은 C++ 및 동적 텐서 셰이프로 작성된 사용자 지정 연산자도 지원합니다. 동적 텐서 셰이프는 텍스트를 처리하는 모델과 같이 입력 텐서 크기를 알 수 없는 모델의 핵심입니다.
AWS Trainium은 AWS Inferentia와 동일한 AWS Neuron SDK를 공유하므로 이미 AWS Inferentia를 사용하고 있는 사용자는 누구나 쉽게 AWS Trainium을 시작할 수 있습니다.
모델 훈련을 위해 Neuron SDK는 컴파일러, 프레임워크 확장 프로그램, 런타임 라이브러리 및 개발자 도구로 구성됩니다. Neuron 플러그인은 기본적으로 PyTorch 및 TensorFlow 같은 널리 사용되는 ML 프레임워크와 통합됩니다.
AWS Neuron SDK는 모델 컴파일 속도를 높이기 위해 사전(AOT) 컴파일 외에도 JIT(Just-in-time) 컴파일과 단계별 실행을 위한 즉시 디버그 모드를 지원합니다.
AWS Trainium에서 모델을 컴파일하고 실행하려면 훈련 스크립트에서 몇 줄의 코드만 변경하면 됩니다. 모델을 수정하거나 데이터 형식 변환을 고려할 필요가 없습니다.
Trn1 인스턴스 시작하기
이 예제에서는 사용 가능한 PyTorch Neuron 패키지를 사용하여 EC2 Trn1 인스턴스에서 PyTorch 모델을 훈련합니다. PyTorch Neuron은 PyTorch XLA 소프트웨어 패키지를 기반으로 하며 PyTorch 작업을 AWS Trainium 명령으로 변환할 수 있습니다.
각 AWS Trainium 칩에는 주 신경망 컴퓨팅 유닛인 NeuronCore 액셀러레이터가 2개 포함되어 있습니다. 훈련 코드를 몇 가지 변경하기만 하면 AWS Trainium NeuronCore에서 PyTorch 모델을 훈련할 수 있습니다.
SSH를 Trn1 인스턴스에 연결하고 PyTorch Neuron 패키지가 포함된 Python 가상 환경을 활성화합니다. Neuron 제공 AMI를 사용하는 경우 다음 명령을 실행하여 사전 설치된 환경을 활성화할 수 있습니다.
source aws_neuron_venv_pytorch_p36/bin/activate훈련 스크립트를 실행하려면 먼저 몇 가지 수정이 필요합니다. Trn1 인스턴스에서 기본 XLA 디바이스를 NeuronCore에 매핑해야 합니다.
먼저 PyTorch XLA 가져오기를 훈련 스크립트에 추가하겠습니다.
import torch, torch_xla
import torch_xla.core.xla_model as xm그런 다음 모델 및 텐서를 XLA 디바이스에 배치합니다.
model.to(xm.xla_device())
tensor.to(xm.xla_device())모델이 XLA 디바이스(NeuronCore)로 이동하면 모델에 대한 후속 작업이 나중에 실행할 수 있도록 기록됩니다. 이는 XLA의 지연 실행으로, PyTorch의 즉시 실행과는 다릅니다. 훈련 루프 내에서 최적화할 그래프를 표시하고 XLA 디바이스에서 xm.mark_step()을 사용하여 실행해야 합니다. 이 표시가 없으면 XLA는 그래프가 끝나는 위치를 알 수 없습니다.
...
for data, target in train_loader:
output = model(data)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
xm.mark_step()
...이제 torchrun <my_training_script>.py를 사용하여 훈련 스크립트를 실행할 수 있습니다.
훈련 스크립트를 실행할 때 torchrun –nproc_per_node를 사용하여 훈련에 사용할 NeuronCore 수를 구성할 수 있습니다.
예를 들어 하나의 trn1.32xlarge 인스턴스에서 32개의 NeuronCore 모두에 대해 멀티 워커 데이터 병렬 모델 훈련을 실행하려면torchrun --nproc_per_node=32 <my_training_script>.py를 실행합니다.
데이터 병렬은 각 워커가 훈련 데이터 세트의 일부를 처리하도록 스크립트를 여러 워커에 복제할 수 있는 분산 훈련 전략입니다. 그러면 각 워커가 결과를 서로 공유합니다.
지원되는 ML 프레임워크, 모델 유형 및 trn1.32xlarge 인스턴스 간에 대규모 분산 훈련을 실행하기 위한 모델 훈련 스크립트를 준비하는 방법에 대한 자세한 내용은 AWS Neuron SDK 설명서를 참조하세요.
프로파일링 도구
ML 실험을 추적하고 Trn1 인스턴스 리소스 소비량을 프로파일링하는 데 유용한 도구를 간단히 살펴보겠습니다. Neuron은 TensorBoard와 통합되어 모델 훈련 지표를 추적하고 시각화합니다.
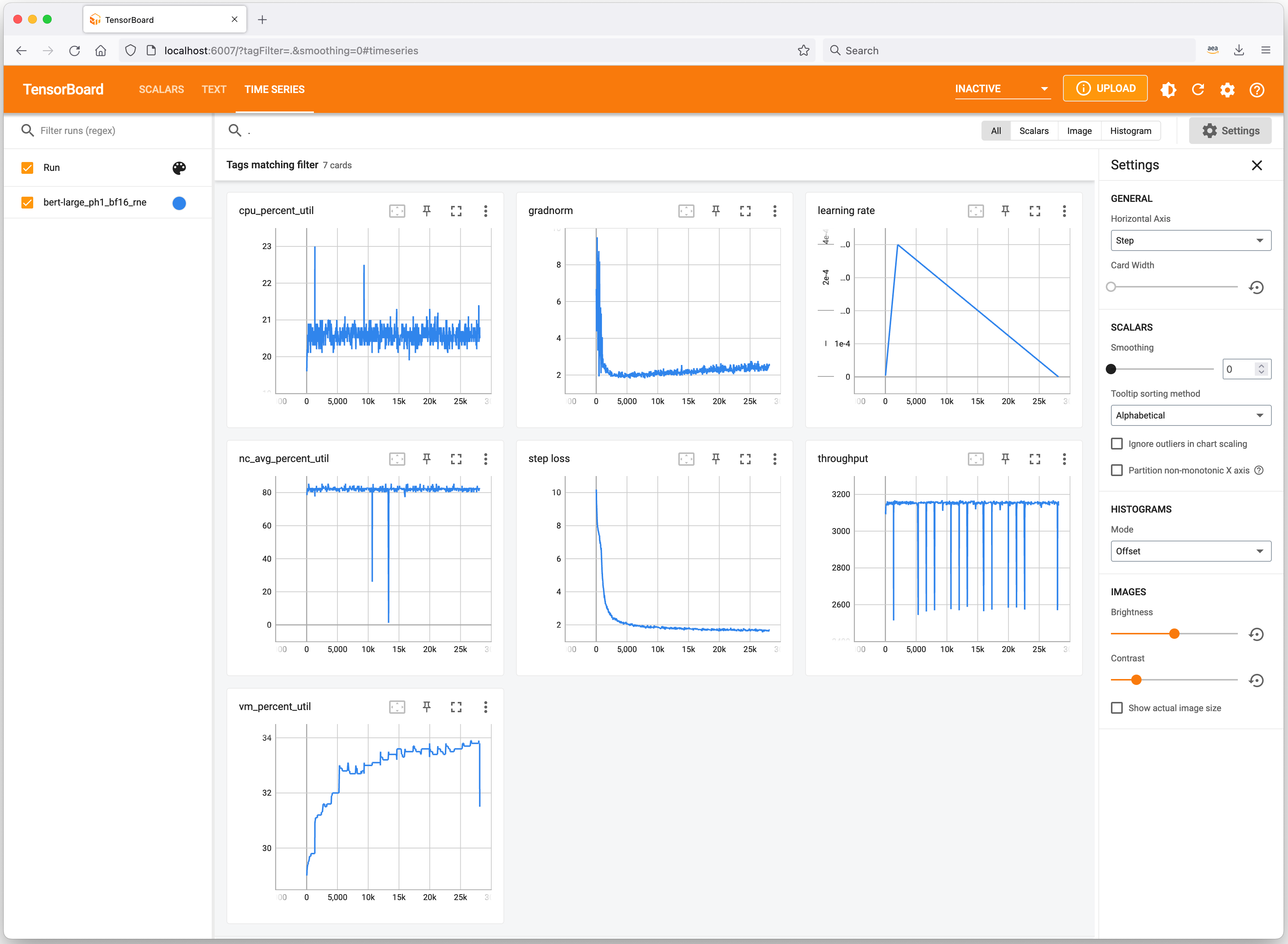
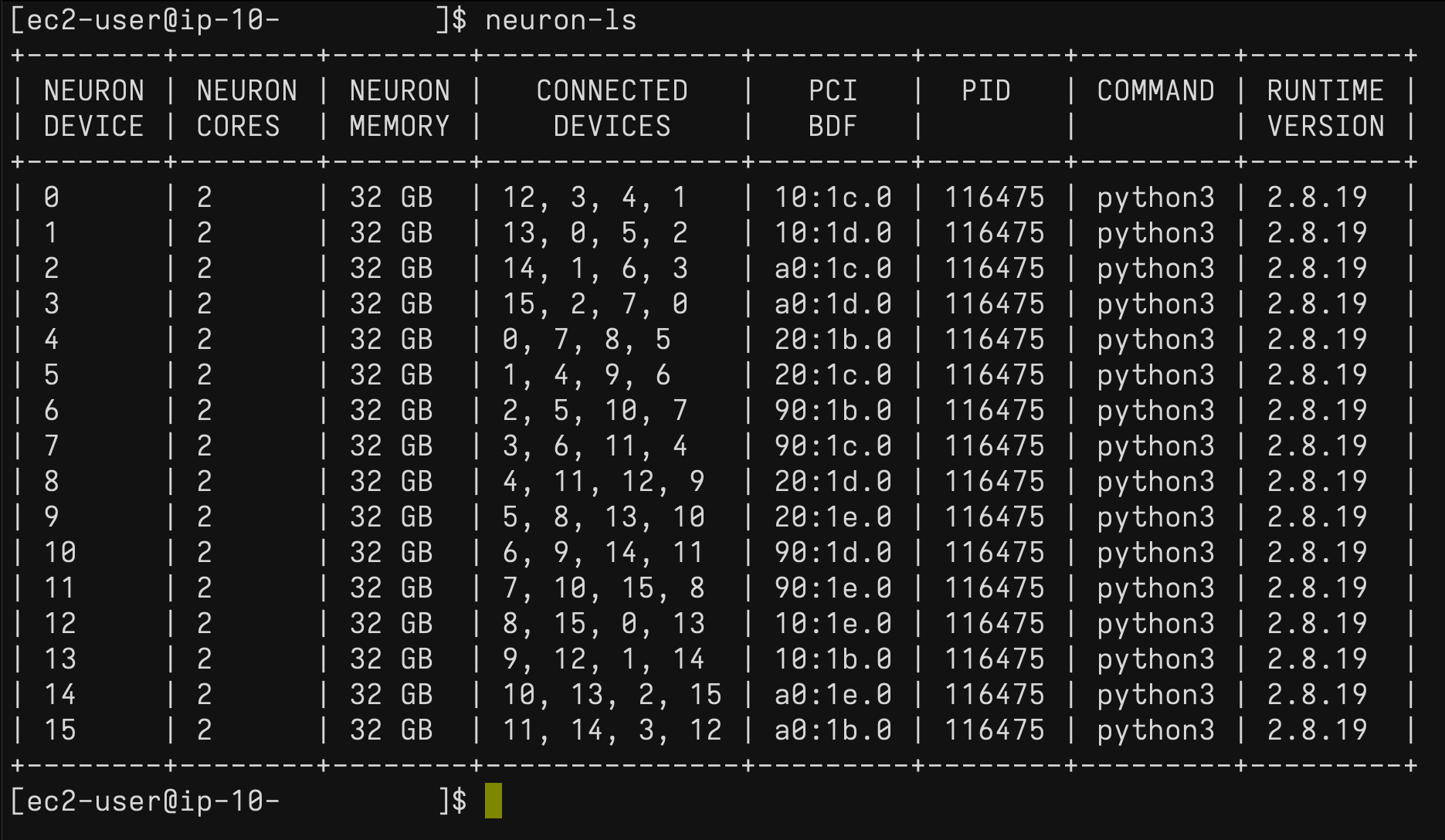
Trn1 인스턴스에서 neuron-ls 명령을 사용하여 시스템에 있는 Neuron 디바이스 수를 연결된 NeuronCore 수, 메모리, 연결/토폴로지, PCI 디바이스 정보 및 현재 NeuronCore의 소유권이 있는 Python 프로세스와 함께 설명할 수 있습니다.
마찬가지로 neuron-top 명령을 사용하여 Neuron 환경을 상위 수준에서 볼 수 있습니다. 여기에는 각 NeuronCore의 사용률, 현재 하나 이상의 NeuronCore에 로드되어 있는 모든 모델, Neuron 런타임을 사용하는 모든 프로세스의 프로세스 ID, vCPU 및 메모리 사용과 관련된 기본 시스템 통계가 표시됩니다.

정식 출시
지금 AWS 미국 동부(버지니아 북부) 및 미국 서부(오레곤) 리전에서 온디맨드, 예약 및 스팟 인스턴스 또는 Savings Plan의 일부로 Trn1 인스턴스를 시작할 수 있습니다. Amazon EC2와 마찬가지로 사용한 만큼만 비용을 지불하면 됩니다. 자세한 내용은 Amazon EC2 요금을 참조하세요.
Trn1 인스턴스는 AWS Deep Learning AMI를 사용하여 배포할 수 있으며, 컨테이너 이미지는 Amazon SageMaker, Amazon Elastic Kubernetes Service(Amazon EKS), Amazon Elastic Container Service(Amazon ECS), AWS ParallelCluster 등의 관리형 서비스를 통해 사용할 수 있습니다.
자세한 내용을 알아보려면 Amazon EC2 Trn1 인스턴스 페이지를 참조하시고, 피드백을 보내시려면 AWS re:Post for EC2를 이용하시거나 평소 교류하는 AWS Support 담당자를 통해 전달해 주세요.
— Antje


Leave a Reply