출처 : http://meetup.toast.com/posts/53
본 내용은 NHN엔터테인먼트의 정성환 님께서 작성하신 내용입니다.
연재
리눅스 서버의 TCP 네트워크 성능을 결정짓는 커널 파라미터 이야기 – 2편
리눅스 서버의 TCP 네트워크 성능을 결정짓는 커널 파라미터 이야기 – 3편
목차
- 들어가기 전에
- 준비
- TCP 대역폭(bandwidth) 관련 파라미터
3.1 BDP
3.2 TCP window scaling
3.3 TCP socket buffer size
3.4 congestion window size - 네트워크 capacity 관련 파라미터
4.1 maximum file count
4.2 backlogs
4.3 port range - TIME_WAIT socket
5.1 TIME_WAIT 상태의 소켓이 무엇일까요?
5.2 TIME_WAIT socket buckets
5.3 TIME_WAIT socket reuse (TW_REUSE)
5.4 TCP timestamp
5.5 TIME_WAIT socket recycling (TW_RECYCLE)
5.6 Socket linger option - 결론
- 맺으며
1. 들어가기 전에
안녕하세요. NHN엔터테인먼트 정성환 입니다.
언젠가 꼭 한번 정리하겠다고 마음 먹었는데, 이제서야 정리하게 되었습니다.
먼저, ”TCP 네트워크 성능을 결정짓는…” 이라는 수식어는 사실 조금 더 자극적인 제목을 뽑아내기 위한 과욕입니다.
네트워크 성능에 가장 중요한 요소는 결국엔 애플리케이션에 있다는 점을 강조하고 싶습니다.
다만, 워크로드 특성에 따라 기본 설정된 TCP 커널 파라미터가 제약이 되어 제성능을 발휘할 수 없을때도 있는데요.
본문에서는 이러한 내용들을 다루고 있습니다.
매우 많은 커널 파라미터가 있겠지만, 본문에서는 네트워크 대역폭(bandwidth)에 대한 커널 파라미터, 네트워크 수용량(capacity)에 대한 커널 파라미터를 주로 다룹니다.
2. 준비
리눅스는 sysctl 명령어로 손쉽게 커널 파라미터를 런타임 중에 변경할 수 있습니다.
다음과 같은 명령어를 사용하면 현재 커널 파라미터 설정값 전체를 열람할 수 있습니다.
$ sysctl -a
본 문서에서는 네트워크, 특히 TCP의 capacity와 bandwidth 등을 조정(tuning)할 수 있는 커널 파라미터 중 아주 일부 만을 다룹니다.
대개, TCP와 관련된 커널 파라미터는 net.core, net.ipv4, net.ipv6 등의 접두사를 붙이고 있습니다.
또, 다음과 같은 명령어로 현재 설정값을 변경할 수 있습니다.
예를 들어 net.core.wmem_max 라는 설정값을 16777216이라고 변경하려면, 다음과 같이 입력하면 됩니다.
$ sysctl -w net.core.wmem_max="16777216"
시스템 부팅시 설정되도록 하려면, /etc/sysctl.conf 파일에 해당 설정값을 기입하면 됩니다.
3. TCP 대역폭(bandwidth) 관련 파라미터
3.1 BDP
TCP의 대역폭을 이해하려면 먼저 BDP(Bandwidth Delay Product)를 이해할 필요가 있습니다.
먼저, 100Mbps의 대역폭을 가지는 네트워크에서 어떤 두 host A, B 사이 RTT(Round-trip time)가 2초인 네트워크 경로가 있다고 가정합시다.
A에서 B까지 데이터가 계속 전송되고 있을때, A에서 출발하였으나 아직 B에 도착하지 않은 데이터 양(bits in flight)은 얼마일까요?
아래 그림을 보면 조금 이해가 쉬울 것 같습니다.
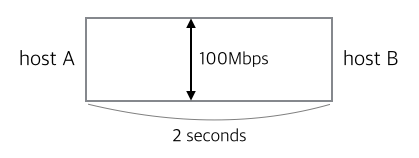
대역폭을 너비로, 지연시간 RTT를 길이로 생각하면, 이 둘의 곱이 네트워크 경로상 떠다니는 데이터 양의 최대치를 나타낼 것입니다.
즉, 대역폭과 지연시간의 곱, 다시 말해 BDP는 어느 네트워크 경로에 전달중인 데이터(패킷)의 양을 나타냅니다.
이 예제에서 BDP는 100Mb/s * 2s = 200Mb / 8 = 25MB 정도입니다.
다른 예를 들어보자면, 어느 서버와 LTE 네트워크(40Mbps, 40ms RTT)로 연결된 단말이 있다고 가정합시다.
이때 BDP는 (40(10^6))bit/s (40(10^-3))s =1600(10^3)bit = 1.6Mb / 8 = 0.2MB 정도일 것 입니다.
BDP의 수식을 이용하면, 다음과 같은 식을 도출할 수 있을 것입니다.
Bandwidth = BDP / RTT
그런데 말입니다. 실제 인터넷에서 BDP는 매우 충분히 큽니다.
용량이 큰 백본망을 비록한 물리적인 네트워크 환경이 예전과 다르게 비약적으로 좋기 때문이죠.
BDP가 어느 정도로 크냐면 receiver의 receiver window size를 온당히 감당할만큼 크다고 할 수 있습니다.
즉, 인터넷의 경우 Bandwidth = (receiver window size) / RTT 관계도 성립한다는 이야기이죠.
다시 정리하자면, 인터넷의 경우 대역폭을 높이기 위해서는 RTT를 낮추거나 receiver window size를 키우면 됩니다.
그런데 RTT는 peer간 물리적인 거리에 종속적이어서 낮추기 힘듭니다.
즉, 대역폭을 높이려면 receiver window size를 증가시켜야 합니다.
그렇다면, receiver window size를 증가하려면 어떻게 해야 할까요?
3.2 TCP window scaling
기본적으로 TCP 연결을 맺을 때, SYN 패킷에는 receiver window size를 공고(advertising) 하도록 되어 있습니다.
이 값의 범위는 0~65,535까지인데요. 즉, 64KB까지 지정할 수 있습니다.
인터넷이 처음 나올적의 예전이라면 모르겠지만, 지금 세상에서 64KB는 꽤나 작은 데이터양이겠지요.
RFC 1323에서는 TCP window scaling이라는 옵션을 정의하고 있습니다.
TCP 헤더의 옵션 필드에 window scale라는 필드를 정의하여 advertise할 수 있는 receiver window size를 키울 수 있도록 합니다.
이 값은 0~14까지 지정할 수 있습니다. 그리고 이 값을 n이라 한다면, 2^n 값을 window scaling factor라고 합니다.
TCP window scaling을 설정하면, 실제 receiver window size는 기존의 window size 값과 이 window scaling factor의 곱으로 구할 수 있습니다.
예를 들어, window size 값이 8,192이고 window scale 값이 8이라면 실제 receiver window size는 8,192 * (2^8) = 2,097,152 바이트가 됩니다.
참고로, TCP window scaling을 사용할 때 최대 receiver window size는 65,535 * (2^14) = 1,073,725,440 바이트(1GB)입니다.
TCP window scaling을 활성화하려면, 커널 파라미터 ’net.ipv4.tcp_window_scaling’ 값이 ’1’로 설정되어 있어야 합니다.
다음과 같은 명령어를 사용하면 활성화 할 수 있습니다.
$ sysctl -w net.ipv4.tcp_window_scaling="1"
참고로, 통신하는 두 host 양 측 모두 TCP window scaling 옵션을 활성화해야 올바르게 동작하게 됩니다.
그리고 일반적으로 클라이언트 OS(Windows, MAC OS X, iOS, Android)들은 이 옵션이 활성화되어 있습니다.
3.3 TCP socket buffer size
TCP window scaling을 이용하여 receiver window size의 한계치를 증가하더라도, 실제 커널에 설정된 소켓 버퍼 크기보다 커질 수는 없을 것 입니다.
결국 receiver window size를 증가하기 위해서는, 소켓당 버퍼 크기를 증가시켜야 합니다.
이와 관련된 커널 파라미터는 다음과 같습니다.
- net.core.rmem_default
- net.core.wmem_default
- net.core.rmem_max
- net.core.wmem_max
- net.ipv4.tcp_rmem
- net.ipv4.tcp_wmem
여기서 rmem은 receive(read) buffer의 크기, wmem은 send(write) buffer의 크기를 나타냅니다.
지정되는 값들의 단위는 바이트(bytes) 입니다.
먼저 net.core 접두사가 붙은 커널 파라미터 부터 살펴 보겠습니다.
이는 TCP를 포함한 모든 종류의 소켓에 기본적으로 설정되는 버퍼 크기를 나타냅니다.
접미사 default는 그 기본값이고, max는 소켓이 가질 수 있는 최대 크기를 나타냅니다.
net.ipv4 접두사가 붙은 커널 파라미터는 TCP 소켓에 대한 부분을 설정합니다.
참고로, 이 설정값은 ipv6에서도 적용되는데, 리눅스에서는 일부 ipv4 커널 파라미터가 ipv6까지 적용 되기 때문입니다.
(ipv6에도 적용되는 커널 파라미터: net.ipv4.ip_, net.ipv4.ip_local_portrange, net.ipv4.tcp, net.ipv4.icmp_*)
각 커널 파라미터는 min / default / max로 세 정수 값으로 설정 할 수 있습니다.
min은 TCP memory pressure 상태일 때 소켓에 할당되는 버퍼 크기를 나타내고요, max는 TCP 소켓이 가질 수 있는 최대 크기를 나타냅니다.
TCP memory pressure 상태에 대해서는 조금 더 아래에서 다루도록 하겠습니다.
중간값은 default로 net.core에서 설정된 default 값을 TCP 소켓에 한정하여 덮어 씌웁니다.
특히, default 값은 TCP receive window 크기를 결정할 때 가장 주요하게 참조되는 값입니다.
이 커널 파라미터의 기본값은 리눅스 커널에 의하여 자동으로 설정(auto-tuned)되나, 대개 default 값이 128KB 정도로 설정되어 있는데요.
비교적 메모리 양이 적고, 대규모/대용량 패킷처리를 하지 않는 데스크탑에서는 적합한 설정입니다.
서버의 경우 일반적으로 메모리 양이 크기에 적절히 크기를 늘려줘도 좋을 것 같습니다. (네트워크 대역폭 – 메모리 사용량의 trade-off)
TCP receive window size를 증가시키려면, 위에서 나열한 커널 파라미터를 적당히 설정해야 합니다.
어떤 워크로드에서도 적용 가능한 완벽한 커널 파리미터는 없습니다.
다만 이 경우 trade-off 관계가 메모리 사용량 밖에 없기에, 아래와 같은 설정값을 조심스레 제안합니다.
(적당히 보수적으로 상향된 설정값입니다.)
$ sysctl -w net.core.rmem_default="253952"
$ sysctl -w net.core.wmem_default="253952"
$ sysctl -w net.core.rmem_max="16777216"
$ sysctl -w net.core.wmem_max="16777216"
$ sysctl -w net.ipv4.tcp_rmem="253952 253952 16777216"
$ sysctl -w net.ipv4.tcp_wmem="253952 253952 16777216"
이 외에 ’net.ipv4.tcp_mem’이라는 커널 파라미터가 있습니다.
이 커널 파라미터는 커널에서 TCP를 위해 사용할 수 있는 메모리 크기를 지정합니다.
위에서 소개한 파라미터들은 개별 TCP 소켓당 지정되는 값이라면, 이 값은 TCP 소켓 전체에 대한 값입니다.
이 설정값은 위에서 소개한 커널 파라미터들과 유사하게 min / pressure / max 값을 지정할 수 있습니다.
이 중 pressure는 net.ipv4.tcp_rmem, net.ipv4.tcp_wmem에서 잠깐 언급한 memory pressure의 threshold 값 입니다.
즉, TCP 소켓 전체에서 사용되는 메모리가 이 값을 초과하면, TCP memory pressure 상태가 되어 이후 소켓은 지정된 min 값의 메모리 버퍼 크기를 가지게 되는 것이죠.
다음과 같은 명령어로 현재 커널 파라미터 설정값을 확인 할 수 있습니다.
$ sysctl net.ipv4.tcp_mem
net.ipv4.tcp_mem = 185688 247584 371376
위 값은 부팅시 시스템의 메모리에 맞추어 자동으로(auto-tuned) 설정됩니다.
한가지 유의할 점은, 되도록 이 커널 파라미터 설정값을 수정하지 말아야 한다는 점 입니다.
왜냐하면, 이미 커널에 의해 시스템 메모리에 맞게 최적화된 값이 설정되기 때문입니다.
구글 검색 등으로 찾을 수 있는 커널 파라미터 설정 관련 문서 중 일부를 살펴보면, 이 값을 대폭 올리도록 가이드 하기도 하는데요.
쉽사리 찾을 수 있는 어떤 문서에는 다음과 같이 가이드 합니다.
$ sysctl -w net.ipv4.tcp_mem="8388608 8388608 8388608"
이 설정값이 왜 말이 안되는 설정값이냐면, 그 단위가 바이트(byte)가 아니라 페이지(page)이기 때문입니다.
리눅스에서는 기본적으로 1 페이지는 4,096 바이트입니다.
즉, 위 설정값대로 라면 8,388,608은 32기가바이트를 뜻 합니다. (커도 너무 크죠.)
3.4 congestion window size
그럼 receiver가 공고(advertising)한 receive window size 만큼 sender는 데이터를 네트워크로 패킷을 보낼 수 있을까요?
결론부터 말하자면, 그렇지 않습니다.
네트워크는 네트워크에 연결된 모든 노드들간 공유하는 공유 자원입니다. 개개 노드가 이를 탐욕적으로 사용하면, 네트워크 전체가 마비될 수 있습니다.
그렇기 때문에, 각 노드들은 적당한 congestion avoidance algorithm을 사용하여 보내는 데이터 양을 자체적으로 조정하고 있습니다.
이 congestion avoidance algorithm은 receiver와는 상관없이 (receiver window size 등 peer가 알려주는 정보와는 무관하게) 독자적으로 네트워크에 보낼 데이터 양을 정합니다.
리눅스에서는 reno, vegas, new reno, bic, cubic 등의 congestion avoidance algorithm을 사용할 수 있는데, 요즈음의 일반적인 리눅스 배포판에서는 cubic가 기본적으로 설정되어 있습니다.
congestion avoidance algorithm은 몇 가지 파라미터를 참조(RTT가 가장 주요한 파라미터가 될 것입니다.)하여 congestion window 크기를 설정하게 되는데요. 이 크기가 한번에 보낼 수 있는 데이터 양의 최대치가 될 것입니다. congestion window 크기는 애플리케이션이나 커널 파라미터로 설정 될 수 있는 값은 아닙니다.
리눅스에서는 ss와 같은 유틸리티를 통해 각 소켓별 현재 congestion window 크기를 확인할 수 있습니다.
$ ss -n -i
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
tcp ESTAB 0 0 10.77.57.57:33000 10.77.57.57:47142
cubic wscale:7,7 rto:208 rtt:5.236/10.107 ato:40 mss:65483 cwnd:10 send 1000.5Mbps rcv_rtt:4 rcv_space:43690
이 소켓은 congestion avoidance algorithm으로 cubic을 사용하고, 현재 congestion window size가 10임을 알 수 있습니다.
즉, 한번에 보낼 수 있는 패킷 개수는 10개이며 약 15KB 정도의 데이터를 한번에 보낼 수 있을 것입니다.
이 congestion window size는 TCP의 혼잡 제어 전략에 따라 slow start 방법으로 최초 연결시 정해진 ’initial congestion window size(CWND)’부터 어느 정도 선까지 지속적으로 증가하게 됩니다.
그리고 통신이 지속적으로 진행되면서 receiver로 부터 ACK 패킷을 받으면, congestion window size를 현재 크기의 2배 만큼씩 증가 시킵니다.
(그 와중에 패킷이 유실되거나 한다면 congestion window size를 감소시킬텐데요. 이는 congestion avoidance algorithm에 따라 얼마만큼 경감할지 달라집니다.)
그런데, 이러한 특성 때문에 RTT가 비교적 높은 모바일 환경에서 취약한 면이 있습니다.
예를 들어, receive window size가 64KB인 receiver가 있다고 합시다. sender의 initial congestion window가 1이라면, congestion window size가 64KB에 도달하기 위해서는 peer로 부터 6번의 ACK을 받아야 합니다.
이 때 RTT가 500ms라면 3초 이후에야 receive window size만큼 congestion window size가 증가될 것입니다.
이러한 이유 때문에 구글에서는 2010년경 TCP initial congestion window size를 10으로 상향(일반적으로 1 혹은 2로 설정) 하자는 의견을 내놓기도 했습니다.
그러나 다시 한번 이야기 하자면, 모든 워크로드와 조건을 만족하는 설정값은 없습니다.
네트워크 상 모든 peer들이 initial congestion window size를 10으로 증가 설정하고, 항상 이 패킷수보다 많은 통신을 빈번히 하게 된다면 전체 네트워크가 혼잡한 상황이 되는 재앙이 발생할 수도 있을 것입니다.
또, 한번에 주고 받는 패킷 크기가 상대적으로 작다면 initial congestion window size를 조정해도 크게 이득이 없을 수 있습니다.
initial congestion window size를 변경하기 위해서는, 커널 파라미터가 아니라 ip route 명령을 사용할 수 있습니다.
먼저, 현재의 라우팅 정보를 확인하려면 아래와 같은 명령어를 사용합니다.
$ ip route show
192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.100 metric 1
169.254.0.0/16 dev eth0 scope link metric 1000
default via 192.168.1.1 dev eth0 proto static
여기서는 default 라우팅 설정을 변경할텐데요. 위의 설정값을 토대로 아래와 같이 입력하여 initial congestion window size를 변경합니다.
$ ip route change default via 192.168.1.1 dev eth0 proto static initcwnd 10
적용되었음을 확인하려면, 아래와 같은 명령어를 사용합니다.
$ ip route show
192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.100 metric 1
169.254.0.0/16 dev eth0 scope link metric 1000
default via 192.168.1.1 dev eth0 proto static initcwnd 10
참고로 특정 커널 버전(2.6.18)에서는 ethernet 설정에서 TSO를 활성화하면 이 수치가 무시되는 버그가 있습니다.
(비교적 오래된 커널이라 최근 배포판에서는 관계가 없지만, Redhat/CentOS 5 버전이 이 커널을 사용합니다.)
또 살펴볼 만한 slow start와 관련된 리눅스 커널 파라미터는 ’net.ipv4.tcp_slow_start_after_idle’ 입니다.
이 파라미터는 0 혹은 1로 설정할 수 있는데요.
1로 설정되어 있으면 congestion window size가 증가된 소켓이라도 특정 시간 동안의 idle(통신이 없는) 상태에 지속되면, 다시 slow start를 통해 initial congestion window size에서 부터 congestion window size를 증가해야 합니다.
반대로 0으로 설정되어 있으면, 일정 시간 통신이 없더라도 congestion window size가 유지 됩니다.


Leave a Reply