
새로운 기능 — Amazon EMR on Amazon Elastic Kubernetes Service(EKS)

수만 명의 고객이 Amazon EMR을 사용하여 Apache Spark, Hive, HBase, Flink,Hudi 및 Presto와 같은 프레임워크에서 빅 데이터 분석 애플리케이션을 대규모로 실행합니다. EMR은 이러한 프레임워크의 프로비저닝 및 조정을 자동화하고 다양한 EC2 인스턴스 유형으로 성능을 최적화하여 가격 및 성능 요구 사항을 충족합니다. 이제 고객은 Kubernetes를 사용하여 조직 전체에서 컴퓨팅 풀을 통합하고 있습니다. Amazon Elastic Kubernetes Service(EKS)에서 Apache Spark를 관리하는 일부 고객은 EMR을 사용하여 프레임워크 및 AWS 서비스와의 통합을 설치하고 관리하는 번거로움을 없애고자 합니다. 또한 고객은 EMR이 제공하는 더 빠른 런타임, 개발 및 디버깅 도구를 활용하기를 원합니다.
오늘은 고객이 EKS에서 오픈 소스 빅 데이터 프레임워크의 프로비저닝 및 관리를 자동화할 수 있는 EMR의 새로운 배포 옵션인 Amazon EKS on Amazon EMR의 출시를 발표합니다. EKS 기반 EMR을 통해 고객은 이제 동일한 EKS 클러스터에서 다른 유형의 애플리케이션과 함께 Spark 애플리케이션을 실행하여 리소스 활용율을 높이고 인프라 관리를 간소화할 수 있습니다.
고객은 EMR 애플리케이션을 다른 유형의 애플리케이션과 동일한 EKS 클러스터에 배포할 수 있습니다. 따라서 리소스를 공유하고 단일 솔루션으로 표준화하여 모든 애플리케이션을 운영 및 관리할 수 있습니다. 고객은 최신 프레임워크 액세스, 성능 최적화 런타임, 애플리케이션 개발을 위한 EMR 노트북, 디버깅을 위한 Spark 사용자 인터페이스 등 현재 EC2에서 사용하는 EKS 기반 EMR 기능을 모두 사용할 수 있습니다.

Amazon EMR은 빅 데이터 프레임워크가 있는 컨테이너에 애플리케이션을 자동으로 패키징하며, 다른 AWS 서비스와 통합하기 위해 사전 구축된 커넥터를 제공합니다. 그런 다음 EMR은 EKS 클러스터에 애플리케이션을 배포하고 로깅 및 모니터링을 관리합니다. EKS 기반 EMR을 사용하면 EKS 기반 표준 Apache Spark에 비해 EMR에 포함된 성능 최적화 Spark 런타임을 사용하여 3배 더 빠른 성능을 얻을 수 있습니다.
Amazon EMR on EKS – 시작하기
Spark 작업을 실행하는 EKS 클러스터가 이미 있는 경우 AWS Management Console, AWS 명령줄 인터페이스(CLI) 또는 API를 사용하여 EMR에 기존 EKS 클러스터를 등록하여 Spark 애플리케이션을 배포하면 됩니다.
예를 들어, 다음은 EKS 클러스터를 등록하는 간단한 CLI 명령입니다.
$ aws emr-containers create-virtual-cluster
--name <virtual_cluster_name>
--container-provider '{
"id": "<eks_cluster_name>",
"type": "EKS",
"info": {
"eksInfo": {
"namespace": "<namespace_name>"
}
}
}EMR 관리 콘솔의 가상 클러스터 목록에서 확인할 수 있습니다.
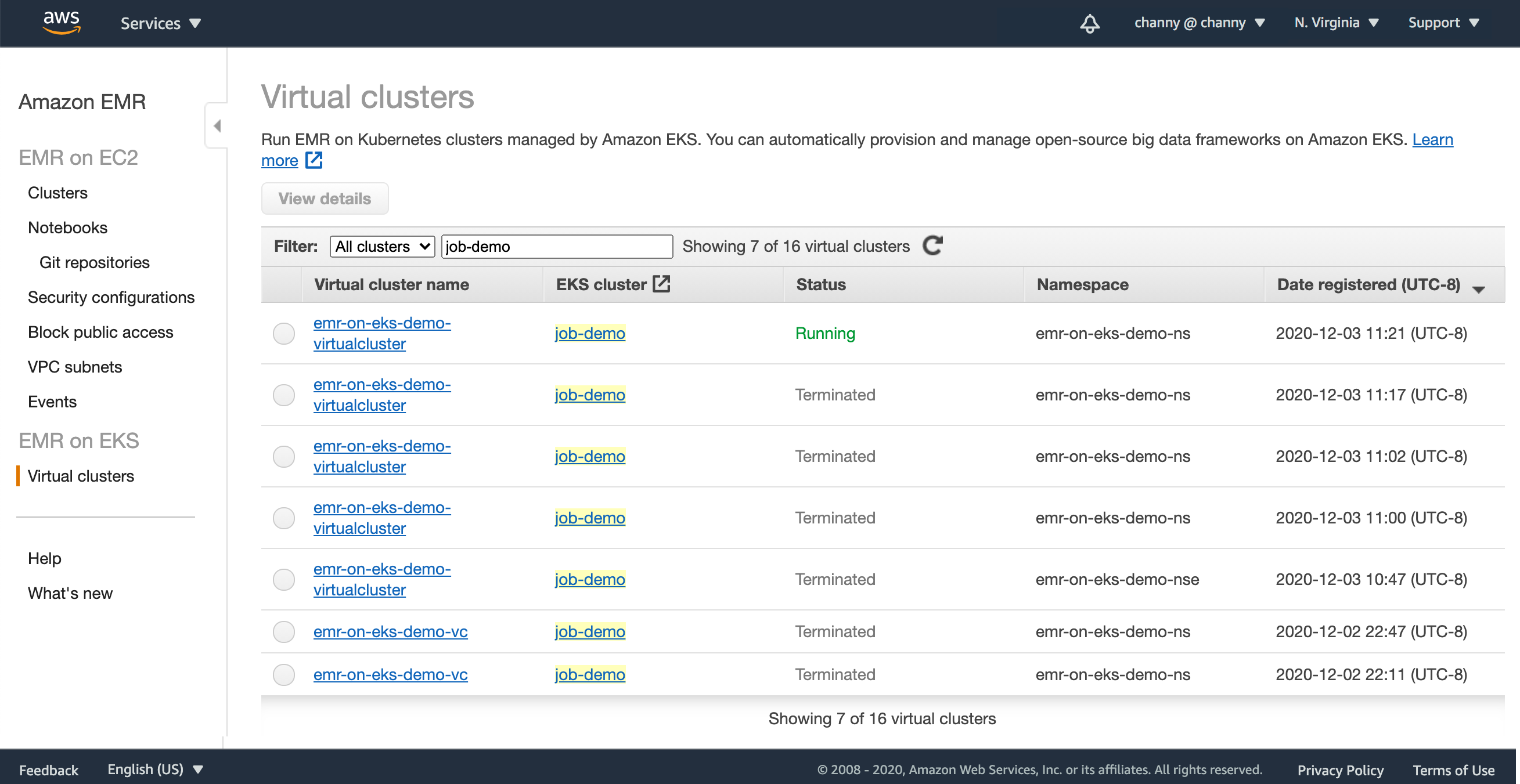
Amazon EKS 클러스터가 등록되면 EMR 워크로드가 Kubernetes 노드와 Pod에 배포되어 애플리케이션 실행 및 Auto Scaling을 관리하고, 노트북과 SQL 클라이언트에 연결할 수 있도록 관리형 엔드포인트를 설정합니다. EMR은 분석 애플리케이션에 사용되는 오픈 소스 프레임워크에 대한 성능 최적화 런타임을 구축 및 배포합니다.
다음과 같이 Spark 작업을 간단하게 시작할 수 있습니다.
$ aws emr-containers start-job-run
--name <job_name>
--virtual-cluster-id <cluster_id>
--execution-role-arn <IAM_role_arn>
--virtual-cluster-id <cluster_id>
--release-label <<emr_release_label>
--job-driver '{
"sparkSubmitJobDriver": {
"entryPoint": <entry_point_location>,
"entryPointArguments": ["<arguments_list>"],
"sparkSubmitParameters": <spark_parameters>
}
}작업을 모니터링하고 디버깅하려면 모니터링 구성의 일부로 구성된 Amazon CloudWatch 및 Amazon Simple Storage Service(S3) 위치에 업로드된 검사 로그를 사용할 수 있습니다. 콘솔에서 원클릭 환경을 사용하여 Spark History Server를 시작할 수도 있습니다.
Amazon EMR Studio와 통합
이제 AWS SDK 및 AWS CLI, Amazon EMR Studio 노트북, Apache Airflow같은 워크플로 오케스트레이션 서비스를 사용하여 분석 애플리케이션을 제출할 수 있습니다. Amazon EMR on EKS를 위한 새로운 Airflow Operator를 개발했습니다. 이 커넥터를 자체 관리형 Airflow와 함께 사용하거나 Amazon Managed Workflows for Apache Airflow로 플러그인 위치에 추가하여 사용할 수 있습니다.
새 평가판 Amazon EMR Studio를 사용하여 웹 기반 IDE(통합 개발 환경)에서 데이터 분석 및 데이터 엔지니어링 작업을 수행할 수도 있습니다. Amazon EMR Studio를 사용하면 Studio 인터페이스를 사용하여 EKS에 배포된 EMR 클러스터에 노트북 코드를 제출할 수 있습니다. Studio 사용자가 Workspace를 연결할 수 있는 하나 이상의 관리형 엔드포인트를 설정하면 EMR Studio는 가상 클러스터와 통신할 수 있습니다.
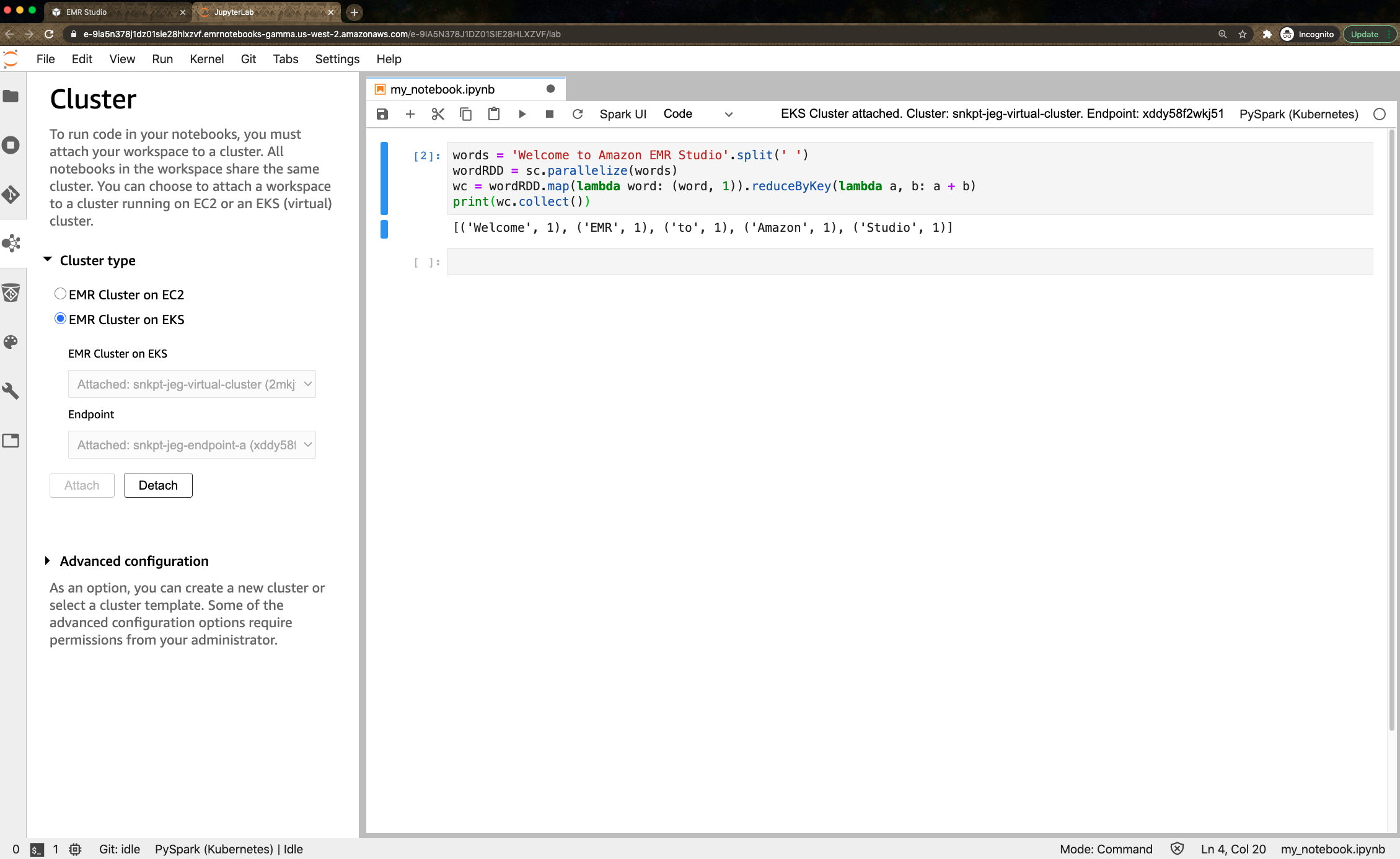
EMR Studio 평가판의 경우 가상 클러스터에 대한 관리형 엔드포인트를 만들 때 추가 비용이 들지 않습니다. 자세한 내용은 블로그 게시물과 안내서 문서를 참조하세요.
정식 출시
Amazon EMR on Amazon EKS는 현재 미국 동부(버지니아 북부), 미국 서부(오레곤) 및 EU(아일랜드) 리전에서 사용할 수 있습니다. EKS용 AWS Fargate에서 EMR 워크로드를 실행할 수 있으므로 서버리스 옵션으로 Pod 인프라를 프로비저닝하고 관리할 필요가 없습니다.
자세한 내용은 설명서를 참조하세요. Amazon EMR의 AWS 포럼 또는 평소 이용하는 AWS 지원 연락처를 통해 피드백을 보내주시기 바랍니다.
Amazon EMR on Amazon EKS에 대한 모든 세부 정보를 알아보고 지금 바로 시작하세요.
— Channy;
Source: 새로운 기능 — Amazon EMR on Amazon Elastic Kubernetes Service(EKS)


Leave a Reply