클라우드 기반 슈퍼 컴퓨팅 — 9.95페타플롭스(PFLOPS) 처리 용량 및 TOP500 목록에서 41위 차지 하다!
일기 예보, 게놈 시퀀싱, 지리 분석, CFD(전산 유체 역학) 및 기타 유형의 고성능 컴퓨팅(HPC) 워크로드는 엄청난 양의 컴퓨팅 성능을 활용할 수 있습니다. 이러한 워크로드는 종종 급증하고 병렬로 대량 발생하며 빠른 결과 산출이 중요한 상황에서 사용됩니다.
기존 방식
정부, 자금 지원 연구 기관 및 Fortune 500대 기업들은 경쟁 우위를 확보하기 위해 슈퍼컴퓨터에 수천만 달러를 투자합니다. 최첨단 슈퍼컴퓨터를 구축하려면 전문화된 전문 지식, 수년간의 계획, 아키텍처 및 구현에 대한 장기적인 노력이 필요합니다. 슈퍼컴퓨터가 구축되면 해당 투자에 대한 성과를 얻기 위해 슈퍼컴퓨터를 바쁘게 유지해야 하며, 이에 따라 작업이 차례를 기다리는 동안 대기열이 길어집니다. 용량을 추가하고 새로운 기술을 활용하는 것은 비용이 많이 들 뿐 아니라 시스템의 과부하를 초래할 수도 있습니다.
새로운 방식
이제 클라우드에서 가상 슈퍼컴퓨터를 구축할 수 있습니다! 10년 이상 동안 수천만 달러를 투자하는 대신 간단하게 필요한 리소스를 확보하고 문제를 해결하고 리소스를 해제할 수 있습니다. 필요할 때 필요한 만큼의 성능만 확보해서 사용할 수 있습니다. 사용 가능한 리소스에 맞춰 문제를 해결하는 대신, 필요한 리소스의 수를 파악하고 확보하여 최대한 자연스럽고 신속한 방법으로 문제를 해결할 수 있습니다. 단일 프로세서 아키텍처를 10년 동안 개발할 필요가 없으며, 새로운 기술이 출시될 때마다 새로운 기술을 쉽게 도입할 수 있습니다. 장기적인 노력 없이 모든 규모의 실험을 수행할 수 있으며, GPU나 기계 학습 교육 및 추론용 전문 하드웨어와 같은 새로운 기술에 대한 경험을 쌓을 수 있습니다.
Top500 슈퍼 컴퓨터 목록
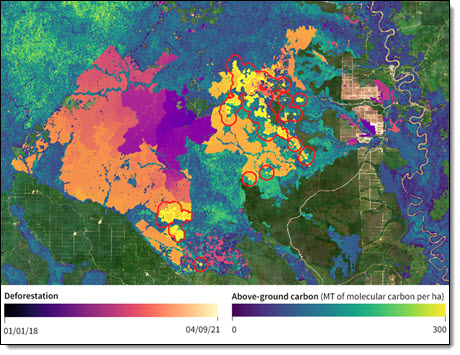
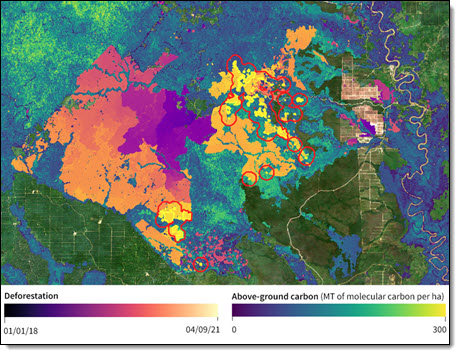
보르네오 칼리만탄 지역의 과거 삼림 벌채와 산림 탄소 손실 추정에 대한 Descartes Labs의 광학 및 레이더 위성 이미지 분석.
AWS 고객인 Descartes Labs는 HPC를 사용하여 세계의 정보를 파악하고 지상, 수중 및 우주의 센서로부터 수신되는 방대한 양의 데이터를 처리합니다. 이 회사는 초창기부터 클라우드에 기반했으며 페타바이트급 데이터를 활용하는 지리공간 애플리케이션에 초점을 맞추고 있습니다.
CTO 겸 Co-Founder인 Mike Warren은 컴퓨팅 성능의 제한을 받지 않도록 하는 것이 그들이 의도라고 말했습니다. 초창기에 Mike는 우주의 시뮬레이션 작업을 하면서 Loki, Avalon 및 Space Simulator를 포함한 여러 개의 클러스터와 슈퍼컴퓨터를 구축했습니다. Mike는 상용 하드웨어로부터 클러스터를 처음 구축한 사람 중 하나였으며 그 과정에서 많은 것을 배웠습니다.
Los Alamos National Lab에서 은퇴한 후, Mike는 Los Alamos National Labs를 공동 설립했습니다. 2019년에 Descartes Labs는 1.93 PFLOPS 성능의 TOP500 실행을 위해 AWS를 사용했으며, 2019년 6월의 TOP500 목록에서 136위에 올랐습니다. 이 실행은 C5 인스턴스 클러스터에서 41,472 코어를 사용했습니다. 특히 Mike는 EC2 팀의 도움이나 조정 없이 이 실행을 시작했다고 말했습니다(Descartes Labs는 고객을 위해 이러한 규모의 프로덕션 작업을 일상적으로 실행하기 때문에 이미 계정의 서비스 할당량이 충분히 높았음). 이 실행에 대해 자세히 알아보려면 Thunder from the Cloud: 40,000 Cores Running in Concert on AWS(클라우드 소식: AWS에서 연동하여 실행되는 40,000개의 코어)를 참조하세요. 이 이야기는 제가 가장 좋아하는 부분입니다.
우리는 AWS 미국 동부 1 리전의 노드 그룹에 대한 액세스 권한을 부여받았으며 요금은 회사 신용 카드로 약 5,000 USD가 청구되었습니다. 이 속도로 사용자 지정 하드웨어를 실행하는 데 드는 비용은 2천만~3천만 USD에 가까우므로 HPC의 대중화 가능성은 명백했습니다. 6~12개월의 대기 시간은 말할 것도 없습니다.
이 실행이 성공한 후 Mike와 그의 팀은 2021년에 7.5 PFLOPS를 목표로 하는 훨씬 더 실질적인 실행 작업을 수행하기로 결정했습니다. EC2 팀과 협력하여 6월 초에 48시간 동안 EC2 온디맨드 용량 예약을 확보했습니다. 한 번에 1,024개의 인스턴스만 사용하는 “작은” 실행들을 수행한 후 촬영 준비가 완료되었습니다. 그리고 총 172,692개 코어로 4,096개의 EC2 인스턴스(C5, C5d, R5, R5d, M5 및 M5d)를 실행했습니다. 결과는 다음과 같습니다.
- Rmax — 9.95 PFLOPS. 이것은 실제로 달성된 성능입니다. 초당 1경 가량의 부동 소수점 연산을 수행했습니다.
- Rpeak – 15.11 PFLOPS. 이것이 이론적인 최고 성능입니다.
- HPL 효율성 – 65.87%. Rmax와 Rpeak 간의 비율이며 하드웨어 활용률에 대한 척도입니다.
- N: 7,864,320. 이것은 Top500 벤치마크를 수행하기 위해 반전되는 행렬의 크기입니다. N2는 약 61.84조입니다.
- P x Q: 64 x 128. 이것은 실행에 대한 파라미터이며 처리 그리드를 나타냅니다.
이 실행은 2021년 6월 TOP500 목록에서 41위에 올랐으며 불과 2년 만에 417%의 성능 향상을 나타냅니다. 다른 CPU 기반 실행과 비교하면, 이 실행은 20위를 차지합니다. GPU 기반 실행은 매우 인상적이지만, 개별 순위를 지정하면 최상의 비교 결과를 얻을 수 있습니다.
Mike와 그의 팀은 결과에 매우 만족했으며 모든 규모의 HPC 작업에 대해 클라우드의 성능과 가치를 입증한다고 믿었습니다. Mike는 1993년에 1위를 차지한 Thinking Machines CM-5(Jurassic Park에서 잠깐 출연)가 실제로는 단일 AWS 코어보다 느리다고 지적했습니다.
이 실행은 6월 4일 오전 11시 56분(태평양 표준시)에 마무리되었습니다. 불과 24분 뒤인 12시 20분경에 클러스터가 해제되고 모든 인스턴스가 중지되었습니다. 이것이 온디맨드 슈퍼컴퓨팅의 힘입니다!
Beowulf 클러스터를 상상해 보세요
Slashdot의 초창기에, 당시 인상적인 하드웨어를 참조하는 모든 게시물에는 항상 ‘Beowulf 클러스터를 상상해 보세요’라는 문구가 언급되어 있었습니다. 오늘날에는 거의 모든 규모의 클러스터를 쉽게 상상하고 실행할 수 있으며 이를 사용하여 대규모 컴퓨팅 요구 사항을 해결할 수 있습니다.
AWS 클라우드의 속도와 유연성을 활용할 수 있는 행성 규모의 문제가 있다면, 상상력을 발휘할 때입니다! 시작하는 데 도움이 되는 몇 가지 리소스는 다음과 같습니다.
- AWS 고성능 컴퓨팅(HPC) 페이지.
- AWS HPC 리소스.
- AWS HPC 블로그.
- AWS HPC 워크숍.
- AWS ParallelCluster.
- AWS 고성능 컴퓨팅(HPC) 컴피턴시 파트너.
축하합니다
이 놀라운 업적을 대해 Mike와 Descartes Labs 팀에게 축하를 전하고 싶습니다! Mike는 수십 년 동안 대량 생산, 상용 하드웨어 및 소프트웨어가 슈퍼 컴퓨터를 구축하는 데 사용될 수 있다는 것을 세계에 증명하기 위해 노력해 왔으며 그 결과는 스스로 말하는 것 이상입니다.

이 실행과 Descartes Labs에 대해 자세히 알아보려면, Descartes Labs가 AWS 기반의 클라우드 기반 슈퍼컴퓨팅 시연을 통해 TOP500 41위를 달성하여 규모에 맞는 지리 공간 데이터 분석의 새로운 시대 예고를 읽어 보세요.
— Jeff;
Source: 클라우드 기반 슈퍼 컴퓨팅 — 9.95페타플롭스(PFLOPS) 처리 용량 및 TOP500 목록에서 41위 차지 하다!


Leave a Reply