Amazon Aurora의 병렬 쿼리 기능 출시
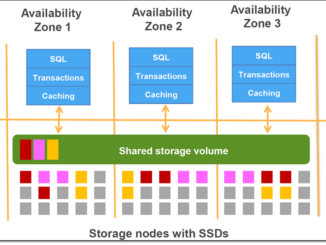
Amazon Aurora의 병렬 쿼리 기능 출시 Amazon Aurora는 클라우드에서 제공되는 풍부한 네트워킹, 처리 및 스토리지 리소스를 활용하도록 설계된 관계형 데이터베이스입니다. Aurora에서는 사용자의 MySQL 및 PostgreSQL과 호환성을 유지하면서 최신의 특별히 설계된 분산 스토리지 시스템을 은밀하게 사용할 수 있습니다. 고속 SSD 스토리지에 있는 3개의 개별 AWS 가용 영역에 분산된 수백 개의 스토리지 노드에 데이터가 스트라이프되고, 영역당 2개의 복사본이 생성됩니다. 그림으로 설명하면 다음과 같습니다(Amazon Aurora 시작하기에서 발췌). 새로운 병렬 쿼리 AWS는 Aurora를 출시할 때 동일한 스케일아웃 설계 원칙을 다른 계층의 데이터베이스 스택에 적용할 계획임을 암시했습니다. 오늘은 AWS의 다음 단계에 대해서도 알려 드리겠습니다. 위의 그림에 나온 스토리지 계층의 각 노드에는 다량의 처리 성능도 포함됩니다. 이제 Aurora에서 분석 쿼리(주로 적정 크기의 테이블 전체 또는 다수를 처리하는 분석 쿼리)를 가져와 수백 또는 수천 개의 스토리지 노드에서 두 자릿수에 가까운 속도로 병렬 실행하여 이 처리 성능을 활용할 수 있습니다. 이 새로운 모델에서는 네트워크, CPU 및 버퍼 풀 [ more… ]


