Parquet 형식의 EMRFS S3 최적화 커미터를 통한 Apache Spark 쓰기 성능 개선하기
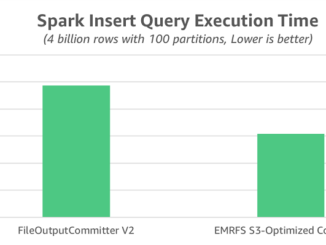
Parquet 형식의 EMRFS S3 최적화 커미터를 통한 Apache Spark 쓰기 성능 개선하기 EMRFS S3 최적화 커미터는 Amazon EMR 5.19.0부터 Apache Spark 작업에 사용할 수 있는 새로운 출력 커미터입니다. 이 커미터는 EMRFS(EMR 파일 시스템)을 사용하는 Amazon S3에 Apache Parquet 파일을 쓸 때의 성능을 개선합니다. 이 게시물에서는 최근 성능 벤치마크를 실행하여 신규 최적화된 커미터를 기존 커미터 알고리즘(FileOutputCommitter 알고리즘 버전 1 및 2)과 비교하여 어떻게 Spark 쓰기 성능이 개선되었는지 알아봅니다. 실제 사용 시, 제약 사항에 대해 설명하고 가능한 해결 방법을 제시해 드리고자 합니다. EMRFS S3와 FileOutputCommitter와 비교 Amazon EMR 버전 5.19.0 이하에서는 Amazon S3에 Parquet를 쓰는 Spark 작업에는 기본적으로 FileOutputCommitter라고 하는 Hadoop 커밋 알고리즘이 사용해 왔습니다. 이 알고리즘에는 버전 1과 버전 2의 두 가지 버전이 있습니다. 두 버전 모두 임시 위치에 중간 작업 출력을 쓰는 방법을 활용합니다. 그런 다음 이름 바꾸기 작업을 수행하여 작업 완료 시간에 데이터를 표시합니다. 알고리즘 버전 1에는 두 가지 [ more… ]