
Building Business Systems with Domain-Specific Languages for NGINX & OpenResty, Part 2

This post is adapted from a presentation at nginx.conf 2016 by Yichun Zhang, Founder and CEO of OpenResty, Inc. This is the second of two parts of the adaptation. In Part 1, Yichun described OpenResty’s capabilities and went over web application use cases built atop OpenResty. In this part, Yichun looks at what a domain-specific language is in more detail.
You can view the complete presentation on YouTube.
td {
padding-right: 10px;
}
Table of Contents
26:17 A Web Platform As A Virtual Machine

Back to our main topic: we’re talking about DSLs built atop OpenResty. We’ve been talking about many OpenResty features, some of which are very new.
My point is that OpenResty can be used as a virtual machine, just like JVM. But it can be more powerful and more Web-oriented.
The experiment was actually done six to seven years ago. It’s nothing new, but I love experimenting.
I worked for Taobao, one of the largest C2C ecommerce websites in China, which is a subcompany of the Alibaba Group. I think most of you have heard of Alibaba. I worked on the data analytics product of Taobao whose customers are Taobao’s merchants, like eBay’s merchants are sellers.
They wanted a data analytics product to analyze the traffic to their shops, and also the effects of ad deployment as well as their sales. It was a big product.
This was the homepage of that product.
We have a lot of nifty charts, just like Google Analytics. But we have so many different reports, data reports.
The data volume is huge because of the size of Taobao.
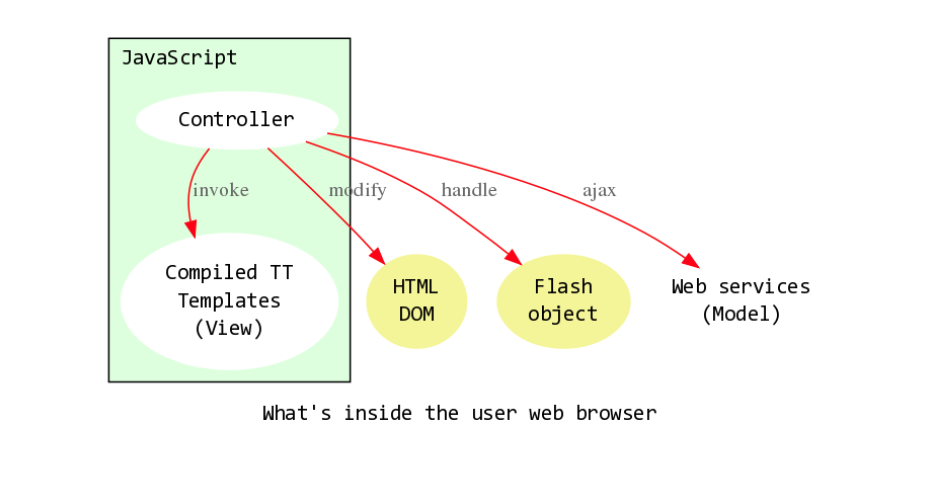
I experimented on the client side, the rich Internet application approach. It was seven years ago. Basically, the whole application’s logic is reading each other’s script running in the web browser, like Gmail.
We also introduced a client-side template. We have a compiler that can generate JavaScript code from template files. We’ll talk about that later.
Also, we have web services to drive the client-side applications. Web services are the key. They’re the only things that run on the server side.
The web services emit JSON data to the client and JavaScript renders the page regions using the compiled version of the templates.
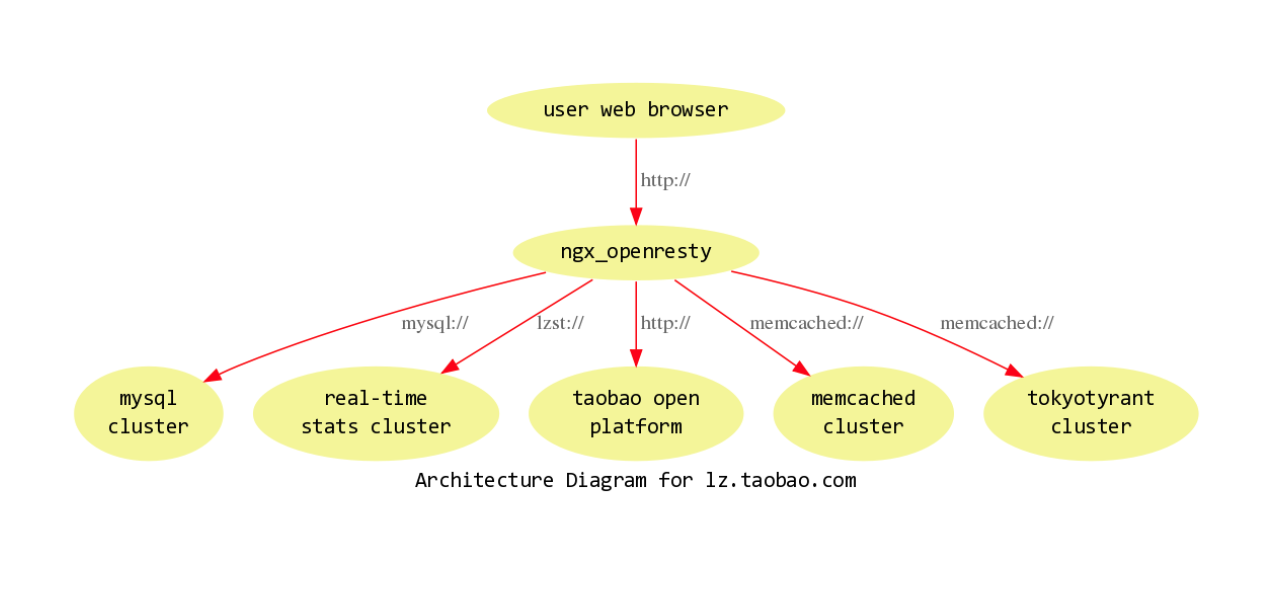
The whole server-side architecture of that data analytics product was like this: basically, OpenResty sits at the center between our backends and the web browsers, our customers.
The backends consist of a huge MySQL cluster because the data volume is so large. It’s almost 100 mils.
Also, there’s a real-time statistics cluster to provide real-time statistics.
And also, there’s Taobao’s open platform which is an open API that emits JSON. We also have a Memcached cluster and Tokyo Tyrant cluster for other metadata.
So, it’s much simpler than the previous version, which used PHP to run the whole product.
30:10 Inventing the LZSQL Language
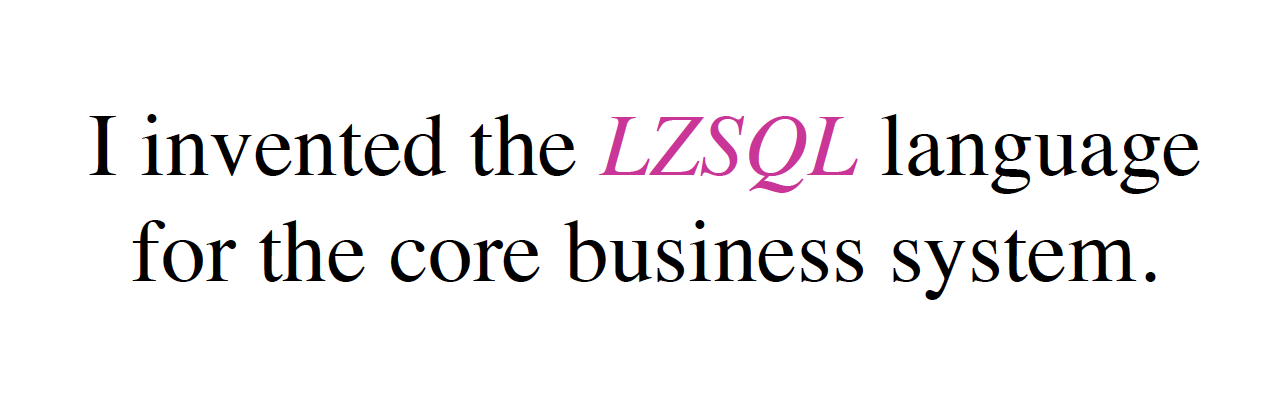
I quickly realized the problem: I didn’t have enough men, I only had two intern students besides me. That was my whole team.
But we had to migrate the whole data analytics product, written in PHP, over to the new OpenResty platform. At the time OpenResty was still very young.
I forced my intern students to write in Lua directly. That’s a very complicated business log because of all the different dimensions of business logic in Taobao and very crazy business requirements.
I thought about it hard throughout the night and I invented a DSL (domain-specific language) for the whole system because I understood the core pattern or model of the data analytics product.
And to leverage that understanding, we can provide a natural way to express our business logic to the machines.
So think about it: what is programming? Programming is essentially an activity to communicate with machines, to make machines understand your intentions. And it runs your business fast, cheaply, and reliably.
The key is to increase the efficiency of communicating with machines.
If you can use two words or two sentences to convey an idea, then there’s no need to use ten solid lines of code. That’s crazy.
For example, I’m not a big fan of Java, obviously, because it’s so much code. And, for this case, Lua is not up to the task. Neither are similarly imperative languages.
So I invented my own language, my own way, to convey the idea to the machine. It’s based on SQL. Why? Because data analytics products are essentially based on the relational model whether or not you are using SQL databases.
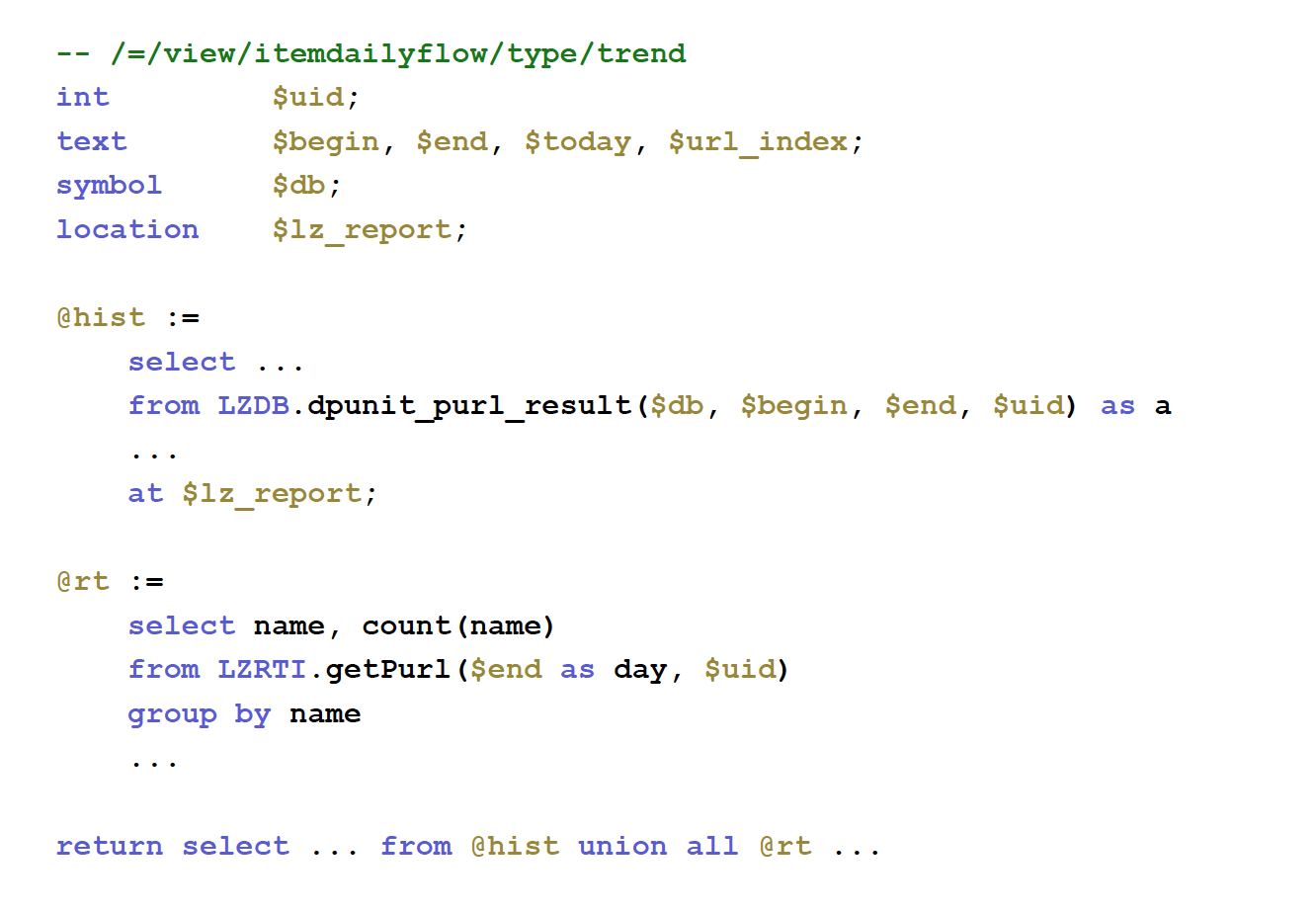
We can define variables and user variables in SQL. They are first-class citizens. The SQL can be run remotely on some MySQL backends, or it can run in place inside NGINX. I implemented a SQL engine in-memory database with just a hundred lines of Lua. It works pretty well.
The complexity comes from the fact that data needs to be fetched from many different MySQL databases. Then we need to mash up the data relationally in memory and then assemble the final result set and emit it to the client.
There are many tricky parts because you have to decompose a SQL query and run it on many different nodes, and you also need to optimize the SQL queries automatically because the MySQL optimizer often can’t do a lot of of optimizations, especially for OLAP [online analytical processing] kinds of applications.
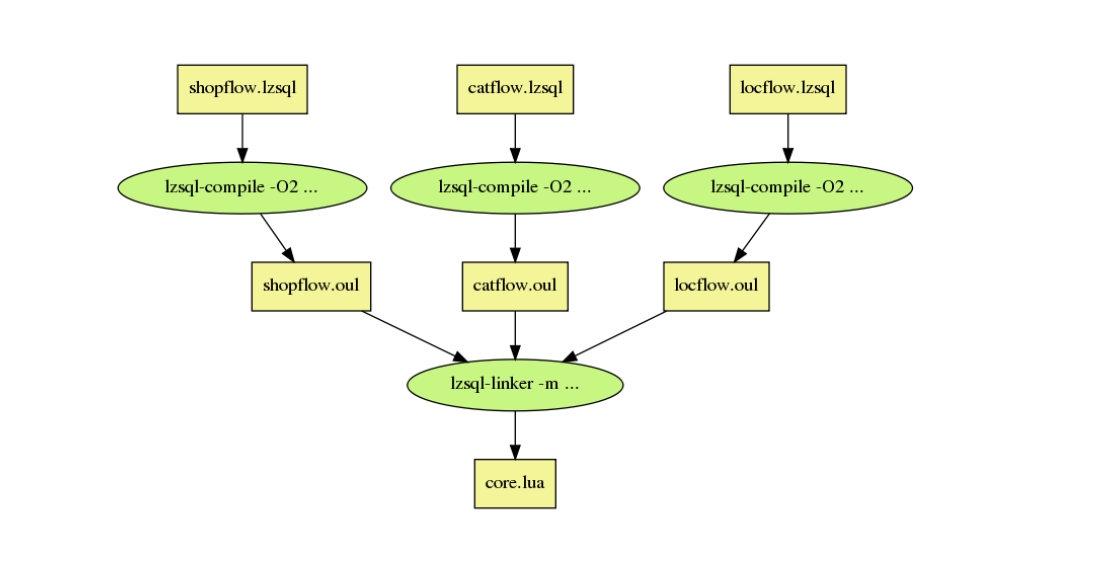
Essentially, we’re writing the business logic in LZSQL files. We use compilers to generate Lua code and, eventually, we publish our Lua code online without the compiler. That’s the beauty of compilation.

Basically, on the command line, we invoke the compiler to compile the LZSQL files and then we link it to the final Lua application.
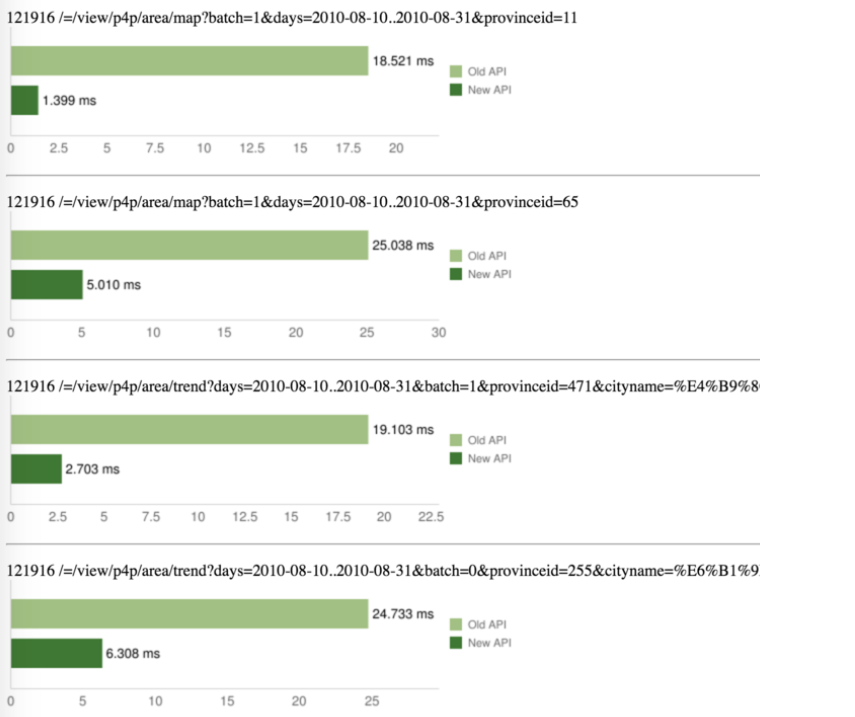
The result is very impressive because the compiler can do a lot of optimizations that a human can’t normally do, or at least can’t do properly, correctly.
The old API was written in PHP and the new API was generated Lua code from my compilers. The latency dropped a lot – like 90% or something including MySQL latency here. It’s a whole API HTTP latency.
One caveat is that we’re using the standard Lua interpreter. We’ll see in the next chart.
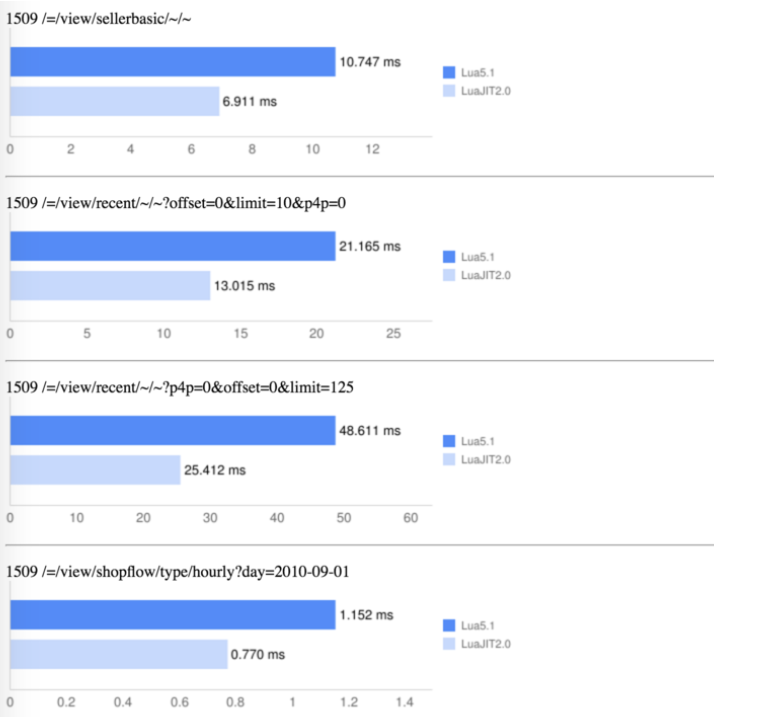
Switching to LuaJIt gives a nice speed-up further. But still, in this chart, the LuaJIT is still using the interpreter only, not the JIT compiler.
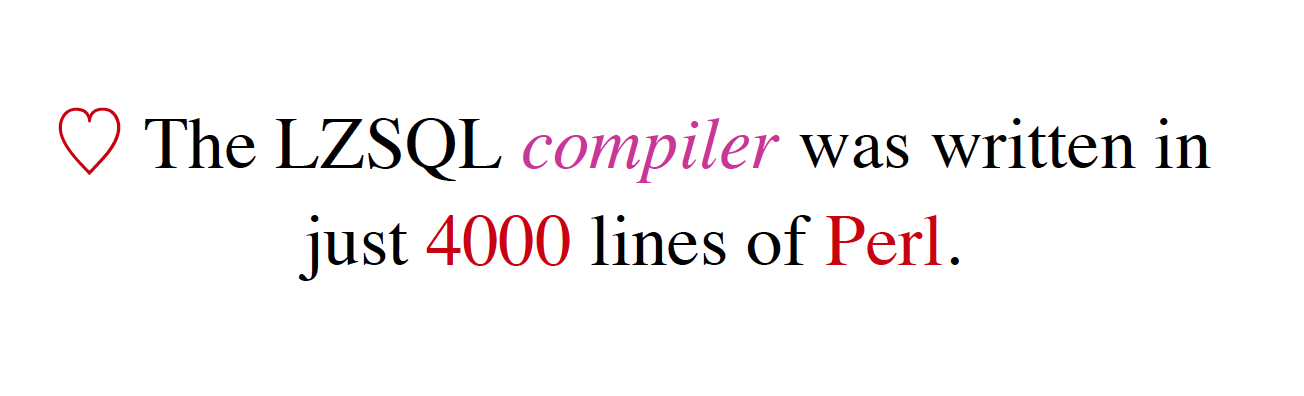
The compiler was written in just 4000 lines of Perl. Not much, but it has very complicated optimizations and Type Check checking and everything and other context-sensitive analysis.

Basically, the compiler can pull itself a parser, an AST (Abstract Syntax Tree), and some optimizers, and a code emitter. Actually, it has several code emitters because it supports multiple backends.
Yeah, we can generate Lua code, but why not C code. We can also generate C code.

If you recall, one of our backends is actually a real-time database. It provides a very specific and complicated wire protocol which is very hard to manually craft a client for.
I got an idea, because this thing has very nice documentation, a wiki page: why not let the machine understand the wiki documentation page and generate an NGINX C module for us? That idea came into my mind and I quickly did an implementation.

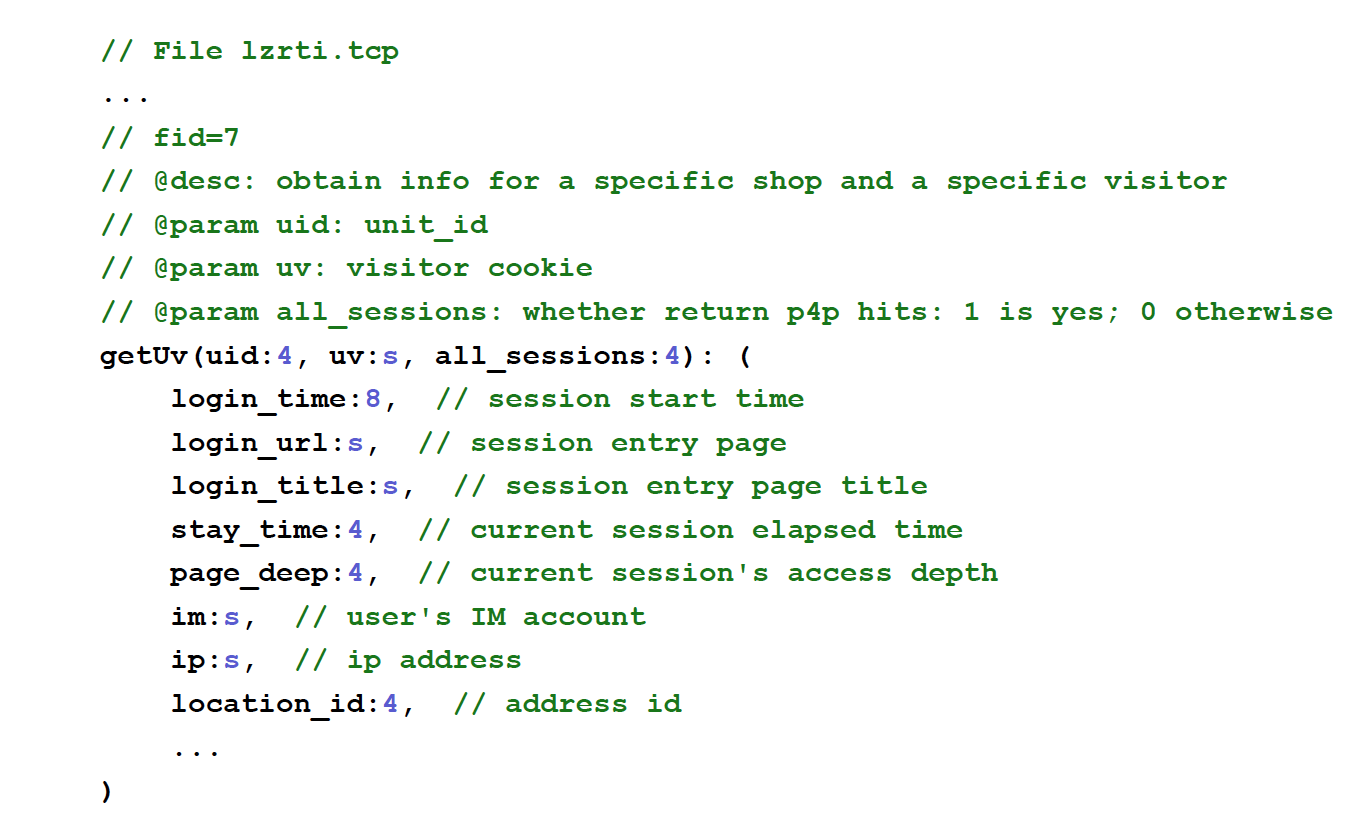
Basically, I abstracted the wiki documentation with a very small DSL, because a wiki is not very precise. But it’s very similar to the original wiki page.
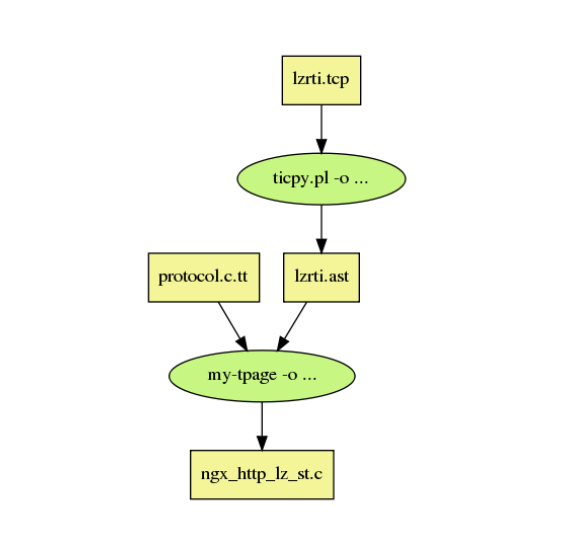
Then I wrote a very quick Perl script and a compiler to complete an NGINX C module that can talk to the real-time database nonblockingly. It’s an NGINX upstream module.

You can see that the documentation is just 300 lines of code, but the resulting C module code is more than 12,000 lines.
37:15 Writing Programs to Write Programs to Write Programs

From this example we can see that programming is about communication with machines. If your documentation is already concise and precise enough, then we can feed that to the machines directly with some guidance, maybe.
That can save all the headache of programming and implementations.
All this leads to the sentence: I’d rather write programs to write programs to write programs.
37:51 Test Scaffold

Our test scaffold is also based on DSLs. For example, we have a specification-like language syntax to describe test cases. So, this test NGINX socket is used by all OpenResty projects.
It doesn’t matter if you don’t know Perl because we are not asking you to use Perl. We provide a specification. Our services can also be tested in a similar way.
38:26 How About Tests?

The next big thing: how about tests? For new products, there’s no data. There’s no data in the databases. But we have to test our SQL queries, our web pages, our services. So I wrote a DSL that looks very similar to the SQL CREATE TABLE statements.
It’s called Cheater. Basically, you specify regular expressions for allowed value renders for paper column, and also specify the foreign key constraints between database tables. Then this tool will generate random data that satisfy all your constraints and requirements.
39:18 The OpenResty Model Language
Back to OpenResty: what can we learn from my six-years-ago experiment? Basically, we can design and provide a model language that can do something similar; that you can use SQL in OpenResty and the compiler can figure out whether to make the running remotely or locally; to do the mash up, or discompose a SQL query because you’re running it up among many different databases, not necessarily relational databases.
39:55 The OpenResty View Language

Also, there’s an OpenResty View language, the MVC Paradigm. And for View, we have template languages: for example, Perl’s TT2 template languages. It’s my favorite. And Python has got Jinja2, for example.
Such DSLs can be compiled into client side JavaScript or server side Lua code. That’s the beauty of DSLs.
40:22 Jemplate & Lemplate
For example, we already have Jemplate to compile Perl’s TT2 template language into client side JavaScript code and Lemplate for compiling down to OpenResty Lua code.
40:35 The OpenResty Controller Language

The Controller language is also a big thing.

It looks like this: basically, it’s a Lua-based language. You specify a bunch of rules.
The left-hand side of the arrows are predicates, like conditions. The right-hand side of the arrows are actions which make side effects like perform a redirect or returning an error page.
The predicates are side-effect free, which is mandatory. This makes a compiler capable of doing some very aggressive optimizations like combining those predicates out of order, and scanning, for example, the URL just once and getting results from multiple regular expressions.
To look at it, most of the CDM business logic can be conveyed in this way. This is the essence of the CDM business models.
Different business models share some kind of intrinsic properties or models. This can be, maybe, formalized. For example, data analytics products share a common relational model, relational arithmetic. SQL happens to be a convenient way to convey that idea.
And for CDN or Gateway-like or WAF-like business systems, I think the model is a rule-based model. And it’s theoretically a forward chaining expert system model.
I’m a big fan of artificial intelligence. In high school I learned a lot about various different kinds of AI branches. Nowadays, machine learning is so hot. But actually, I think another branch, the expert system branch, can also be of great use in software learning.
This is an example, I think: the syntax is based on the Prolog language, which is very popular in natural language processing, and the semantics is based on CLIPS. It’s a public demand system developed by NASA a few decades ago in the 1970s, maybe.

We also can have response filters which support multiple regular expressions to do complicated substitutions all in NGINX computers. It’s also non-buffered. So, constant buffer, infinite data stream processing: that’s pretty cool.
This example shows how to correctly remove all the C++ comments from C++ source code. You can change this example to support, for example, CSS minification, and JavaScript minification array. So it will be based on Xregex, for obvious reasons.
44:03 WAF = Hot

WAF: WAF is pretty hot. And yes, the company is launching a more secure report for NGINX. In my opinion, WAF can be based on the controller language I just demonstrated.
44:20 ModSecurity = a Horrible DSL

ModSecurity is a horrible DSL. It’s a DSL, that’s the good thing. The bad thing is that it’s horrible. It’s so horrible that it makes my baby cry.
44:30 Example of a Poor Rule from the Cold Rule Set of Mall Security
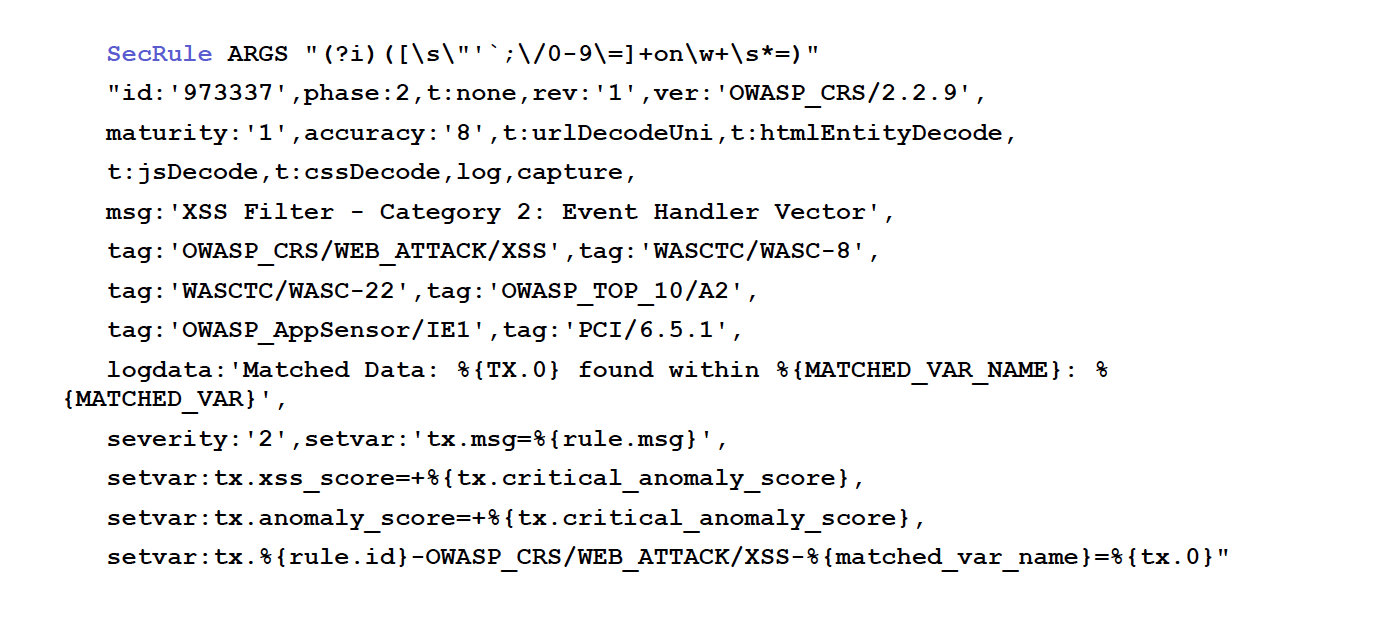
This is a rule from the cold rule set of mall security. It’s a single line, can you believe that? There are a lot of line noises. And also, to compromise the Apache configuration syntax, they made the syntax of their wack rule language very convoluted.
They also invented go-to like things like skip skip. They also have tricks to make it possible to express if else if else, because it’s flat.
Why not create a new language like what we did here?

It’s clean. For example, the down keyword can be short-circuited so if the first rule matches, the second rule will be skipped, and so are all the subsequent rules.
It’s essentially an if else. It’s more natural and it doesn’t require crazily deep nesting of indentation.
If you look at VCL or some CDN‘s business code, it’s all like a decision tree: if else if else if else. Yes, it’s crazy.
45:55 Model, View, Controller

Speaking of the essential models, like theoretical models of different kinds of business systems, I can get a model language. It’s also quite general for data analytics businesses and many microservices.
And View: we already have many template languages. They’re DSLs.
And also, we have controller languages we’ve just shown that can be used to do very complicated dynamic routing and dispatching, and even WAF for validations.
46:33 SportLang
The sports games industry could use their own sports language, their own language to describe the business systems. How could that be any cooler.
We, as professionals in the software industry, have no reason to force other industries, like physics, like math, like sports, whatever, or even philosophy, to use computer languages. That’s a shame.
Ideally, we should use domain-specific languages, their domains, their languages, their talks, and let the machine do the hard work.
Also, it opens a huge amount of possibilities for optimizations. Because not every programmer knows how to optimize things and how to optimize things nicely.
47:34 The Y Language

We have the Y language for different debugging tools for different systems like GDB, like SystemTap, like LuaJIT.
47:44 CoffeeScript

Also, we can have CoffeeScript support, because CoffeeScript is a very popular, maybe, DSL overlay language that can generate client side JavaScript. A compiler can compile CoffeeScript code into OpenResty Lua code.
48:04 A Meta DSL

We can also have a meta DSL that’s a DSL for creating all the DSLs including Self. We have a DSL specifically for creating compilers, DSL compilers, optimizing compilers. It would be great.
Perl is the best choice for me, but it’s not the best. It’s not the best choice. We can create a language specifically for compiler viewing and construction.
48:35 Clean Separation Between Business Representation and Business Implementation

We can have clean separation between business representation and business implementation, which means that we can swap the underlying implementation overnight without touching even a single line of the business code. That would be crazy.
For example, now we are running the business systems atop OpenResty. Maybe the next day we can migrate the backend to the assembly code or C code to generate pure C implementation, and without touching the business specification. That can be huge.
And migrating to a new technology stack in the future will not mean rewriting everything from scratch, but just writing, adding a new backend optimizer in the existing DSL compiler.
49:24 Compiling-Style Web Frameworks

Also, we can have brand new kinds of web application frameworks. It should be compiling-style instead of adding up layers and layers and layers which makes the whole thing run very slowly and clumsily.
And we can achieve beauty and efficiency at the same time. That is the only way that I can see, after years of business product engineering.
49:52 The Best Language
And the best language is the business language, as we’ve already said.
One nice thing about business language is that once I create a DSL and I pour some business logic into that DSL, and I happen to find the original requirement document from the customer and I compare them side-by-side and find that they look so similar, then I know I’m on the right track.
I think there is a best way to describe a specific problem demand.
50:28 The Machine Truly Understands Business Logic

So the machine that truly understands your business logic can do more than ever for you, like generating test cases, doing context-sensitive analysis, or even generating a true, runnable implementation for you on the fly.
Sorry, no time for questions.
You are welcome to contact me online either by Twitter or via email.
Thank you so much. I’m sorry for running over.
This post is adapted from a presentation at nginx.conf 2016 by Yichun Zhang, Founder and CEO of OpenResty, Inc. This was the second of two parts of the adaptation. In Part 1, Yichun described OpenResty’s capabilities and went over web application use cases built atop OpenResty. In this part, Yichun looked at what a domain-specific language is in more detail.
You can view the complete presentation on YouTube.
The post Building Business Systems with Domain-Specific Languages for NGINX & OpenResty, Part 2 appeared first on NGINX.
Source: Building Business Systems with Domain-Specific Languages for NGINX & OpenResty, Part 2


Leave a Reply