Apache Flink를 이용한 AWS기반 실시간 스트림 처리 파이프라인 구성하기
오늘날 비즈니스 환경에서, 다양한 데이터 소스의 꾸준한 증가에 맞추어 데이터는 계속적으로 생성되고 있습니다. 따라서, 원시 데이터의 대규모 스트림을 통해 실행 가능한 통찰력을 얻기 위한 데이터를 지속적으로 수집하고, 저장하고, 처리하는 능력을 갖춘다는 것은 조직의 경쟁력 측면에서 장점이라 하겠습니다.
Apache Flink는 스트림 프로세싱 파이프라인의 기반을 갖추는 데 매우 적합한 오픈소스 프로젝트 입니다. 스트리밍 데이터의 지속적인 분석에 적합한 고유한 기능을 제공합니다. 하지만, Flink를 기반으로 파이프라인 을 구축하고 유지하려면 때때로 물리적 자원 및 운영상의 노력 외에 상당한 전문 지식이 필요합니다.
이 글을 통해서 Amazon EMR, Amazon Kinesis 및 Amazon Elasticsearch Service (ES)를 사용하는 Apache Flink를 기반으로 일관성 있고 확장 가능하며 안정적인 스트림 프로세싱 파이프라인에 대한 레퍼런스 아키텍처를 설명해드리고자 합니다. AWSLabs GitHub 저장소는 레퍼런스 아키텍처를 실제로 탐색하는데 필요한 아티팩트(artifact)를 제공합니다. 리소스에는 샘플 데이터를 Amazon Kinesis Stream으로 수집하는 프로듀서(producer) 애플리케이션과 실시간으로 데이터를 분석하고 그 결과를 시각화하기 위해 Amazon ES로 보내는 Flink 프로그램이 포함되어 있습니다.
실시간으로 택시 데이터 지리적 위치 분석하기
택시의 차량 운영 최적화와 관련하여 다음과 같은 시나리오를 생각해보겠습니다. 뉴욕시에서 현재 운영중인 수많은 택시들로부터 운행 정보를 지속적으로 확보합니다. 그리고 이 데이터를 사용하여 수집된 데이터를 실시간으로 분석하고 데이터에 기반한 의사 결정을 내림으로써 운영을 최적화하고자 합니다.
예를 들어, 현재 택시 수요가 많은 지역을 의미하는 핫스팟(Hot spot)을 식별해서 빈 택시들이 이 곳으로 이동하도록 할 수 있습니다. 또, 현재 교통 상황을 파악해서 가까운 공항으로 가기 위한 대략적인 운행 시간을 고객에게 알려드릴 수도 있습니다. 당연히, 이러한 결정은 현재의 수요와 교통 상황을 상세하게 반영하고 있는 정보를 기반으로 합니다. 유입되는 데이터는 지속적이면서도 시간에 맞춰 적절하게 분석되어야 합니다. 이와 관련한 KPI와 이를 통해 도출되는 인사이트는 실시간으로 대시보드에서 액세스할 수 있어야 합니다.
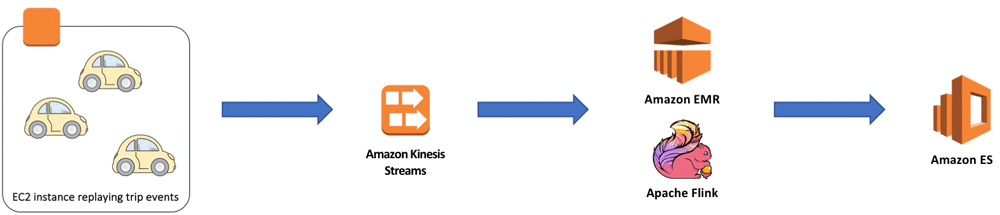
이 글의 목적에 맞게, 뉴욕시에서 수집된 택시 운행 이력 데이터셋을 Amazon Kinesis Streams로 재생해서 운행 이벤트를 만들어보겠습니다. 이 데이터셋은 New York City Taxi & Limousine Commission 웹사이트에서 얻을 수 있으며, 지리적 위치 정보와 택시 운행 관련 요금 정보 등이 포함되어 있습니다.
보다 현실적인 시나리오에서는, AWS IoT를 사용하여 택시에 설치된 원격 측정 유닛에서 데이터를 수집한 다음 이 데이터를 Amazon Kinesis Streams로 처리할 수도 있습니다.
높은 신뢰성과 확장 가능한 스트림 프로세싱 파이프라인 아키텍처
파이프라인이 택시를 운영하고 최적화하기 위한 중앙 집중형 툴을 제공하므로, 단일 노드의 장애에 대한 내성을 갖는 아키텍처를 구축하는 것은 매우 중요합니다. 파이프라인은 유입되는 이벤트의 변화율에 맞춰 적응할 것입니다. 따라서, 이벤트 수집, 실질적인 처리, 확보한 인사이트의 시각화를 다른 구성 요소들로 분리합니다. 인프라의 구성요소들 간의 결합도를 낮추고, 관리형 서비스를 사용해서 장애에 대해 파이프라인의 견고성(robustness)을 증가시킬 수 있습니다. 또, 인프라의 여러 부분을 확장시킬 수 있고 전체 파이프라인을 구축하고 운영하는데 필요한 노력을 줄일 수 있습니다.

기대하는 데이터 통찰력을 얻기 위한 쿼리 계산으로부터 택시를 통해 전송된 이벤트의 수집과 저장을 분리하여, 인프라의 견고성을 상당히 증가시킬 수 있습니다.
이벤트는 처음에는 Amazon Kinesis Streams를 통해 유지됩니다. Amazon Kinesis Streams는 재생 가능하고 순서가 있는 로그(log)를 보유하며 여러 가용 영역(Availability Zone)에 이벤트를 중복 저장합니다. 이후에, 스트림에서 이벤트를 읽어서 Apache Flink에서 처리합니다. Flink는 내부 상태를 지속적으로 스냅샷으로 남겨놓기 때문에, 스냅샷에서 내부 상태를 복원하고 스트림에서 재처리가 필요한 이벤트를 재생하여 오퍼레이터 또는 전체 노드에서 발생한 장애를 복구 할 수 있습니다.
이벤트 저장을 위해 이렇게 한 곳에 로그를 보유하는 또 다른 장점은 여러 애플리케이션에서 데이터를 소비(Consume)할 수 있다는 점입니다. 벤치마크 테스트 및 일반 테스트를 위해 다른 버전의 Flink 애플리케이션을 나란히 실행시키는 것도 가능합니다. 또는, 장기간 아카이빙을 위해 스트림에서 Amazon S3로 데이터를 저장하는 데에 Amazon Kinesis Firehose를 사용할 수 도 있고, 그런 다음 Amazon Athena를 사용하여 과거의 기록을 상세하게 분석할 수도 있습니다.
Amazon Kinesis Streams, Amazon EMR, Amazon ES는 간단한 API 호출을 통해 생성 및 확장할 수 있는 관리형 서비스입니다. 따라서 이러한 서비스를 사용하면 비즈니스 가치를 제공하기 위한 전문 작업에 집중할 수 있습니다. 파이프라인 전체를 구축하고, 운영하고, 확장하기 위해 필요한 것들이 구분되어 있지 않은 무거운 작업을AWS로 수행하시기 바랍니다. 파이프 라인 생성은 AWS CloudFormation으로 완전히 자동화 될 수 있습니다. 개별 구성 요소는 Amazon CloudWatch를 통해 모니터링되고 자동으로 확장될 수 있습니다. 오류 사항 감지 및 자동 완화 역시 지원됩니다.
이후 부분에서는, AWS에서 레퍼런스 아키텍처를 만들고 실행하는 것에 관련된 부분에 중점을 두겠습니다. Flink에 대한 자세한 사항은, API를 이용하여 Flink 프로그램을 어떻게 구현하는지 다루는 Flink training session 을 참조하시기 바랍니다. 이 세션에서 사용된 시나리오는 이 글에서 다루는 내용과 상당히 비슷합니다.
레퍼런스 아키텍처 빌드 및 실행
실제 택시 운행 분석 애플리케이션을 위해, 다음 2 개의 CloudFormation 템플릿을 사용하여 레퍼런스 아키텍처를 만들고 실행합니다:
- 첫번째 템플릿은 택시 운행을 스트림으로 수집하고 Flink로 운행 정보를 분석하기 위한 런타임 아티팩트(artifact)를 구축합니다.
- 두번째 템플릿은 애플리케이션을 실행시키는 인프라 리소스를 생성합니다.
Flink 애플리케이션과 CloudFormation템플릿을 비롯한, 레퍼런스 아키텍처를 구축하고 실행시키는데 필요한 리소스는 AWSLabs GitHub 저장소의 flink-stream-processing-refarch에 있습니다.
런타임 아티팩트(Artifacts) 빌드 및 인프라 생성
우선 첫번째 CloudFormation 템플릿을 실행해서 AWS CodePipeline 파이프라인을 생성합니다. 이 파이프라인은 서버리스 방식으로 AWS CodeBuild를 사용해서 아티팩트를 만듭니다. 여기에 Maven을 설치하고 Flink Amazon Kinesis 커넥터 및 기타 런타임 아티팩트를 수동으로 구축할 수 있습니다. 파이프라인의 모든 단계가 성공적으로 완료되면, CloudFormation 템플릿의 출력 섹션에 지정되어 있는 S3 버킷에서 아티팩트를 검색할 수 있게 됩니다.
첫번째 템플릿이 생성되고 런타임 아티팩트가 만들어지면, 두번째 CloudFormation 템플릿을 실행합니다. 이를 통해 앞에서 설명한 레퍼런스의 리소스를 생성합니다. (SSH 접속을 위한 Key Pair가 없을 경우 두번째 CloudFormation 템플릿 실행 전에 미리 생성하여 준비합니다)
![]()
다음 단계를 진행하기 전에 위의 템플릿 2개가 모두 성공적으로 생성될 때까지 기다립니다. 약 15분 정도 걸릴 수 있으니, CloudFormation이 모든 작업을 마칠 때까지 자유롭게 커피 한 잔 하면서 기다립니다.
![]()
Flink 런타임 시작 및 Flink 프로그램 제출하기
Flink 런타임을 시작하고, 분석을 하는 Flink 프로그램을 서브밋(submit)하기 위해, EMR 마스터 노드에 연결합니다. 인프라 프로비저닝과 런타임 아티팩트 빌드를 위해 사용된 2개의 CloudFormation 템플릿의 실행 결과를 다음 명령어와 관련 파라미터를 통해 확인할 수 있습니다.
CloudFormation 템플릿을 통해 프로비저닝 된 EMR 클러스터는 노드당 4개의 vCPU를 지닌 2개의 c4.xlarge 코어 노드로 구성됩니다. 일반적으로, 태스크 매니저당 슬롯의 개수와 노드 코어의 수를 동일하게 맞춥니다. 여기서는, 2개의 태스크 매니저와 각 태스크 매니저 당 4개의 슬롯을 지닌 long-runnig Flink 클러스터로 시작하면 적절하겠습니다 (EMR 마스터 노드에 접속한 상태에서 다음 명령어를 실행합니다):
$ flink-yarn-session -n 2 -s 4 -tm 4096 -dFlink 런타임이 실행되고 나면, 택시 스트림 프로세서 프로그램은 Amazon Kinesis 스트림 내의 운행 이벤트를 실시간으로 분석하기 위해 Flink 런타임에 제출 됩니다.
$ aws s3 cp s3://«artifact-bucket»/artifacts/flink-taxi-stream-processor-1.0.jar .
$ flink run -p 8 flink-taxi-stream-processor-1.0.jar --region «AWS region» --stream «Kinesis stream name» --es-endpoint https://«Elasticsearch endpoint»Flink 애플리케이션이 실행 중이니, 스트림에서 유입되는 이벤트를 읽습니다. 그런 다음 이벤트 시간에 따라 타임 윈도우 내에서 이들을 집계하여 결과를 Amazon ES로 전송합니다. Flink 애플리케이션은 소규모 요청으로 Elasitcsearch 클러스터에 과부하가 걸리지 않도록 배치 레코드를 처리하고, 배치 처리 요청에 서명을 통해서Elasticsearch 클러스터의 보안 구성이 가능하도록 합니다.
브라우저에서 프록시(proxy)를 활성화 해놓았다면, 마스터 노드에 대한 SSH 세션을 수립하는 동적 포트 포워딩을 통해서Flink 웹 인터페이스를 볼 수 있습니다.
택시 운행 이벤트를 Amazon Kinesis Stream으로 입력
이벤트를 수집하기 위해, 택시 스트림 프로듀서 애플리케이션을 사용합니다. 이 애플리케이션은 미국 뉴욕 시에서 기록한 택시 운행의 이력 데이터셋을 S3로부터 읽어와서 8개의 샤드(shard)가 있는 Amazon Kinesis Stream으로 재생합니다. 택시 운행에 외에도, 프로듀서 애플리케이션은 워터마크 이벤트를 스트림으로 가져옵니다. 이를 통해서 프로듀서가 이력 데이터셋을 재생하는 시간을 Flink 애플리케이션이 결정할 수 있게 됩니다.
$ ssh -C ec2-user@«producer instance IP»
$ aws s3 cp s3://«artifact-bucket»/artifacts/kinesis-taxi-stream-producer-1.0.jar .
$ java -jar kinesis-taxi-stream-producer-1.0.jar -speedup 1440 -stream «Kinesis stream name» -region «AWS region»이 애플리케이션은 이번 블로그에서 논의한 레퍼런스 아키텍처에만 특화된 것은 아닙니다. 예를 들어 Apache Flink 대신 Amazon Kinesis Analytics를 기반으로 유사한 스트림 처리 아키텍처를 구축하는 식으로 다른 목적에도 쉽게 재사용이 가능합니다.
Kibana 대시보드 탐색
전체 파이프라인이 실행중이므로, Flink 애플리케이션에 의해 실시간으로 제공되는 인사이트를 보여주는 Kibana 대시보드를 볼 수 있습니다:
https://«Elasticsearch end-point»/_plugin/kibana/app/kibana#/dashboard/Taxi-Trips-Dashboard이 글의 목적에 맞게 Elasticsearch 클러스터는 인프라를 생성하는 CloudFormation 템플릿의 파라미터로 지정된 IP 주소 범위의 연결을 허용하도록 구성됩니다. 프로덕션-준비 상태의 애플리케이션의 경우, 이러한 설정이 맞지 않을 수도 있고 설정 자체가 불가능할 수도 있습니다. Elasticsearch 클러스터에 안전하게 연결하는 방법에 대한 자세한 내용은 AWS 데이터베이스 블로그의 Amazon Elasticsearch Service에 대한 액세스 제어 설정을 참조하시기 바랍니다.
Kibana 대시 보드에서 왼쪽의 지도는 택시 운행의 시작 지점을 시각화하여 보여주고 있습니다. 사각형이 빨간색에 가까울수록 해당 위치에서 더 많은 택시 운행이 시작됨을 의미합니다. 오른쪽의 그래프 차트는 John F. Kennedy 국제 공항과 LaGuardia Airport까지의 택시 운행 평균 시간을 각각 보여줍니다.

이러한 정보를 가지고, 현재 수요가 많은 지역에 빈 택시를 사전 조치하여 보내고 현지 공항으로의 운행 시간을 보다 정확하게 예측함으로써 택시 차량 운영 최적화가 가능해집니다.
이제 기본 인프라를 확장시킬 수 있습니다. 예를 들면, 스트림의 샤드 용량을 확장 시킵니다. Elasticsearch 클러스터의 인스턴수 갯수 또는 타입도 변경합니다. 아울러, 전체 파이프라인이 스케일 조정 중에도 제대로 동작하고 응답하는지 확인합니다.
AWS 에서 Apache Flink 실행
앞에서 본 것처럼, Flink 런타임은 YARN을 통해서 배포될 수 있습니다. 따라서 EMR은 AWS 상에서 Flink를 실행시키기에 매우 적합합니다. 하지만, Flink 애플리케이션을 빌드하고 실행시키기 위해 해야할 AWS에 관련된 고려사항이 몇 가지 있습니다:
- Flink Amazon Kinesis 커넥터 빌드
- Amazon Kinesis 컨슈머(Consumer) 환경 설정 수정
- Amazon Kinesis에 워터마크를 서브밋해서 이벤트 시간 처리를 가능하게 함
- Flink를 Amazon ES에 연동
Flink Amazon Kinesis 커넥터 빌드
Flink는 Amazon Kinesis Streams를 위한 커넥터를 제공합니다. 다른 Flink 아티팩트와는 달리, Amazon Kinesis 커넥터는 Maven central에서는 사용할 수 없습니다. 따라서 여러분이 직접 빌드하셔야 합니다. Maven 3.3.x의 경우 부적절하게 가려진 의존성(dependency)으로 인한 출력이 만들어질 수 있으므로, Maven 3.3.x 이상의 배포판 보다는 Maven 3.2.x로 Flink 빌드를 권장합니다.
$ wget -qO- https://github.com/apache/flink/archive/release-1.2.0.zip | bsdtar -xf-
$ cd flink-release-1.2.0
$ mvn clean package -Pinclude-kinesis -DskipTests -Dhadoop-two.version=2.7.3 -Daws.sdk.version=1.11.113 -Daws.kinesis-kcl.version=1.7.5 -Daws.kinesis-kpl.version=0.12.3Flink Amazon Kinesis 커넥터를 받고 나면, 로컬 Maven 저장소에 .jar 파일들을 임포트 할 수 있습니다.
$ mvn install:install-file -Dfile=flink-connector-kinesis_2.10-1.2.0.jar -DpomFile=flink-connector-kinesis_2.10-1.2.0.pom.xmlAmazon Kinesis consumer 환경 설정 적용
Flink는 최근 EMR 클러스터와 관련된 role에서 AWS 자격 증명을 얻을 수 있도록 지원하기 시작했습니다. Flink 애플리케이션 소스 코드에서 AWS_CREDENTIALS_PROVIDER 속성을 AUTO로 설정하고 Properties 객체에서 AWS_ACCESS_KEY_ID 및 AWS_SECRET_ACCESS_KEY 파라미터를 생략하여 이 기능을 활성화합니다.
Properties kinesisConsumerConfig = new Properties();
kinesisConsumerConfig.setProperty(AWSConfigConstants.AWS_CREDENTIALS_PROVIDER, "AUTO");자격 증명은 인스턴스의 메타데이터에서 자동으로 검색되므로 장기 자격 증명을 Flink 애플리케이션 또는 EMR 클러스터의 소스 코드에 저장할 필요가 없습니다.
프로듀서 애플리케이션은 초당 수천 개의 이벤트를 스트림으로 가져오므로, 단일 GetRecords 호출에서 Flink가 가져온 레코드 수를 늘리는 데 도움이 됩니다. 이 값을 Amazon Kinesis 에서 지원하는 최대값으로 변경하시기 바랍니다.
kinesisConsumerConfig.setProperty(ConsumerConfigConstants.SHARD_GETRECORDS_MAX, "10000");Amazon Kinesis에 대한 워터마크 제출을 통한 이벤트 타임 프로세싱 지원
Flink는 여러 가지 개념의 타임, 특히 이벤트 타임을 지원합니다. 이벤트 타임은 스트리밍 응용 프로그램에 매우 적합한데, 이는 쿼리에 대해 안정적인 의미의 결과를 내주기 때문입니다. 이벤트 타임은 프로듀서 또는 프로듀서에 근접한 경우에 의해 결정됩니다. 네트워크로 인한 이벤트 순서의 재지정이 쿼리 결과에 미치는 영향은 매우 작습니다.
이벤트 타임을 실현하기 위해, Flink는 일정한 시간 간격으로 프로듀서가 보낸 워터마크를 사용하여 소스의 현재 시간을 Flink 런타임에게 알립니다. Amazon Kinesis Streams와 통합할 때 Flink 에 워터 마크를 제공하는 두 가지 방법이 있습니다:
- 스트림에 워터마크를 수동으로 추가
- 스트림 수집 과정에서 이벤트에 자동으로 추가되도록 ApproximalArrivalTime을 이용
Amazon Kinesis 스트림에서 시간 모델을 이벤트 시간으로 설정하면, Flink는 Amazon Kinesis에서 제공하는 ApproximalArrivalTime 값을 자동으로 사용합니다.
StreamExecutionEnvironment env = StreamExecutionEnviron-ment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);또는, 스트림의 해당 이벤트에서 워터 마크 정보를 추출하는 사용자 정의 Timestamp Assigner 연산자를 지정하여 프로듀서가 정해 놓은 시간을 사용하도록 선택할 수도 있습니다.
DataStream<Event> kinesis = env
.addSource(new FlinkKinesisConsumer<>(...))
.assignTimestampsAndWatermarks(new PunctuatedAssigner())PunctuatedAssigner 를 사용할 경우, 모든 개별 샤드에 워터 마크를 가져오는 것이 중요합니다. 왜냐하면Flink는 스트림별 샤드를 개별적으로 처리하기 때문입니다. 이는 스트림의 샤드를 나열하여 해결할 수 있습니다. 워터마크가 전송될 샤드의 해시 범위에 대해 해시 키를 명시적으로 세팅해서 특정 샤드에 워터마크를 수집합니다.
Amazon Kinesis를 이용하여 택시 운행 정보를 수집하는 프로듀서는 후자의 접근법을 사용합니다. 구현에 관련된 자세한 사항은 AWSLabs GitHub 저장소의flink-stream-processing-refarch를 참고하시기 바랍니다.
Amazon ES와 Flink의 연동
Flink는 Elasticsearch에 대한 몇 가지 커넥터를 제공합니다. 그러나 이러한 모든 커넥터는 단지 Elasticsearch의 TCP 전송 프로토콜을 지원합니다. 반면 Amazon ES는 HTTP 프로토콜을 사용합니다. Elasticsearch 5부터는 TCP 전송 프로토콜이 더 이상 사용되지 않습니다. HTTP 프로토콜을 지원하는 Flink 용 Elasticsearch 커넥터는 여전히 동작하지만, Jest 라이브러리를 사용하여 Amazon ES에 연결할 수 있는 사용자 정의 싱크(sink)를 빌드 할 수 있습니다. 싱크(sink)는 IAM 자격 증명으로 요청에 서명 할 수 있어야합니다.
Elasticsearch 싱크의 전체 구현에 대한 자세한 내용은 Flink 애플리케이션의 소스 코드가 포함 된 flink-taxi-stream-processor AWSLabs GitHub 저장소를 참조하십시오.
요약
이 글에서는 Apache Flink를 기반으로 일관성 있고 확장 가능하며 안정적인 스트림 처리 아키텍처를 구축하는 방법에 대해 설명했습니다. 또한 관리형 서비스를 활용하여 짧은 대기 시간 및 높은 처리량 스트림 처리 파이프라인을 구축하고 유지 관리하는 데 필요한 전문 지식과 운영 노력을 줄이는 방법을 보여줌으로써 전문 지식을 비즈니스 가치를 제공하는 데에 집중할 수 있습니다.
오늘부터 Amazon EMR에서 Apache Flink를 사용해보시기 바랍니다. AWSLabs GitHub 저장소에는 주어진 예제를 실행하는 데 필요한 리소스가 포함되어 있으며 빠르게 시작하는 데 도움이 되는 추가 정보가 포함되어 있습니다.
이 글은 AWS Bigdata 블로그의 Build a Real-time Stream Processing Pipeline with Apache Flink on AWS의 한국어 번역으로, AWS 프로페셔널 서비스의 남궁영환 컨설턴트께서 번역해 주셨습니다.


Leave a Reply