Amazon SageMaker, 배치 변환 기능 및 TensorFlow 컨테이너를 위한 파이프 입력 모드 추가
지난 주 AWS Summit NY에서 두 가지 새로운 Amazon SageMaker 기능을 출시했습니다. 그 중 하나는 고객이 페타바이트 규모의 데이터에 대한 비-실시간 시나리오에서 예측을 수행할 수 있게 해 주는 배치 변환이라는 새로운 배치 추론 기능이며 다른 하나는 TensorFlow 컨테이너를 위한 파이프 입력 모드 지원입니다. SageMaker는 한국 블로그와 Machine Learning 블로그에서 상세하게 다루고 있지만, 출시 중인 기술 혁신 속도는 보조를 맞추기조차 어려울 정도입니다.
SageMaker의 하이퍼 파라미터 최적화를 통한 자동 모델 튜닝 기능 출시 이후로 SageMaker 팀은 네 가지 새로운 내장 알고리즘과 수많은 신규 기능을 출시했습니다. 먼저 새로운 배치 변환 기능에 대해 살펴보겠습니다.
배치 변환
배치 변환 기능은 데이터 변환 및 추론 생성을 위한 고성능 고처리량 방식으로서 대규모의 데이터 배치를 처리하거나 초 단위 이하의 지연 시간이 필요하지 않거나 훈련 데이터에 대한 사전 처리 및 변환이 모두 필요한 시나리오에 이상적입니다. 가장 좋은 점은 이 기능을 사용하기 위해 단 한 줄의 코드도 작성할 필요가 없다는 것입니다. 고객은 기존 모델을 그대로 가져와 이를 기반으로 배치 변환 작업을 시작할 수 있습니다. 이 기능은 추가 요금 없이 사용할 수 있으며 기반 리소스에 대한 비용만 지불하면 됩니다.
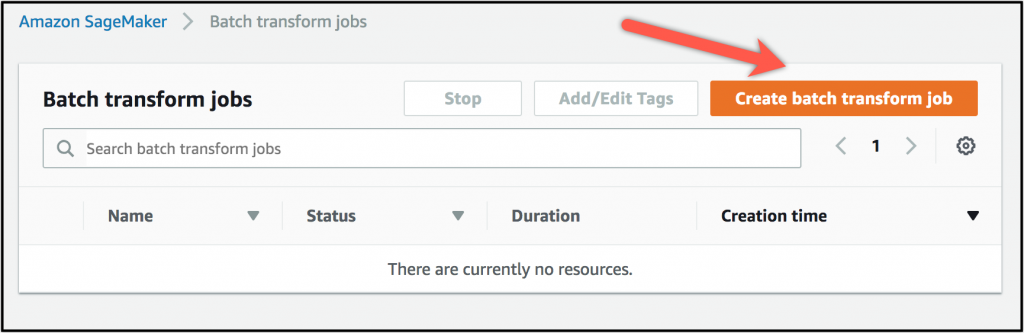
내장된 객체 탐지 알고리즘에 이 기능을 어떻게 사용할 수 있는지 살펴보겠습니다. 저는 객체 탐지 모델을 훈련하는 예제 노트북을 따라 작업을 수행했습니다. 이제 SageMaker 콘솔로 이동하여 배치 변환 하위 콘솔을 열겠습니다.

여기에서 새 배치 변환 작업을 시작할 수 있습니다.

여기에서 변환 작업의 이름을 지정하고, 사용하려는 모델 및 사용하려는 인스턴스의 수와 유형을 선택할 수 있습니다. 그뿐 아니라 동시에 추론에 전송할 레코드의 수와 페이로드의 크기에 대한 구체적인 사항을 구성할 수 있습니다. 이러한 사항을 수동으로 지정하지 않으면 SageMaker에서 적합한 일부 기본값을 선택합니다.

다음에는 입력 위치를 지정해야 합니다. 매니페스트 파일을 사용하거나 모든 파일을 S3 위치에 직접 로드할 수 있습니다. 여기에서는 이미지를 다루고 있으므로 입력 컨텐츠 유형을 수동으로 지정했습니다.

마지막으로 출력 위치를 구성하고 작업을 시작하겠습니다!

일단 작업이 실행되면 작업 세부 정보 페이지를 열고 Amazon CloudWatch의 지표 및 로그에 대한 링크를 따를 수 있습니다.

작업이 실행 중인 것을 볼 수 있으며 S3의 결과를 보면 각 이미지에 대해 예측된 레이블이 표시되어 있습니다.

변환 작업은 탐지된 객체를 포함하는 입력 파일 당 하나의 출력 JSON 파일을 생성합니다.
여기에서부터는 쉽게 AWS Glue에서 버킷에 대한 테이블을 생성하고 Amazon Athena로 결과를 쿼리하거나 Amazon QuickSight를 통해 시각화할 수 있습니다.
물론 SageMaker API에서 프로그래밍을 통해 이러한 작업을 시작할 수도 있습니다.
자체 컨테이너에 배치 변환을 사용하는 방법에 대한 보다 세부적인 내용은 설명서에서 찾을 수 있습니다.
Tensorflow용 파이프 입력 모드
파이프 입력 모드에서는 고객이 고도로 최적화된 멀티 스레드 백그라운드 프로세스를 사용하여 Amazon Simple Storage Service(S3)에서 Amazon SageMaker로 훈련 데이터 세트를 직접 스트리밍할 수 있습니다. 이 모드는 데이터를 먼저 로컬 Amazon Elastic Block Store(EBS) 볼륨으로 다운로드해야 하는 파일 입력 모드보다 대폭 향상된 처리량을 제공합니다. 이는 곧 훈련 작업이 더 빨리 시작 및 완료되며, 더 적은 디스크 공간을 사용하고, 모델 훈련과 관련된 비용을 절감할 수 있음을 의미합니다. 그 외에 16TB EBS 볼륨 크기 한도보다 큰 데이터 세트를 훈련할 수 있다는 장점도 있습니다.

올해 초 저희는 파이프 입력 모드에 대한 일부 실험을 수행했으며 78GB 데이터 세트에서 시동 시간이 최대 87% 단축되고 일부 벤치마크에서 처리 속도가 최대 2배 빨라져 궁극적으로 전체 훈련 시간이 최대 35% 단축되는 것을 확인했습니다.
TensorFlow에 파이프 입력 모드에 대한 지원을 추가함으로써 고객은 내장 알고리즘에서 사용 가능한 속도 증가의 이점을 더 쉽게 활용할 수 있게 되었습니다. 이 작업을 실제로 살펴보겠습니다.
먼저, 훈련 작업에 sagemaker-tensorflow-extensions를 사용 가능한지 확인해야 합니다. 이 기능은 채널과 기록 형식을 입력 받아 TensorFlow 데이터 세트를 반환하는 새로운 PipeModeDataset 클래스를 제공합니다. 이 클래스를 TensorFlow 산출기용 input_fn 함수에 사용하고 채널에서 값을 읽을 수 있습니다. 아래의 샘플은 간단한 예제를 보여줍니다.
from sagemaker_tensorflow import PipeModeDataset
def input_fn(channel):
# Simple example data - a labeled vector.
features = {
'data': tf.FixedLenFeature([], tf.string),
'labels': tf.FixedLenFeature([], tf.int64),
}
# A function to parse record bytes to a labeled vector record
def parse(record):
parsed = tf.parse_single_example(record, features)
return ({
'data': tf.decode_raw(parsed['data'], tf.float64)
}, parsed['labels'])
# Construct a PipeModeDataset reading from a 'training' channel, using
# the TF Record encoding.
ds = PipeModeDataset(channel=channel, record_format='TFRecord')
# The PipeModeDataset is a TensorFlow Dataset and provides standard Dataset methods
ds = ds.repeat(20)
ds = ds.prefetch(10)
ds = ds.map(parse, num_parallel_calls=10)
ds = ds.batch(64)
return ds
그러면 일반 TensorFlow 산출기에서와 같은 방식으로 모델을 정의할 수 있습니다. 산출기 생성 시간에 대해서는 파라미터 중 하나로 input_mode='Pipe' 값을 전달하기만 하면 됩니다.

지금 이용 가능
이 새로운 기능 둘 다는 현재 추가 요금 없이 사용할 수 있습니다. 배치 변환 기능으로 다양한 솔루션을 구축해 보시기 바랍니다. AWS Marketing에서도 일부 사내 ML 워크로드에 많은 도움이 될 것이 확실합니다.
– Randall
Source: Amazon SageMaker, 배치 변환 기능 및 TensorFlow 컨테이너를 위한 파이프 입력 모드 추가


Leave a Reply