Amazon SageMaker를 위한 서버리스 엔드포인트 만들기
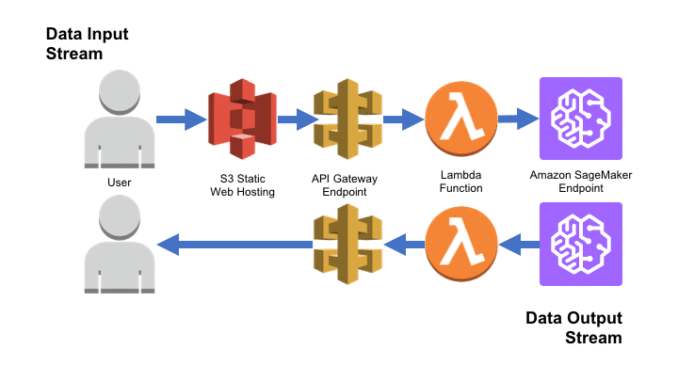
Amazon SageMaker는 AWS에서 기계 학습 모델을 구축 및 교육하고 프로덕션 환경에 배포할 수 있는 강력한 플랫폼을 제공합니다. 이 강력한 플랫폼과 Amazon Simple Storage Service(S3), Amazon API Gateway 및 AWS Lambda의 서버리스 기능을 결합하면, Amazon SageMaker 엔드포인트를 잠재적으로 다양한 소스로부터 새로운 입력 데이터를 수락하고 최종 사용자에게 결과로 나온 추론을 제시하는 웹 애플리케이션으로 변환할 수 있습니다.
이 블로그 게시물에서는 유명한 Iris dataset를 사용하여 간단한 SageMaker 모델을 생성하고 이를 Amazon SageMaker엔드포인트로서 배포하겠습니다. 그런 다음 Chalice 패키지를 통해 API Gateway 엔드포인트를 생성하여 고유한 예측을 생성하는 SageMaker 엔드포인트를 호출할 Lambda 함수를 트리거하겠습니다. 마지막으로 애플리케이션의 사용자 인터페이스 역할을 하도록 Amazon S3에서 정적 HTML 양식을 생성하겠습니다. 이 엔드포인트는 새로운 사용자 데이터를 수락하고 해당 데이터를 기반으로 온디맨드 예측을 생성하여 사용자의 브라우저로 반환할 수 있는 간단한 웹 앱입니다.
이는 SageMaker 설명서에 제안된 아키텍처와 유사한 AWS Lambda 아키텍처의 한 버전이지만, 모든 사용 사례에 해당하는 최적의 아키텍처가 아닐 수 있습니다. 지연 시간이 중요한 고려 사항인 경우, SageMaker 엔드포인트에 호스팅된 Docker 컨테이너에 직접 데이터 변환을 구축하는 것이 좋습니다. 하지만 단일 엔드포인트와 상호 작용하는 여러 잠재적 프런트엔드 및/또는 데이터 소스가 있는 복잡한 애플리케이션을 보유한 경우에는 API Gateway와 Lambda를 사용하는 것이 가장 적합합니다. 이 블로그 게시물을 통해 데모, 개념 증명 및 프로토타입을 시작할 수 있습니다. 하지만 프로덕션 아키텍처는 다음 예제와 상당히 다를 수 있습니다.
Amazon SageMaker 모델 배포
기계 학습 애플리케이션을 구축하는 첫 번째 단계는 모델을 배포하는 것입니다. 프런트엔드까지 효율적으로 진행하기 위해 샘플 노트북 scikit_bring_your_own.ipynb를 기반으로 사전에 구축되고 사전에 교육된 모델을 퍼블릭 Docker 이미지에서 Amazon SageMaker로 배포하겠습니다. 이 이미지는 모든 SageMaker 노트북 인스턴스에서 사용할 수 있습니다. 이 이미지가 어떻게 만들어졌는지 궁금하다면 이 노트북을 살펴보시기 바랍니다. 서버리스 프런트엔드에만 관심이 있다면, 다음 지침을 따라 SageMaker 엔드포인트에서 사전에 구축된 모델을 설정하시기 바랍니다.
모델 생성
AWS Management Console에서 Services를 선택한 다음, Machine Learning 아래에서 Amazon SageMaker를 선택합니다. 모든 것이 확실히 같은 리전에 있도록 오른쪽 위 모서리에서 리전으로 US East (N. Virginia)를 선택합니다. 그런 다음 Resources 아래에서 Models를 선택합니다. 그리고 Create model 버튼을 선택합니다.

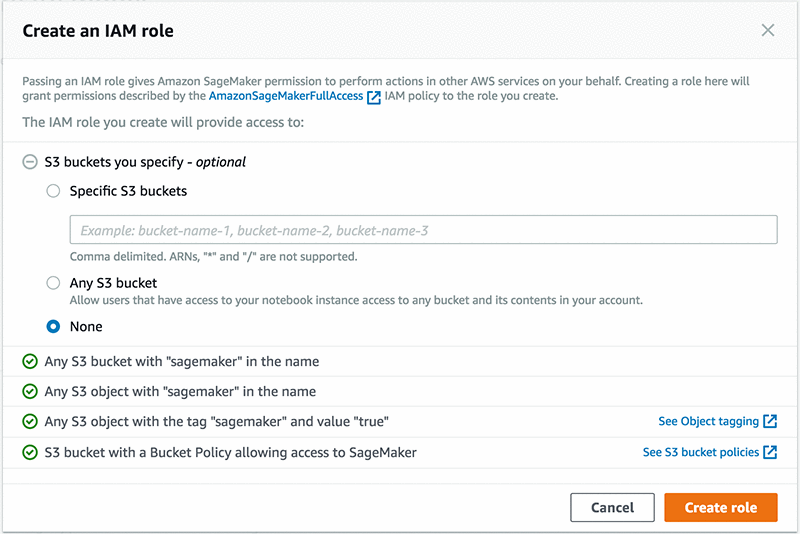
이 예제에서는 Model name을 decision-trees로 설정하고, IAM role 아래에서 Create a new role을 선택합니다.
이 역할에는 Amazon S3에 대한 특별 액세스 권한이 필요 없습니다. 따라서 S3 buckets you specify 아래에서 None을 선택한 후 Create role을 선택합니다. 모델을 구축하거나 교육하는 경우에는 이러한 권한이 필요하지만, 여기에서는 사전에 구축된 모델을 사용하고 있으므로 필요하지 않습니다.
이제 다음 값을 Primary container에 입력합니다.
Location of inference code image: 305705277353.dkr.ecr.us-east-1.amazonaws.com/decision-trees-sample:latest
Location of model artifacts: s3://aws-machine-learning-blog/artifacts/decision-trees/model.tar.gz
이러한 위치는 이 예제에서 사용하고 있는 사전에 구축된 모델과 Docker 컨테이너를 위한 것입니다. Create model을 선택합니다. 그러면 Amazon SageMaker가 어떻게 추론하고 어디에서 특정 모델을 찾아야 하는지 알 수 있습니다. 향후에는 자체 모델을 사용하시기 바랍니다.
엔드포인트 구성 생성
Amazon SageMaker 콘솔의 왼쪽 탐색 창에 있는 Inference 아래에서 Endpoint configuration을 선택합니다. 이제 Create endpoint configuration 버튼을 선택합니다. Endpoint configuration name을 “decision-trees”라고 입력한 후 New endpoint configuration 블록 하단에서 Add model을 선택합니다.
이 새로운 Add model 대화 상자에서 이전 단계에서 생성한 decision-trees 모델을 선택한 후, Save를 선택합니다.
새로운 엔드포인트 구성은 다음과 같아야 합니다.

Create endpoint configuration 버튼을 선택합니다. 엔드포인트 구성을 통해 Amazon SageMaker는 어떤 모델을 사용하고(이전 섹션), 어떤 유형의 인스턴스를 사용하고, 몇 개의 인스턴스를 사용해 엔드포인트를 초기화해야 하는지 알 수 있습니다. 다음 섹션에서는 인스턴스를 구동할 실제 엔드포인트를 생성하겠습니다.
엔드포인트 생성
SageMaker 콘솔의 왼쪽 탐색 창에 있는 Inference 아래에서 Endpoints를 선택합니다. [Create endpoint] 버튼을 선택합니다. Endpoint name 아래에 “decision-trees”를 입력합니다. Attach endpoint configuration 아래에 있는 Use an existing endpoint configuration의 기본 값을 그대로 유지합니다.
Endpoint configuration 아래에서 마지막 단계에서 생성한 decision-trees 엔드포인트를 선택한 후, Select endpoint configuration 버튼을 선택합니다. 결과는 다음과 같아야 합니다.
이제 Create endpoint 버튼을 선택합니다.
Iris dataset를 기반으로 사전에 구축된 Scikit 모델을 배포했습니다! 이제 엔드포인트용 서버리스 프런트엔드를 구축할 수 있습니다.
경고: SageMaker 엔드포인트를 실행 상태로 두면 비용이 발생합니다. 학습 경험을 쌓기 위해 이 블로그를 따라 하고 있다면, 추가 비용이 발생하지 않도록 완료 시 엔드포인트를 삭제하시기 바랍니다.
Chalice를 통한 서버리스 API 작업 생성
이제 SageMaker 엔드포인트를 사용할 수 있으므로, 최종 사용자에게 제공할 결과를 생성하기 위해서는 엔드포인트에 액세스할 수 있는 API 작업을 생성해야 합니다. 이 블로그 게시물에서는 Chalice 프레임워크를 사용하여 API Gateway에 간단한 Flask 유사 애플리케이션을 배포함으로써 SageMaker 엔드포인트와 상호 작용할 Lambda 함수를 트리거합니다.
Chalice는 AWS를 위한 서버리스 마이크로 프레임워크입니다. 이를 사용하면 Amazon API Gateway 및 AWS Lambda를 사용하는 애플리케이션을 신속하게 생성하고 배포할 수 있습니다. 현재 엔드포인트는 CSV 형식의 입력을 예상하므로 HTML 양식 데이터를 엔드포인트가 예상하는 CSV 파일로 변환하기 위해 약간의 사전 처리를 수행해야 합니다. Chalice를 사용하면 자체 Lambda 함수를 구축하는 것과 비교하여 빠르고 효율적으로 이를 수행할 수 있습니다.
Chalice의 장점 및 단점에 대한 추가 질문이 있는 경우, Chalice GitHub 리포지토리를 참조하시기 바랍니다.
개발 환경
일관된 환경을 유지하기 위해 개발 환경으로 Amazon EC2 인스턴스를 사용하겠습니다. AWS Management Console에서 Services를 선택한 후, Compute 아래에서 EC2를 선택합니다. 이제 Launch Instance 버튼을 선택합니다. Amazon Linux AMI에는 필요한 개발 도구 대부분이 함께 제공되므로 우리에게 적합한 환경입니다. Select를 선택합니다.

리소스 집약적인 작업은 수행하지 않을 것이므로 t2.micro를 선택한 후, Review and Launch 버튼을 선택하는 것이 좋습니다. 마지막으로 Launch 버튼을 한 번 더 선택합니다.
Select an existing key pair or create a new key pair라는 메시지가 표시될 것입니다. 인스턴스에 연결할 수 있는 가장 편리한 방법을 선택합니다. EC2 인스턴스에 연결하는 데 익숙하지 않은 경우, 설명서의 Linux 인스턴스에 연결 섹션에서 지침을 확인할 수 있습니다.
인스턴스에 연결하기 전에 인스턴스에 일부 권한을 부여해야 합니다. 아니면 Chalice 애플리케이션을 배포할 때 자격 증명을 사용해야 합니다. AWS Management Console에서 Services로 이동한 후, Security, Identity & Compliance 아래에서 IAM을 선택합니다. 왼쪽에서 Roles를 선택한 후, Create role을 선택합니다.
Select type of trusted entity에서 AWS service와 EC2를 각각 선택합니다. Choose the service that will use this role 아래에서 EC2 (Allows EC2 instances to call AWS services on your behalf)를 선택합니다. Next: Permissions를 선택합니다.
이 화면에서 Next: Review를 선택하기 전에 AmazonAPIGatewayAdministrator, AWSLambdaFullAccess, AmazonS3FullAccess 및 IAMFullAccess를 권한으로 선택합니다.
Role name으로 chalice-dev를 입력하고, “Allows an EC2 instance to deploy a Chalice application”과 유사한 설명을 입력합니다. Create role을 선택합니다.
이제 새로운 역할을 실행 중인 EC2 인스턴스에 연결해야 합니다. Services를 선택하고 Compute 아래에서 EC2를 선택하여 EC2 콘솔로 돌아갑니다. Running instances를 선택합니다. 앞에서 시작한 인스턴스를 선택하고, Actions와 Instance Settings를 선택한 후, Attach/Replace IAM role을 선택합니다.
IAM role 아래에서 “chalice-dev“를 선택한 후, Apply를 선택합니다.
이제 EC2 인스턴스에 연결할 수 있습니다.
Chalice 설정
EC2 인스턴스에 연결한 후에는 Chalice와 Python용 AWS SDK(Boto3)를 설치해야 합니다. 다음 명령을 실행하십시오.
다음 명령으로 환경 변수를 설정하여 애플리케이션이 모델과 같은 리전에 배포되도록 하겠습니다.
이제 Chalice가 설치되었으므로 새로운 Chalice 프로젝트를 생성할 수 있습니다. 샘플 애플리케이션을 다운로드하고 프로젝트 디렉터리로 변경하겠습니다. 다음 명령을 실행하면 됩니다.
이 패키지의 app.py 파일은 우리가 앞에서 배포한 사전에 구축된 모델과 상호 작용하도록 특별히 설계되었습니다. 또한, Chalice가 프런트엔드에서 필요한 종속성이 무엇인지 알 수 있도록 requirements.txt file을 다운로드했으며, “.chalice” 폴더에는 추가로 숨겨진 구성 파일이 있습니다. 이는 정책 권한을 관리하는 데 도움이 됩니다.
앱이 어떤 모습인지 감을 잡을 수 있도록 소스를 간략하게 살펴보겠습니다. 다음 명령을 실행합니다.
나중에 자체 모델에서 이러한 파일을 자유롭게 사용하고 수정하십시오.
이제 필요한 Chalice 프로젝트 파일을 확보하였으므로 애플리케이션을 배포할 수 있습니다. 이를 위해 터미널에서 다음 명령을 실행합니다.
실행이 완료되면 chalice 엔드포인트의 URL이 반환됩니다. 나중에 Rest API URL을 프런트엔드의 HTML 파일에 입력해야 하므로 이를 저장합니다.
이제 SageMaker 엔드포인트와 통신할 수 있는 API Gateway 엔드포인트에 연결된 Lambda 함수를 배포했습니다. 이제 필요한 것은 데이터를 API Gateway에 게시할 HTML 프런트엔드뿐 입니다. 사용자가 프런트엔드 애플리케이션을 사용하여 요청을 제출하면, 해당 요청은 API Gateway로 전달됩니다. 그러면 Lambda 함수가 트리거됩니다. 이 함수는 Chalice 애플리케이션에 포함된 app.py 파일을 기반으로 작업을 실행하고 데이터를 여러분이 생성한 SageMaker 엔드포인트로 전송합니다. 필요한 사전 처리 작업은 사용자 지정 app.py 파일에서 수행될 수 있습니다.
HTML 사용자 인터페이스 생성
이제 SageMaker에 호스팅된 모델이 있고 엔드포인트와 상호 작용할 수 있는 API Gateway 인터페이스가 있습니다. 하지만 여전히 사용자가 새로운 데이터를 우리 모델로 제출하고 실시간 예측을 생성할 수 있게 해주는 적절한 사용자 인터페이스가 없습니다. 다행히도 우리는 우리 데이터를 Chalice 애플리케이션의 엔드포인트에 POST할 간단한 HTML 양식만 제공하면 됩니다.
Amazon S3를 사용하면 간단하게 해결됩니다.
명령줄 도구를 사용하여 Amazon S3에 웹 사이트 버킷을 생성하겠습니다. 버킷 이름을 선택하고 다음 명령을 실행합니다.
이제 프런트엔드 역할을 하도록 샘플 HTML 파일을 버킷에 업로드해야 합니다. 샘플 HTML 파일을 다운로드하고 우리 목적에 맞게 수정하겠습니다. 여기에서 Chalice 엔드포인트를 배포 명령에서 우리가 저장한 URI입니다.
index.html을 살펴보겠습니다.
이 파일에서 중요한 부분은 API Gateway 엔드포인트를 가리키는 양식의 동작입니다. 이를 통해 HTML 파일이 업로드된 파일을 Lambda 함수에 POST할 수 있고, 그래야 이 함수가 SageMager 엔드포인트와 통신하게 됩니다.
HTML 프런트엔드를 생성했으므로 이제 이를 Amazon S3 웹 사이트에 업로드해야 합니다. 다음 명령을 실행합니다.
새로운 사용자 인터페이스는 http://<bucket_name>.s3.amazonaws.com/index.html과 유사한 URL에서 사용할 수 있습니다.
결론
축하합니다! 이제 Amazon SageMaker에서 구축, 교육 및 호스팅한 모델을 위해 완벽하게 작동하는 서버리스 프런트엔드 애플리케이션이 완성되었습니다! 이 주소를 사용하여 사용자가 새로운 데이터를 모델에 제출하고 즉시 실시간 예측을 생성하도록 할 수 있습니다.
사용자가 Amazon S3의 정적 HTML 페이지에 액세스하면, 이 페이지는 POST 메서드를 사용하여 양식 데이터를 API Gateway로 전송합니다. 그러면 Lambda 함수가 트리거되어 데이터를 Amazon SageMaker가 예상하는 형식으로 변환합니다. 그런 다음 Amazon SageMaker가 이 입력을 수락하고, 사전에 교육된 모델을 통해 실행하고, 새로운 예측을 생성합니다. 그리고 이 예측은 AWS Lambda로 반환됩니다. 그러면 AWS Lambda는 결과를 사용자에게 렌더링합니다.
이 모든 것이 프로토타입, 빠른 데모, 소규모 배포에서는 문제없이 작동하지만, 프로덕션 환경에서는 좀 더 강력한 프레임워크를 사용하는 것이 좋습니다. 이를 위해서는 서버리스 접근 방식을 포기하고, 상시 가동 배포 환경을 위한 AWS Elastic Beanstalk 프런트엔드를 개발할 수 있습니다. 또는 완벽하게 서버리스로 갈 수도 있습니다. 서버리스를 선택하면 Lambda 함수 내 SageMager 엔드포인트의 콘텐츠를 패키징하는 작업이 필요합니다. 이 프로세스는 어떤 ML 프레임워크를 사용하는지에 따라 달라지며 이 블로그 게시물의 범위에서 벗어납니다. 어떤 방향을 선택할지는 자체 프로덕션 요구 사항에 따라 달라집니다.
이 애플리케이션을 영구적으로 실행할 생각이 아니라면, Amazon S3와 Amazon SageMaker에서 사용한 다양한 리소스를 잊지 말고 정리하시기 바랍니다. 특히 사용료가 부과되지 않도록 엔드포인트를 꼭 삭제하십시오.
자유롭게 이 일반 구조를 사용하여 Amazon SageMaker와 AWS에서 좀 더 복잡하고 흥미로운 애플리케이션을 구축하시기 바랍니다!
참조
Dua, D. 및 Karra Taniskidou, E.(2017년). UCI Machine Learning Repository. Irvine, CA: University of California, School of Information and Computer Science.
 Thomas Hughes는 AWS Professional Services의 데이터 과학자입니다. UC Santa Barbara에서 박사 학위를 받았으며 사회과학, 교육 및 광고 분야의 문제를 다루어왔습니다. 현재 기계 학습 모델을 복잡한 애플리케이션에 통합하는 모범 사례를 연구하고 있습니다.
Thomas Hughes는 AWS Professional Services의 데이터 과학자입니다. UC Santa Barbara에서 박사 학위를 받았으며 사회과학, 교육 및 광고 분야의 문제를 다루어왔습니다. 현재 기계 학습 모델을 복잡한 애플리케이션에 통합하는 모범 사례를 연구하고 있습니다.
이 글은 AWS Machine Learning 블로그의 Build a serverless frontend for an Amazon SageMaker endpoint의 한국어 번역입니다.


Leave a Reply