Amazon EC2 G4 인스턴스 정식 출시 – NVIDIA T4 Tensor 코어 GPU 기반 (서울 리전 포함)
올해 초반에 약속했던대로 NVIDIA 지원 Amazon EC2 G4 인스턴스가 정식 출시되었습니다. 총 6개 인스턴스 크기로 서울 리전 포함 8개 AWS 리전에서 사용해보실 수 있습니다! 이 인스턴스는 기계 학습 교육 및 추론, 비디오 코드 변환, 게임 스트리밍 및 원격 그래픽 워크스테이션 애플리케이션에 사용할 수 있습니다.

G4 인스턴스는 각각 320개 Turing Tensor 코어, 2,560개 CUDA 코어 및 16GB 메모리를 보유한 4개의 NVIDIA T4 Tensor 코어 GPU를 탑재하고 있습니다. T4 GPU는 기계 학습 추론, 컴퓨터 비전, 비디오 처리, 실시간 음성 및 자연어 처리에 적합합니다. 또한 T4 GPU는 효율적인 하드웨어 지원 레이 트레이싱을 위해 RT 코어도 제공합니다. NVIDIA Quadro Virtual Workstation(Quadro vWS)은 AWS Marketplace에서 사용할 수 있습니다. 이 제품은 실시간 레이 트레이싱 렌더링을 지원하며, 미디어 및 엔터테인먼트, 아키텍처, 석유 및 가스 관련 애플리케이션에서 종종 나타나는 창의적 워크플로를 가속화할 수 있습니다.
G4 인스턴스는 AWS 사용자 지정 2세대 인텔® 제온® 스케일러블(캐스케이드 레이크) 프로세서(최대 64개 vCPU 장착)로 지원되며, AWS Nitro 시스템에 구축되어 있습니다. Nitro의 로컬 NVMe 스토리지 구성 요소는 최대 1.8TB의 빠른 로컬 NVMe 스토리지를 제공합니다. Nitro의 네트워킹 구성 요소는 고속 ENA 네트워킹을 제공합니다. Intel AVX512 딥 러닝 부스트 기능은 새로운 VNNI(Vector Neural Network Instructions) 세트 기반 AVX-512를 확장합니다. 이 명령어는 많은 추론 알고리즘의 내부 루프에 상주하는 낮은 정밀도의 곱셈 및 덧셈 연산을 가속화합니다.
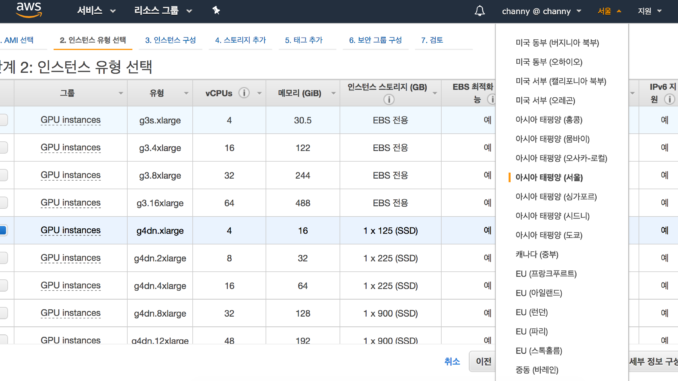
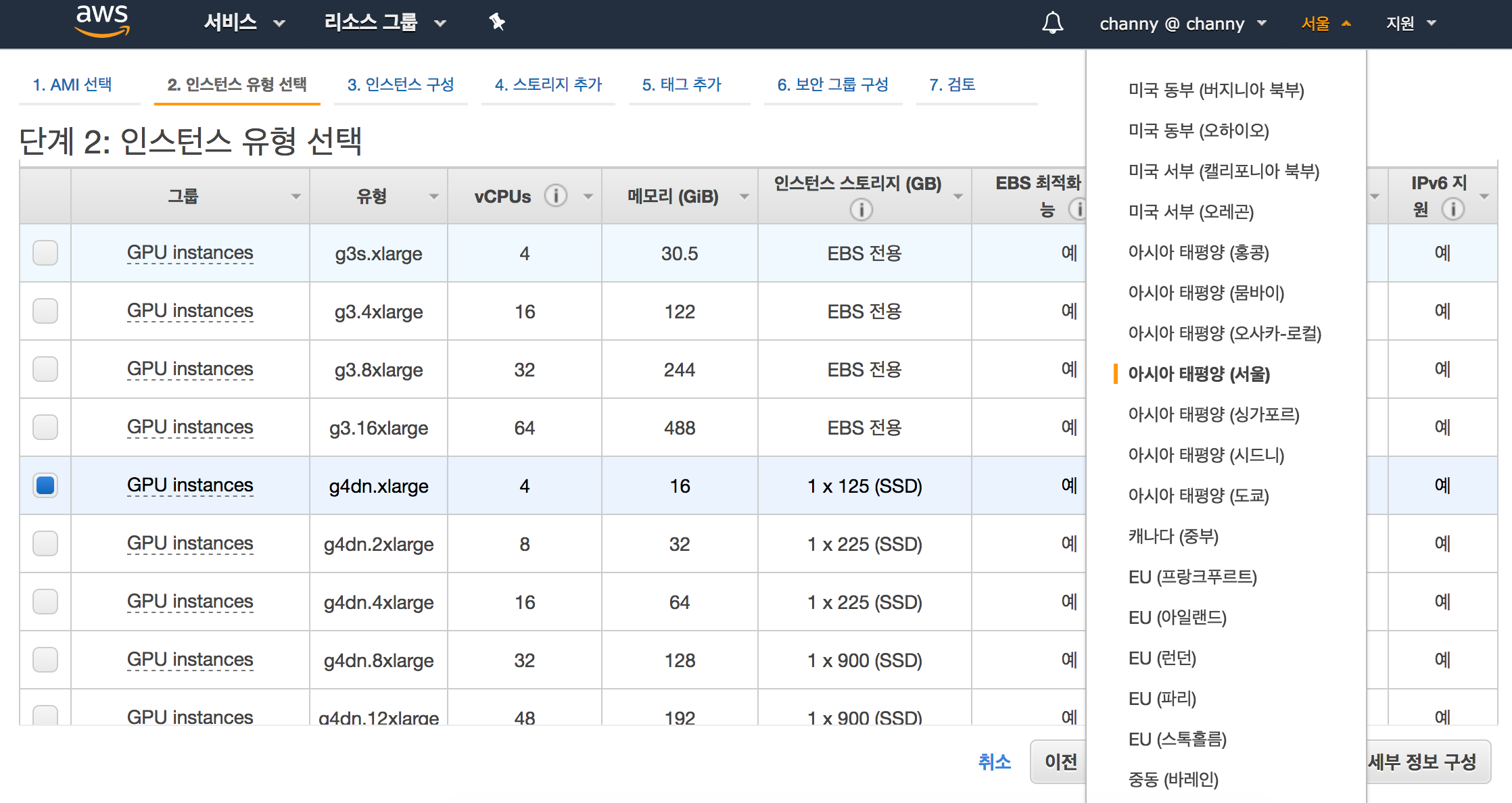
다음은 인스턴스의 크기입니다.
| 인스턴스 이름 |
NVIDIA T4 Tensor 코어 GPU | vCPU | RAM | 로컬 스토리지 | EBS 대역폭 | 네트워크 대역폭 |
| g4dn.xlarge | 1 | 4 | 16GiB | 1 x 125GB | 최대 3.5Gbps | 최대 25Gbps |
| g4dn.2xlarge | 1 | 8 | 32GiB | 1 x 225GB | 최대 3.5Gbps | 최대 25Gbps |
| g4dn.4xlarge | 1 | 16 | 64GiB | 1 x 225GB | 최대 3.5Gbps | 최대 25Gbps |
| g4dn.8xlarge | 1 | 32 | 128GiB | 1 x 900GB | 7Gbps | 50Gbps |
| g4dn.12xlarge | 4 | 48 | 192GiB | 1 x 900GB | 7Gbps | 50Gbps |
| g4dn.16xlarge | 1 | 64 | 256GiB | 1 x 900GB | 7Gbps | 50Gbps |
또한 다음 달에 제공 예정인 베어 메탈 인스턴스도 준비 중입니다.
| 인스턴스 이름 |
NVIDIA T4 Tensor 코어 GPU | vCPU | RAM | 로컬 스토리지 | EBS 대역폭 | 네트워크 대역폭 |
| g4dn.metal | 8 | 96 | 384GiB | 2 x 900GB | 14Gbps | 100Gbps |
G4 인스턴스에서 그래픽 워크로드를 실행하려는 경우 최신 최적화 및 패치를 포함하는 NVIDIA Quadro Workstation 이미지와 함께 필수 GRID 및 그래픽 드라이버에 액세스할 수 있도록 NVIDIA AMI의 최신 버전을 사용해야 합니다(AWS Marketplace에서 사용 가능). 다음은 이 요소를 제공하는 위치입니다.
- NVIDIA Gaming – Windows Server 2016
- NVIDIA Gaming – Windows Server 2019
- NVIDIA Gaming – Ubuntu 18.04
최신 AWS Deep Learning AMI에는 G4 인스턴스에 대한 지원이 포함되어 있습니다. AMI를 생성하는 팀은 g4dn.12xlarge 인스턴스에 대해 g3.16xlarge 인스턴스를 벤치마킹했으며, 이 결과를 저와 공유해주었습니다. 다음은 몇 가지 주요 사항입니다.
- MxNet Inference(resnet50v2, MMS 없이 포워드 패스) – 2.03배 단축.
- MxNet Inference(MMS 포함) – 1.45배 단축.
- MxNet Training(resnet50_v1b, 1 GPU) – 2.19배 단축.
- Tensorflow Inference(resnet50v1.5, 포워드 패스) – 2.00배 단축.
- Tensorflow Inference(Tensorflow Service 지원)(resnet50v2) – 1.72배 단축.
- Tensorflow Training(resnet50_v1.5) – 2.00배 단축.
벤치마크는 FP32 숫자 정밀도를 사용합니다. 혼합 정밀도(FP16) 또는 낮은 정밀도(INT8)를 사용하는 경우 더 큰 부스트 기능을 예상할 수 있습니다. 또한, 비용도 스팟 구매 옵션을 사용하면 최대 75%까지 저렴하게 사용 가능합니다.

오늘 미국 동부(버지니아 북부), 미국 동부(오하이오), 미국 서부(오레곤), 미국 서부(캘리포니아 북부), EU(프랑크푸르트), EU(아일랜드), EU(런던), 아시아 태평양(서울) 및 아시아 태평양(도쿄) 지역에서 G4 인스턴스를 시작할 수 있습니다.
또한 Amazon SageMaker 및 Amazon EKS 클러스터에서 해당 인스턴스에 액세스할 수 있도록 준비 중입니다.
— Jeff Barr & Channy(윤석찬);
Source: Amazon EC2 G4 인스턴스 정식 출시 – NVIDIA T4 Tensor 코어 GPU 기반 (서울 리전 포함)


Leave a Reply