Amazon S3 업데이트 — 강력한 쓰기 후 읽기 일관성
2006년에 S3를 출시했을 때 사실상 무제한의 용량 (“…개수에 상관없이 블록을 쉽게 저장…”)과, 99.99%의 가용성을 제공하도록 설계되었으며 데이터가 여러 위치에 투명하게 저장되는 내구성 있는 스토리지를 제공한다는 사실에 대해 논의했습니다. 이 출시 이후 고객은 백업 및 복원, 데이터 아카이빙, 엔터프라이즈 애플리케이션, 웹 사이트, 빅 데이터, 그리고 10,000개가 넘는 (마지막 계산 시 수치) 데이터 레이크와 같은 놀랄 정도로 다양한 방식으로 S3를 사용해왔습니다.
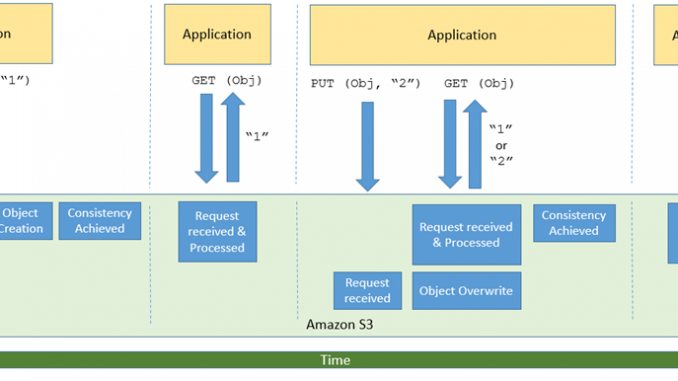
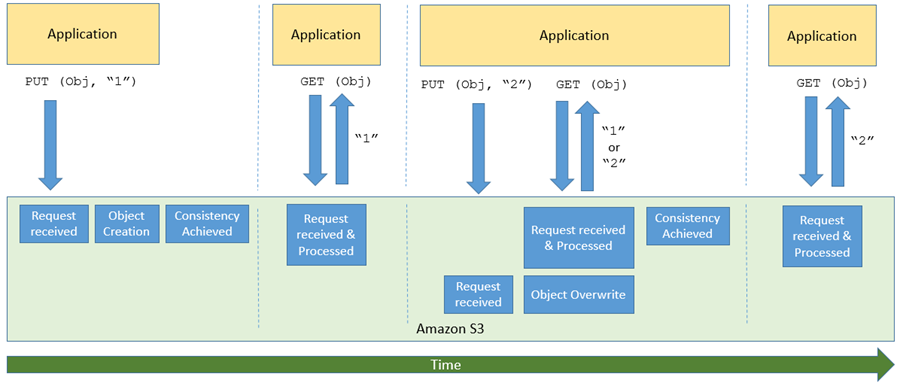
S3 및 기타 대규모 분산 시스템의 더 흥미롭고 때로는 다소 혼란스러운 측면 중 하나가 바로 일반적으로 최종 일관성이라고 하는 개념입니다. 간단히 말해서 데이터를 저장하거나 수정하는 PUT과 같은 S3 API 함수를 호출한 후에는 데이터가 허용되고 안정적으로 저장되었지만 모든 GET 또는 LIST 요청에는 아직 표시되지 않는 약간의 시간 지연이 있습니다. 제가 이를 바라보는 방법은 다음과 같습니다.
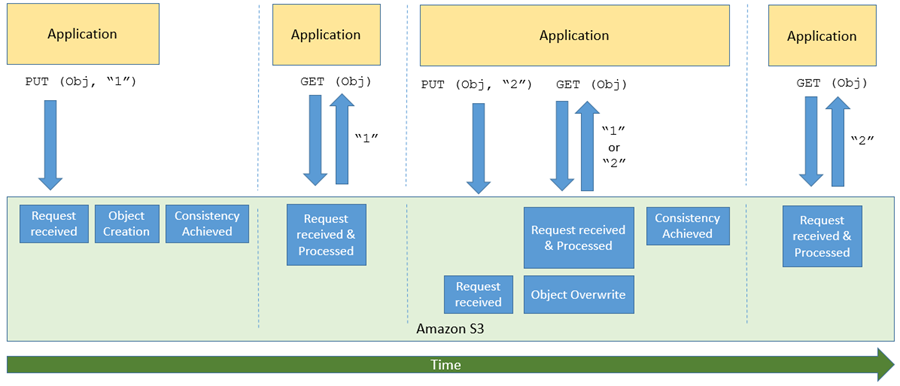
S3의 이러한 측면은 빅 데이터 워크로드 (대부분 Amazon EMR을 사용함)와 데이터 레이크의 경우 매우 까다로울 수 있습니다. 둘 다 쓰기 직후 최신 데이터에 액세스해야 하기 때문입니다. 고객이 클라우드에서 빅 데이터 워크로드를 실행할 수 있도록 Amazon EMR은 EMRFS Consistent View를 구축했으며 오픈 소스 Hadoop 개발자는 S3Guard를 구축했습니다. 이 S3Guard는 이러한 애플리케이션에 강력한 일관성을 제공합니다.
이제 강력한 일관성을 제공하는 S3
도입부가 지나치게 길었지만 여러분에게 소개할 좋은 소식이 있습니다!
모든 S3 GET, PUT 및 LIST 작업은 물론 객체 태그, ACL또는 메타데이터를 변경하는 작업에도 즉시 적용되어, 모두 강력한 일관성을 제공하게 되었습니다. 여러분이 쓰는 것은 곧 여러분이 읽을 내용이며, LIST의 결과는 버킷에 있는 것을 정확하게 반영합니다. 이는 모든 기존 S3 객체는 물론 새 S3 객체에 적용되고 모든 리전에서 작동하며 추가 비용 없이 사용할 수 있습니다! 성능에 영향을 미치지 않으며, 원하는 경우 초당 수백 번 객체를 업데이트할 수 있고 전역 종속성이 없습니다.
이러한 개선은 데이터 레이크의 경우 유용하지만 다른 유형의 애플리케이션도 도움이 됩니다. S3는 이제 강력한 일관성을 제공하기 때문에 온프레미스 워크로드 및 스토리지를 AWS로 이전보다 쉽게 마이그레이션할 수 있습니다.
Microsoft는 고객이 빅 데이터 워크로드에서 이 업데이트를 활용할 수 있도록 하기 위해 Amazon EMR 팀 및 오픈 소스 커뮤니티의 개발자와 협력하고 있습니다. 따라서 EMRFS Consistent View 또는 S3Guard를 더 이상 사용할 필요가 없으므로 AWS에서 빅 데이터 워크로드를 실행하는 데 드는 비용을 더욱 절감할 수 있습니다.
S3의 강력한 일관성에 대해 자세히 알아보려면 여기 기능 페이지를 참조하실 수 있습니다.
Dropbox의 사례
오랜 기간 AWS 고객인 Dropbox는 최근 온프레미스 Hadoop 클러스터에서 34PB의 분석 데이터 레이크를 S3로 마이그레이션했습니다. 이 동영상을 시청하여 강력한 일관성과 Dropbox가 데이터 레이크를 간소화할 수 있는 방법에 대해 자세히 알아보실 수 있습니다.
— Jeff
Source: Amazon S3 업데이트 — 강력한 쓰기 후 읽기 일관성


Leave a Reply