Amazon HealthLake – 클라우드 기반 의료 데이터 저장, 변환 및 분석 서비스 제공
의료 기관은 가족력과 임상 관찰부터 진단 및 약물 치료에 이르기까지 매일 방대한 양의 환자 정보를 수집합니다. 그리고 더 나은 의료 서비스를 제공하기 위해 환자의 건강 정보를 포괄적으로 이해하고자 이러한 모든 데이터를 사용합니다. 현재 이 데이터는 다양한 시스템(전자 의료 기록, 실험실 시스템, 의료 이미지 리포지토리 등)에 분산되어 있으며 수십 개의 호환되지 않는 형식으로 존재합니다.
Fast Healthcare Interoperability Resources(FHIR)와 같은 새로운 표준의 목표는 이러한 시스템에서 구조화된 데이터를 설명하고 교환하기 위한 일관된 형식을 제공하여 이 과제를 해결하는 것입니다. 그러나 이러한 데이터 대부분은 의료 기록(예: 임상 기록), 문서(예: PDF 실험실 보고서), 양식(예: 보험 청구), 이미지(예: 엑스레이, MRI), 오디오(예: 녹음된 대화) 및 시계열 데이터(예: 심전도 검사)에 포함된 구조화되지 않은 정보이며, 이러한 정보를 추출하는 작업은 쉽지 않습니다.
의료 기관에서 이 모든 데이터를 수집하고 변환(태그 지정 및 인덱싱), 구조화 및 분석을 위해 준비하려면 몇 주 또는 몇 달이 걸릴 수 있습니다. 게다가 대부분의 의료 기관에서는 이 모든 작업을 수행하는 데 드는 비용과 복잡한 작업을 감당하기 어렵습니다.

오늘 완전관리형 HIPAA 적격 서비스인 Amazon HealthLake를 소개하게 되어 정말 기쁩니다. 평가판으로 출시된 이 서비스를 사용하면 의료 및 생명 과학 고객이 서로 다른 사일로의 의료 정보를 집계하여 중앙화된 AWS 데이터 레이크로 형식화할 수 있습니다. HealthLake는 기계 학습(ML) 모델을 사용하여 의료 데이터를 정규화하고 데이터에서 의미 있는 의료 정보를 자동으로 이해하고 추출하므로 이 모든 정보를 쉽게 검색할 수 있습니다. 그런 다음, 고객이 데이터를 쿼리 및 분석하여 관계를 이해하고 추세를 파악하며 예측을 수행할 수 있습니다.
작동 방식
Amazon HealthLake는 온프레미스에서 AWS 클라우드로 데이터 복사를 지원합니다. AWS 클라우드에 구조화된 데이터(예: 연구실 결과)와 구조화되지 않은 데이터(예: 임상 노트)를 저장하면 HealthLake가 FHIR에 따라 태그를 지정하고 구조화할 수 있습니다. 모든 데이터는 표준 의료 용어를 사용하여 완전히 인덱싱되므로, 모든 고객의 의료 정보를 빠르고 쉽게 쿼리, 검색, 분석 및 업데이트할 수 있습니다.
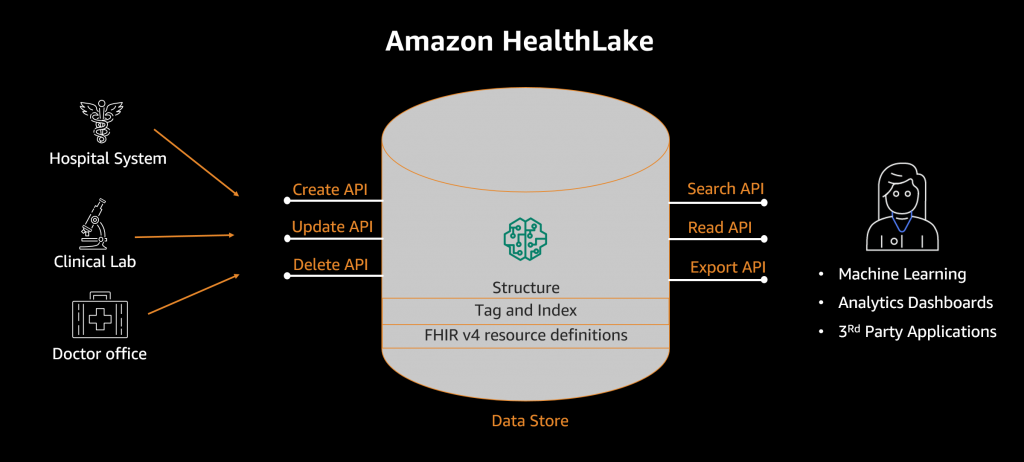
HealthLake를 사용하면 의료 기관이 몇 분 안에 환자의 의료 정보를 수집 및 변환하고 강력한 검색 및 쿼리 기능을 사용하여 FHIR 업계 표준 형식으로 구조화된 환자의 의료 기록을 완벽하게 파악할 수 있습니다.
AWS Management Console에서 의료 기관은 HealthLake API를 사용하여 몇 번의 클릭만으로 온프레미스 의료 서비스 데이터를 AWS의 안전한 데이터 레이크에 복사할 수 있습니다. 소스 시스템이 FHIR 형식으로 데이터를 전송하도록 구성되지 않은 경우 AWS 파트너 목록을 통해 기존 의료 서비스 데이터 형식을 쉽게 연결하고 FHIR로 변환할 수 있습니다.
기계 학습으로 지원되는 HealthLake
HealthLake는 자연어 처리(NLP)와 같은 전문 ML 모델을 사용하여 원시 데이터를 자동으로 변환합니다. 이러한 모델은 구조화되지 않은 상태 데이터에서 의미 있는 정보를 이해하고 추출하도록 훈련됩니다.
예를 들어, HealthLake는 의료 기록, 의사 메모 및 의료 영상 보고서에서 환자 정보를 정확하게 식별할 수 있습니다. 그런 다음, 변환된 데이터를 태그 지정, 인덱싱 및 구조화하여 의료 상태, 진단, 치료 및 약물 치료와 같은 표준 용어로 검색할 수 있습니다.
수만 건의 환자 기록에 대한 쿼리도 매우 간단합니다. 예를 들어, 의료 기관은 의료 상태에 대한 표준 목록에서 “diabetes”를 선택하고, 치료 메뉴에서 “oral medications”를 선택하며, 성별과 검색을 세분화하여 약물의 유사성을 기반으로 당뇨병 환자 목록을 만들 수 있습니다.
의료 기관은 Amazon SageMaker에서 Juypter Notebook 템플릿을 사용하여 진단 예측, 병원 재입원 확률, 수술실 사용 예측과 같은 공통 태스크에 대해 정규화된 데이터를 쉽고 빠르게 분석할 수 있습니다. 예를 들어, 이러한 모델은 의료 기관이 질병의 발병을 예측하는 데 도움이 될 수 있습니다. 의료 기관은 사전 구축된 노트북에서 몇 번의 클릭만으로 과거 데이터에 ML을 적용하고 향후 5년 동안 당뇨병 환자에게서 고혈압이 발병할 시기를 예측할 수 있습니다. 또한 운영자는 AWS Management Console에서 직접 Amazon SageMaker를 사용하여 자체 ML 모델을 구축, 훈련 및 배포할 수 있습니다.
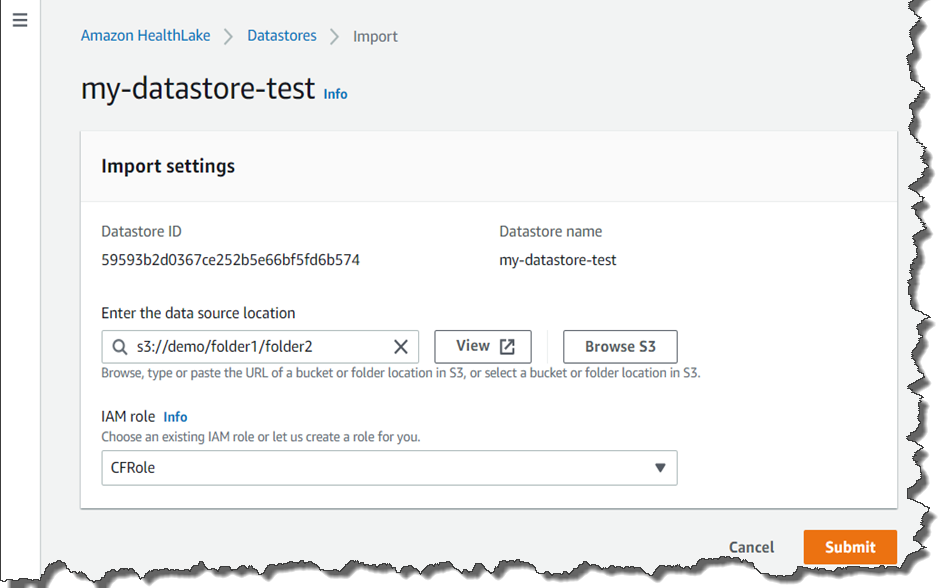
고유한 데이터 스토어 생성 후 테스트 시작
HealthLake를 사용하는 방법은 간단합니다. AWS Management Console에 액세스하고 [데이터 스토어 생성(Create a datastore)]을 클릭합니다.
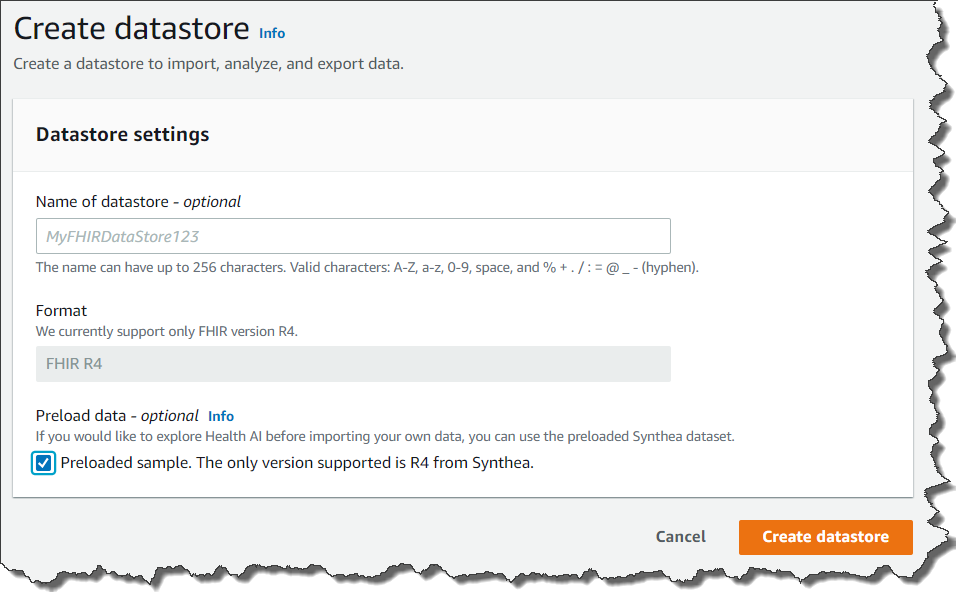 [데이터 사전 로드(Preload data)]를 클릭하면 테스트 데이터를 로드하고 기능 테스트를 시작할 수 있습니다. FHIR 4 준수 데이터가 이미 있는 경우 자체 데이터를 업로드할 수도 있습니다. S3 버킷에 업로드하고 가져와서 버킷 이름을 설정합니다.
[데이터 사전 로드(Preload data)]를 클릭하면 테스트 데이터를 로드하고 기능 테스트를 시작할 수 있습니다. FHIR 4 준수 데이터가 이미 있는 경우 자체 데이터를 업로드할 수도 있습니다. S3 버킷에 업로드하고 가져와서 버킷 이름을 설정합니다.
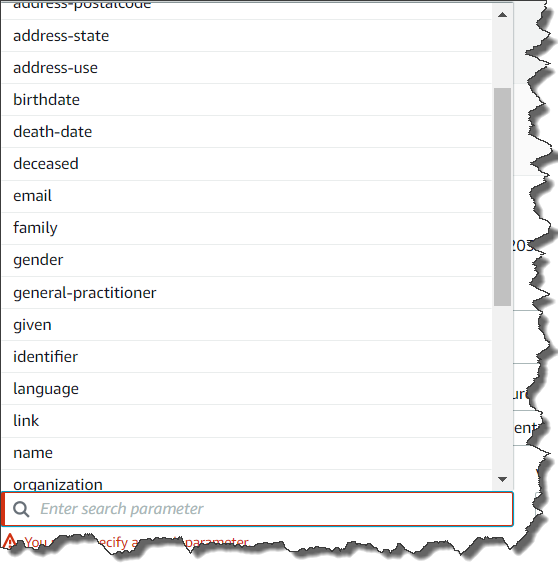
데이터 스토어가 작성되면 검색, 생성, 읽기, 업데이트 또는 삭제와 같은 FHIR 쿼리 작업을 수행할 수 있습니다. 예를 들어, 뉴욕에 있는 모든 환자 목록이 필요한 경우 쿼리 설정은 아래 스크린샷과 같습니다. FHIR 사양에 따라 삭제된 데이터는 분석 및 결과에서만 숨겨지고 서비스에서 삭제되지 않으며, 버전화만 지원됩니다.

아래와 같이 쿼리의 중첩된 조건에 대한 검색 파라미터 추가를 선택할 수 있습니다.
평가판으로 출시된 Amazon HealthLake
오늘 Amazon HealthLake는 미국 동부(버지니아 북부)에서 평가판으로 공개되었습니다. 자세한 내용은 웹 사이트를 참고하세요.
– Kame
Source: Amazon HealthLake – 클라우드 기반 의료 데이터 저장, 변환 및 분석 서비스 제공


Leave a Reply